분산처리
1.분산 처리 - Hadoop, Spark, Kafka

Hadoop Apache Hadoop, High-Availability Distributed Object-Oriented Platform 대량의 자료를 처리할 수 있는 큰 컴퓨터 클러스터에서 동작하는 분산 응용 프로그램을 지원하는 프리웨어 자바 소프트웨어 프레임워크
2.Hadoop 설치

Window 10에 Hadoop 설치Docker는 설치되어 있다 가정cmd창에 다음을 입력하둡용 우분투 설치설치 이후 우분투에 들어가기 ubuntu root로 접속한 상태로 다음 실행라이브러리 및 jdk 설치SSH 설정SSH 접속할 수 있도록 키 파일 생성 / 권한 설
3.Hadoop 예제
IntelliJ, Gradle 사용JDK는 azul-1.8 사용 (상위 버전 사용 시 에러 발생 가능성 있음)Gradle Project 생성WordCount.javabuild.gradle그래들 빌드 후 jar 파일 생성cmd에서 실행SSH root 접속 권한 설정htt
4.Hive

하둡에서 동작하는 데이터 웨어하우스 인프라 구조로서 데이터 요약, 질의 및 분석 기능을 제공한다.데이터 웨어하우스(data warehouse)란 사용자의 의사 결정에 도움을 주기 위하여 기간시스템의 데이터베이스에 축적된 데이터를 공통의 형식으로 변환해서 관리하는 데이터
5.2023-03-02
금융 중 주식 관련된 모의 투자 학습 플랫폼을 개발하자는 의견이 나왔음데이터를 얻기 위해서 Open API를 이용할 예정Yahoo Finance API, Alpha Vantage, Kiwoom API를 조사공식 문서를 찾기 어려움지원이 중단된다는 이야기가 있음일 별 2
6.2023-03-03

MVP 구현 요구사항은 아래를 펼쳐서 확인 가능Yahoo Finance로 2020-01-01 ~ 2020.12.31 까지 1년 데이터를 한달 기준으로 가져오는 일을 수행 (코로나 기간)국내 주식 10건, 해외 주식 10건에 대해서 데이터를 가져옴국내주식, 해외주식 종목
7.Maria DB, Hadoop, Spark, Zeppelin 설치

Ubuntu 20.04LTSDocker는 설치되어 있음maria-db 설치docker run --name maria-db -d -p 3306:3306 --restart=always -e MYSQL_ROOT_PASSWORD=\[] mariadb --lower_case_t
8.2023-03-17
docker-compose > https://github.com/ManduTheCat/docker-hadoop-spark 참고 페이지 > https://github.com/dbusteed/kafka-spark-streaming-example > https://www.
9.주식 데이터 수집 - Yahoo Query
https://yahooquery.dpguthrie.com/asset_profile : Information related to the company's location, operations, and officers.https://yahooquery.
10.주식 데이터수집 2 - Yahoo Query
valid_company_list.csv를 이용해서 데이터를 가져옴valid_company_list.csv는 yahoo query 조회시 얻어올 수 있는 데이터를 저장한 파일importvalid_company_list.csv 파일 형식Information related
11.Naver Java Convention 적용
코딩 컨벤션을 적용하기 위해 네이버 핵데이 컨벤션을 적용하기로 결정https://naver.github.io/hackday-conventions-java/아래 블로그를 참고해서 IntelliJ에 설정https://bestinu.tistory.com/6
12.CRLF, LF
CRLF/LF는 OS에 따라 다른 개행 방식이다. 리눅스와 맥같은 Unix-like System은 LF 방식을 사용하고, 윈도우는 CR/LF 방식을 사용lf 방식을 사용하기로 함gitattributes 파일을 생성해서 lf 방식으로 변경위와 같이 설정해두면 CRLF로
13.EC2 Docker MariaDB CSV 파일 import
AWS EC2에 Docker로 설치된 MariaDB에 csv파일을 import 시킨다.CyberDuck을 이용해서 윈도우 로컬에서 AWS EC2로 파일 옮기기docker cp /home/ubuntu/stock_datas/. maria-db:/ 명령어로 stock_dat
14.2023-04-05
Yahoo Query Open API를 이용해 주식 정보를 수집했다.Python을 이용해서 수집했으며, Pandas를 이용해서 csv파일을 추출했다.csv파일을 데이터 베이스에 적용하기 위해서 pandas의 to_sql을 사용했다.약 1150개의 회사 정보를 수집했다.
15.Returnz 부하 테스트
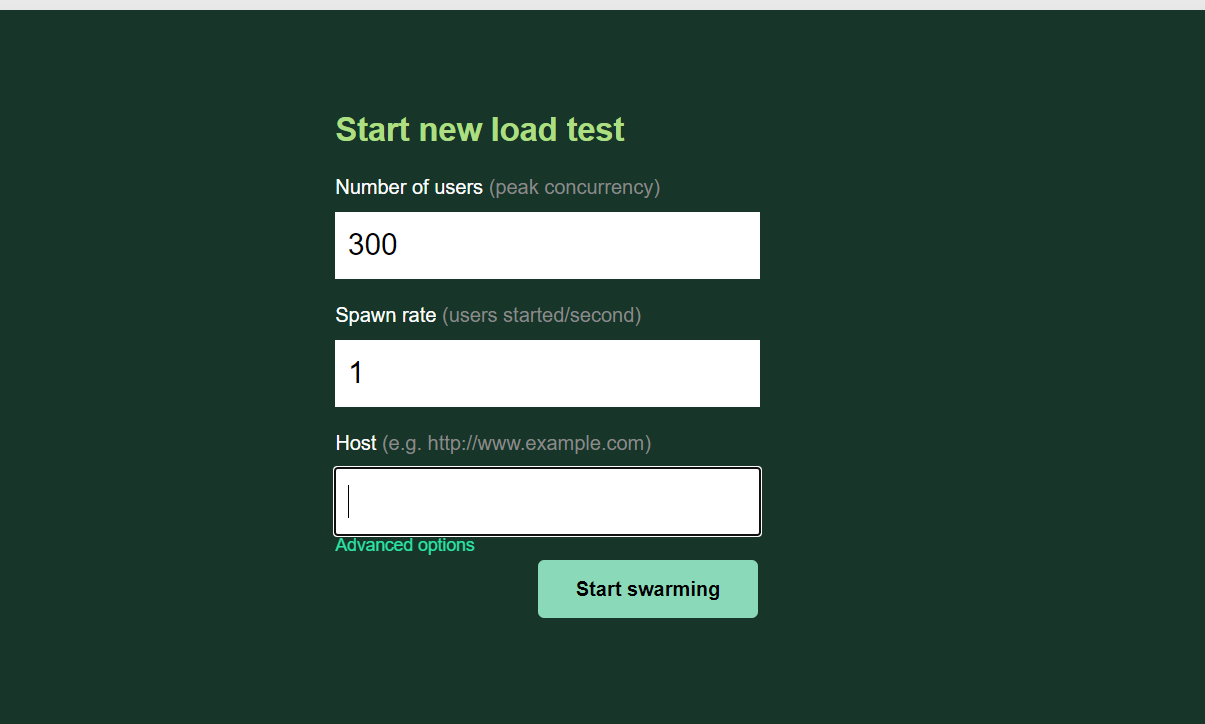
게임방을 미리 생성해둔 채로 진행.닉네임 조회, 게임 생성, 게임 조회를 수행하도록 함.게임방 생성을 계속해서 해줘야 하므로, 한번의 테스트로 Insight를 얻을 수 있도록 Number of Users, spawn rate를 조정게임 방 진행시 가져오는 Data가 많
16.Returnz 부하테스트 2
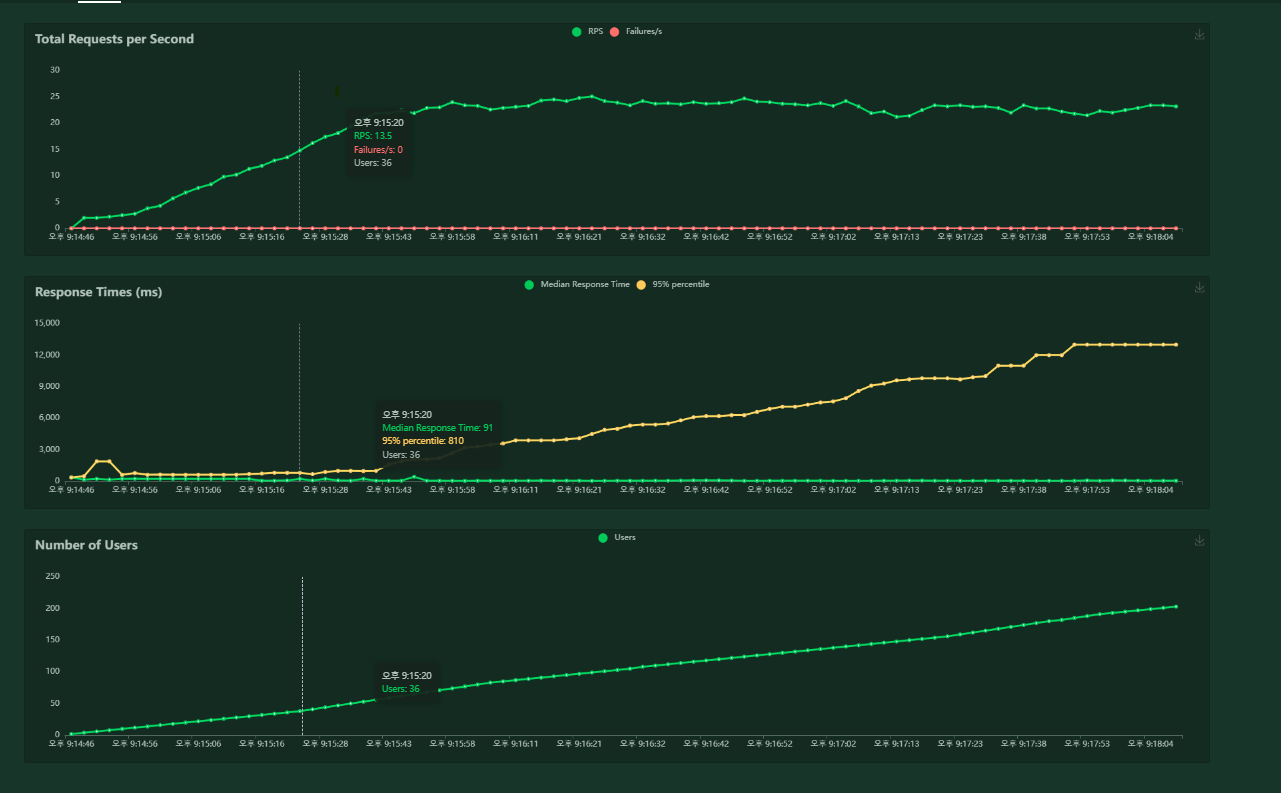
게임 진행 시 턴을 넘기지 않도록 설정하고, 부하테스트를 진행했다.분산 저장을 위해 사용했던 hadoop, spark, zeppeline 등을 stop 시킨 후 진행했다.xeon 2676v3 Siblings : 4RPS는 2295% 4500ms되는 구간의 유저수는 99
17.JPA 제약 조건 수정하기
https://velog.io/@joshuara7235/ISSUEs-JPA%EB%A1%9C-%EC%83%9D%EC%84%B1%ED%95%9C-entity-column%EC%97%90%EC%84%9C-unique-%EC%A0%9C%EC%95%BD%EC%A1%B0%EA%B
18.2023-04-18
JPQL, Native Query JPA를 이용할 떄, 쿼리를 이용하기 위한 방법은 JPQL과 Native Query가 있다. JPQL을 사용하게 될 경우 SQL을 추상화 하기 때문에 데이터 베이스 의존도가 낮아진다. 반면 Native Query를 사용하게 될 경우