
Emerging Properties in Self-Supervised Vision Transformers
Introduction
본 논문에서 저자들은 Transformer 모델이 이미지 분류에서 성능이 좋지 않은 이유에 대해 탐구하여, 문제점은 Transformer 모델의 사전 학습에서 지도 학습을 사용하기 때문이라고 결론짓습니다.
이에 대해 이 논문은 NLP에서의 Transformer 모델의 성공 요인 중 하나가 self-supervised pretraining 이었다는 것을 참고하여, computer vision 분야에서도 self-supervised pretraining을 사용하여 성능을 향상시킬 수 있는지를 연구합니다. 이를 위해 이 논문에서는 self-supervised learning을 사용하여 ViT 모델을 학습시키고, 이를 통해 ViT 모델의 특징과 이점을 탐구합니다.
figure 를 참고하여 발견한 내용들에 대해 자세히 이야기해보자면,

Self-supervised ViT feature들은 위의 이미지와 같이 장면 레이아웃(scene layout), 특히 객체 경계(object boundaries)를 명시적으로 포함합니다. 이 정보는 마지막 블록의 Self-attention 모듈에서 직접 접근할 수 있습니다.- Self-supervised ViT feature들은 finetuning, linear classifier, data augmentation 없이 기본 k-NN에서 특히 잘 수행되어 ImageNet에서 78.3%의 top-1 accuracy를 달성하였습니다.
기존의 Self-supervised 방법에서는 segmentation mask 의 출현이 공통 속성으로 나타나는 것으로 보입니다. 하지만 k-NN에서 우수한 성능은 momentum encoder와 multi-crop augmentation과 같은 특정 구성 요소를 결합할 때만 나타난다고 합니다. 또한 ViT와 resulting features의 퀄리티를 개선하기 위해선 작은 패치를 사용하는 것이 중요하다는 것을 발견하였습니다.
이리하여, DINO가 제안되는데요,
위의 구성 요소의 중요성에 대한 발견을 통해 라벨이 없는 knowledge distillation (with no label)의 한 형태로 해석될 수 있는 간단한 self-supervised 방법을 이야기합니다.
DINO(Distillation of Non-contrastive Image representations) 는 self-supervised learning 방법 중 하나로, contrastive learning이 아닌 distillation 기반의 self-supervised learning 방법으로, 이미지의 특징을 추출하는 teacher 모델과 student 모델을 사용합니다.
contrastive learning 이란?
Contrastive Learning (CRL)이란 입력 샘플 간의 비교를 통해 학습을 하는 것으로 볼 수 있습니다. CRL의 경우에는 self-supervised learning(자기지도학습)에 사용되는 접근법 중 하나로, 사전에 정답 데이터를 구축하지 않는 판별 모델이라고 할 수 있습니다. (판별 모델: Discriminative Approach)
DINO에서는 먼저 teacher 모델을 학습시키고, 이를 통해 이미지의 feature를 추출합니다. 그 다음, student 모델을 학습시키는데, 이 때 teacher 모델이 추출한 특징을 distillation을 통해 student 모델에 전달합니다. 이를 통해 student 모델은 teacher 모델이 추출한 특징을 학습하고, 이를 통해 이미지의 특징을 추출할 수 있게됩니다.
자세한 내용들을 확인해보도록하겠습니다.
Related Work
Self Supervised Learning
self supervised learning 방식에 대해 확인해보았습니다. eden 님의 블로그를 잘 참고하였습니다.
Self-supervised learning은 지도 학습과 달리 레이블이 없는 데이터를 사용하여 모델을 학습시키는 방법입니다. 이를 위해 모델은 데이터에서 유용한 feature를 추출하고, 이를 통해 다양한 task를 수행합니다.
DINO 의 방식인 knowledge distillation 에 대해 확인해보면,
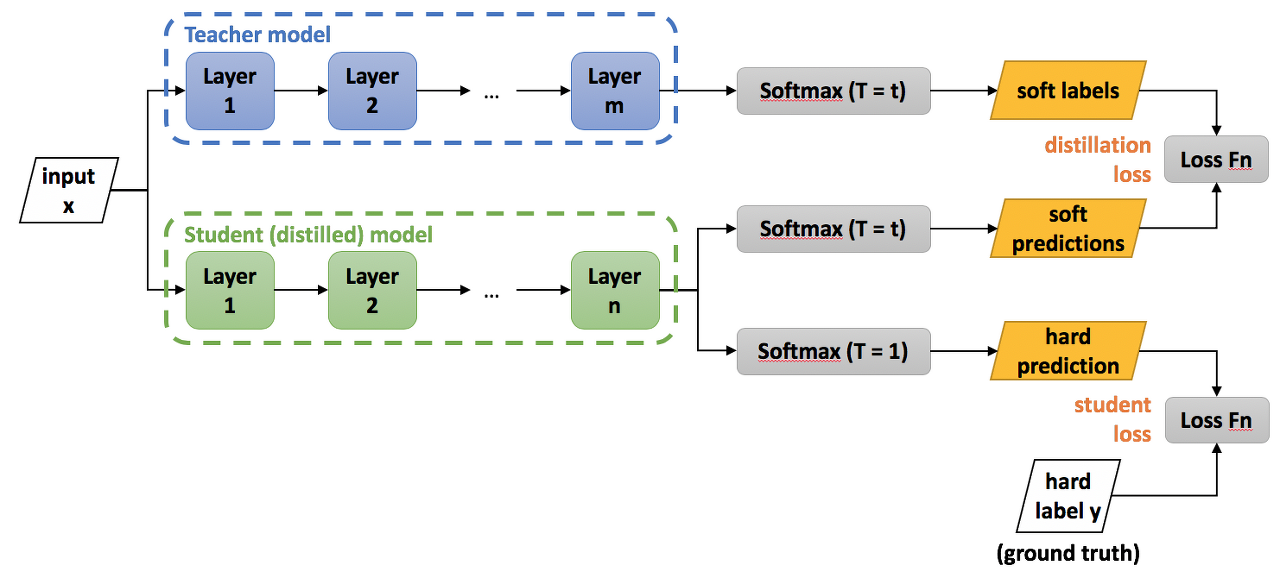
처음으로, Teacher model을 학습하고
다음으로 Student model을 학습합니다. 이때 Teacher 가 Student 에게 knowledge distillation을 적용합니다. 또한 Student model을 학습하기 위해 학습한 Teacher model을 freeze 시킵니다.
이 과정에서 중요한 것은 각각의 loss 인데요, (Distillation Loss와 Student Loss)
- Distillation Loss
Distillation loss는 Teacher model이 가지고 있는 Knowledge를 Student model에게 Distillation을 하기 위한 Loss 입니다. Tempearture hyperparameter로 softning한 각각의 Teacher와 Student의 soft target을 KL divergence Loss를 이용하여 계산합니다. KL divergence로 두 확률분포의 차이를 계산할 수 있기 때문에 Distillation Loss에서 KL divergence를 사용함으로서 Teacher와 Student의 확률분포가 비슷해지도록 학습을 유도합니다.- Student Loss
Student Loss를 계산하기 위해 Cross Entropy Loss를 사용하고 soft targets이 아닌 T = 1인 Hard targets을 사용합니다. Student model는 Distillation Loss를 통해 Teacher model의 knowledge를 전수받고, Student Loss를 통해 더 정확한 값을 학습할 수 있습니다.
Approach : SSL with Knowledge Distillation
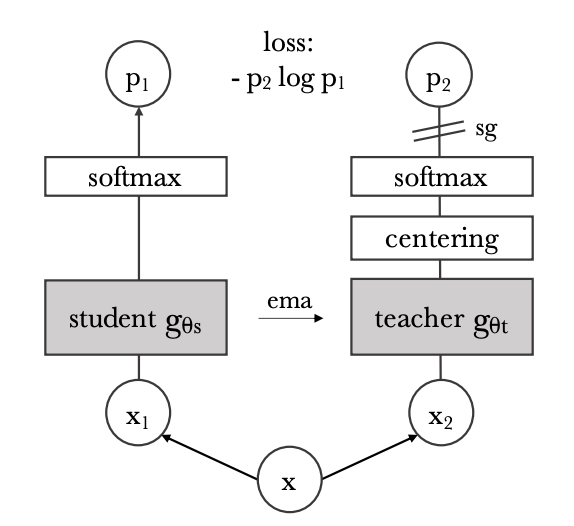
DINO 는 ViT에 SSL(Self Supervised Learning) 을 적용한 논문입니다. DINO 의 pseudo-code 를 보면, 전반적인 flow를 확인할 수 있습니다.

제시된 식을 자세히 확인해보면,
knowledge distillation 은 student network 를 학습할 때 teacher network 와 일치시키는 방식으로 학습됩니다. 이미지 X가 주어졌을 때 두 신경망 모두 K차원의 확률 분포 와 를 출력합니다.
이때 확률분포 P는 네트워크 g의 출력을 softmax function 으로 정규화하여 획득합니다.
도 위의 과정과 동일하게 진행됩니다. 여기서 는 temperature parameter이며 출력 분포의 뾰족한 정도를 조절하는데, 고정된 teacher network 가 주어졌을 때 student network의 파라미터 에 대한 cross-entropy loss 를 최소화하여 두 신경망의 출력 분포를 일치시키는 과정을 진행합니다.
Cross Entropy Loss
DINO 는 SSL에서 사용하는 siam network를 teacher, student 사이의 knowledge distillation으로 해석합니다. 학습으로 인해 성능이 좋아진 teacher의 output을 student가 따라가도록 합니다. 이 둘 사이의 cross entropy 를 사용하여 student 모델을 학습합니다. teacher는 stop gradient를 적용합니다. 위에서 확인한 Student Loss 가 Cross Entropy Loss 입니다.
Multi-Crop Strategy
Multi-crop은 self-supervised learning에서 사용되는 데이터 증강 기법 중 하나인데요, 이는 이미지를 여러 개의 작은 패치로 나누어 각각을 모델에 입력시키는 방법입니다. (이전 논문에서도 augmentation 하는 것과 목적이 비슷)
이 논문에서는 multi-crop을 사용하여 ViT 모델을 학습시키고, 이를 통해 성능을 향상시킵니다. 논문에서는 두 가지 종류의 crop을 사용합니다. 하나는 224x224 크기의 큰 crop이고(global view), 다른 하나는 96x96 크기의 작은 crop입니다(local view). 각 이미지에 대해 두 종류의 crop을 적용하여 총 10개의 crop을 얻습니다.
DINO에서 특이한 점은 하나의 이미지에 224x224 크기로 augmentation 적용한 이미지는 teacher, 96x96 image로 crop되어 augmentation을 적용한 이미지는 student로 전달합니다.
Mean Teacher
Mean Teacher 는 self-supervised learning에서 학습하는 student model의 성능을 향상시키기 위해 사용되는 기술로, 이 기술에서는 student model과 teacher model 두 개의 모델이 사용되는데, Teacher model은 student model의 가중치의 이동 평균으로, 학습 중에 student model에게 soft target을 제공하는 데 사용됩니다.
student model은 teacher model이 제공하는 soft target과의 차이를 최소화하도록 학습합니다. 이를 통해 student model은 더 강한 특징(두드러지는 특징)을 학습하고, unseen data에 대해 더 일반화된 예측을 할 수 있게 됩니다.
Mean Teacher 는 self-supervised learning 모델, 특히 ViT 모델의 성능을 향상시키는 데 효과적이라는 것이 입증되었습니다. 이 논문에서는 Momentum Teacher 라는 Mean Teacher의 변형을 사용하는데, Momentum Teacher는 student model의 가중치의 지수적으로 감소하는 이동 평균을 teacher model로 사용합니다.
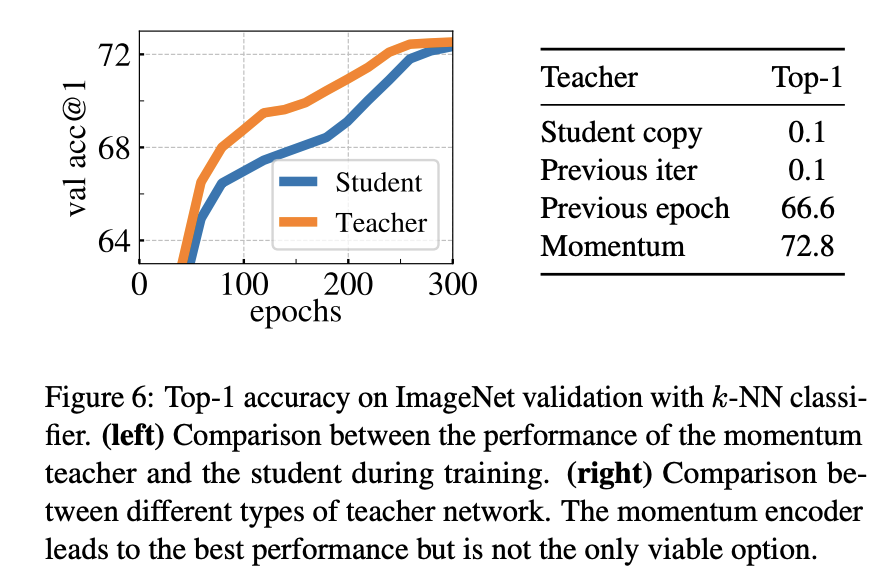
이와 같은 teacher network의 파라미터는 student의 평균이 되는 데 이는 앙상블한 효과를 갖습니다. 논문에서 실험 결과 teacher의 성능이 student보다 높다는 것을 보여줍니다.
Centering 과 Sharpening
자기 지도 학습(self-supervised learning) 에서 ViT 모델의 안정적인 학습을 위해 centering 과 sharpening 이라는 방법을 제안합니다. Centering 은 teacher 네트워크가 생성한 feature 벡터의 평균을 각 벡터에서 빼는 방법입니다. 이를 통해 어떤 차원도 지배하지 않도록 하고 feature 벡터가 더 균일하게 분포되도록 합니다.
Sharpening 은 softmax 함수에 적용되는 온도 매개변수를 조정하여 feature 벡터를 정규화하는 것을 의미합니다. 온도 값이 낮을수록 가장 유사한 feature 벡터에 가장 높은 확률이 할당되는 더 선명한 분포가 생성됩니다. 이를 통해 feature 벡터를 더 구별 가능하게 만들고 학습 중에 쉽게 구분할 수 있도록 돕습니다. (이는 ViT for small datasets에서도 사용한 기법입니다)
Centering과 sharpening의 조합은 서로의 효과를 균형있게 조절하여 모델이 학습 중에 붕괴하는 것을 방지합니다. 이는 논문에서 self-supervised ViT 모델의 학습을 안정화하고 downstream task에서의 성능을 향상시키는 데 효과적이라는 것이 입증되었다고합니다.
Results

정리해보겠습니다.
본 논문에서는 작은 패치를 사용하는 ViT-Base로 80.1%의 top-1 accuracy로 ImageNet linear classification 벤치마크에서 이전의 self-supervised feature들을 넘어버림으로써 DINO와 ViT간의 시너지 효과를 추가로 검증하였습니다.
또한 DINO를 state-of-the-art ResNet-50 아키텍처에 사용하여 DINO가 convnet과 함께 잘 작동되는 것도 확인하였고, 마지막으로 계산 및 메모리 용량이 제한된 경우 ViT와 함께 DINO를 사용하는 다양한 시나리오에 대해 이야기하였습니다. 특히, ViT로 DINO를 학습하는 데 3일 동안 단 2개의 8-GPU 서버만 있으면 ImageNet linear classification 벤치마크에서 76.1%를 달성할 수 있다고 한다.
먼저, 논문은 Vision Transformer(ViT)에서 자기 지도 학습(self-supervised learning)의 고유한 이점과 합성곱 신경망(convnet)과의 비교를 다룹니다. 이 논문에서는 self-supervised ViT feature가 시맨틱 구조에 대한 명시적인 정보를 포함하고 있으며, 이를 통해 비지도 객체 분할을 이끌어낼 수 있다는 것을 발견합니다.
이 논문에서는 DINO, BYOL, MoCo 등의 여러가지의 self supervised learning framework를 사용하여 이미지 분류, 객체 검출, 시맨틱 세그멘테이션 등의 다양한 downstream task에서 성능을 평가합니다.
결과적으로, self-supervised ViT 모델이 대부분의 task에서 convnet보다 우수한 성능을 보이며, 특히 작은 데이터셋에서 fine-tuning을 수행할 때 더욱 뛰어난 성능을 보입니다.
또한, 논문에서는 Momentum Teacher라는 새로운 방법을 제안합니다. 이는 Mean Teacher 기술의 변형으로, self-supervised ViT 모델의 학습을 안정화하는 데 효과적입니다. 이 방법은 모델이 학습 중에 붕괴하는 것을 방지하고 downstream task에서의 성능을 향상시키는 데 도움이 된다는 것을 따로 설명하고 있습니다.
각각의 method 를 넣었을 때의 수치를 확인하여 DINO 가 다양한 모델에서 사용될 수 있음을 입증하였던 논문이라고 볼 수 있습니다.
Emerging Properties in Self-Supervised Vision Transformers - 논문 보기
