
Fast-RCNN이란?
RCNN의 성능 손실 문제와 시간 지연 문제를 해결하기 위하여 나온 모델로, RoI pooling과 feature 추출, classification, bounding box regression 까지 하나의 모델에서 학습하도록 구축하였다.
Fast-RCNN의 기본적인 구조
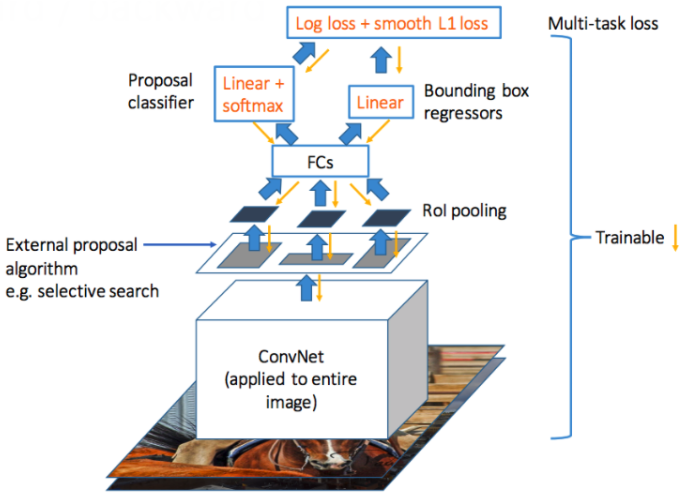
CNN Feature extraction
Inpute image 에서 미리 학습된 CNN을 통과하여 feature map을 추출한다.
Region proposal & projection
RCNN과 동일하게 Selective search를 통하여 각 RoI에 대해 bounding box를 만들고, 이 bounding box를 feature map 위에 투영하는 과정을 진행한다. 이를 region projection 이라고 한다.
RCNN에서 CNN output이 FC layer의 input으로 들어가야했기 때문에 CNN input을 동일 size로 맞춰줘야 했다. 따라서 원래 이미지에서 추출한 RoI를 crop, warp을 통해 동일 size로 조정했었다.
하지만 알아둬야 할 것은 FC layer의 input이 고정인거지 CNN input은 고정이 아니기 때문에 CNN에는 입력 이미지 크기, 비율 관계없이 input으로 들어갈 수 있고 FC layer의 input으로 들어갈때만 size를 맞춰주기만 하면된다. 이 사이즈를 맞춰줄 때 SPPNet이 사용된다.
Spatial Pyramid Pooling(SPP)의 과정 ?
- 이미지를 CNN에 통과시켜 feature map을 추출한다.
- 미리 정해져있는 4x4, 2x2, 1x1 영역의 피라미드로 feature map을 나눠주고, (이 한칸을 bin이라고 함)
- bin 내에서
max pooling을 적용해 각각의 bin 마다 하나의 값을 추출한다. - 피라미드의 크기만큼 max 값을 추출하여 3개의 피라미드 결과를 이어붙여서 고정된 크기의 vector를 만들어준다. 이 값들이 FC layer의 input으로 들어가게된다.
CNN을 통과한 feature map에서 2000개의 region proposal을 만들고 region proposal마다 SPPNet에 넣어서 고정된 크기의 feature vector를 만들어내는 방식이다.
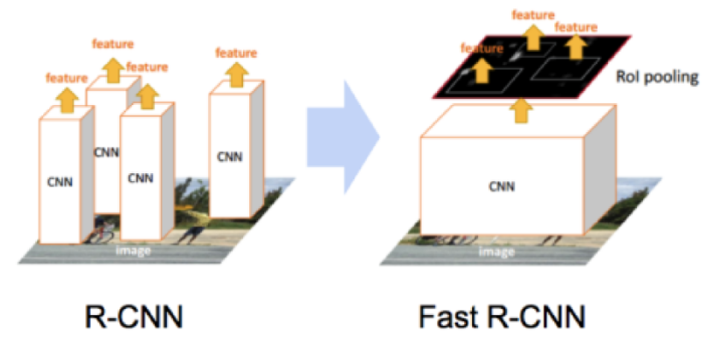
여기서 ! 모든 2000개의 region proposal 마다 해야했던 2000번의 CNN 연산이 1번으로 줄어들게되었다.
SPPNet의 한계점은
But unlike R-CNN, the fine-tuning algorithm proposed in cannot update the convolutional layers that precede the spatial pyramid pooling
Conv layer층을 업데이트할 수없다는 단점이 존재한다는 것.
RoI pooling
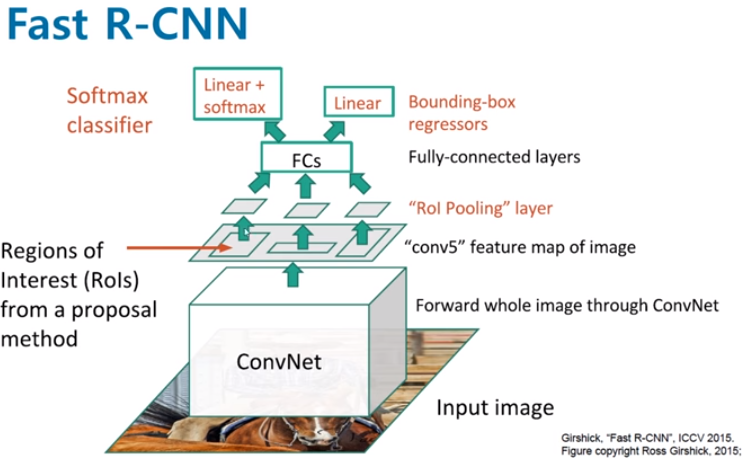
위의 이미지를 확인해보면, Fast-RCNN 에서 적용된 1개의 피라미드 SPP로 고정된 크기의 feature vector를 만드는 과정을 RoI Pooling 이라고 한다.
기존의 max pooling 층을 RoI pooling 층으로 바꿔주는 것인데,
과정은
- 미리 설정된 FC input layer(HxW) 크기로 만들어주기 위하여 h/H * w/W 크기만큼 grid를 RoI 위에 제작한다.
- RoI를 grid 크기로 split시킨 뒤, max pooling을 적용시켜서 각 grid 칸마다 하나의 값을 추출한다.
(H, W 값은 고정, h,w는 어떤 값이 되어도 !)
RoI Pooling은 feature map의 proposal region에서 FC input layer의 격자에 맞춰 bin마다 maxpooling 하여 고정된 크기의 feature vector를 만들어내는 과정을 진행한다.
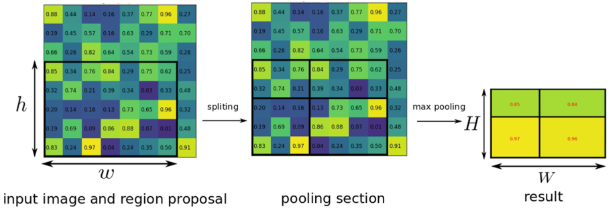
원래 이미지를 CNN에 통과시킨 후 나온 feature map에 이전에 생성한 RoI를 projection하고 이 RoI를 FC layer input 크기에 맞게 고정된 크기로 변형할 수 있다.
따라서 더이상 2000번의 CNN연산이 필요하지 않고 1번의 CNN연산으로 속도를 대폭 높일 수 있었다.
Image Classification & Bounding Box Prediction
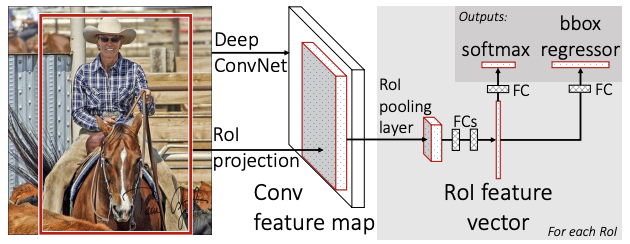
이 feature vector을 활용하여 classification 과 bounding box prediction을 각각 수행한다.
결과적으로 2개의 FC layer를 동시에 통과하여 softmax 결과값(=output vector)과 boundingbox regressor 결과값(=output vector)이 동시에 출력되게된다. (softmax probabilities and per-class bounding-box regression offsets)
Loss function & Training
classification과 bounding box prediction을 통해 나온 loss 값을 이용해 back propagation을 하여 전체 모델을 학습시킨다. 이때, RCNN과 비교해서 보아야할 점은, multi-stage pipeline으로 인해 3가지 모델을 따로 학습해야했던 문제이다. R-CNN에선 CNN을 통과한 후 각각 서로 다른 모델인 SVM(classification), bounding box regression(localization) 안으로 들어가 forward됐기 때문에 연산이 공유되지 않았다.
위 그림을 보면 RoI Pooling을 추가함으로써 이제 RoI영역을 CNN을 거친후의 feature map에 투영시킬 수 있다. 따라서 동일 data가 각자 softmax(classification), bbox regressor(localization)으로 들어가기에 연산을 공유한다. 이는 Fast-RCNN 모델이 end-to-end로 한 번에 학습시킬 수 있다는 뜻이다.
이 때, classificaiton loss와 bounding box regression loss를 적절히 엮어 multi-task loss를 만들면classification & bounding box regression을 동시에 돌릴 수 있는 결과를 얻을 수 있다.
Multi Task Loss란?
위의 과정에서 이미지로부터 feature map을 추출하였고, 해당 feature map에서 RoI를 찾아서 RoI pooling을 적용하여 feature vector를 구하였다. 이제 각각의 loss값을 얻어내고, 이를 back propagation을 하여 전체 모델을 학습시키는데, 이 때 사용되는 loss 가 multi task loss라고 한다.
이의 수식은
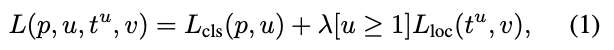
입력으로는 p는 softmax를 통해서 얻어낸 K+1(K 개의 object+1 개의 배경, 아무 물체도 아닌 것을 나타내는 클래스)개의 확률 값이다. u는 해당 RoI의 ground truth 라벨 값이다.
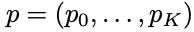
softmax 결과값은 다음과 같다.
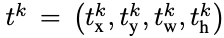
bounding box regression 결과값의 경우, K+1개의 클래스에 대해 각 x,y,w,h를 조정하는 t^k 를 리턴받는다. loss function에서는 이 값들 중 ground truth 라벨에 해당하는 값만 가져오고, 이는 t^u에 해당된다. v는 ground truth bounding box 조절값에 해당된다.
결과적으로 구한 classification loss 와 bounding box loss는 다음과 같다 !
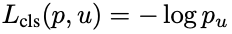
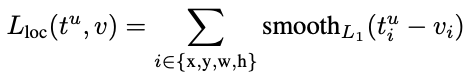
여기서 , input으로 정답 라벨에 해당하는 bounding box regression 예측 값과 ground truth 조절 값을 받는다. x,y,w,h에 대해 각각 예측값과 라벨값의 차이를 계산한 후, smoothL1 이라는 함수를 통과시킨 합을 계산한다.
smoothL1은
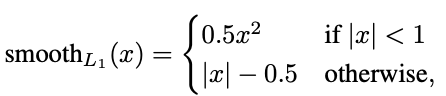
예측값과 라벨 값의 차이가 1보다 작으면 0.5x^2로 L2 distance 를 계산해준다. 반면 1보다 큰 경우 L1 distance 를 계산한다.
이는 object detection task에 맞춰 loss function을 custom 해주는 것으로 확인할 수 있다. 논문을 읽어보면 실험 과정 중, 라벨값과 차이가 많이 나는 예측값(outlier)들이 발생하였고, 이들을 그대로 L2 distance로 계산하여 적용을 할 경우에는 gradient가 explode 해버리는 현상을 관찰할 수 있다.
이를 방지하기 위하여 다음과 같은 함수를 추가한 것이다.
Fast-RCNN의 의미
- Fast R-CNN에는 1개의 CNN 연산만 한다. 이전 R-CNN에서 CNN 연산을 2000여번 하던 것에 비해서 연산량이 매우 감소했고 속도도 빨라졌다.
- CNN fine tuning, boundnig box regression, classification을 모두 하나의 네트워크에서 학습시키는
end-to-end 기법을 제시하였다. - Pascal VOC 2007 데이터 셋을 대상으로 mAP 66%를 기록하였다.
Fast-RCNN의 한계
그러나 여전히 Fast R-CNN에서도 RCNN에서와 마찬가지로 RoI를 생성하는 Selective search알고리즘은 CNN외부에서 진행되므로 이 부분이 속도의 bottleneck이 된다. 따라서 이 RoI 생성마저 CNN내부에서 함으로써 더욱 빠르면서 정확한 region proposal을 생성한 Faster RCNN이 나오게 된다. 차 후에 Faster RCNN을 논문 리뷰 해보겠다 !
