평가함수
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score, roc_auc_score
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix(y_test, pred) #혼동행렬
accuracy = accuracy_score(y_test, pred) #정확도
precision = precision_score(y_test, pred) #정밀도
recall = recall_score(y_test, pred) #재현율
f1 = f1_score(y_test, pred) #F1점수
print("Confusion Matrix:\n", confusion)
print("Accuracy: ", accuracy)
print("Precision: ", precision)
print("Recall: ", recall)
print("F1 Score: ", f1)
모델을 평가하기 위해 찾아보니 위와 같은 경우가 많았다.
뭐가 뭔지 하나씩 뜯어보겠다.
혼동행렬
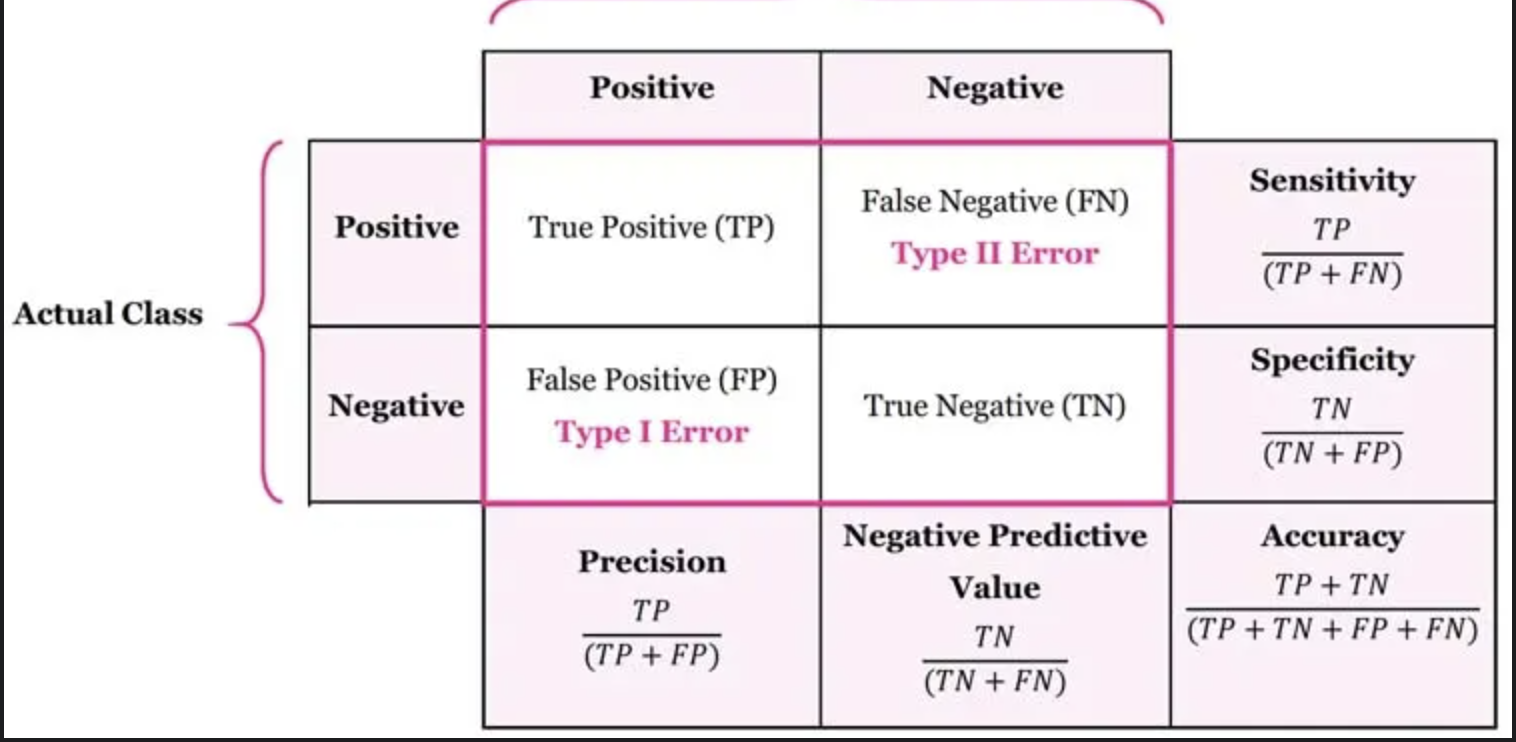
어떤 개인이나 모델, 검사도구, 알고리즘의 진단·분류·판별·예측 능력을 평가하기 위하여 고안된 표
코로나 19를 주제로 하여 예를 들어 보자. 어떤 사람이 코로나 감염이 의심되어 검사를 했을 때, 검사 결과는 양성 혹은 음성으로 나올 것이다. 여기서 양성이 나왔다는 것은 그 사람이 코로나에 감염되었다고 예측한다는 의미이고, 음성은 코로나에 감염되지 않았다고 예측한다는 의미가 된다. 문제는 현실이 진단 결과와 다를 수 있다는 데 있다. 의료진의 뒷목을 잡게 만드는 상황은 두 가지로, 검사 결과가 양성인데 실제로는 감염되지 않았던 경우, 그리고 검사 결과는 음성인데 실제로는 감염자였던 경우다. 이런 상황들이 많을수록 그 검사 키트는 못 믿을 물건이 되고 만다. 그렇다면 검사 키트를 만드는 업체에서는 이런 두 가지 상황은 최소한으로 줄이면서, 감염자는 정확히 양성으로, 비감염자는 정확히 음성으로 판정할 수 있는 검사 키트를 만들고자 할 것이다.
혼동행렬은 모델의 예측 결과를 실제값과 비교하여 분류 모델의 성능을 평가하는 도구로, 2개의 클래스(양성, 음성)에 대해 4개의 값을 계산한다:
True Positive (TP): 실제 양성 클래스인 데이터 중에서 모델이 양성이라고 예측한 수
True Negative (TN): 실제 음성 클래스인 데이터 중에서 모델이 음성이라고 예측한 수
False Positive (FP): 실제 음성 클래스인 데이터 중에서 모델이 양성이라고 잘못 예측한 수
False Negative (FN): 실제 양성 클래스인 데이터 중에서 모델이 음성이라고 잘못 예측한 수
혼동행렬을 통해 각 클래스에 대해 모델이 어떻게 예측했는지 시각적으로 확인할 수 있다.
출처
https://namu.wiki/w/%ED%98%BC%EB%8F%99%ED%96%89%EB%A0%AC
정확도
정확도는 전체 샘플의 개수들 중에서 얼마나 나의 알고리즘이 정답이라고 예측한 샘플이 포함되었는지의 비율을 의미한다. 예를 들어서, 내 알고리즘이 90% 정확하다면, 100개의 샘플들 중에서 90개만 정확하게 분류 하는 것이다.

높은 정확도는 모델이 잘 작동한다고 판단할 수 있다. 하지만 데이터가 불균형할 경우, 예를 들어 한 클래스의 비율이 매우 높을 때는 정확도가 높아도 모델이 불균형을 잘 반영하지 못할 수 있다. # 이를 샘플링 편향이라 함.
정밀도
정밀도란 모델이 True라고 분류한 것 중에서 실제 True인 것의 비율이다.
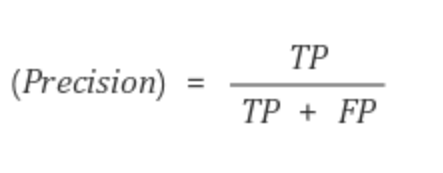
정확도와 정밀도의 차이로는, 정확도는 전체 샘플에 대해서 모델이 올바르게 예측한 비율이고 정밀도는 오로지 양성 샘플에 대해서 올바른 비율로 각자가 대상하는 데이터 범위가 다르다.
Positive 정답률, PPV(Positive Predictive Value)라고도 불린다.
재현율
재현율이란 실제 True인 것 중에서 모델이 True라고 예측한 것의 비율이다.
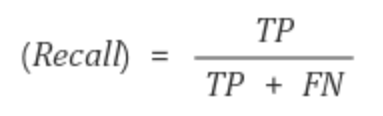
Precision이나 Recall은 모두 실제 True인 정답을 모델이 True라고 예측한 경우에 관심이 있으나, 바라보고자 하는 관점만 다르다. 정밀도는 모델의 입장에서, 그리고 재현율은 실제 정답의 입장에서 정답을 정답이라고 맞춘 경우를 바라보고 있다.
F1 점수
정밀도와 재현율 모두 완벽한 평가지표가 아니다.
F1점수는 어느 한쪽으로 치우치지 않고, 정밀도와 재현율을 결합한 지표이다.
F1 점수는 정밀도와 재현율의 조화 평균으로, 0과 1사이의 값이며 1에 가까울 수록 모델의 성능이 좋다는 것을 나타낸다.
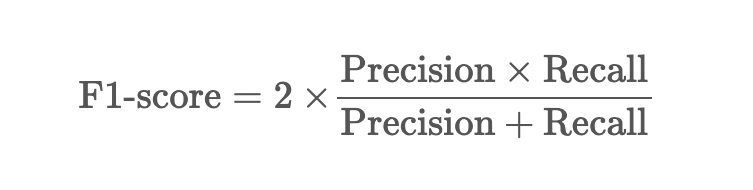

이 글의 F1 점수는 1.00입니다