
📌 Elasticsearch?
엘라스틱서치 = 검색엔진
그렇다면 검색엔진이란 무엇일까...?
웹에서 정보를 수집하여 검색 결과를 제공하는 프로그램이다.
우리가 많이 사용하는 데이터 베이스에서는 비정형 데이터를 색인하고 검색하는 것이 불가능하다.
비정형 데이터 : 정해진 규칙이 없는 데이터
색인 : 키워드를 찾아보기 쉽도록 정렬한 목록하지만 엘라스틱서치에서는 비정형 데이터를 색인하고 검색하는 것이 가능하다. 또한 역색인 구조를 사용함으로써 빠른검색이 가능하다.
역색인 : 키워드를 통해 문서를 찾는 방식엘라스틱서치 공식 페이지에서는 이렇게 정의하고 있다.
텍스트, 숫자, 위치 기반 정보, 정형 및 비정형 데이터 등 모든 유형의 데이터를 위한 무료 검색 및 분석 엔진으로 분산형 및 개방형을 특징으로 합니다.
엘라스틱서치는 애플리케이션 검색, 웹사이트 검색뿐만아니라 성능모니터링, 보안분석, 위치 기반 정보 데이터 분석 및 시각화 등에서도 사용될 수 있다.
그렇다면 이제 엘라스틱 서치에 대해 자세히 알아보자!
✅ 관계형 데이터베이스와의 비교
| 엘라스틱서치 | 관계형 데이터베이스 |
|---|---|
| 인덱스 | 데이터베이스 |
| 샤드 | 파티션 |
| 타입 | 테이블 |
| 문서 | 행 |
| 필드 | 열 |
| 매핑 | 스키마 |
| Query DSL | SQL |
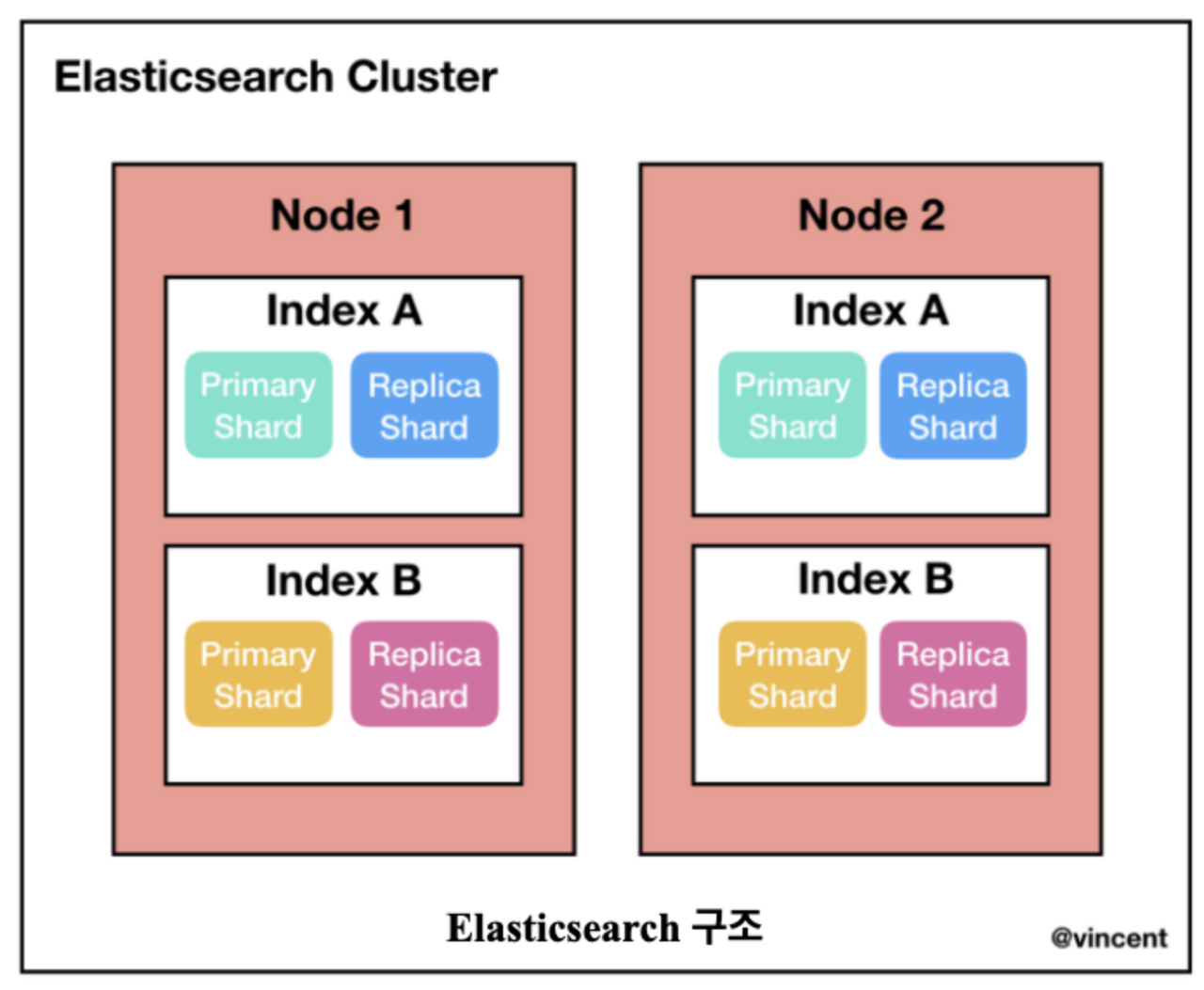
- 인덱스
- 데이터의 저장공간으로 유사한 특성을 가지고 있는 문서를 모아둔 컬렉션
- 엘라스틱 내부에 생성되는 모든 인덱스는 클러스터 내에서 유일한 인덱스명을 가져야 하기 때문에 매우 중요하고 모두 소문자로 설정해야함
- 샤드(Shard)
- 매우 많은 양의 문서가 저장되는 경우를 위해 데이터를 분산 저장하는 방식으로 수평확장 시키는 파티션
- 전체 데이터를 분산해서 가지고 있는 부분집합
- 설정에 의해 샤드 개수를 수정할 수 있고 인덱스에 쿼리를 요청하면 인덱스가 가지고 있는 모든 샤드로 검색 요청이 전달되고 각 샤드에서 1차 검색이 이루어진 후 그 결과를 취합해서 최종결과로 제공
- 문서
- 검색의 대상이 되는 실제적인 데이터
- JSON 형식으로 표현
- 매핑
- 문서의 필드와 필드의 속성을 정의하고 그에 따른 색인방법을 정의하는 프로세스
- 클러스터
- 데이터를 실제로 가지고 있는 노드들의 모임
- 노드
- 엘라스틱서치 클러스터를 운영하기 위해 다수의 물리 서버에 엘라스틱 서치를 설치하고 실행하게 되는데 이때 실행된 엘라스틱서치 인스턴스를 말함
- 안정적인 클러스터 운영을 위해 노드를 각 역할에 맞게 분리해서 운영하는 것을 권장
- 레플리카
- 샤드의 복제본
- 인덱스를 생성할 때 기본적으로 1개의 레플리카 생성
- 샤드 내부에는 루씬 라이브러리를 포함하고 있는데 이를 이용해 대부분의 검색기능을 제공
- 세그먼트
- 루씬의 데이터가 색인되면 데이터는 최소한의 단위인 토큰으로 분리되고 특수한 형태의 자료구조로 저장되는 자료구조
✅ 장점
엘라스틱서치를 다시 정의해보자면
" 오픈소스인 아파치 루씬(Apache Lucene) 으로 구현한 RESTful API 기반의 실시간 분산 검색엔진" 입니다.
따라서 최대 장점은 방대한 양의 데이터를 신속하고 거의 실시간으로 저장하며 저장, 검색, 분석할 수 있다는 것입니다.
-
오픈소스이다.
오픈소스이기 때문에 다양한 플러그인이 개발되어있습니다.
수많은 개발자가 필요에 따라 플러그인을 만들어 놓았기 때문에 필요에 따라서 손쉽게 기능을 확장할 수 있습니다. -
아파치 루씬 기반이다.
아파치 루씬 : 자바로 개발된 검색 서비스용 라이브러리루씬은 전문 텍스트 검색(Full text Search)에 특화되어 있어서 검색까지 대기시간이 1초정도로 매우 짧습니다.
-
RESTful API이다.
엘라스틱서치는 REST API로 조작할 수 있습니다. 즉 검색 및 분석 결과를 API형태로 제공하기 때문에 어플리케이션 개발 시 API종류만 알면 쉽게 활용할 수 있습니다. -
분산시스템
데이터를 분산하여 병렬처리 할 수 있기 때문에 검색대상의 사이즈가 크더라도 분석할 수 있고 처리속도도 빠릅니다. -
JSON 기반
JSON문서 형식으로 표현하기 때문에 비정형 데이터를 포함한 모든 유형의 데이터를 대상으로 분석 및 검색이 가능합니다. -
멀티테넌시(Multi-teneancy)
검색할 필드명으로 여러개의 인덱스를 한번에 조회할 수 있다.
✅ 단점
-
실시간이 아님
색인된 데이터는 내부적으로 commit과 flush등의 복잡한 과정을 거치기 때문에 1초 뒤에나 검색이 가능하다. 그러나 거의 실시간처럼 보인다. -
트랜잭션과 롤백기능이 없음
전체적인 클러스터의 성능향상을 위해 시스템적으로 비용소모가 큰 롤백과 트랜잭션을 지원하지 않는다. -
데이터의 업데이트를 제공하지 않음
데이터의 명령이 올 경우 기존 문서를 삭제(delete)하고 새로운 문서를 생성(insert)한다.
업데이트에 비해서 많은 비용이 들지만 이를 통해 불변성이라는 이점을 취한다.
📑 References
- https://www.elastic.co/kr/what-is/elasticsearch
- https://velog.io/@shinychan95/Elasticsearch-%EA%B8%B0%EB%B3%B8-%EA%B0%9C%EB%85%90-%EB%B0%8F-%ED%8A%B9%EC%A7%95-%EC%A0%95%EB%A6%AC
- https://velog.io/@jakeseo_me/%EC%97%98%EB%9D%BC%EC%8A%A4%ED%8B%B1%EC%84%9C%EC%B9%98-%EC%95%8C%EC%95%84%EB%B3%B4%EA%B8%B0-2-DB%EB%A7%8C-%EC%9E%88%EC%9C%BC%EB%A9%B4-%EB%90%98%EB%8A%94%EB%8D%B0-%EC%99%9C-%EA%B5%B3%EC%9D%B4-%EA%B2%80%EC%83%89%EC%97%94%EC%A7%84
- https://devfunny.tistory.com/384
- https://esbook.kimjmin.net/02-install/2.1
- https://jaemunbro.medium.com/elastic-search-%EA%B8%B0%EC%B4%88-%EC%8A%A4%ED%84%B0%EB%94%94-ff01870094f0
- https://it-ist.tistory.com/52
