/ 컬렉션 프레임워크란?
다수의 데이터를 다루기 위한 자료구조를 표현하고 사용하는 클래스의 집합을 의미한다
데이터를 다루는데 필요한 풍부하고 다양한 클래스와 기본함수를 제공하기 때문에 유용!
//컬렉션 프레임워크의 모든 클래스는
Collection interface를 구현(implement)하는 클래스 또는 인터페이스 입니다//
/ 컬렉션 인터페이스와 자료구조
-
List : 순서가 있는 데이터의 집합이며 데이터의 중복을 허용합니다.
→ ArrayList, LinkedList, Stack 등 -
Set : 순서를 유지하지 않는 데이터의 집합이며 데이터의 중복을 허용하지 않습니다.
→ HashSet, TreeSet 등 -
Map : 키(key)와 값(value)의 쌍으로 이루어진 데이터의 집합입니다. 순서는 유지되지 않으며 키는 중복을 허용되지 않고 값은 중복을 허용합니다.
→ HashMap, TreeMap 등 -
Stack : 마지막에 넣은 데이터를 먼저 꺼내는 자료구조입니다. LIFO(Last In First Out)
→ Stack, ArrayDeque 등 -
Queue : 먼저 넣은 데이터를 먼저 꺼내는 자료구조입니다. FIFO(First In First Out)
→ Queue, ArrayDeque 등
/ int VS integer
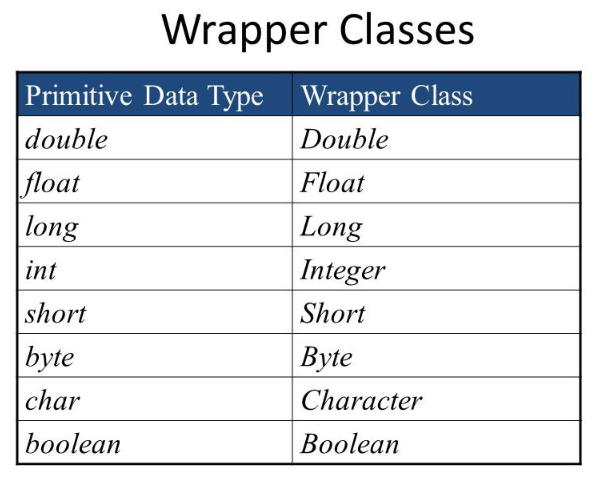
integer는 int의 Wrapper Class 이다
Wrapper Class, 기본자료형을 객체로 다루기 위해 사용하는 클래스
매개변수로 객체를 필요로 할 때/ 기본형 값이 아닌 객체로 저장해야할 때/ 객체 간 비교가 필요할 때
int : 자료형(primitive type)
- 산술 연산 가능함
- null로 초기화 불가
Integer : 래퍼 클래스 (Wrapper class)
- Unboxing하지 않을 시 산술 연산 불가능함
- null값 처리 가능
boxing : primitive type -> wrapper class 변환 ( int to Integer )
unboxing : wrapper class -> primitive type 변환 ( Integer to int )
/ List
순서가 있는 데이터를 표현합니다. 중복허용
-ArrayList는 배열을 이용하여 데이터를 저장하는 List인터페이스이다
(배열은 잘사용하지 않는다, 사이즈가 고정되어야 하기 때문에!)
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Integer> integerList = new ArrayList<>();
// 자료구조를 담는것은 객체이므로 객체를 담을수 있는 타입이어야한다 <Integer>
// 인터페이스인 List ,< primitive 자료형 int의 wrapper 클래스인 integer > 객체이름 integerList =
// 클래스인 Arraylist 공란으로 생성 (추가하면 길이늘어남)
integerList.add(1); // 리스트 .add() 자료 추가
integerList.add(5);
integerList.add(4);
integerList.add(11);
integerList.add(10);
System.out.println(integerList);
Collections.sort(integerList); // 자바유틸컬렉션 .sort() 정렬, 기본설정=오름차순
System.out.println(integerList);
System.out.println(integerList.size()); // 리스트 .size() 길이알려줌
integerList.remove(4); // 리스트 .remove(index) 인덱스번호의 자료 삭제
System.out.println(integerList);
for(int i=0; i<integerList.size(); i++){
System.out.println(integerList.get(i));
// size 이용해 i반복 , 리스트.get(인덱스) 인덱스번째 데이터 추출
}
for(int current : integerList){
System.out.println(current); // int 자료형으로 integer class 의 리스트 반복, 데이터 추출
}
}
}/ Set
순서를 유지하지 않는 데이터의 집합이며 데이터의 중복을 허용하지 않습니다
- HashSet은 Set 인터페이스를 구현한 대표적인 컬렉션입니다
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class Main {
public static void main(String[] args) {
Set<Integer> integerSet = new HashSet<>(); // 왼쪽 Set = 인터페이스 , 오른쪽 HashSet = 클래스
integerSet.add(1);
integerSet.add(1);
integerSet.add(3);
integerSet.add(2);
integerSet.add(9);
integerSet.add(8);
System.out.println(integerSet);
// 결과 : [1, 2, 3, 8, 9] 1이중복 안되고, add한 순서유지 안된다
Set<String> stringSet = new HashSet<>();
stringSet.add("LA");
stringSet.add("New York");
stringSet.add("LasVegas");
stringSet.add("San Fransisco");
stringSet.add("Seoul");
System.out.println(stringSet);
// 결과 : [New York, San Fransisco, LasVegas, LA, Seoul] 순서유지 안된다
stringSet.remove("Seoul"); // 순서가 없기때문에 인덱싱 X, 데이터 지정해줘야함
System.out.println(stringSet); // 결과 : [New York, San Fransisco, LasVegas, LA]
List<String> target = new ArrayList<>();
target.add("New York");
target.add("LasVegas");
stringSet.removeAll(target); // removeAll(컬렉션 타입) , 컬렉션 타입이면 가능 set, list ..
System.out.println(stringSet); // 결과 : [San Fransisco, LA] , 여러개 한번에 지움
System.out.println("LA 포함되어있나요? " + stringSet.contains("LA"));
// 포함여부 확인 set.contains() -> boolean trye/false로 반환
System.out.println("Seoul 포함되어있나요? " + stringSet.contains("Seoul"));
// 결과 : LA 포함되어있나요? true , Seoul 포함되어있나요? false
System.out.println(stringSet.size()); // 결과 : 2 , Set 자료구조 길이
stringSet.clear(); // 자료구조 다지워줌
System.out.println(stringSet); // 결과 : []
}
}/ Map
HashMap은 키(key)와 값(value)을 하나의 데이터로 저장하는 특징을 가집니다.
이를 통하여 해싱(hashing) 을 가능하게 하여 데이터를 검색하는데 뛰어난 성능을 보입니다
import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "apple"); // map은 add아니라 .put(key,vallue)
map.put(2, "berry");
map.put(3,"cherry");
System.out.println(map); // 결과 : {1=apple, 2=berry, 3=cherry}
System.out.println("1st in map :" + map.get(1)); // map은 .get(key) 해야함 value를 리턴,
// 결과 = 1st in map :apple
map.remove(2); // .remove(key) -> 해당 key,value 지워짐
System.out.println(map); // 결과 : {1=apple, 3=cherry}
System.out.println(map.containsKey(2));
// key에 해당하는값 존재유무 True False, 위에서 지웟으므로 결과 : false
System.out.println(map.containsValue("cherry"));
// value에 해당하는값 존재유무 True False, 결과 : true
map.clear();
System.out.println(map); // .clear()로 비워줌 -> 결과 : {}
}
}/ 스택(stack)
스택은 마지막에 저장한 데이터를 가장 먼저 꺼내는 자료구조 입니다
이것을 LIFO(Last In First Out)이라 한다
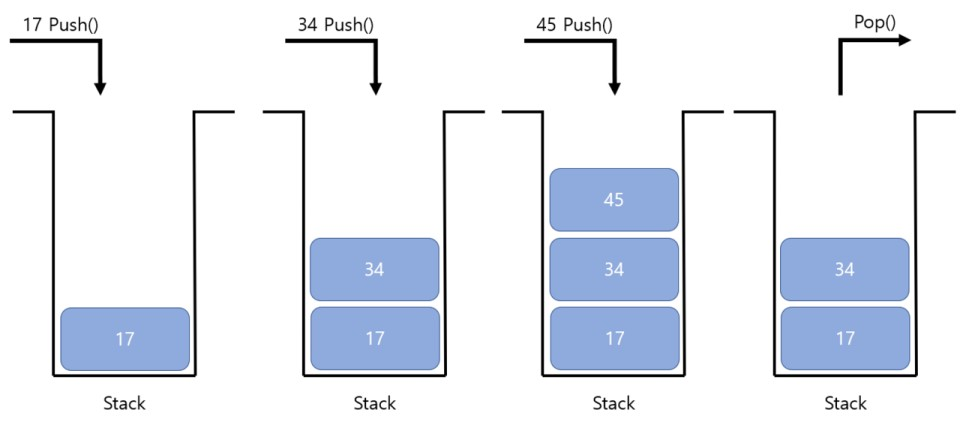
import java.util.Stack;
public class Main {
public static void main(String[] args) {
Stack<Integer> stack = new Stack<>();
stack.push(1); // stack.push(item) 맨위에 추가
stack.push(3);
stack.push(7);
stack.push(5);
System.out.println(stack); // 결과 : [1, 3, 7, 5]
System.out.println(stack.peek()); // 맨위에꺼 확인 결과 : 5
System.out.println("size: " + stack.size()); // 결과 : size: 4
System.out.println(stack.pop()); // 맨위에꺼 꺼낸다 결과 : 5
System.out.println("size: " + stack.size()); // 결과 : size: 3
System.out.println(stack.contains(1)); // 결과 : true
System.out.println(stack.empty()); // 비엇나? , 결과 : false
stack.clear();
System.out.println(stack.isEmpty()); // empty()랑 같음, 결과 : true
}
}/ 큐(queue)
큐는 처음에 저장한 데이터를 가장 먼저 꺼내게 되는 자료구조
이것을 FIFO(First In First Out)이라 한다
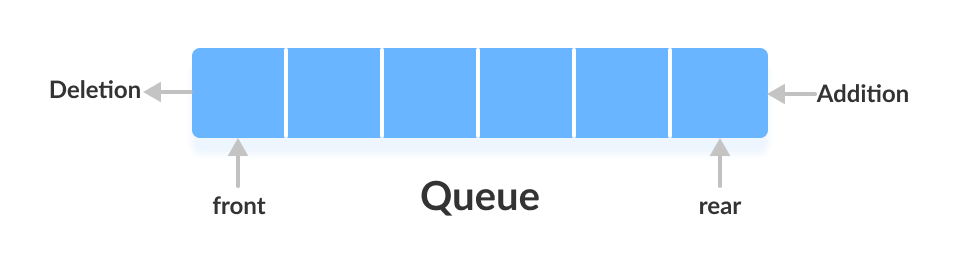
import java.util.LinkedList;
import java.util.Queue;
public class Main {
public static void main(String[] args) {
Queue<Integer> queue = new LinkedList<>(); // 큐 는 구현체 필요하다 대표적으로 링크드리스트
queue.add(1);
queue.add(5);
queue.add(3);
System.out.println(queue); // 결과 : [1, 5, 3]
System.out.println(queue.poll()); // 맨앞꺼 빼내고 return , 결과 : 1
System.out.println(queue); // 결과 : [5, 3]
System.out.println(queue.peek()); // 맨앞꺼 조회만, 결과 : 5
System.out.println(queue); // 결과 : [5, 3]
// clear() , empty() 도 스택과 마찬가지로 존재
}
}/ ArrayDeque, 어레이 디큐
실무에서 많이사용 : 기본 Stack, Queue의 기능을 모두 포함하면서도 성능이 더 좋기 때문이죠.
deque의 경우 양 끝에서 삽입과 반환이 가능합니다, 유연성 높다
성능 사용성 모두좋다
import java.util.ArrayDeque;
public class Main {
public static void main(String[] args) {
ArrayDeque<Integer> arrayDeque = new ArrayDeque<>();
arrayDeque.addFirst(1); // 계속앞자리에 넣음, 1앞에 2 , 2앞에 3, 3앞에 4
arrayDeque.addFirst(2);
arrayDeque.addFirst(3);
arrayDeque.addFirst(4);
System.out.println(arrayDeque); // 결과 : [4, 3, 2, 1]
arrayDeque.addLast(0); // 뒤에 넣음
System.out.println(arrayDeque); // 결과 : [4, 3, 2, 1, 0]
arrayDeque.offerFirst(10); // addFirst와 유사하지만 ,
// 큐의 크기에 문제가 생길때 addFirst는 exception이 나지만, offerFirst는 false라는 리턴값을 리턴
System.out.println(arrayDeque); // 결과 : [10, 4, 3, 2, 1, 0]
arrayDeque.offerLast(-1);
System.out.println(arrayDeque); // 결과 : [10, 4, 3, 2, 1, 0, -1]
arrayDeque.push(22);
System.out.println(arrayDeque); // 결과 : [22, 10, 4, 3, 2, 1, 0, -1]
System.out.println(arrayDeque.pop()); // 결과 : 22 , 꺼내서 리턴
System.out.println(arrayDeque); // 결과 : [10, 4, 3, 2, 1, 0, -1]
System.out.println(arrayDeque.poll()); // poll 도 마찬가지로 지원함
System.out.println(arrayDeque); // 결과 : [4, 3, 2, 1, 0, -1]
System.out.println(arrayDeque.peek()); // peek도 지원함 , peekFirst peekLast도 지원
System.out.println(arrayDeque.size()); // 결과 : 6
arrayDeque.clear(); // clear()
System.out.println(arrayDeque.isEmpty()); // isEmpty()
}
}/ 제네릭스(Generics)
다양한 타입의 객체들을 다루는 메소드나 컬렉션 클래스에 컴파일 시의 타입 체크를 해주는 기능을 의미합니다
왜 사용할까?
객체의 타입을 컴파일 시에 체크하기 때문에 안정성이 높아집니다
(의도하지 않은 타입의 객체가 저장되는 것을 막고 잘못된 형변환을 막을 수 있기 때문입니다!)
/ 제네릭스의 형식
public class 클래스명<T> {...}
public interface 인터페이스명<T> {...}
- 자주 사용되는 타입인자 약어
- <T> == Type - <E> == Element - <K> == Key - <V> == Value - <N> == Number - <R> == Result
/ 제네릭스 활용한 예제
... 잘모르겟음 책읽어보고 추가
/ 람다
람다식(Lambda expression)이란?
"식별자 없이 실행 가능한 함수"
즉, 함수의 이름을 따로 정의하지 않아도 곧바로 함수처럼 사용할 수 있는 것입니다. 문법이 간결하여 보다 편리한 방식입니다
람다식이 코드를 보다 간결하게 만들어주는 역할을 하지만 그렇다고 무조건 좋다고만 이야기 할 수는 없습니다
->이유 :
람다를 사용하여서 만든 익명 함수는 재사용이 불가능합니다.
람다만을 사용할 경우 비슷한 메소드를 중복되게 생성할 가능성이 있으므로 지저분해질 수 있습니다.
람다식의 형식
'→'의 의미는 매개변수를 활용하여 {}안에 있는 코드를 실행한다는 것입니다.
[기존의 메소드 형식]
반환타입 메소드이름(매개변수 선언) {
수행 코드 블록
}
[람다식의 형식]
반환타입 메소드이름(매개변수 선언) -> {
수행 코드 블록
}람다 예제
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("korea");
list.add("japan");
list.add("france");
Stream<String> stream = list.stream();
stream.map(str -> str.toUpperCase()) // 대괄호 쓸수있음, map( ) 앞에값을 뒤에값으로 바꿈
.forEach(it -> System.out.println(it)); // forEach 각각하나하나마다 구문을 실행해줘
}
}이중 콜론 연산자
public class Main {
public static void main(String[] args) {
List<String> cities = Arrays.asList("서울", "부산", "속초", "수원", "대구");
cities.forEach(System.out::println);
}
}이중 콜론 연산자는 매개변수를 중복해서 사용하고 싶지 않을 때 사용하곤 합니다
출력결과를 보시면 cities의 요소들이 하나씩 출력 될 것입니다
cities.forEach(System.out::println);
cities.forEach(x -> System.out.println(x));같은 의미이다
