
RCNN이란?
Regions with Convolutional Neuron Networks features의 약자로, 설정한 region을 CNN의 feature로 활용하여 Object detection을 수행하는 신경망이다. 딥러닝을 object detection에 최초로 적용시킨 모델이다.
RCNN의 기본적인 구조
RCNN의 기본적인 구조를 알기 위해서는 2-stage detector 와 1-stage detector 의 차이점을 파악해야한다.
이 둘은 object detection의 종류로, 간단하게 말하면 2-stage detector 은 RoI를 뽑아내고 1-stage detector 은 RoI를 뽑아내지 않고 전체 이미지로 classification 한다는 점 !
아래에서 차근차근 확인해보자.

2-Stage Detector
slective search 기법과 region proposal 기법을 활용하여 object가 있을만한 영역을 우선적으로 뽑아낸다. 이 영역은 Region of Interest(RoI) 라고한다.
Region Proposal의 정의
객체가 있을법한 위치를 나열,제안한다. → feature extractor : 각각의 위치에 대해 피처 추출 → 분류, Regression(바운딩박스 좌표 예측) 모델 진행
즉, 물체가 있을 법한 위치를 찾는다. Sliding window방식을 사용하여 → 이미지에서 다양한 형태의 윈도우를 슬라이딩하며 물체가 존재하는지 확인한다. 그러나, 너무 많은 영역에 대하여 확인해야한다는 단점이 존재한다.
sliding window란? : 다양한 형태의 window를 sliding하며 object가 있는지 없는지 확인하는 방식이다.

Selective Search의 정의
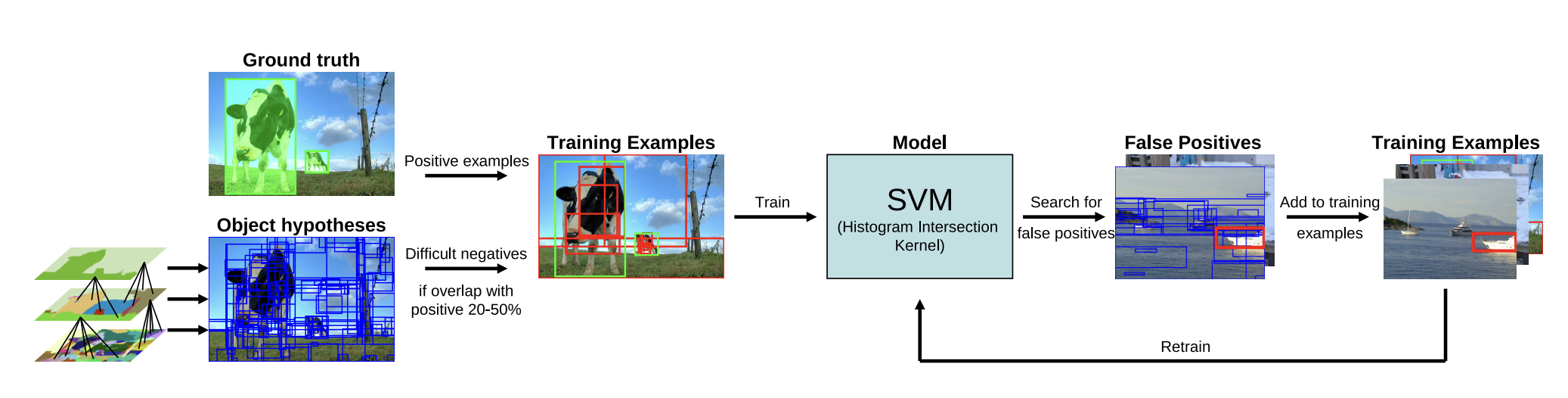

인접한 영역(region)끼리 유사성을 측정하여 큰 영역으로 차례대로 통합해 나간다. (R-CNN / Faster R-CNN) → CPU에서 수행되도록 라이브러리에서 작성되기 때문에 한장을 처리하는데 시간이 오래 걸린다.
-
selective search의 경우, 초기에는 sub-segmentation 을 수행하는데, 각각의 객체가 1개의 영역에 할당될 수 있도록 초기 영역들을 생성한다.
-
Greedy algorithm을 활용하여 이 과정을 진행한다. 우선 초기 영역으로부터 가장 비슷한 영역을 고르고 좀 더 큰 영역으로 통합을 하며, 이 과정을 1개의 영역이 남을 때까지 반복과정을 진행한다. 초기의 복잡한 영역들을 유사도에 따라 점점 통합이 된다.
(Fast segmentation algorithm based on pairwise region comparison (by Felzenszwalb etal.) - initial regions
Greedily group regions together by selecting the pair with highest similarity until the whole image become a single region
Generates a hierarchy of bounding boxes) -Selective Search for Object Recognition, Song Cao, vision seminar,2013
- 통합된 영역을 바탕으로 후보 영역들을 만들어낸다.

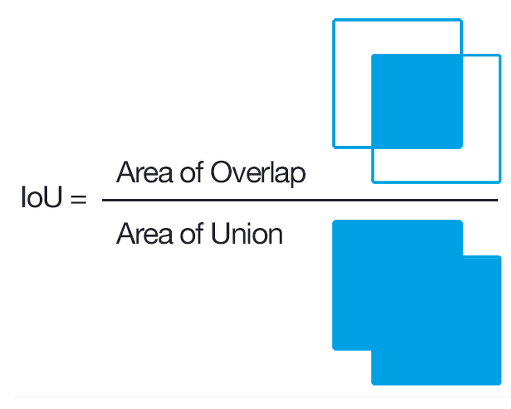
IoU란? : INTERSECTION OVER UNION 두 바운딩 박스가 겹치는 비율 | 성능 평가 예시, NMS 계산 시 사용된다.
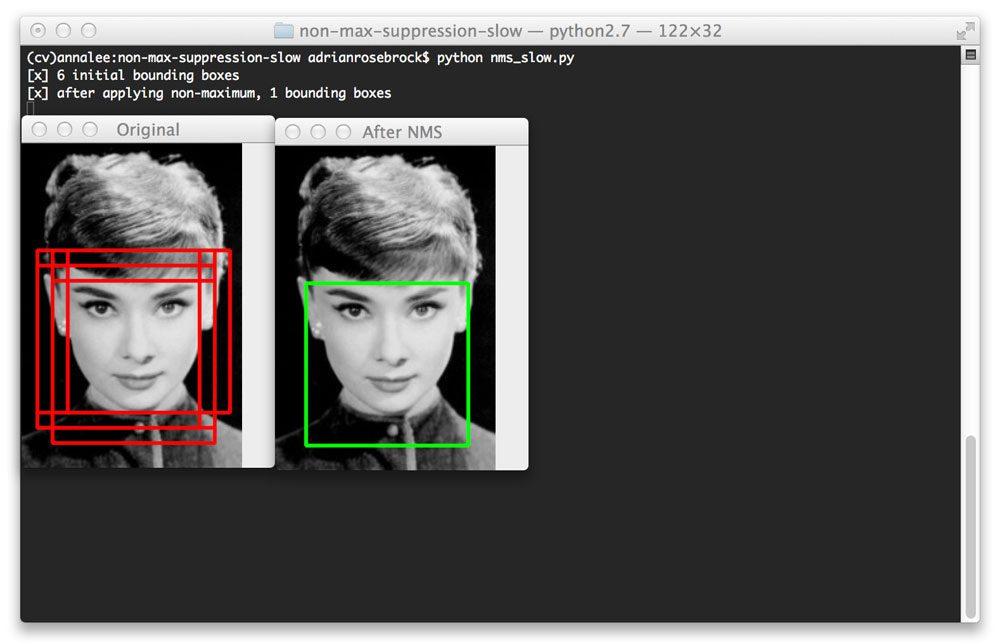
NMS란? : Non maximum supression 객체 검출에서는 하나의 인스턴스에 하나의 바운딩 박스가 적용되어야한다. → 따라 여러개의 바운딩 박스가 겹쳐 있는 경우에 하나로 합치는 방법을 사용한다.
실행 순서는 다음과 같다.
1. 특정 Confidence score 이하의 box를 제거한다.
2. Bounding box 를 confidence score 에 따라 내림차순으로 정렬한 뒤, score가 높은 box부터 IOU가 특정 값 이상인 box들을 모두 제거한다.
3. 남아있는 box만 선택한다.
Non maximum suppression 알고리즘은 confidence score threshold가 높을수록, IOU threshold가 낮을수록 많은 box가 제거된다.
1-Stage Detector
1-stage detector 의 경우 RoI를 뽑아내지 않고 전체 image에 대해서 convolution network로 classification, box localization을 진행한다. 물체의 위치를 찾는 문제와 분류 문제를 한번에 해결해준다.
RCNN의 작동 방식
RCNN - Region with CNN features
먼저 selective search 를 이용해 2000개의 region proposal 을 생성한다. 각 region proposal 을 일일히 CNN에 넣어서 forward 결과를 확인한다. (크기는 각각 동일하게, feature vector를 추출)
-
Selective search를 이용해 2000개의 Rol(region of interest)를 추출한다.
Selective search : 색상, 질감, 영역크기 등등,, 을 이용하여 non-object-based segmentation을 진행 → bottom- up 방식으로 small segmented areas 들을 합쳐 더 큰 segmented areas들을 만든다 → 윗 작업을 반복해 최종적으로 2000개의region proposal을 생성한다. -
각 RoI에 대하여 warping을 수행하여 동일한 크기의 입력 이미지로 변경한다.
-
warped image를 CNN에 넣어서(forward) 이미지 feature를 추출한다.
: selective search를 통해 영역들이 생성되면, RCNN은 이 영역을 적절히 찌부러뜨려(warp) 모델에 표준화된 크기 (역자주: 입력값으로 지정된 이미지 사이즈)로 생성한다. -
해당 feature 를 SVM에 넣어 클래스 분류 결과를 얻는다. → 이때 각 클래스에 대해 독립적으로 훈련된 이진 SVM을 사용한다.(2014년도까지는 SVM 을 많이 사용하였다 - SVM을 통해 객체인지 아닌지, 객체 클래스가 무엇인지 판단한다.)
지역화(localization)성능을 높이기 위해 bounding box regression 을 사용한다.
- 해당 feature를 regressor에 넣어 바운딩박스를 예측한다.
이 bounding box는 기존 box 보다 더 tight한데, 이 때 단순한linear regression을 이용한다. 그 선형 회귀식의 입력과 결과물은 다음과 같다.
- 입력 : 객체에 해당하는 이미지의 부분(sub-region)
- 출력 : 그 입력 부분(sub-region)에 맞는 새로운 bounding box의 좌표들
왜 Classifier로 Softmax를 쓰지 않고 SVM을 사용했을까?
: CNN fine-tuning을 위한 학습 데이터가 시기상 많지 않아서 Softmax를 적용시키면 오히려 성능이 낮아져서 SVM을 사용했다.
Bounding BOX regression을 사용한 이유는 무엇일까?
: Bounding BOX regression은 지역화(localization) 성능을 높이기 위하여 사용한다.

지역화(localization)란? : 이미지의 두번째 경우와 같이 모델이 주어진 이미지 안의 Object가 이미지 안의 어느 위치에 있는지 위치 정보를 출력해주는 것으로, 주로 bounding box를 많이 사용하며, bounding box의 네 꼭지점 pixel 좌표가 출력되는 것이 아닌, left top 또는 right bottom의 좌표를 출력한다.
RCNN의 한계점
- 입력 이미지에 대해서 CPU 기반의 Selective search를 진행해야하므로, 상당히 많은 시간이 소요된다.
- 전체 구조도를 확인해보면, SVM과 Regressor 모듈이 CNN 아키텍처와 분리되어있기 때문에, SVM과 Regressor의 결과를 통하여 CNN을 업데이트 할 수 없다. 분리되어있기 때문 ! → 즉, End-to-End 방식으로 학습할 수 없다.
- 모든 ROI를 CNN에 넣고 학습해야하기 때문에, ROI 개수만큼, (현 논문에서는 2000번) 의 CNN 연산이 필요하다. 따라서 많은 시간이 소요될 수 밖에 없다.
