Self-Supervised Leaning with Vision Transformer
1. Multi-level Contrastive Learning for Self-Supervised Vision Transformers
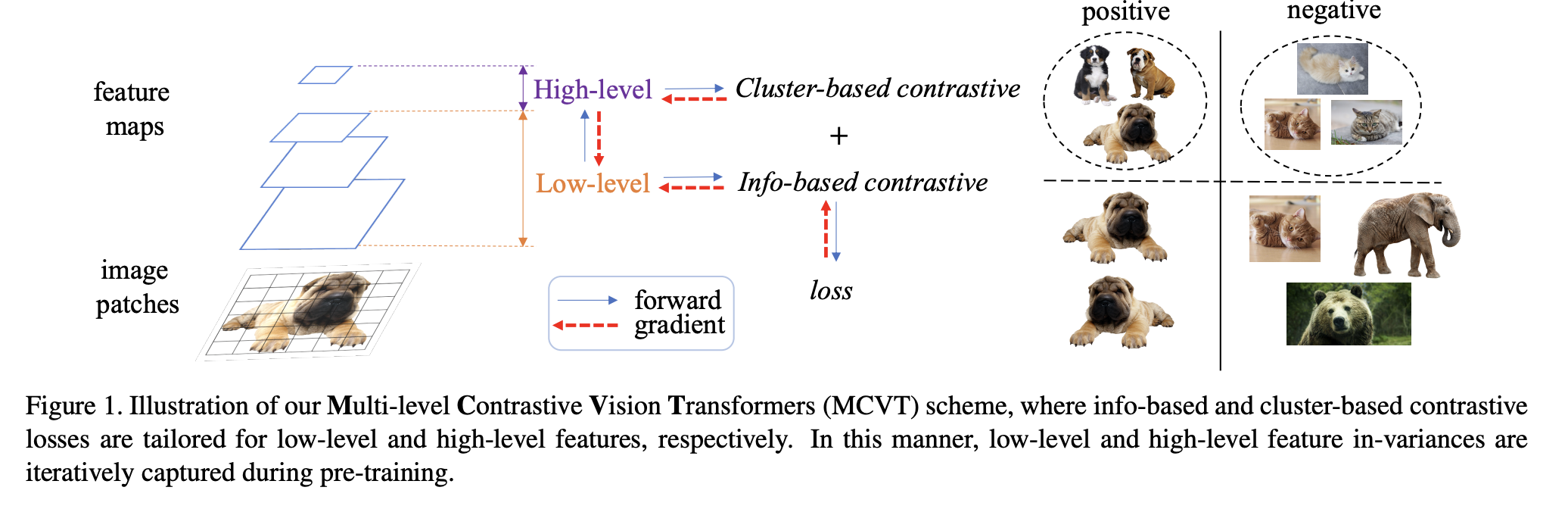
Multi-level Contrastive Learning for Self-Supervised Vision Transformers
ViT 와 CNN 의 가장 큰 차이점은 전체를 본다는 것과 주변만을 본다는 것인데요,
ViT 외에도 대조 학습은 최근 또 다른 인기 있는 연구 주제로, 이전의 대조 학습 (contrastive learning) 작업은 대부분 CNN을 기반으로 진행하였으나, 최근 일부 연구에서는 향상된 Self-Supervised Learning(SSL)을 위해 ViT와 대조 학습을 결합하려고 시도하였습니다.
ViT와 대조 학습을 합치는 과정에서 대부분 인스턴스 수준의 대조에 중점을 두는데, 이 방식의 문제점은 종종 전역 대조를 간과하고 클러스터링 결과를 직접 학습하는 기능도 부족하다는 점입니다.
이를 고려하여, 이 논문에선 우리가 아는 한 처음으로 이미지 클러스터링 작업을 위한 Transformer와 대조 학습을 통합하는 VTCC(Vision Transformer for Contrastive Clustering) 라는 새로운 심층 클러스터링 접근 방식을 제시합니다. 구체적으로 각 이미지에 대해 두 번의 무작위 확대를 수행하여 두 개의 가중치 공유 뷰(weight sharing view) 를 백본으로 사용하는 ViT 인코더를 활용하였다고 합니다.
ViT의 잠재적인 불안정성(potential instability) 을 해결하기 위해 본 논문에서는 강화된 각 샘플을 패치 시퀀스로 분할하는 컨볼루션 스템(convolutional stem) 을 통합합니다. 이는 patch projection layer의 큰 컨볼루션 대신 여러 개의 작은 컨볼루션을 사용하여 쌓은 구조입니다.
백본을 통해 패치 시퀀스에 대한 특징 표현(feature representation) 을 학습함으로써, 인스턴스 프로젝터와 클러스터 프로젝터는 각각 인스턴스 수준 대조 학습과 전역 클러스터링 구조 학습을 수행하는 데 활용됩니다. 8개의 이미지 데이터 세트에 대한 실험은 최첨단 기술에 비해 VTCC 접근 방식의 안정성과 우수한 성능을 보여줍니다.
Contrastive learning은 SSL에서 매우 자주 쓰이는 방법이다.
매우 간단하기도 하고, 대표적인 embedding vector를 만들어낼 수 있기 때문이다.
2. Emerging Properties in Self-Supervised Vision Transformers
3. Visual Place Recognition task
Visual Place Recognition task 는, 한 장소에 대한 뷰를 다른 시간에 촬영한 동일한 장소에 대한 다른 뷰와 일치시키는 작업입니다. DINO를 활용한 self-supervised Learning 에서 이 task 에서 3위 정도로 높은 성능을 내는 것을 확인해볼 수 있었습니다.
4. Self-Supervised Learning with Swin Transformers
ViT 의 모델 중 하나인 Swin Transformers와 SSL 을 연관지어 발전시킨 논문들이 정말 많았습니다.
Efficient self-supervised vision transformers for representation learning , Self-supervised pre-training of swin transformers for 3d medical image analysis 등 3D 이미지에 사용되거나, represnetation learning 등에도 활용됩니다.
Representation Learning
2021년 논문 중에 가장 많이 보이는 키워드가 Representation Learning 입니다. 특히 GAN, Self-Supervised Learning, Transfer Learning 등에서 자주 보입니다.
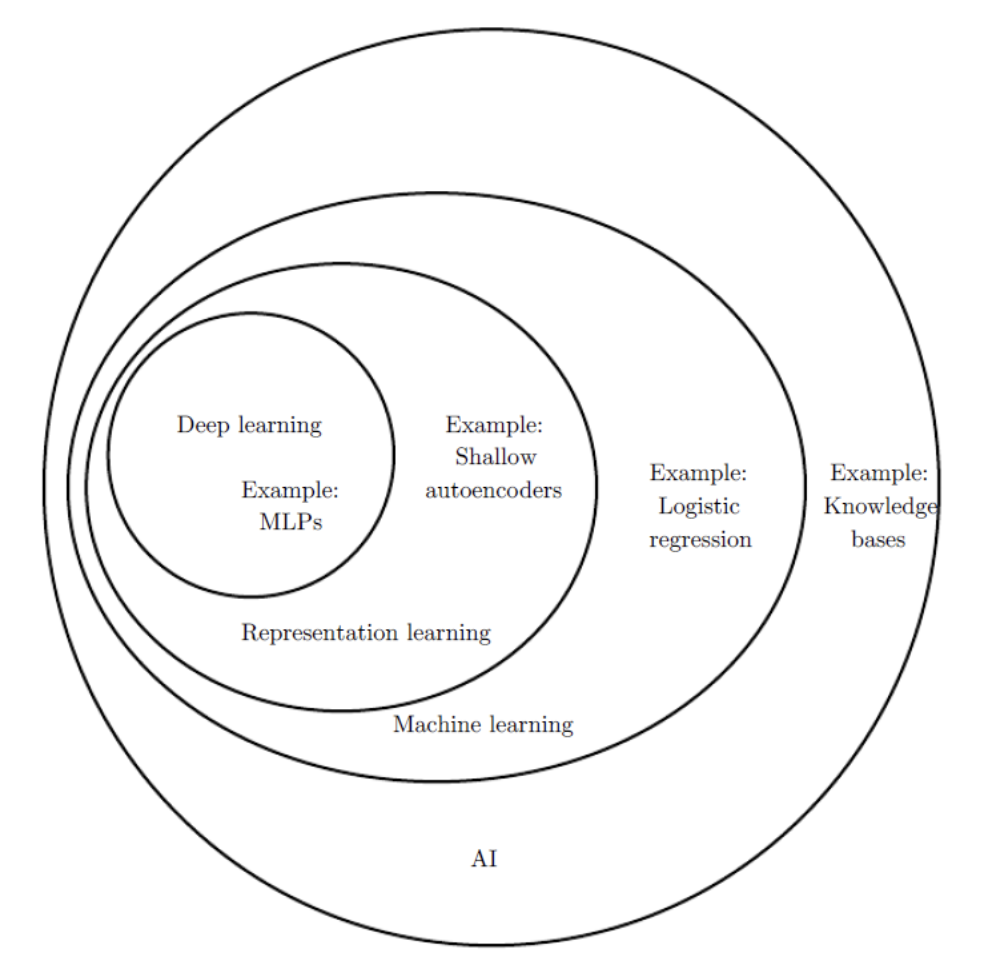
representation learning 은 정보를 어떻게 가공하여 (represenation)표현 하냐에 따라 task를 쉽게 해결하느냐 마느냐를 결정하는데 중요한 학습 방법입니다.
input image 가 conv layer 에 의해 hierarchical feature map 가 만들어진다. task 가 무엇이냐에 따라 ( segmentation, classification 등 ) feature extractor 를 거쳐서 최종적인 feature 가 representation 이 달라지게됩니다.
이렇게 모델에서 최종 task 에 따라서 new representation 에 해당되는 new feature 를 출력하는 것이 (new represenation을 학습하게 하는 것) representation learning 이라고 합니다.
