
ViTOL: Vision Transformer for Weakly Supervised Object Localization
본 논문에서는 이미지 classification 모델이 object localization 할 때 직면하는 1) 객체를 중요한 부분인 작은 영역만 localization 한다는 문제와, 2) 여러 클래스들이 있을 때 이들을 한번에 highlight 한다는 점, 3) localization을 수행할 때 배경 noise 에 영향을 받는다는 점을 문제로 들고, 이들을 해결하기 위한 ViTOL 방법을 제시하였습니다.
Introduction
이 부분에서는 weakly supervised object localization (WSOL) 문제를 다루고, 본 논문의 모델이 왜 필요한지를 이야기하고 있습니다.
WSOL 은 이미지 분류 모델이 객체를 지역화할 때, 정확한 위치 정보 없이 이미지의 라벨 정보만을 활용하여 학습하는 문제입니다. (다양한 라벨들이 존재하지만, 여기서는 이미지 라벨 정보만을 활용하였다고 합니다.)
이 WSOL 의 task 에는 몇가지 문제가 있는데요,

Highlighting Only Discriminative Regions
기존의 WSOL 에는 객체 중에 가장 두드러지는 부분만 Activate 하는 성격을 가지고 있습니다. 이것이 WSOL 문제점 중 가장 큰 문제점이였죠. 객체 전체를 봐야하는데 일부만을 highlight 하기 때문입니다. (위에서 강아지 열을 보면 문제점을 확인할 수 있습니다.)
Class Agnostic Activation Map
하나의 Activation map 에서는 하나의 객체만을 capture 해야하는데, WSOL 에서는 똑같은 Activation map 에 여러 클래스의 객체가 포착되는 것을 문제점으로 들 수 있습니다.
Background Noise
빛이 번져서 카메라에 빛번짐이 생기는 현상, 물살이 쳐서 물방울 때문에 사진에 흐릿하게 보이는 현상들을 background noise 라고 합니다. 이러한 노이즈들이 꼈을 때 객체를 잘 포착해내지 못한다는 점 또한 WSOL 의 문제점입니다.
이러한 문제를 해결하기 위해 이전 연구에서는 CNN 아키텍처에서의 변화를 도입하였으나, 이 방법들은 여전히 localization accuracy (지역화 정확도) 가 떨어지는 문제가 있었습니다.
따라서 ViTOL 논문에서는 vision based transformer 를 활용하여 이러한 문제를 해결하고자 하였습니다. 이 방법은 이미지를 패치로 나누어 transformer를 적용하며, attention dropout layer와 gradient attention rollout 메커니즘을 도입하여 지역화 정확도를 향상시키는 것이 목적입니다.
ViTOL 에서는 두가지 기능을 추가하였습니다.
patch-based Attention Dropout Layer (p-ADL)
p-ADL 은 attention dropout mechanism을 패치 임베딩 시퀀스에 적용하는 레이어입니다. 이 레이어는 patch importance map과 patch drop mask 두 가지 구성 요소를 가지고 있습니다. 학습 과정에서 이러한 구성 요소는 각각 정보를 highlight하고 discriminative(두드러지는) 패치를 제거하여 모델의 분류 및 지역화 성능을 균형있게 유지하는 데 사용됩니다.
이를 통해 모델은 객체의 전체 영역을 포함하면서도 분류 및 지역화 성능을 향상시킬 수 있습니다.
Grad Attention Rollout (GAR)
Attention rollout 은 각 레이어에서 얻은 attention weight matrices를 재귀적으로 곱하여 attention map을 생성하는 방법입니다.
이러한 방법을 활용하여, 각 attention map에서 계산된 gradient를 사용하여 가중치가 적용된 attention rollout mechanism을 도입합니다. 이를 Grad Attention Rollout 이며, 이 방법은 p-ADL과 함께 사용되어 모델이 각 클래스에 대한 attention map에서 양의 attribute와 음의 attribute를 정량화할 수 있도록 합니다. 이를 통해 모델은 클래스별 attention map을 생성하도록 유도하며, GAR에서 음의 클램핑 작업은 attention map에서의 배경 잡음 효과를 더욱 억제합니다.
Related Work
이 부분에서는 WSOL 에서 성능을 올리기 위한 연구들을 이야기하며 각각의 장단점을 짚어가며 이야기하고 있습니다. ( 제가 여태까지 봤던 모든 WSOL 내용들이 들어있었습니다..)
본 논문은 기존 논문에서 (특히 CNN base) 적용한 기법들을 ViT 에 가져왔다고 봐도 무방할 정도로 잘 적용해서 사용한 내용들에 대해 이야기하고 있습니다.
Method
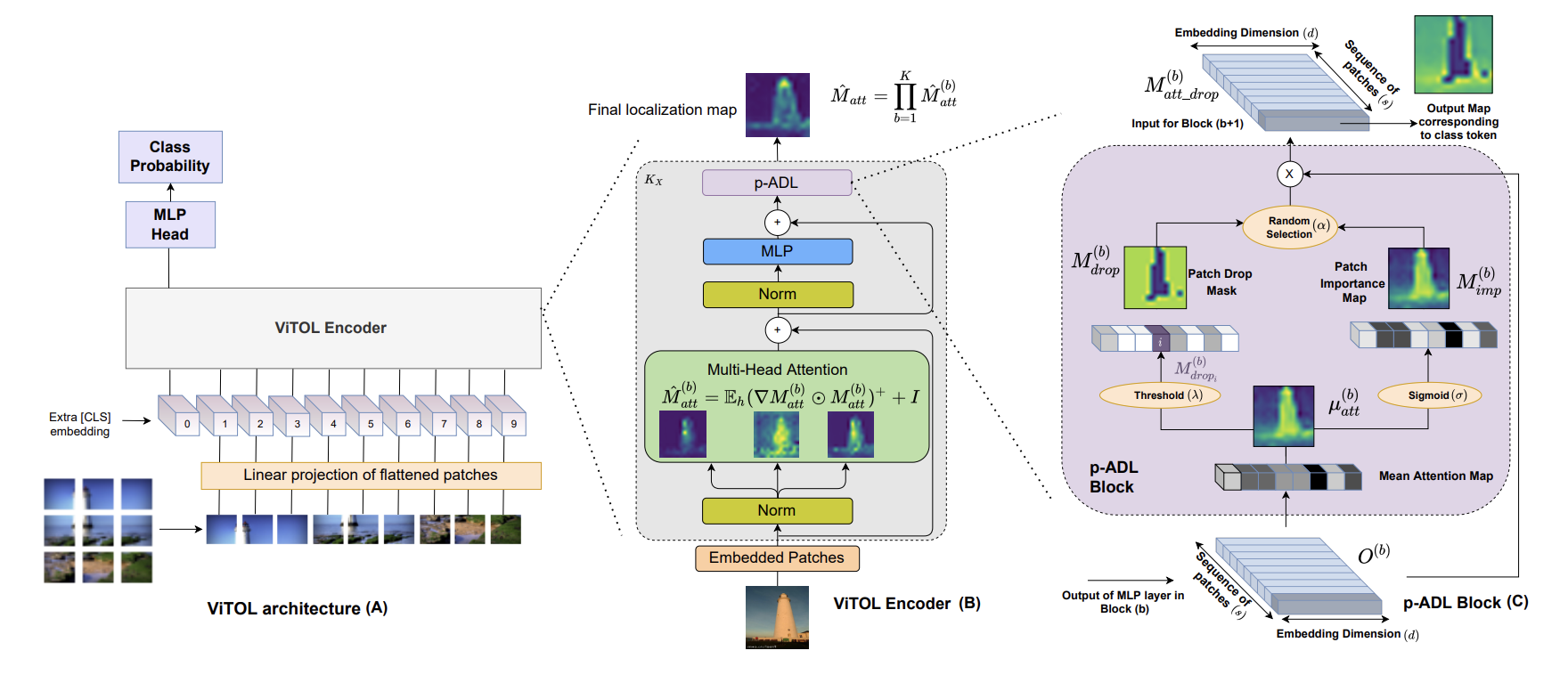
ViTOL 은 크게 두가지로 나눠져있습니다. ( Architectural changes , localization map generation )
Architectural changes
ViTOL은 ViT 에서 patchbased Attention Dropout Layer (p-ADL)를 추가하였습니다. p-ADL layer 는 정규화 역할 을 하며, 네트워크가 객체의 판별적(discriminative, 두드러지는 영역) 및 비판별적인 영역에 모두 집중할 수 있도록 돕습니다. 이는 전체 객체 영역을 커버하므로 localize하는 능력을 크게 향상시킵니다.
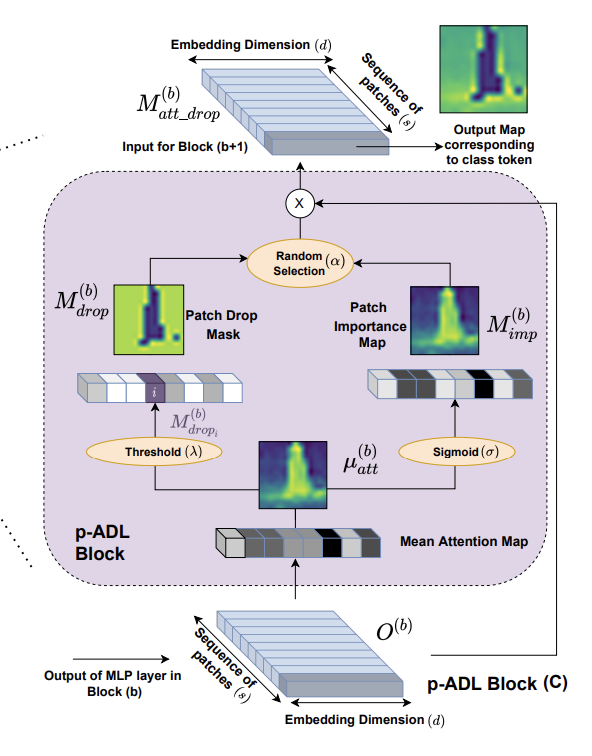
p-ADL 레이어는 patch importance map 과 patch drop mask 두 가지 구성 요소를 가지고 있습니다. 이러한 구성 요소는 average attention map에서 작동하며, 이는 임베딩 차원을 평균하여 계산됩니다. 패치 드롭 마스크는 드롭 임계값 (λ) 매개 변수를 기반으로 가장 활성화된 평균 패치 임베딩을 제거하여 생성됩니다. 패치 importance map은 시그모이드 활성화 함수를 사용하여 평균 attention map을 정규화하여 계산되며, 이는 이미지에서 패치의 중요성을 나타냅니다.
이 레이어에서는 embedding drop rate (α) 매개 변수를 기반으로 패치 중요도 맵 또는 패치 드롭 마스크 중 하나가 무작위로 선택됩니다. 패치 드롭 마스크는 네트워크가 지역화 능력을 향상시키도록 돕습니다. 이는 attention map에서 가장 discriminative한 영역이 제거되어 모델이 원하는 객체의 나머지 영역에 집중하도록 강제하기 때문입니다(위의 그림 참조). 패치 중요도 맵은 classification accuracy를 높혀줍니다. 이는 학습 과정에서 패치 드롭 마스크가 관심 대상 객체의 정보를 제거할 수 있기 때문에 필요하게됩니다.
패치 중요도 맵은 관심 대상 객체에 대한 필요한 정보가 유지되도록 도와주게됩니다. 특히 두 과정 중 새로운 학습 가능한 매개 변수를 도입하지 않는다는 이점도 존재하는데요, p-ADL 레이어에 대한 식을 확인해보면
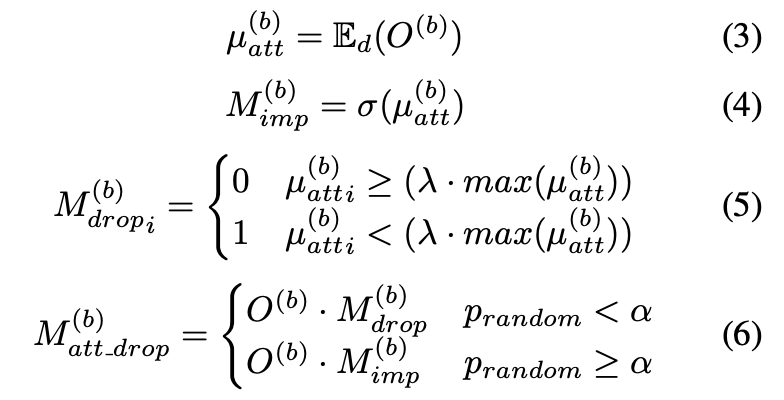
여기서 는 인코더 블록 b에서 출력 패치 임베딩 행렬을 나타내며, 는 임베딩 차원을 따라 평균을 나타냅니다.
는 인코더 블록 b에 대한 평균 패치 임베딩, 패치 중요도 맵, 패치 드롭 마스크를 나타내며, 는 의 i번째 인덱스를 나타냅니다.
s는 입력 시퀀스의 패치 수를 나타내며, 는 인코더 블록 b에 대한 p-ADL 레이어의 출력입니다.
σ는 시그모이드 함수를 나타내며, 은 랜덤 숫자 생성 함수를 사용하여 생성할 수 있습니다.
Patch Drop Mask

쿼리 이미지에 대한 각 인코더 블록 이후 클래스 토큰에 해당하는 패치 드롭 마스크의 출력을 시각화를 진행하는데요, 초기에는 crane의 매우 작은 패치가 활성화되어 Block 1(첫번째 block)에서 패치 드롭 마스크에 의해 제거됩니다.
이러한 정보를 제거하면 모델이 crane의 다른 부분을 탐색하여 올바르게 분류할 수 있도록 제한합니다. 이는 각 인코더 블록(Block 2-5) 이후에 발생하므로 모델이 더 많은 객체 영역을 탐색하도록 합니다. 그러나 각 블록 이후에 점진적으로 모든 정보를 제거하면(Block 5) 객체에 대한 정보가 더 이상 없는 임베딩이 생성될 수 있는데, 이러한 객체 정보의 손실은 객체 분류 오류로 이어질 수 있기 때문에, 이러한 상황을 피하기 위해 패치 중요도 맵도 무작위로 선택되어 활성화된 패치를 강조하고 객체별 정보를 보존합니다.
localization map generation
localization map generation 에서는 grad attention rollout mechanism (GAR) 을 소개합니다. 이를 attention rollout (AR) mechanism 및 layer relevance propagation (LRP) 과 비교하여 클래스별 attention map을 생성하는 데 사용됩니다.
Generation of localization maps
Grad Attention Rollout (GAR)
Attention rollout 은 인코더 블록의 각 어텐션 헤드에서 self-attention map을 averaging하고 모든 트랜스포머 레이어에서 재귀적으로 곱하여 localization map을 생성하는 직관적인 방식입니다.
Rollout은 네트워크의 잔차 연결(residual connection) 을 고려하기 위해 각 레이어에서 attention matrix에 Identity matrix I 를 추가합니다. 이 때, 이 방식은 어텐션이 선형적으로 결합된다고 가정합니다. 과거의 이 방법이 중간 레이어에서 GELU 활성화 함수를 사용한다는 사실을 간과한다고 언급합니다.
이러한 방식은 최종 attention map에 대한 긍정적인 attribute와 부정적인 attribute를 구분하지 못한다는 문제를 가져오는데요, Grad Attention Rollout(GAR) 은 이러한 문제를 해결하기 위해 각 어텐션 맵에서 계산된 그래디언트를 사용하여 가중치가 적용된 attention rollout mechanism 을 도입합니다.
이 방법은 클래스별 어텐션 맵을 생성하고 어텐션 맵에서 백그라운드 노이즈의 영향을 억제하는 음수 클램핑 연산을 수행하여 WSOL에서 성능을 개선하는 데 효과적이라고 합니다.
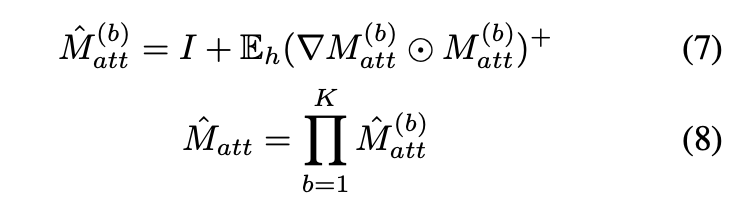
여기서 ⊙는 Hadamard product(아다마르 곱)을 나타내며, 는 헤드 차원을 따라 평균을 나타냅니다. 는 각 어텐션 매트릭스 에 해당하는 그래디언트 매트릭스이며,
K는 인코더 블록의 총 수를 나타냅니다. 는 최종 롤아웃 어텐션 맵입니다. 상위 첨자 + 는 음수 가중치 클램핑 연산을 나타냅니다. 여기서 저자는 피드백에 따라 식을 수정하는데요, deep Taylor decomposition 원리 를 기반으로 지역적인 관련성(local relevance) 을 계산하는데요, 이는 클래스별 시각화를 제공합니다. 최종적으로 다음과 같은 식이 만들어집니다.
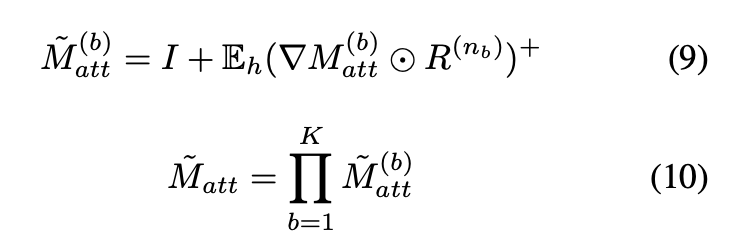
는 인코더 블록 b에서의 softmax 레이어를 나타냅니다. 는 레이어에 대한 관련성(relevance)을 나타냅니다.
는 최종 어텐션 맵입니다. 이 방법에서는 식 8과 10을 사용하여 self-attention map을 계산합니다.
이 방법에서 최종 행렬은 는 (s × s) 크기를 가지며, 이미지의 각 패치가 다른 패치와 Interaction 하는 방식을 나타냅니다. 최종 어텐션 맵을 계산하기 위해 크기가 (1 × s) 인 첫 번째 행만 고려합니다. 이 행에서 첫 번째 값을 무시하여 [CLS] 토큰의 self-attention을 제외하고, 크기가 (s-1)인 추출된 어텐션 임베딩을 크기로 재구성하여 최종 Localization map 을 만들어냅니다.
Results
ViTOL 은 ImageNet-1K 와 CUB200-2011 데이터셋으로 실험을 진행하였으며, MaxBoxAcc-V2 localization score에서 각 데이터셋마다 70.47% 과73.17% 의 성능을 도달하였다고합니다.
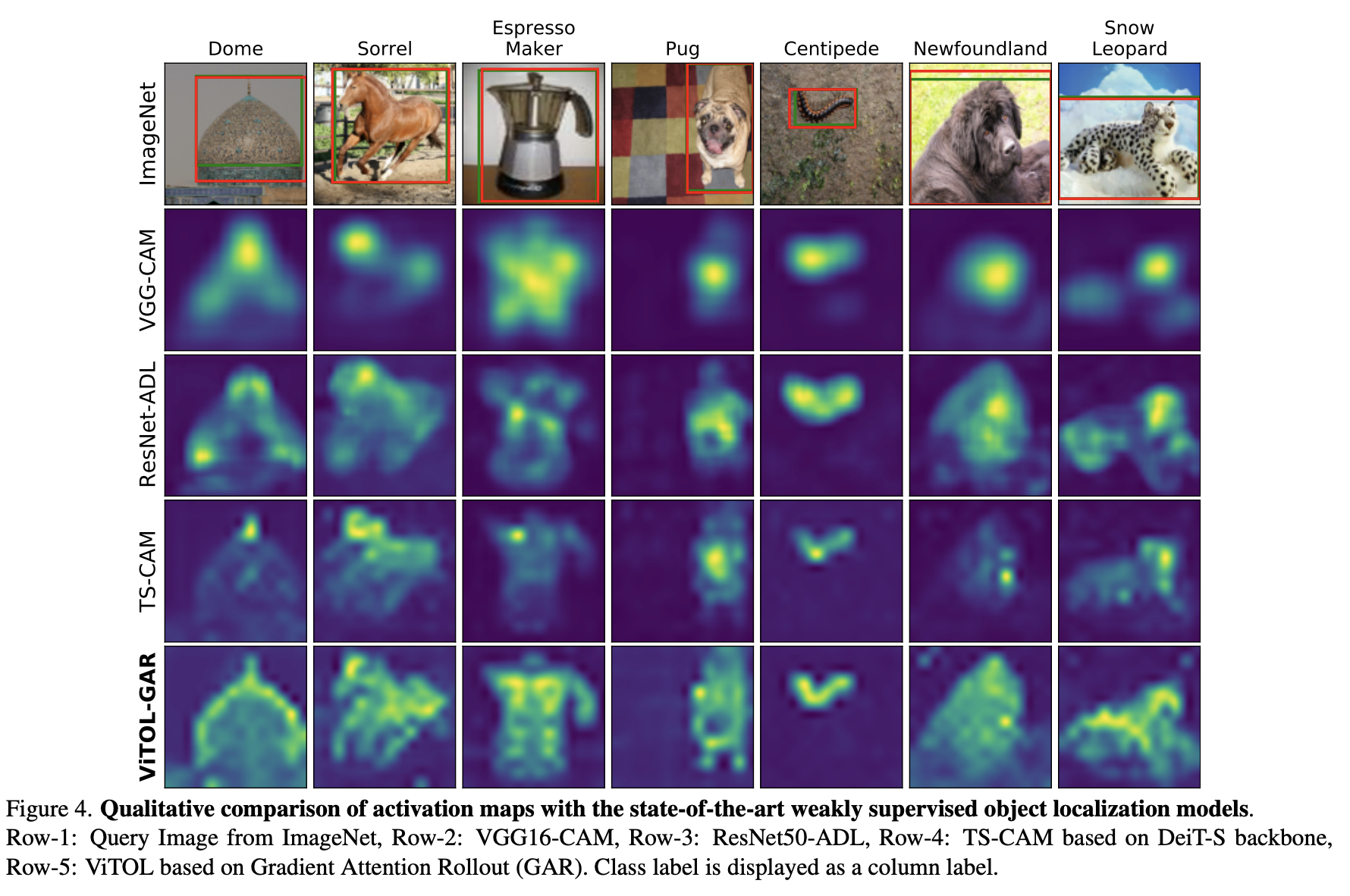
기존에 공부하였던 TS-CAM 과 그냥 CAM 들과는 다르게 객체 전체를 localization 잘 하는 모습을 확인할 수 있습니다.

Top1-loc 도 확인해보면, 기존의 rethinkingcam 보다는 성능이 떨어지지만, 전반적인 CAM 성능보다는 높은 것을 확인할 수 있습니다.
ViTOL : Vision Transformer for Weakly Supervised Object Localization - 논문 보기
