
CMT: Convolutional Neural Networks Meet Vision Transformers
본 논문은 Convolutional Neural Networks (CNNs) 와 Vision Transformers 를 결합한 새로운 하이브리드 네트워크인 CMT (Convolutional Neural Networks Meet Vision Transformers) 를 제안합니다. 이 네트워크는 transformers를 사용하여 longe range dependency를 발견하고, CNNs를 사용하여 지역 정보(local feature)를 추출합니다.
Introduction
여러분들이 알다시피, 최근 몇년간 CNN의 활약으로 인하여 Computer Vision 분야는 특징점을 추출하여 classification detection 등 다양한 task 에서 좋은 성과를 이뤘습니다.
또한 새로 등장한 self attention 기반의 transformer 모델은 token 간의 거리가 멀어도 전체 기반으로 영향력을 다루기 때문에 NLP 분야에서 높은 성과를 이뤘습니다.
따라서 transformer를 computer vision 에서도 도입하여 활용하려는 많은 연구( ViT ) 들이 있었고, 다양한 테스크에서 좋은 성능을 내는 모습을 볼 수 있습니다.
하지만, 동일한 크기의 small CNN모델과 비교하여 ViT는 성능이 많이 떨어지는 모습을 볼 수 있는데, 그러한 이유로는
-
ViT 의 경우 단순히 이미지를 patch 형태로 나누고 1D sequence 의 형태로 입력을 진행합니다. 이러한 transformer의 방식으로 인해 patch 간의 longe range dependency 를 효과적으로 찾아내지만, 이미지의 2D의 locality 와 같은 차이를 고려하지 않게됩니다. (이미지의 각 위치 정보를 고려하지 않는다는 뜻입니다.)
-
ViT 의 경우, 항상 fix된 patch size를 사용해 multi scale feature map 을 추출할 수 없으며, 특히나 low resolution feature map 에서도 잘 작동하지 않게됩니다.
-
ViT는 이미지를 patch 로 잘라 입력하는 방식으로 작동하고, 이미지 크기에 대해 quadratic 한 연산량을 필요로 합니다. 정확히 보면, ViT 는 인데, CNN은 형태이기 때문에, COCO datasets과 같이 해상도나, cityscape 와 같은 등을 학습하는데는 과도한 연산량을 가져 힘들게 됩니다. (C가 해상도를 뜻하기 때문)
따라서 본 논문에서는 이러한 CNN과 ViT의 이점만을 적절하게 결합하여 문제점을 해결할 수 있는 CMT를 제안하게됩니다.
Approach : Architecture
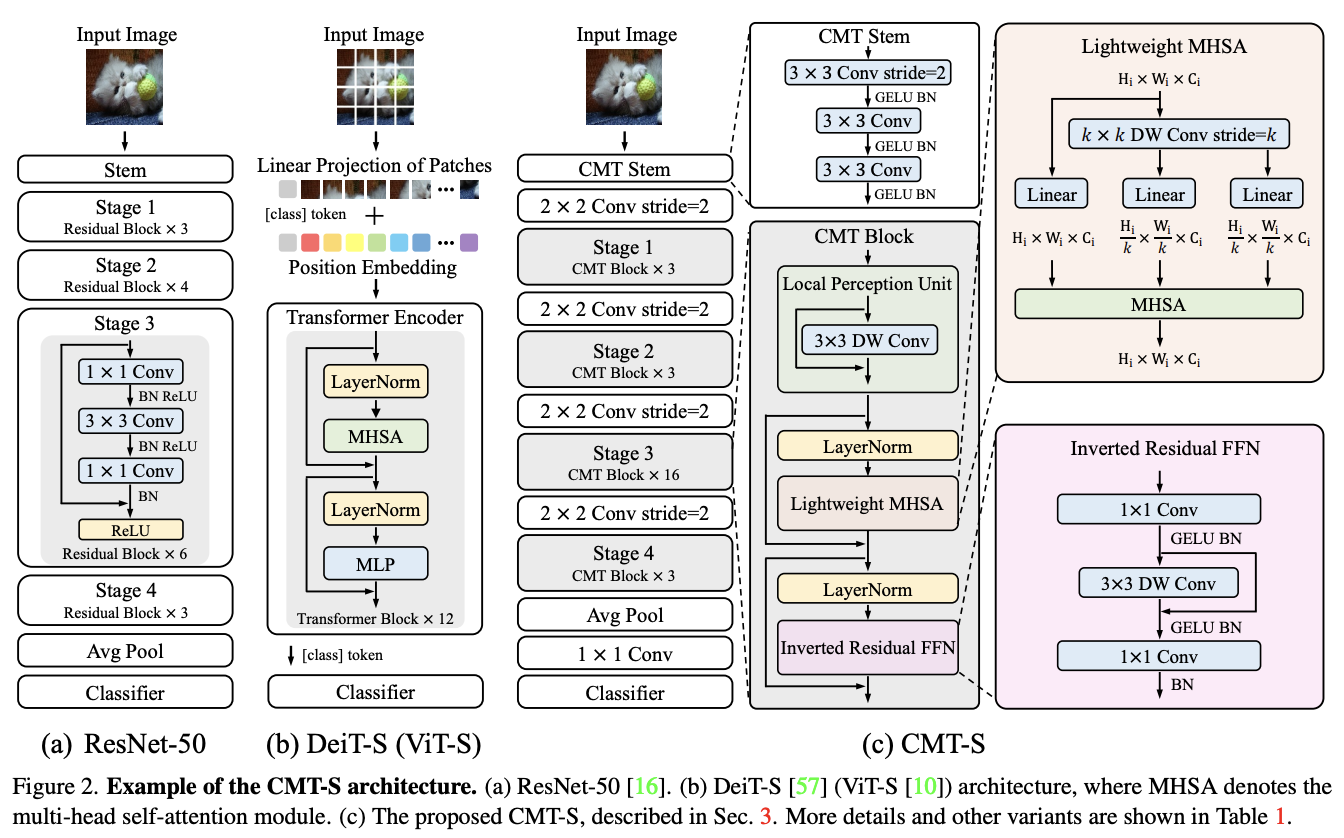
다음은 CMT 의 전반적인 구조를 나타냅니다. CNN 과 transformer 의 이점을 모두 활용하기 위하여 hybrid architecture 를 제안합니다.
Hybrid architecture는?
서로 다른 인공지능 모델을 결합하여 하나의 모델을 만드는 방법입니다. 이 방법은 각 모델의 장점을 결합하여 더 나은 성능을 얻을 수 있게됩니다.
CMT 논문에서 제안된 모델은 CNN(Convolutional Neural Network)과 Transformer를 결합한 Hybrid architecture입니다.
-
기존 ViT 에서는 이미지를 patch로 잘라서 입력을 진행하고 linear projection을 통하여 합치기 때문에 기존의 위치 정보가 많이 손실되고, poor modeling이 된다는 한계가 있습니다.
이를 보완하기 위하여 CMT 아키텍처에서는 CMT stem 이라는 ResNet 앞부분과 비슷한 방식으로 input 을 처리하여 input 의 사이즈를 줄이고 핵심 정보를 뽑아냅니다. -
기존 ResNet, EfficientNet 과 같은 CNN 구조들과 동일하게 4 stage 구조를 사용하였는데, CNN 표준 모형을 전반적으로 따라간다고 보면 됩니다.
-
CMT Block 내부에는 local feature 와 longe range dependency 를 모두 고려하여 해결할 수 있도록 만들어졌으며, 마지막을 확인해보면 output에서는 global average pooling 층과 함께 FC를 거쳐서 classification layer 로 연결됩니다.
-
CNN 의 기본 구조와 매우 비슷하기 때문에, 다양한 분야에서 backbone 모델로 사용할 수 있습니다.
-
4 stage 중간중간 마다 2 * 2 conv layer 를 2 stride 와 같이 사용되어 CNN 구조와 같이 feature map 의 scale 을 점점 바꾸며 학습을 진행하는 효과를 갖고, 이를 통하여 입력 이미지에 대한 multi scale feature map 획득할 수 있으며, detection, segmentation과 같은 downstream task 에 효과적인 모습을 볼 수 있습니다.
CMT Block 이란?
CMT block은 CMT 네트워크의 기본 구성 요소입니다. 이 블록은 transformer 블록의 개선하여 변형된 것으로, depth-wise convolution을 사용하여 local information을 강화합니다. CMT block은 세 가지 구성 요소로 구성됩니다.
- 첫 번째로,
LPU (Local Perceptual Unit)는 depth-wise convolution을 사용하여 지역 정보를 추출합니다. - 두 번째로,
LMHSA (Local-enhanced Multi-Head Self-Attention)는 transformer의 Multi-Head Self-Attention (MHSA)를 사용하여 longe range dependency를 캡처하고, shortcut을 사용하여 gradient forward ability를 향상시킵니다. - 세 번째로,
IRFFN (Inverted Residual Feed-Forward Network)은 transformer의 Feed-Forward Network (FFN)을 개선하여 더 나은 성능을 제공합니다.
이러한 세 가지 구성 요소를 조합하여 CMT block은 입력 특징을 변환하고 모으기 위해 여러 번 쌓여져 있습니다. 이를 통해 CMT 네트워크는 위에서 말한 것과 같이 local feature 과 longe range dependency를 모두 고려할 수 있게됩니다.
LPU(Local Perceptual Unit)
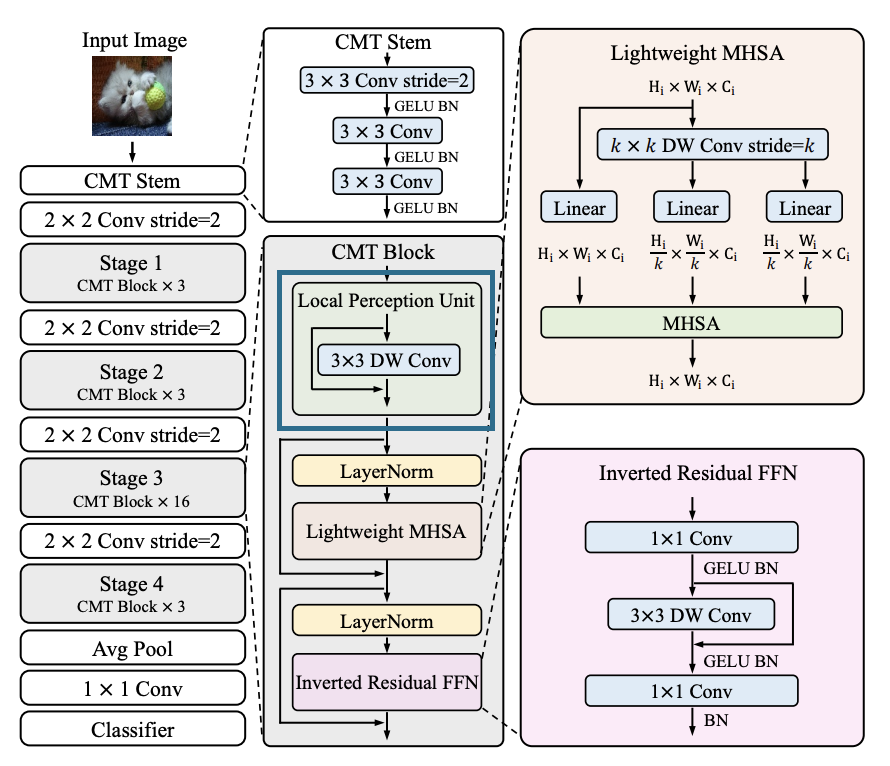
LPU (Local Perceptual Unit) 는 CMT block의 첫 번째 구성 요소로, local feature를 추출하기 위해 depth-wise convolution을 사용합니다. 이는 이미지에서 지역적인(특징이 될만한) 패턴을 감지하고, 이러한 패턴이 이미지의 다른 부분에서도 발생할 수 있음을 고려합니다.
Depth-wise convolution이란?
Depth-wise convolution은 컨볼루션 연산의 한 종류로, 입력 채널마다 따로따로 컨볼루션을 수행하는 방법입니다. 이 방법은 모델의 파라미터 수를 줄이고, 계산량을 감소시키면서도 모델의 성능을 유지하는 효과가 있습니다.
기존의 컨볼루션 연산은 입력 이미지의 모든 채널에 대해 동일한 필터를 적용합니다. 이에 비해 Depth-wise convolution은 입력 이미지의 각 채널마다 따로따로 필터를 적용하므로, 입력 이미지의 지역적인 정보를 더욱 잘 보존할 수 있습니다.
이를 통하여 LPU는 이미지의 local feature를 추출하고, 이러한 정보를 이후의 LMHSA 및 IRFFN 구성 요소에서 사용될 수 있도록 합니다. LPU는 다음과 같이 정의 되는데요,
여기서 X는 현재 stage의 입력 특징 이고, DWConv는 depth-wise convolution 을 나타냅니다. 이러한 LPU 구성 요소는 CMT 네트워크에서 local feature(지역 정보)를 추출하는 데 매우 유용하며, 이미지 분류 및 객체 감지와 같은 vision task 에서 높은 성능을 보이는데 중요한 역할을 합니다.
Lightweight Multi-head Self-attention
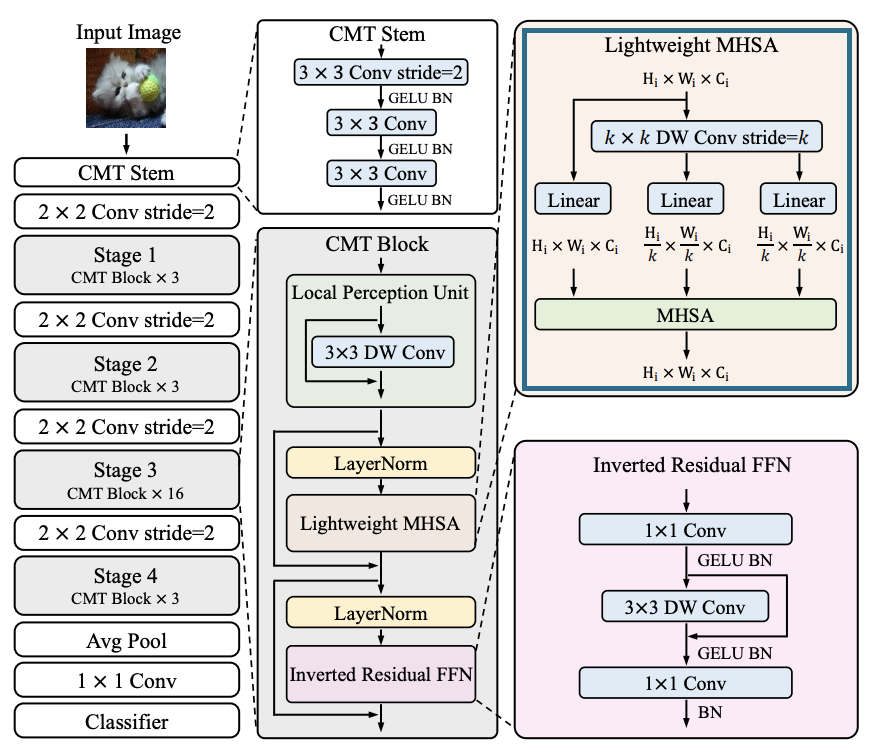
Lightweight Multi-head Self-attention 모듈은 self-attention을 사용하여 입력 이미지의 각 위치에서 주변 픽셀과의 Interaction 을 계산합니다. 이를 통해 이미지의 전반적인 전체 정보를 고려할 수 있게됩니다.
기존의 attention 식과 비교해봅시다.
기존의 self attention 계산의 경우, 입력 X가 n * d의 형태를 가질 경우, 이를 선형적으로(linear) 변환하여 Quary, Key, Value 값을 각각 나눠 처리를 하였지만, 이렇게 하는 과정에서 매우 많은 연산을 진행 해야했습니다.
따라서 본 논문에서는 이를 해결하기 위하여 k * k 크기 의 depth-wise convolution 을 stride k 와 같이 진행하여 Query 와 Key의 크기를 감소시켜 연산량을 줄였습니다.
또한 Swin Transformer 에서 사용되었던 Relative Position Bias 개념 또한 사용되어있는 것을 확인할 수 있는데요, swin 에서는 단순히 좌표의 상대적인 거리를 통해 relative position을 구했던 반면에, 본 논문에서는 임의의 값으로 초기화를 진행 후 학습 가능한 방식으로 진행하였습니다.
Lightweight Multi-head Self-attention 모듈 은 입력 X를 query Q, key K, value V로 선형 변환합니다. 이때, Q, K, V는 각각 n x dk, n x dk, n x dv 크기의 행렬입니다. 여기서 n은 입력 이미지의 패치 수이며, dk와 dv는 각각 key와 value의 차원입니다.
그 다음, LightweightAttention 함수를 h번 적용합니다. 이 함수는 입력 Q, K, V를 받아 Softmax 함수를 적용한 후, value값인 V' 를 출력합니다. 이때, Softmax 함수는 query와 key의 내적을 dk의 제곱근으로 나눈 값에 적용됩니다. 이를 통해 유사도를 정규화하고, 상대적인 위치 정보를 고려할 수 있습니다.
각 head에서 출력된 h개의 n x dh 크기의 행렬을 이어붙여서 n x d 크기의 행렬을 만듭니다. 이 행렬은 입력 이미지의 각 위치에서 계산된 self-attention 정보를 담고 있습니다. 이렇게 계산된 self-attention 정보는 다른 모듈들과 함께 사용되어집니다.
IRFFN (Inverted Residual Feed-Forward Network)
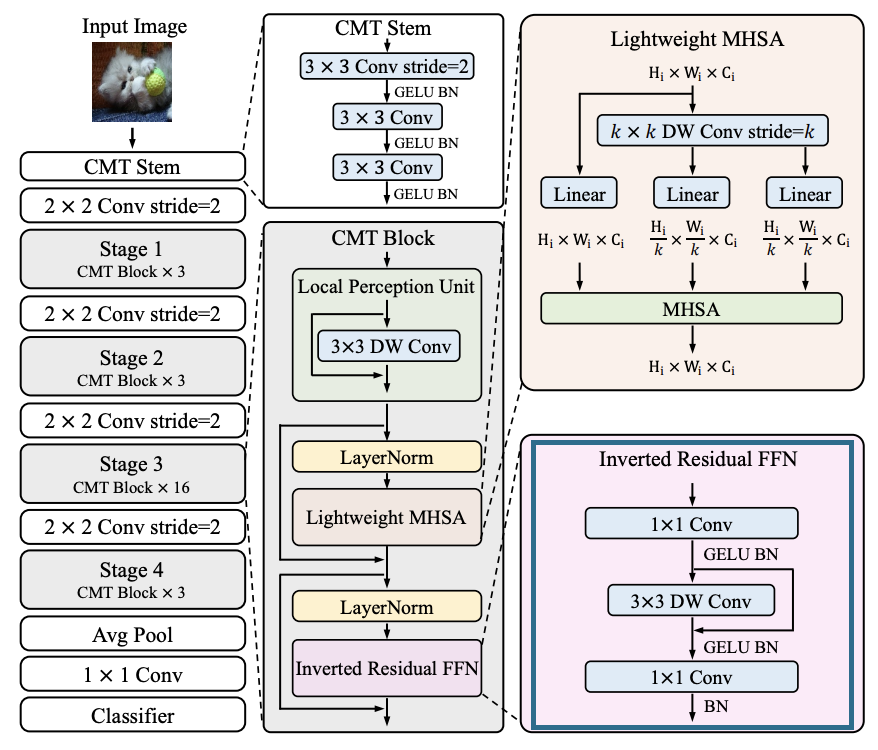
IRFFN 은 Vision Transformer의 Feed-Forward Network (FFN)을 개선한 모듈입니다.
기존의 FFN은 두 개의 선형 레이어와 GELU 활성화 함수로 구성되어 있습니다. 이때, 첫 번째 레이어는 차원을 4배로 확장하고, 두 번째 레이어는 다시 차원을 줄입니다. (ResNet의 BottleNeck 구조)
이와 달리 IRFFN 은 Inverted Residual Block에서 영감을 받아, 먼저 입력을 확장하는 레이어를 적용한 후, Depthwise Convolution과 Shortcut Connection을 적용합니다. 이후, 다시 입력을 줄이는 레이어를 적용합니다.
IRFFN은 FFN보다 더 적은 파라미터와 FLOPs를 가지면서도 높은 성능을 보입니다. 이는 Depthwise Convolution이 파라미터 수를 줄이고, Shortcut Connection이 학습을 더욱 효과적으로 돕기 때문입니다.
Scaling Strategy
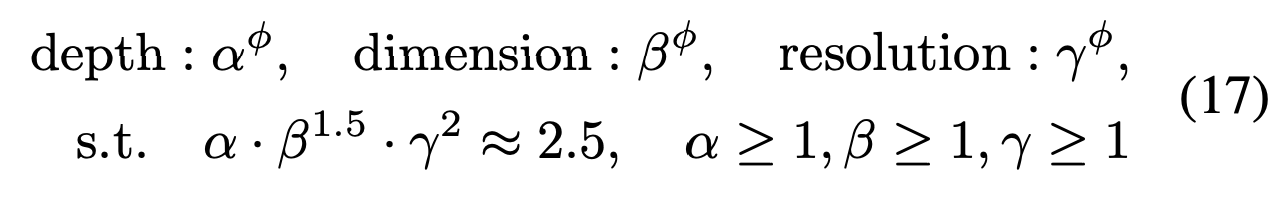
EfficientNet 구조에서 차용하여 Compound Scaling 전략을 도입하였는데요, 이를 통하여 Depth, Dimension, Resolution 등 에 대해서 가장 최적의 값을 Grid 하게 Search 하는 과정을 진행합니다.
Results
마지막에는 다양한 스케일링 전략을 적용한 모델들을 비교하였습니다. 이때, 스케일링 전략은 모델의 깊이, 차원, 윈도우 크기 등을 조절하여 모델의 크기와 성능을 조절하는 방법입니다.
Ablation study 결과를 보면, 스케일링 전략을 적용하지 않은 모델보다 스케일링 전략을 적용한 모델이 더 높은 성능을 보입니다. 특히, 스케일링 전략을 모두 적용한 모델은 가장 높은 성능을 보입니다.
또한, IRFFN 모듈과 Batch Normalization을 추가한 모델은 이를 적용하지 않은 모델보다 더 높은 성능을 보입니다.
이러한 결과는 CMT 논문에서 제안한 모델의 구성 요소들이 모델의 성능에 큰 영향을 미친다는 것을 보여줍니다. 따라서, 모델을 설계할 때 이러한 구성 요소들을 고려하여 최적의 모델을 설계하는 것이 중요합니다.
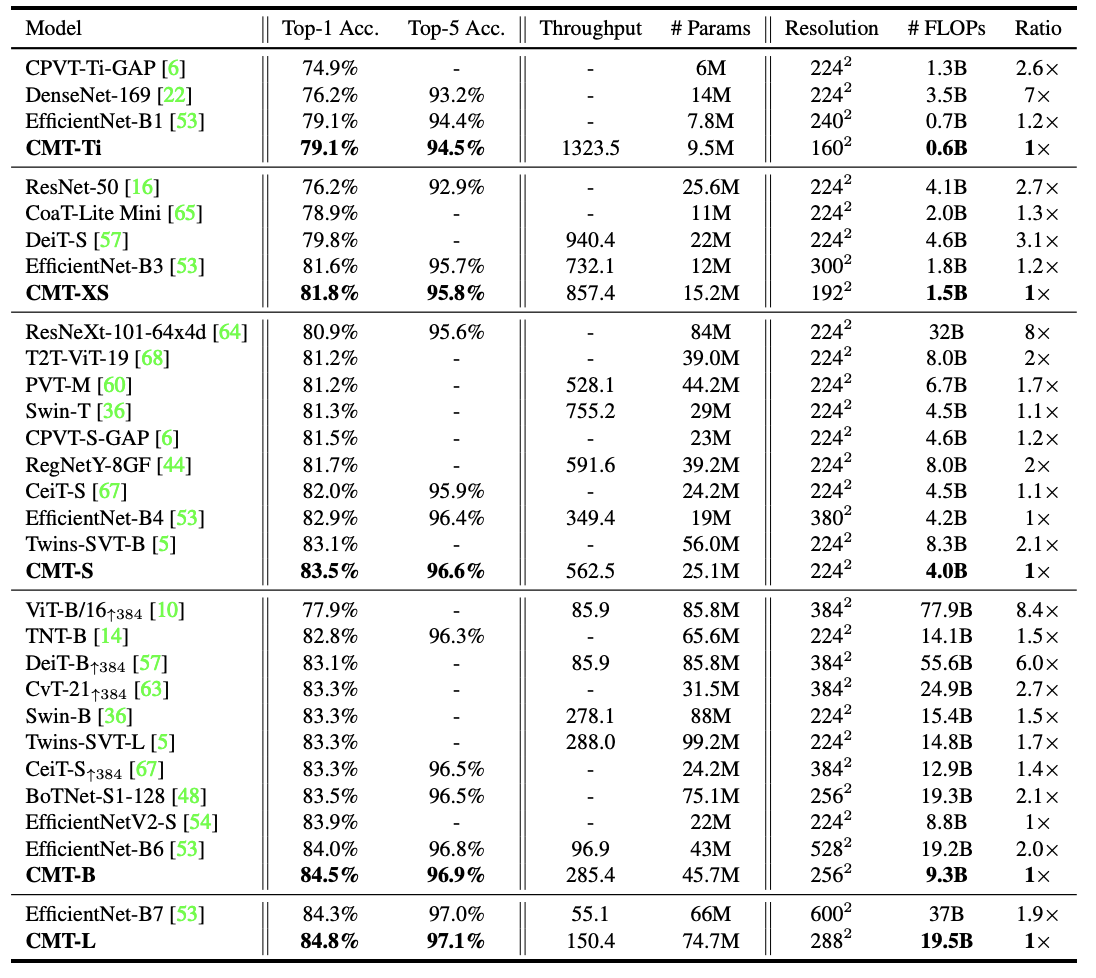
아래의 표는 ImageNet datasets 기반으로 classification 수치를 나타냅니다.
다음으로는 transfer learning,object detection, sementic segmentation 에서의 결과입니다. 역시나 잘 나타나있는 모습을 확인할 수 있습니다.

CMT: Convolutional Neural Networks Meet Vision Transformers - 논문 보기
