
Simultaneous Deep Transfer Across Domains and Tasks
Domain adaptation 관련한 논문 중 중요한 기법이 담긴 이번 논문에 대해 공부해보았습니다. 차근차근 확인해보도록합니다 !
2015년도 논문이라, 이 논문에서는 라벨링 되지않거나 뜨문뜨문 라벨링이 되어있는 타겟 도메인 데이터(target domain data) 를 탐지할 수 있는 새로운 CNN 아키텍처를 제안합니다.
이러한 방식은 도메인 불변성(invariance) 을 극대화하여 domain transfer (다른 도메인으로의 전이학습)을 촉진시키고 테스크간의 정보를 전이하려는 loss 값을 매칭시키기 위해서 soft label distribution 을 사용합니다.
- domain transfer 이란?
전이 학습으로, 한 데이터셋으로 학습시킨 모델(pre-trained)을 다른 데이터셋에서 적용시켜 사용하는 방식으로, 흔히 다운스트림(downstream) 이라고 불려 큰 데이터셋으로 학습한 모델을 작은 데이터셋에 사용할 때 많이 씁니다.
- soft label 이란?
원핫 인코딩(one-hot encoding) 과 같이 개, 고양이 중 이미지가 개가 나왔다면 value 를 1 0 으로 주는게 hard label, 개냥이가 나와서 개, 고양이를 0.4 0.6 으로 값을 큰 차이가 나지 않게 주는게 soft label 입니다.
이 논문의 방식은 domain adaptation task 에서 benchmark 를 달성하였으며, 방식이 알아두면 좋아서 자세히 살펴보겠습니다.
Introduction
그 당시 가장 성능이 좋았던 recognition algorithms 은 수백만장의 supervised images 가 초기 학습을 할 때 필요하였습니다.
또한 같은 분야가 아닌 데이터셋을 사용해야하는 경우, 파인튜닝(fine-tuning)을 진행해야했죠. 이러한 불편함을 없애기 위하여 효과적으로 training data 와 target domain data 간의 적용을 하기 위하여
라벨링 되지 않은 타겟 데이터를 사용하여 계산된 marginal distribution을 측정하고, feature representation을 최적화하여 소스 데이터(train data) 와 타겟 데이터 간의 간극을 최소화시켰습니다. 방법은
- 저자는 average output probability distribution을 계산하였습니다. (또는 soft labeling 진행) 소스 데이터(training data)의 각 카테고리마다 진행하였습니다.
- 각 타켓 라벨 샘플에 대해 클래스별 분포를 소프트 라벨과 일치시키기 위하여 우리 모델을 직접 최적화합니다.
이러한 방식으로 타겟 도메인에 명시적인 레이블이 없는 범주 데이터에 정보를 전달하여 task adaptation을 수행할 수 있습니다.
Joint CNN architecture for domain and task
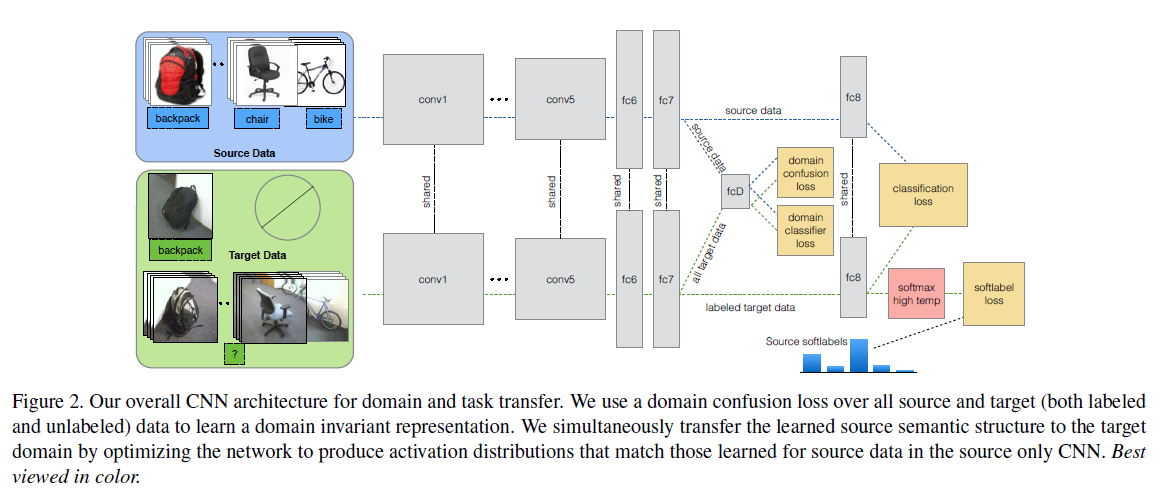
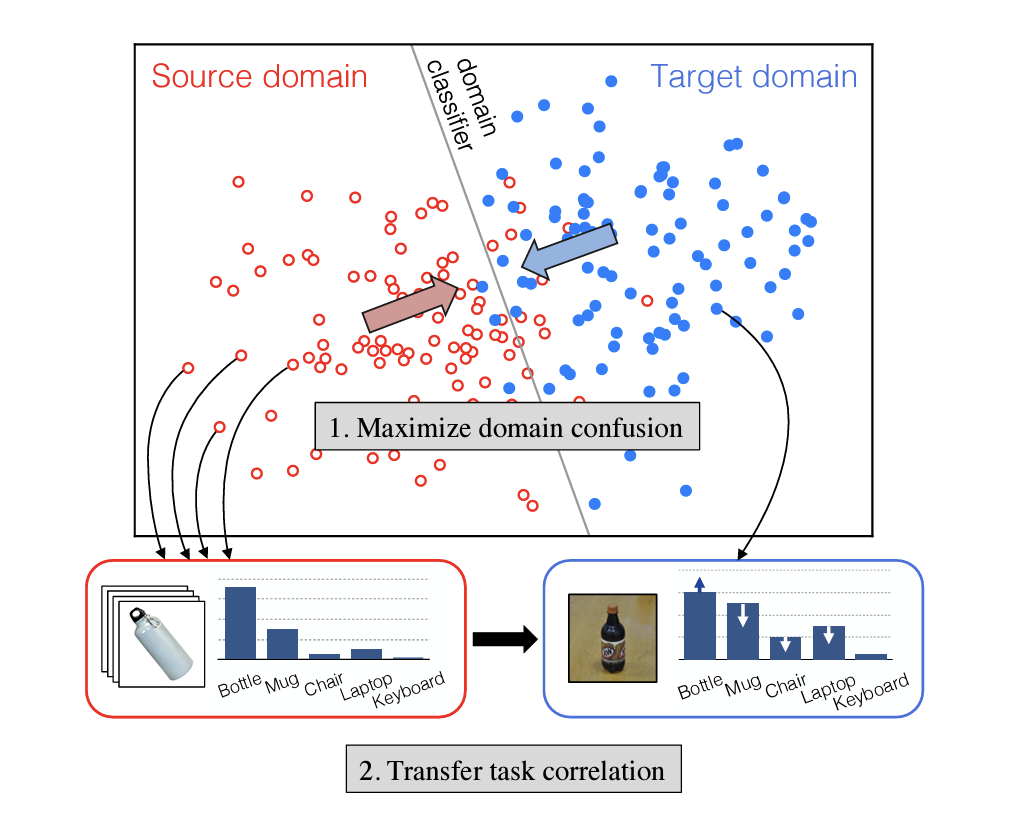
위의 이미지에서 볼 수 있듯이, representation을 학습하는데, visual domain (시각적으로 보이는 도메인 종류)를 정렬하고 (파란색 박스) 잘 분류된 소스 도메인에서부터 뜨문뜨문 라벨링된 타겟 도메인으로 semantic 한 구조를 이동합니다.
여기서 그냥 이동을 진행시키면 효율적이지 않고, 기존의 방식과 동일한데요, 저자는 소스 라벨링된 데이터가 우리의 타겟 도메인의 라벨 공간과 공유하기 때문에, 소스 데이터를 올바른 classifier 의 학습을 지도하는데 사용한다고 합니다.
수식으로 살펴보면, 라벨링된 소스 데이터를 input 으로 여기고, 타겟 데이터를 라 하면, 라벨인 는 오로지 타겟 데이터의 하위 구조만 제공받게 됩니다. 저자의 목표는 category classifier 인 는 image feature representation 을 조절하는데 사용되며, 올바르게 타겟 이미지가 test time 에 classify 될 수 있도록 합니다.
K 카테고리로 세팅되어있기 위해서, 이러한 기존 softmax loss 를 정의합니다
p 는 softmax of the classifier activations 를 나타내며, 로 작성할 수 있습니다.
이런 방식을 사용하게 된다면, 타겟 데이터와 소스 데이터의 라벨 차이에 대해서 크게 영향을 받게 되는데요, 소스 데이터의 라벨들이 타겟 데이터와 비슷하다면, 당연히 성능이 높을 수 밖에 없습니다. 따라서 저자는 새로운 도메인에 대한 domain confusion loss 를 작성하여, representation 능력을 최대화시켜 소스와 타겟 distribution 간 차이를 최소화하였다고 합니다.
Domain confusion 이란?
소스와 타겟의 데이터 분포 차이를 최소화하기 위해서 사용되는 방식. 소스와 타겟 데이터를 나열해서 특징을 학습하는데, 여기서 어떠한 타겟 데이터 중 라벨링된 데이터를 사용하지 않고 학습합니다.
Aligning domains via domain confusion
저자는 이 논문에서 loss 를 고려할 때, domain 에 상관없이 불변하는 (invariant) representation 을 다루고 있습니다. 이 피처는 라벨링된 소스 데이터를 사용하여 분류기를 학습할 때 더 성능을 높힐 수 있습니다. (소스 데이터의 라벨 값에 상관없이 강건한 피처를 추출하기 때문)
이렇게 되면 두 도메인으로부터 구분할 수 없는 피처 값을 학습 시에 사용할 수 있게 됩니다.
마지막 부분에는 , 추가적인 도메인 분류층인 fcD 를 파라미터 와 함께 추가하였습니다. ( 는 particular domain classifier)
이 fcD 층 은 이미지와 그 라벨에 일치하는 도메인을 사용하여 이진 분류를 진행하는 층입니다.
마지막에 fcD층을 넣어 제안하는 loss 값 하나를 계산하게되는데요, maximally confuse 한 (가장 소스 데이터와 타겟 데이터에서 추출한 피처가 비슷해서 도메인을 구분할 수 없는) loss 를 계산합니다. 이는 ouput predicted domain labels 과 uniform distribution over domain labels 사이의 cross entropy 로 계산합니다.
이 domain confusion loss 가 domain 에 불변하는 피처값을 탐색하는 과정이라고 보시면됩니다.
summary - about loss
정리하자면 크게 두가지 Loss 를 제안합니다.
- : 이미지와 라벨이 얼마나 일치하는지 (클래스 분류)
- : 예측한 도메인의 라벨과 정답 라벨 간의 차이 (강건한 피처)
그러나 이 둘의 loss 사이에는 괴리가 존재합니다. 를 최소화시키려면 두 도메인 사이의 두드러지는 피처를 추출해야하기 때문에 가 커지게되고,
를 줄이기 위해 불변한 피처를 추출하여 를 줄이면 두 도메인 간 구분이 어려워져 는 커지게됩니다.
최적의 학습을 위해, 반복적으로 업데이트 하는 방식으로 loss 를 계산하게되는데요,
이 때 loss 에 고정된 파라미터를 넣어서 적절히 조절을 진행합니다. (이 파라미터는 이전의 iteration 으로부터 얻어지는 값입니다)
를 최소화하는 과정 중에는 만 업데이트하고 나머지를 고정시키고,
를 최소화하는 과정 중에는 만 업데이트하고 나머지를 고정시키면서 loss 를 줄이는 학습을 진행하게됩니다.
결과적으로 이러한 loss 를 줄이는 과정은 domain 에 invariant 한 representation을 학습할 수 있게 되죠 !
Aligning source and target classes via soft labels
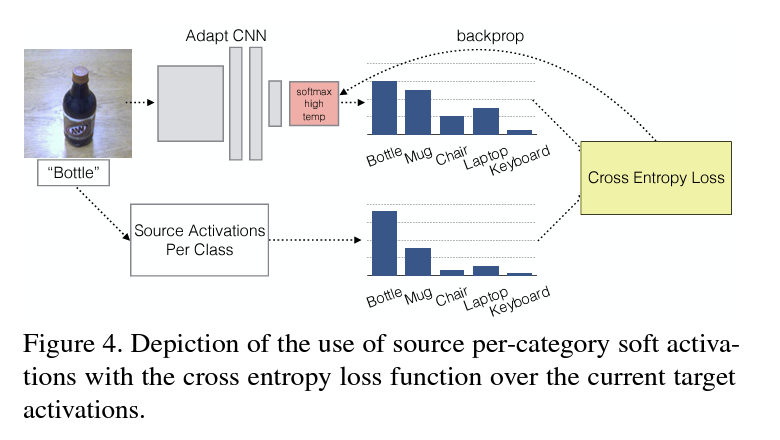
본 논문에서는 각각의 주변 확률 분포를 나열하여 도메인에 따라 구분 할 수 없도록 강건한 피처를 학습하는 네트워크를 제작하였습니다.
marginal distribution : 주변 확률 분포. 두개의 변수로 이루어진 결합 확률분포를 통해 하나의 변수로 이루어진 확률 함수를 구하려 하는 것
하지만 이 방식에는 각 도메인 사이의 클래스 나열 방법이 알맞는가에 대한 확신이 없습니다. 따라서 클래스 사이의 관계가 소스와 타겟 사이에 보존된다는 것을 입증하기 위하여, hard label 을 사용하지 않고 soft label 을 이용하여 fine-tuning 을 진행 합니다.
Soft label loss
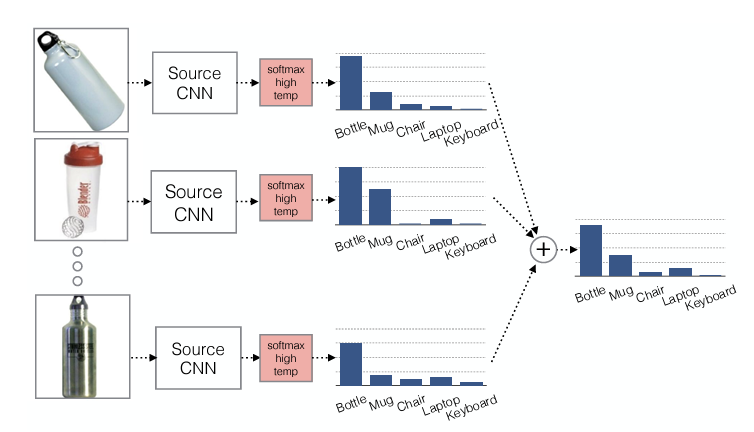
논문에서 soft label loss 를 사용하는 이유를 요약하면 다음과 같습니다.
이미지 분류 학습을 통해 soft label 을 적용하면, 클래스 별로 비슷한 클래스끼리는 feature space 공간이 좁혀지고 (similarity 가 높다) , 완전히 다른 종류의 클래스끼리는 space 공간이 멀어지도록 학습하기 위해서 !!
예를 들면, 학습을 진행하면서 bottle, mug, keyboard 라는 카테고리가 있을 때, hard label로 정답이 bottle 인 이미지를 1 0 0 으로 매기면 각 클래스별로 유사도를 측정할 수 없지만, soft label 로 0.8 0.3 0.1 이 되면 bottle 과 mug 는 유사한 클래스로 학습하게 되고, keyboard 는 다른 종류의 클래스로 학습할 수 있게됩니다.
이렇게 학습을 하게 되면 또다른 이점이 존재하는데요, 타겟 데이터에서 라벨값이 없는 데이터에도 무조건 0으로 책정되는 것이 아니라, 값을 가질 수 있도록 학습할 수 있게됩니다.
Results
결과를 확인해보면, 기존의 방식들보다는 훨씬 더 성능이 오른 모습을 확인할 수 있습니다.
각각의 loss 를 도입하고, fcD층 구조만을 추가적으로 넣으면 모든 model (classifier network) 에서 사용할 수 있다는 이점을 지니고 있습니다.

Limitations
- 본 논문은 domain adaptation 이지만 일단 source data 에 input 값으로 label 과 image 가 들어가야합니다. (supervised & semi-supervised에만 적용 가능)
- target domain 과 source domain 의 세가지 loss 를 계산해야하는데,
첫번째는
domain confusion loss: 라벨링 되지 않은 타겟 데이터를 제외하고, 라벨링 된 타겟 데이터와 소스 데이터의 distribution 차이를 최소화하기 위한 loss 를 계산한다.
두번째는
soft label loss: 소스 데이터를 분류하기 위해 학습된 네트워크에서 soft label activation 을 활용하여 소스 데이터에서 정답에 알맞은 비슷한 라벨들 값은 empathize 하고 정답이 아닌 관련 없는 라벨들은 suppress 하는 값을 계산 한다 .
마지막으로
domain classifier loss: 피처 값에 따라서 학습하려는 이미지가 소스 도메인인지 , 타겟 도메인인지를 판단하여 계산한다.
이렇게 loss 값을 계산하려면 세가지 값이 필요하게 되는데, 가장 중요한 부분은 소스 도메인의 라벨 종류랑 타겟 도메인의 라벨 종류가 같아야 LOSS 가 계산되는데 IMAGENET 과 MVTEC 의 라벨이 완전히 달라서 계산이 불가능하다는 점입니다.
데이터셋의 라벨이 서로 다르면, domain adaptation 기법을 적용할 수 없다는 명확한 한계점이 존재하게됩니다.
