
CBAM: Convolutional Block Attention Module
Introduction
CBAM 은 CNN 네트워크의 단순하지만 효율적인 성능 향상 방식을 제안하는 논문입니다.
일반적으로 CNN 모델의 성능을 향상시키는 방법은 depth, width, cardinality 세 가지 요인이 있습니다.
depth는 층을 의미하고, width는 필터 수를 의미하며 cardinality는 Xepction과 resnext에서 제안된 group convolution에서 group의 수를 의미합니다. 이들을 조정하여 CNN의 모델 성능을 향상시키곤 하였습니다.
CBAM은 위 세가지 요소를 제외하고 attention module 을 사용하여 모델의 성능을 향상시킵니다. channel attention module 과 spatial attention module 로 구성되어 있으며, 각각의 attention module은 채널과 공간 각각에 대한 attention map(무엇을, 어디를 봐야하는지 담겨있는)을 생성합니다.
생성한 attention map을 input feature map 에 곱하여 필요없는 정보는 억제하고 중요한 정보는 강조합니다. CBAM은 무시할만한 작은 연산량으로 CNN 구조에 적용할 수 있도록 설계되었습니다.
CBAM 은
- CNN의 표현 능력을 단순하고도 효율적인 모듈인 CBAM 으로 향상시켜줍니다.
- 넓은 추가적 연구에서 저자의 Attention Module 의 효율성을 입증받았습니다.
- 다양한 벤치마크(ImageNet, COCO, VOC2007 등)에서 다양한 네트워크의 성능 향상을 입증받았습니다.
즉 CBAM은 input feature에서 채널, 공간 정보에 대한 attention map을 생성하여 input feature map에 곱하여 모델이 어디에 집중해야 하는지에 대한 정보를 제공합니다.
channel별 weight를 계산하는 SENet과 공간 픽셀별 가중치를 계산하는 residual attention network의 개념을 함께 사용한 것 으로 생각해볼 수 있습니다.
Convolutional Block Attention Module
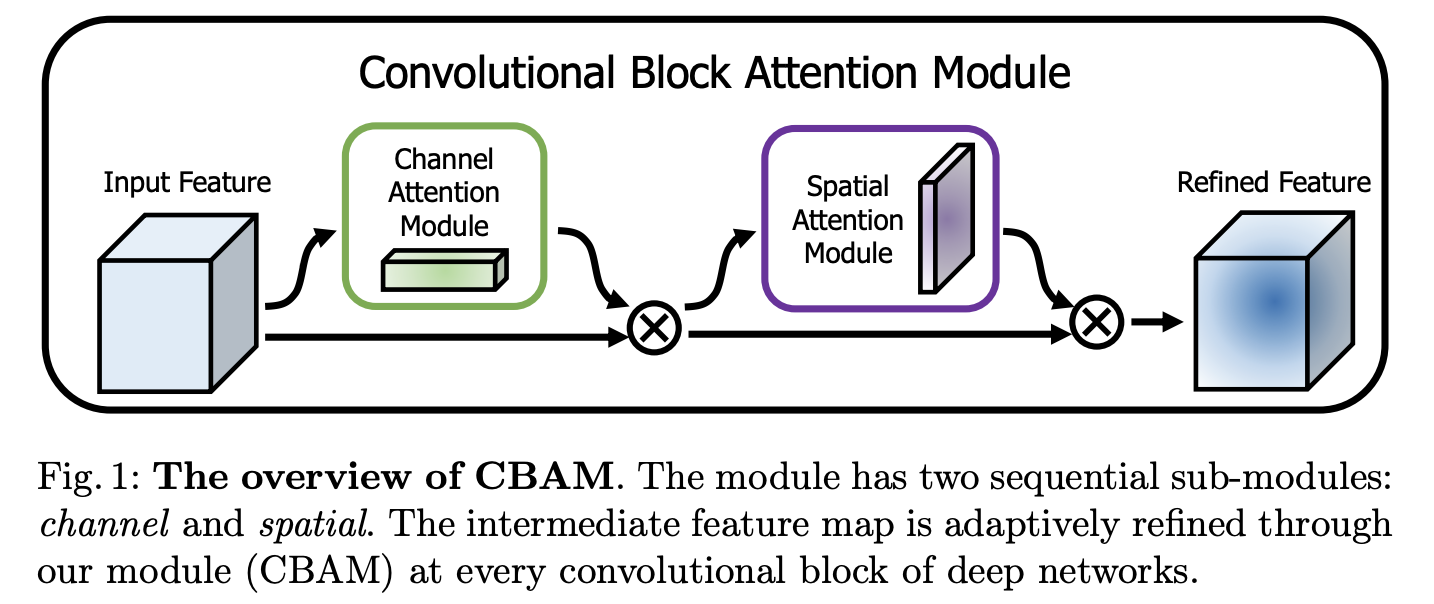
위의 이미지를 확인해보면, CBAM은 channel attention module 과 spatial attention module 로 이루어져 있습니다.
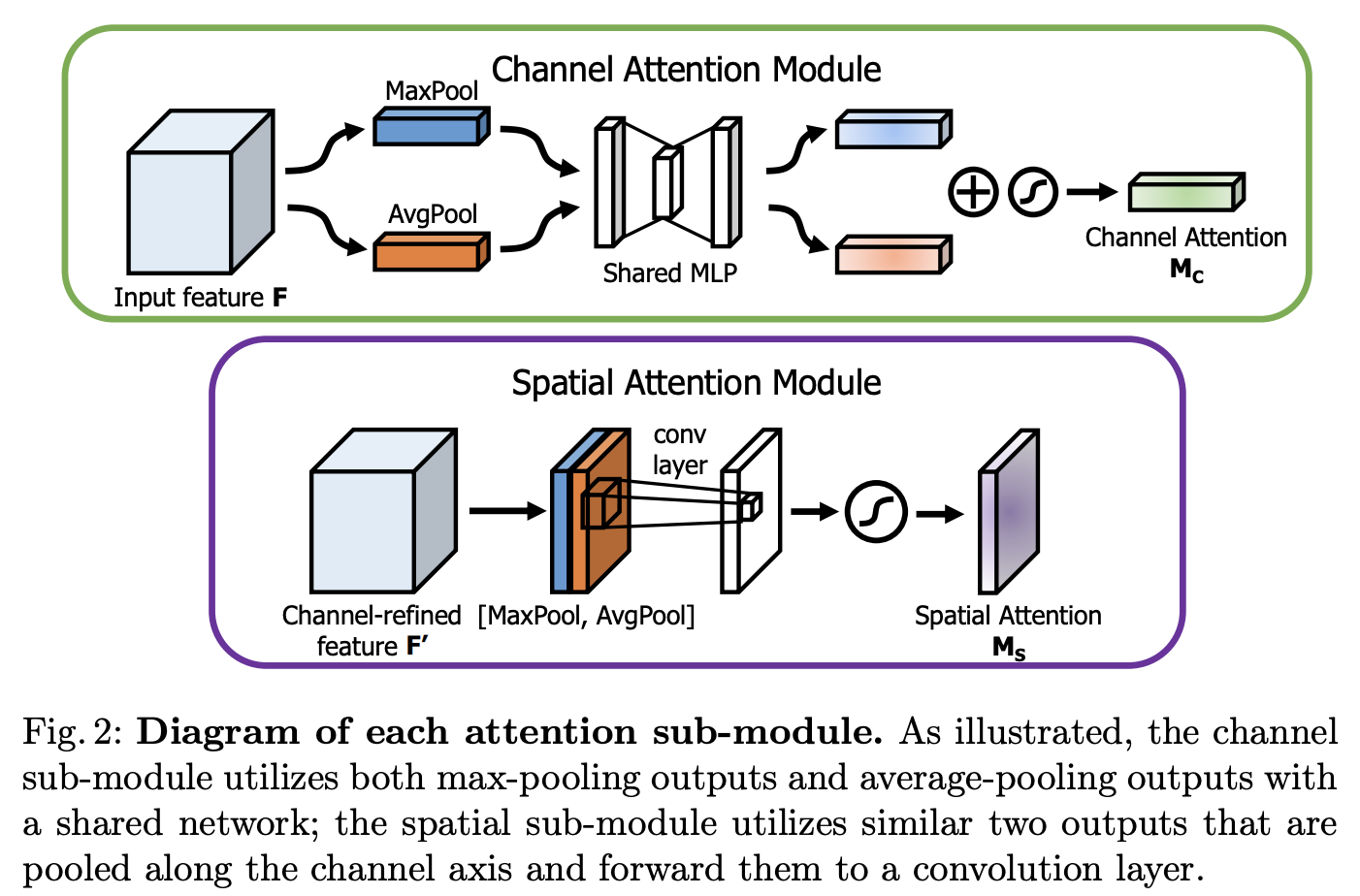
channel attention module 은 input feature 에서 1D channel attention map인 을 생성합니다.
생성한 1D channel attention map 에 input feature을 곱하여 F' 를 생성합니다.
spatial attention module 은 F' 를 입력 받아 2D spatial attention map 인 을 생성합니다.
생성한 2D spatial attention map을 F에 곱하여 F'를 생성합니다.
최종적으로
는 element-wise mulitplication 이고, 이 과정에서 공간 면적을 따라 채널 어텐션 값들이 broadcast 됩니다.
최종적으로 F는 attention이 적용되어 중요한 정보를 강조하고, 불필요한 noise를 억제한 feature map이 됩니다.
Channel attention module
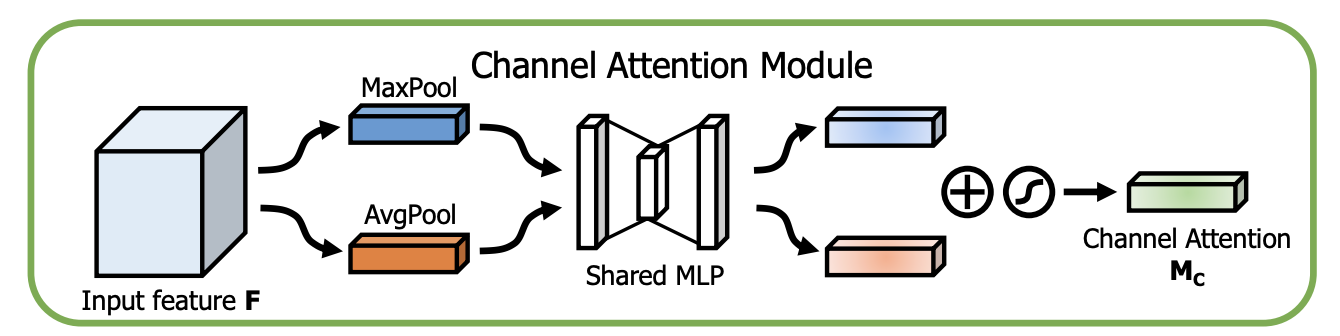
channel attention module 은 input feature F의 내부 채널 관계를 활용하여 channel attention map을 생성합니다.
channel attention module 은 '무엇이' input feature 에서 가장 의미있는 내용인가를 찾는 과정인데요, 여기서 효과적으로 계산하기 위해 input feature map의 spatial 차원을 1x1로 압축 합니다. 즉 가 되는 것입니다.
또한 spatial 정보를 통합하기 위해 average pooling 과 max pooling 을 적용합니다. 두 pooling 을 함께 사용하면 성능 향상 효과를 볼 수 있습니다.
Channel Attention module의 동작 원리는 ave pooling과 max pooling을 모두 사용하여 feature map의 공간 정보를 통합하여 와 를 생성합니다. 각각의 와 를 MLP에 전달하여 각각의 attention map을 생성한 후에 둘을 더해여 최종 channel attention map 을 생성합니다.
계산식은 다음과 같습니다.
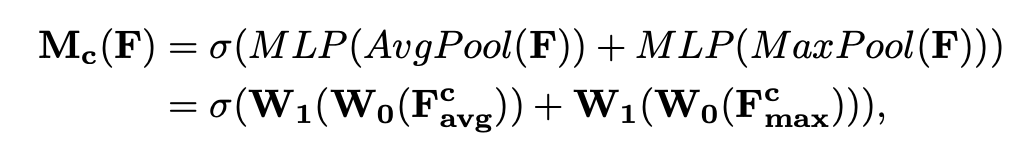
는 시그모이드 함수를 나타내며
를, 을 나타냅니다. ReLU 함수는 를 따라갑니다.
Spatial attention module
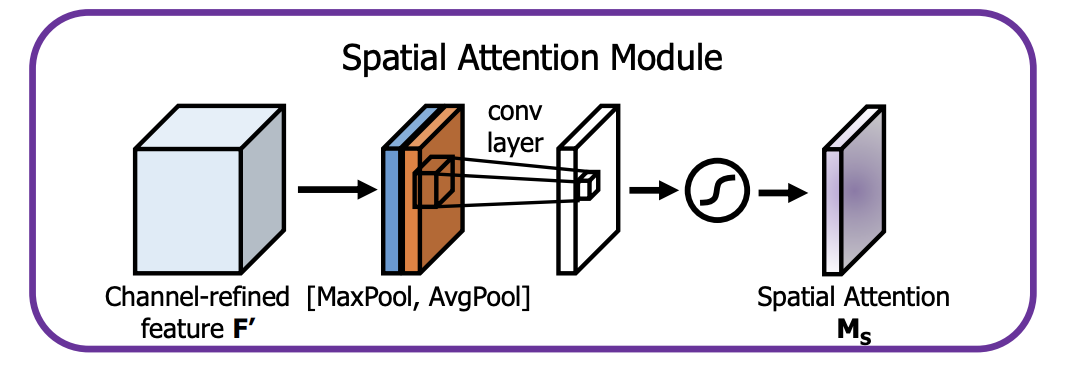
Spatial attention module 은 어디에 중요한 정보가 있는지 집중하도록 합니다.
channel attention map과 input feature map을 곱하여 생성한 F' 에서 채널을 축으로 Maxpool과 Avgpool을 적용해 생성한 의 와 두 값을 concatenate 합니다. ( , )
여기에 7x7 컨볼루션 연산을 적용하여 spatial attention map 을 생성합니다.
계산식은 다음과 같습니다.
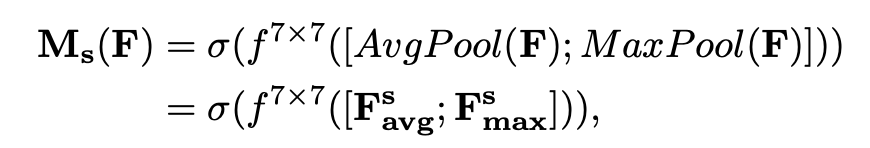
Arrangement of attention modules
두가지 모듈이 존재하기 때문에 놓는 방식을 고려해야하는데요, 병렬적이거나 수평적으로 놓는 방식이 존재하나, 병렬적으로 놓는 방식이 동시에 수행하는 방법보다 더 나은 결과를 보여준다고합니다. 이중에서도 channel module 이 먼저 수행되고 spatial module 이 그 다음 수행되는 것이 조금 더 나은 결과를 보여준다고 합니다.
Results
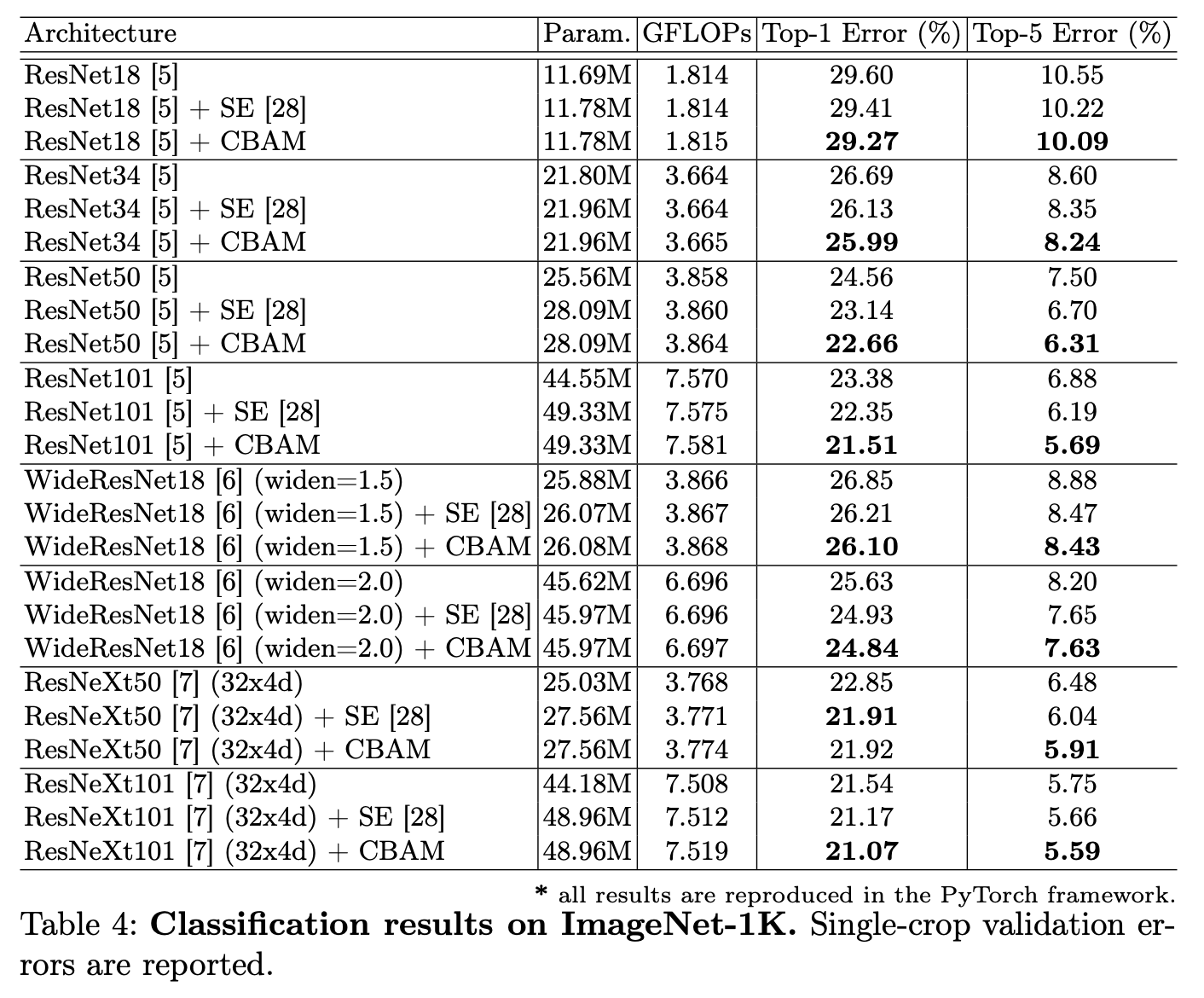
다음 표의 결과를 확인해보면 큰 데이터셋의 다양한 모델 안에서 CBAM 을 사용하였을 때 뛰어난 성과를 보여준다는 것을 확인할 수 있습니다.
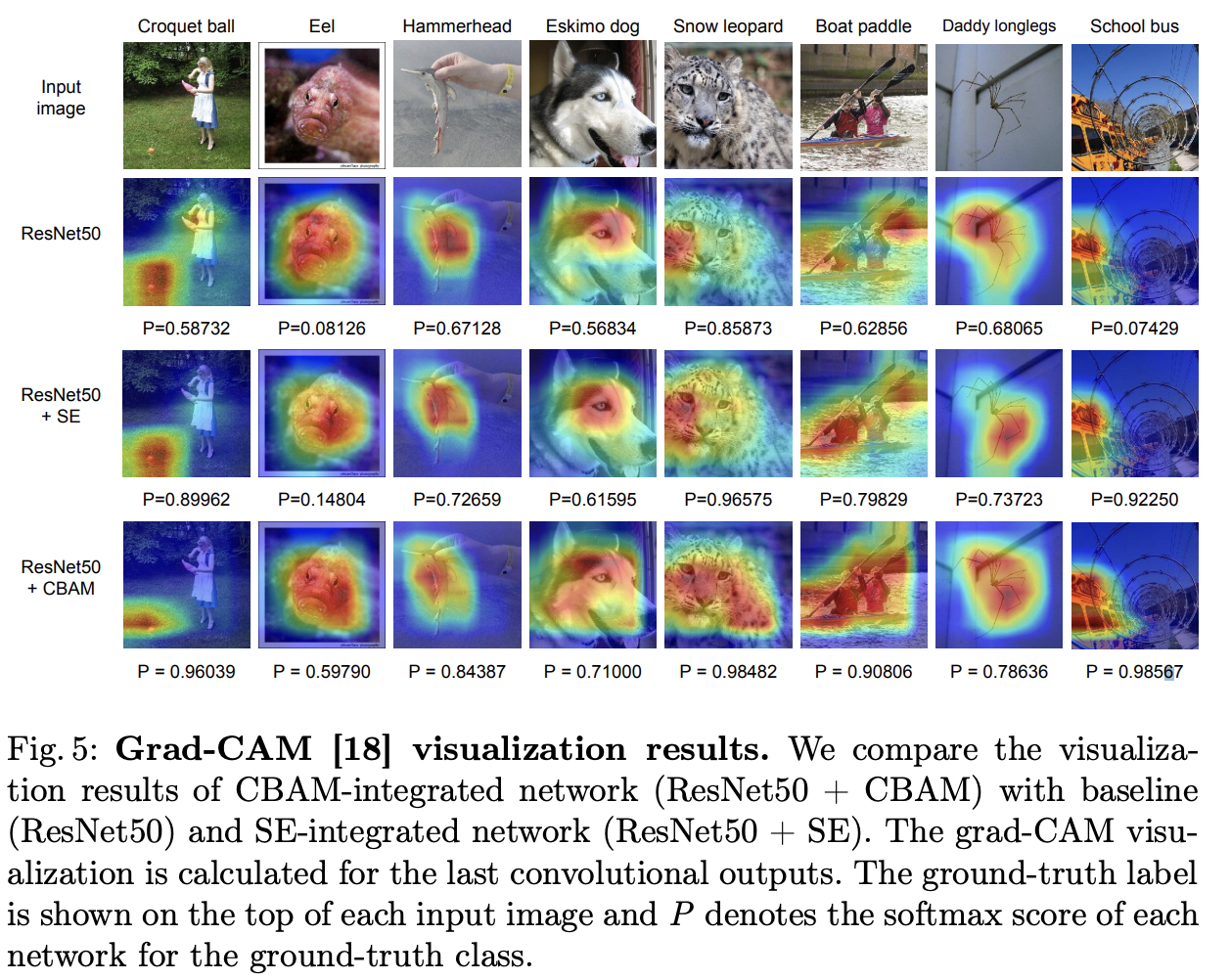
Grad-CAM을 적용하여 visualization을 한 결과를 보아도, CBAM을 통해 모델을 돌린 결과를 확인해보면 객체에 대한 localize 를 더욱 선명하고 정확하게 하는 모습 또한 확인할 수 있습니다.
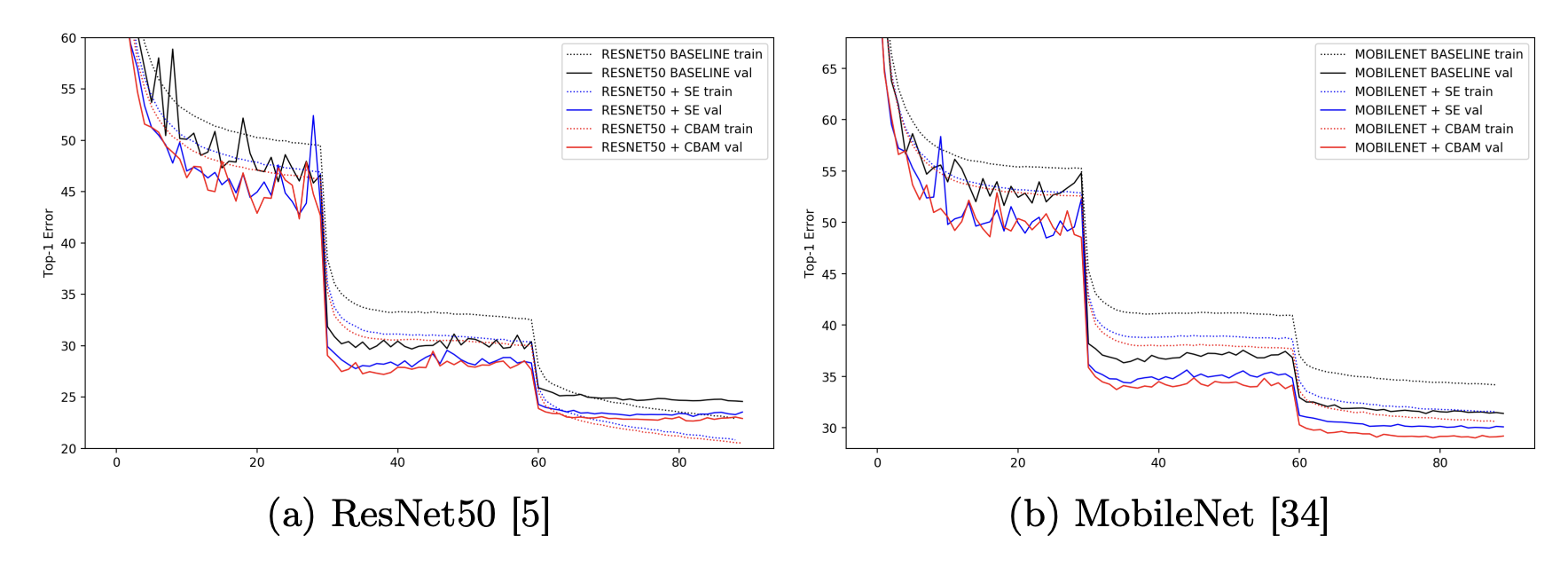
다음과 같은 결과를 보면 CBAM 은 베이스라인의 정확도를 높여주는 것 뿐만 아니라, SE 방식의 performance 를 향상시켜주는 것까지 확인할 수 있습니다.
