
Self-Supervised Anomaly Detection : A Survey and Outlook
이 논문에서는 self-supervised anomaly detection에 대한 전반적인 리뷰와 현 방법론들에 대한 비교를 포괄적으로 진행하였습니다. anomaly detection이 어떤 방식으로 SSL 로 학습되고, 각각의 장단점은 무엇인지 파악하려할 때, 확인하기 좋은 논문입니다.
Introduction
처음 Anomaly detection 이 어떻게 시작되었는지를 이야기하고있습니다. 처음에는 Machine learning이 떠오르면서 ML-based model 들이 automatic anomaly detection method에서 인기를 얻게 되었는데요, 대표적으로 Kernel Density Estimation(KDE) , One-Class Support Vector Machine(OCSVM) , Isolation Forests(IF) 등이 있습니다.
하지만 이러한 ML based model 들은 고차원의 데이터들에 적용하는데 있어 성능이 떨어집니다.
따라서 현재, deep learning models 가 다루기 까다로운 방대한 양의 데이터들에 적용하는데 있어서 뛰어난 성과를 보이고 있습니다.
Anomaly detection task는 다른 딥러닝 task 들에 비해서
- training data가 불균형적이고(정상적인 데이터가 대부분이고 비정상적인 데이터가 극소수이기 때문),
- 비정상적인 데이터는 심지어 노이즈로 오염되어있으며,
- 비정상적인 데이터의 종류가 새롭게 계속해서 발견되기 때문에(비정상적인 데이터는 여러 종류일 수 있음)
deep learning 알고리즘이 anomaly detection에서 문제가 발생하게 됩니다. 따라서 성능 제한이 생기고 bottleneck 이 만들어지게 되는거죠.
이러한 anomaly detection 알고리즘에 하나의 구원자가 등장하게됩니다. 그것이 바로 Self-supervised learning이라고 합니다.
SSL은 일반화된 표현을 본래의 task 와 관련이 없는, 대체된 지도학습을 진행한 task의 문제를 해결하여 만들어진 데이터로부터 학습합니다.
이런 학습방식 때문에, SSL은 speech representation learning, visual feature learning, healthcare applications 등에서 좋은 성과를 냈습니다.
Anomaly Detection : Terminology and Common Practice
흔히들 Anomaly Detection(이하 AD)은 일반적인 패턴을 벗어나는 샘플들을 입증하는 모든 알고리즘을 anomaly detection 이라고 부릅니다.
하지만 anomaly detection에서도 여러가지 종류가 존재하는데요,
총 Anomlay Detection, Outlier Detection, Novelty Detection, Out-of-Distribution Detection 이렇게 4가지로 나눠 볼 수 있습니다.
- Anomlay Detection : 동일한 큰 틀에서 다른 카테고리일 때(기준 카테고리를 벗어날 때)를 탐지
- Outlier Detection : 지금까지 등장하지 않았고 앞으로도 등장할 가능성이 없는, 데이터 오염이 발생했을 가능성이 있는 Oulier data를 탐지
- Novelty Detection : 지금까지 등장하지 않았지만 충분히 등장할 가능성이 있는 sample 들을 탐지
- Out-of-Distribution Detection : 큰 틀에서부터 다른 종류의 데이터들을 탐지
이를 그림으로 표현하면 다음과 같이 설명할 수 있습니다.

Types of anomalies
Anomaly detection의 디테일한 종류들을 분류하면 다음과 같습니다.
-
Point Anomalies
기존패턴에서 벗어나는 불규칙한 샘플들을 찾아내는 방식
Individual sample that exhibits an irregularity or deviation from the standard pattern -
Contextual Anomalies
특정 상황을 기준으로 그 상황에서 벗어나는 샘플들을 찾아내는 방식( ex/ 120km 속도가 자전거에서는 비정상적이지만 차에서는 정상적인 케이스인 경우 )
Data point deemed abnormal within a specific context(depends on context) -
Collective Anomalies
작은 단위로 보면 비정상적인 샘플이 아니지만, 큰 그룹으로 묶어 봤을 때 비정상 샘플인 경우를 찾아내는 방식( ex/ 남자의 눈코입을 보면 여자랑 비교했을 때 같은 그룹이지만, 큰 그룹인 사람에서 묶어 봤을 때 남/여가 다른 경우 )
Subset of data points that exhibit collective abnormality when considered in relation to the entire dataset -
Sensory(Low-level) Anomalies
가구같은 것에서 흠집과 같이 텍스쳐나 질감 일부분이 정상이 아닌 것을 찾아내는 방식
The irregularities that occur in the low-level feature hierarchy, such as textures or edges of an image -
Semantic(High-level) Anomalies
고양이를 학습시켰는데 강아지와 같이 기준 정상 샘플을 벗어나는 샘플을 찾아내는 방식(큰 범주인 anomaly detection을 칭하는 케이스)
Samples that belong to a different class compared to the normal data

Self-Supervised for Anomaly-Detection
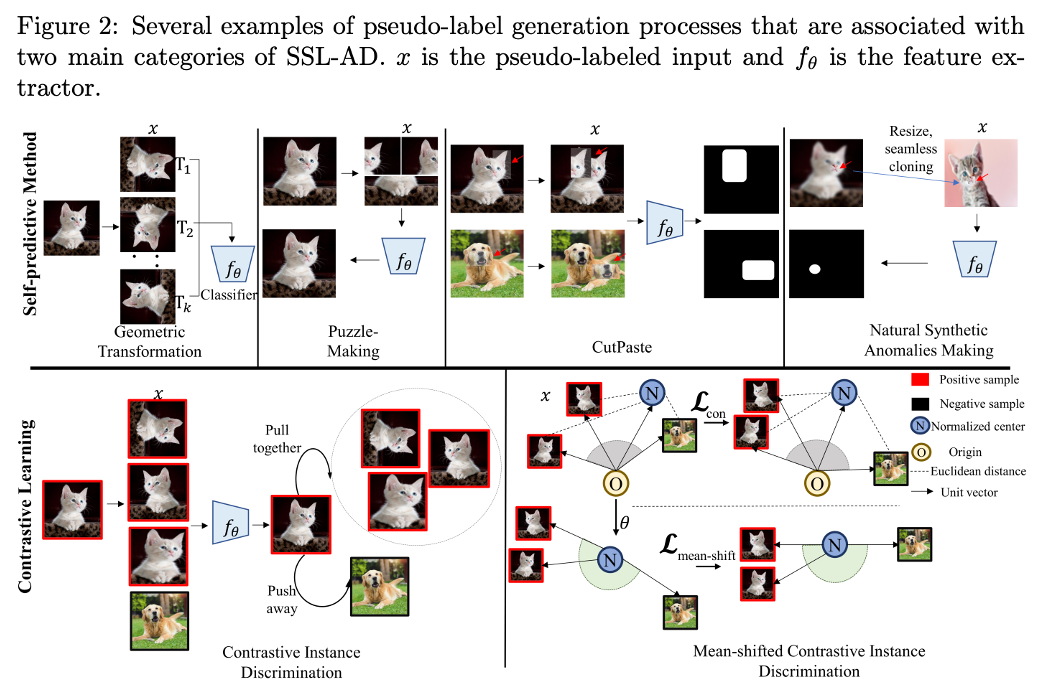
Multi-class anomaly detection, multiple classes in the same datasets are considered normal during training, and one or multiple remaining classes are deemed anomalous
Class-imbalance problem in Supervised & Semi-Supervised Learning
지도학습이나, Semi-Supervised learning 에서는 다중 클래스가 있는 동일한 데이터셋에서는 정상 데이터셋이지만, 그 중 몇개의 클래스가 없는 데이터셋에서는 비정상 샘플이라고 여겨지는 경우가 존재하기도 합니다.
이렇게 라벨이 존재하는 학습을 진행할 경우, 정상 샘플은 무수히 많지만 비정상 샘플이 아주 조금 존재하는 Class imbalance (클래스 불균형) 현상도 문제가 크게 발생합니다.
따라서 현재는 현장에서 쓰일 수 있는 Self-Supervised Learning을 통한 Anomaly detection 연구가 활발히 진행되고 있습니다.
Self-Supervised Learning 에는 크게 두가지 method 가 존재하는데요,
-
Self-predictive Methods: create the pretext task for each individual sample
positive sample, 말하자면 정상 샘플들을 transformation (변형)을 진행하여 in-distribution sample들을 늘려 더욱 강건하게 학습을 진행하는 방식입니다. 다양한 변형을 진행해 정상적인 샘플들을 학습시켜 특징을 더욱 정교하게 추출하는 과정입니다. -
Contrastive Methods: generate positive views of a sample by applying different geometric transformations – pull together the positives while pushing them away from the negative ones
positive 샘플과 negative 샘플을 둘 다 이용합니다. 이미지들을 저차원 인코딩을 시켜 유사한 종류의 이미지들은 공간적 거리를 좁히고, 다른 종류의 이미지들은 거리를 떨어뜨려 특징을 추출하는 학습 방식입니다.
이 두가지 method 방식에는 다음과 같은 종류의 학습 방식이 존재합니다.
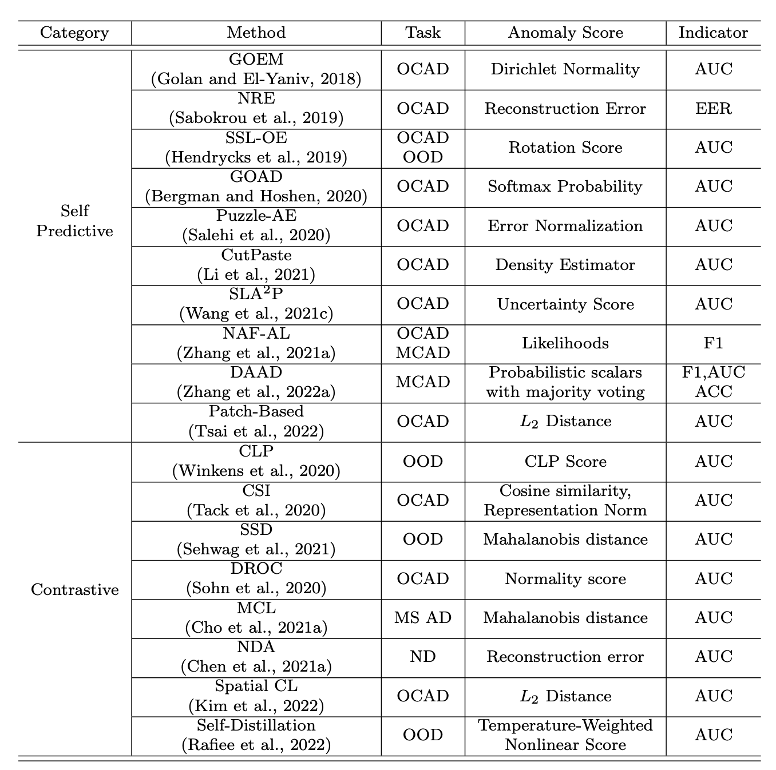
타임라인 순으로 방식들을 확인해볼까요?
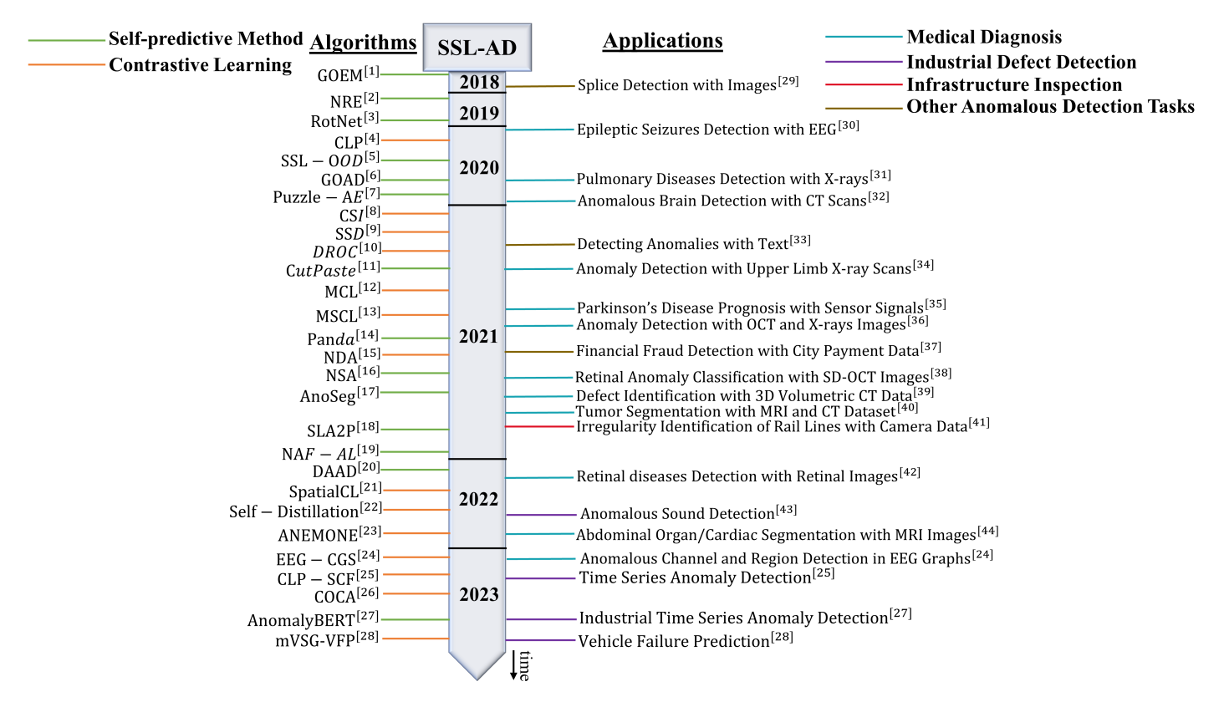
크게 두가지 카테고리로 연구가 활발히 진행되고 있음을 확인할 수 있습니다.
여기서 anomaly score 가 특이한 몇가지 모델들을 확인해보았습니다.
NRE : Deep Anomaly Detection Using Geometric Transformations
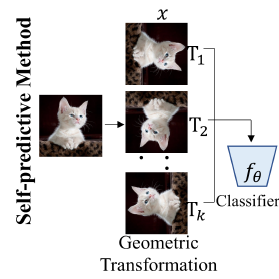
GEO-Transformation 을 이용한 이상 탐지 알고리즘을 제안합니다. 입력 이미지에 대해 flipping, rotation 등의 transformation을 통하여 얻은 self-labeled data를 이용해 일반적인 classifier 를 학습시키고 classifier score 로부터 정상, 비정상 여부를 판단합니다. 이러한 방식은 classifier가 정상 데이터에 대해 geo-transformed 된 이미지를 어떠한 transformation을 적용하였는지 잘 구분하도록 학습하게 된다면 정상 데이터의 도드라지는 공통된 feature 를 얻을 수 있게 될 것이라는 판단에서 시작되었다고합니다.
CutPaste : Self-Supervised Learning for Anomaly Detection and Localization

normal 샘플로부터 anomaly 샘플을 만들어내는 방법을 사용합니다. normal 샘플들을 자르고 붙이는 방법을 사용하여 만들게 되는데요, 직사각형 모양의 patch를 정해서 자른 뒤 위치를 무작위로 선정하여 붙이는 방법을 사용합니다.
그 후 inference process에서 noraml 샘플들의 feature 를 Gaussian distribution으로 가정하여 Gaussian Density Estimation(GDE) 를 사용하여 anomal score를 측정합니다.
Normal 샘플의 feature가 이루는 Gaussian 분포에서 얼마나 떨어졌는지를 바탕으로 Anomal Score를 측정하는 것이죠. Gaussian 분포의 중심으로부터 멀리 떨어져 있을수록 Anomaly라고 판단합니다.
Anomaly Detection with AutoEncoder
오토인코더를 활용하여 이상탐지를 수행하는 과정은 다음과 같습니다.
- 입력 샘플을 인코더를 통하여 저차원으로 압축합니다.
- 압축된 샘플을 디코더를 통과시켜 다시 원래 차원으로 복원합니다.
- 입력 샘플과 복원 샘플의
복원 오차(reconstruction error)를 구합니다. - 복원 오차는 이상 점수(anomaly score)가 되어 threshold와 비교를 통해 이상 여부를 결정합니다.
- threshold 보다 클 경우 이상으로 간주
- threshold 보다 작을 경우 정상으로 간주
이 과정에서 오토인코더는 복원 오차를 최소화하기 위해서 병목 구간(bottleneck)을 지날 때, 최소한의 정보량을 잃기 위해 자동으로 학습될 것입니다.
즉, MNIST의 예로 들면, 주변부의 항상 숫자가 존재하지 않는 뻔한 pixel들은 굳이 기억하지 않아도 될 것이고, 중간 pixel들을 좀 더 효율적으로 기억하도록 할 것입니다.
그럼 비정상 샘플이 테스트 과정에서 주어질 경우, 오토인코더는 주어진 샘플에 대해서 효과적으로 압축과 복원을 수행하지 못하게됩니다. 결국 주어진 샘플들의 특징을 잘 추출해내지 못할 것이므로, 복원 오차(reconstruction error)는 커져서 비정상 샘플로 판별할 수 있습니다.
Self-Supervised Anomaly Detection : A Survey and Outlook - 논문 보기
Anomaly Detection 관련 보기 좋은 블로그 자료

Lowe's is running a customer feedback survey for visitors to its US and Canada stores. Participants will be asked easy questions about their recent visits and will receive a free $500 gift card for taking part. Visit the https://lowescomsurvey.page portal to share your experience.