Jar 파일 생성
- IntelliJ, Gradle 사용
- JDK는 azul-1.8 사용 (상위 버전 사용 시 에러 발생 가능성 있음)
-
Gradle Project 생성
-
WordCount.java
package org.example;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}- build.gradle
plugins {
id 'java'
}
group 'org.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
implementation 'org.testng:testng:7.1.0'
implementation group: 'org.apache.hadoop', name: 'hadoop-common', version:'3.3.4'
implementation group: 'org.apache.hadoop', name: 'hadoop-hdfs', version: '3.3.4'
implementation group: 'org.apache.hadoop', name: 'hadoop-yarn-common', version: '3.3.4'
implementation group: 'org.apache.hadoop', name: 'hadoop-minicluster', version: '3.3.4'
implementation group: 'org.apache.hadoop', name: 'hadoop-mapreduce-client-core', version:'3.3.4'
implementation group: 'org.apache.hadoop', name: 'hadoop-mapreduce-client-jobclient', version: '3.3.4'
implementation group: 'org.apache.hadoop', name: 'hadoop-mapreduce-client-app', version: '3.3.4'
implementation group: 'org.apache.hadoop', name: 'hadoop-mapreduce-client-shuffle', version: '3.3.4'
implementation group: 'org.apache.hadoop', name: 'hadoop-mapreduce-client-common', version: '3.3.4'
implementation group: 'org.apache.hadoop', name: 'hadoop-client', version: '3.3.4'
testImplementation group: 'junit', name: 'junit', version: '4.12'
implementation 'org.apache.hadoop:hadoop-common:3.3.4'
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.8.1'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.8.1'
}
test {
useJUnitPlatform()
}- 그래들 빌드 후 jar 파일 생성
Hadoop Client 생성
- cmd에서 실행
docker run -it -h client -p 5555:22 --name client --link master:master hyesungkang/hadoopbase- SSH root 접속 권한 설정
$ vi /etc/ssh/sshd_config
# PermitRootLogin yes 설정
#PermitRootLogin prohibit-password
PermitRootLogin yesWin SCP 설치
-
WinScp 실행 후 연결 설정
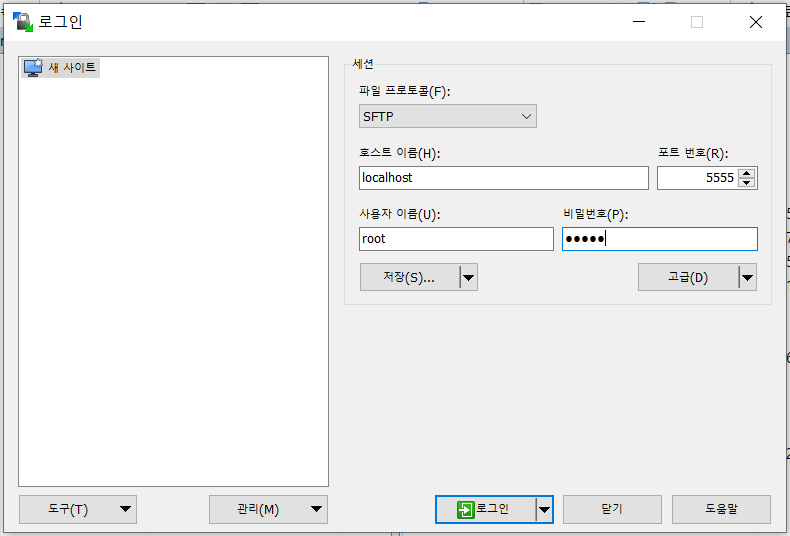
-
jar 파일 옮기기
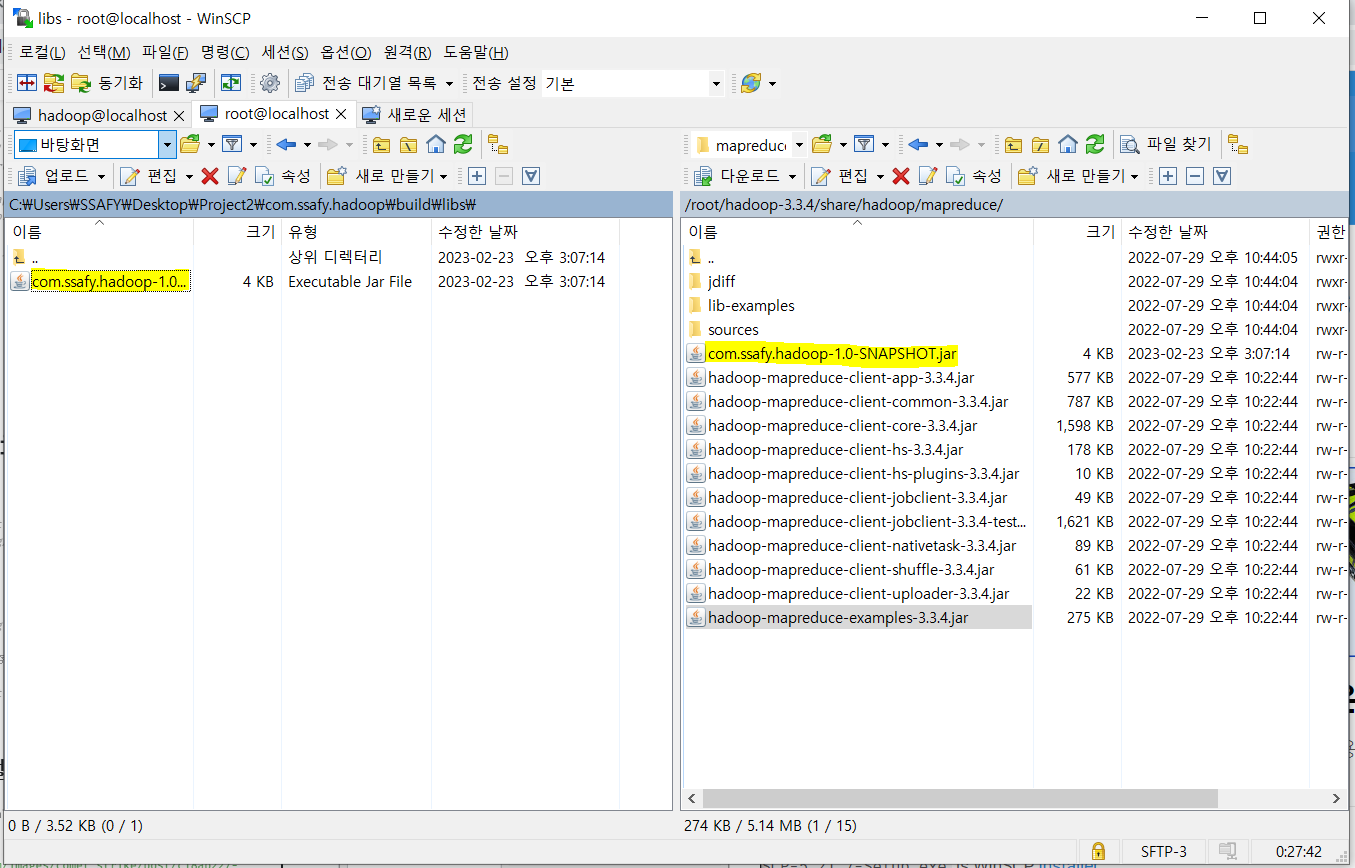
Hadoop 설정
- Client 에서 실행
- hadoop 데이터 저장 디렉토리 생성
$ hadoop fs -mkdir /data- hadoop 데이터 저장
$ hadoop fs -put [저장할 텍스트 파일 위치] /data- hadoop jar 파일 실행
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/com.ssafy.hadoop-1.0-SNAPSHOT.jar org.example.WordCount /data /test_out- Output 확인
$ hadoop fs -ls /test_out/*- 파일 확인
$ hadoop fs -cat /test_out/*