
Improved Techniques for Training GANs
Improved GAN 으로도 알려진 이 논문은, 기존에 공부하였던 GAN을 훈련하는데 있어서 여러 효율적인 방법들을 알려주는 논문입니다.
Introduction
GAN 훈련 방법의 핵심을 이렇게 말합니다.
'Training GANs requires finding a Nash equilibrium of a non-convex game with continuous, highdimensional parameters'
Nash equilibrium(내시 균형) 이란, 게임 이론에서 경쟁자 대응에 따라 최선의 선택을 하면 설로가 자신의 선택을 바꾸지 않는 균형상태를 의미합니다.
GAN 에서는 생성자(Generator) 와 판별자(Discriminator) 라는 두 모델이 서로 경쟁하는 상황을 의미합니다.
하지만 논문에서는 이 내시 균형 상태를 찾기 위한 과정에서 GAN 이 실패한다고 말합니다. 따라서 본 논문은 GAN 의 수렴을 위해 할 수 있는 몇가지 방법들을 소개합니다.
Main Idea
핵심 아이디어는 5가지 입니다. (방법 5가지)
Feature Matching
Feature Matching 은 현재 Disciriminator에 새로운 목표를 지정하여 overtraining을 방지하고, GAN의 불안정성(insatbility) 을 해결합니다.
Generator에서 생성한 분포가 실제 데이터의 분포에 알맞게 matching 시키기 위해 Discriminator 중간층의 activation 함수를 이용합니다.
이는 단순히 진짜/가짜를 나누는 방식이 아닌, 진짜와 같은 feature를 가지고 있느냐? 라는 방식으로 훈련을 진행하는 것입니다.
이를 위해 새로운 손실함수 다음과 같은 방식으로 정의하고 사용합니다.
기존에는 나온 output 의 값으로 loss 를 계산하여 보완하였지만, 이제는 discriminator 중간층에서 생성된 feature 를 가지고 위의 loss 를 계산하는 방식을 말합니다. (feature 의 특징을 비슷하게 만들기 위해서 output 이 아닌 feature map 을 가지고 비교한 듯 합니다)
여기서 f(x) 는 Discriminator의 중간층 activation 함수입니다. Discriminator 중간층의 output이 생성에 필요한 하나의 특징(feature) 이며, 이게 random sampling된 z에 대해 분포가 비슷한지(matching) 살펴보는 것입니다.
G가 최종적으로 목표하는 통계치에 도달하는지는 확신할 수 없지만, 경험적으로 불안정한 GAN에 대해 효과적이라고 설명하고 있습니다.
Minibatch Discrimination
GAN이 실패하는 경우 중 하나는 Generator 가 동일한(유사한) 출력을 하게 parameter가 세팅되는 경우라고 합니다.
이는 GAN의 게임 원리인 Generator가 Discriminator를 속이기만 하면 되기 때문에 이런 일이 발생합니다.
따라서 여러가지 종류의 다양성을 가진 output 이 나오지 않고 GAN의 mode collapse와 같이 비슷한 경우의 이미지만 출력되는 것이죠. 이를 해결하기 위해 minibatch discrimination을 적용합니다.
Vanila GAN 등 기본적인 GAN에서 실험한 결과를 확인해보면 초기 noise에 따라 loss가 급격하게 줄어들고 결과를 확인하면 이상한 noise만 출력하는 것을 확인할 수 있습니다.
본 논문에서는 이 문제는 Discriminator가 각 example을 개별로 처리하기 때문에 출력간의 관계를 고려하지 않기 때문 이라고 이야기하고 있습니다.
따라서 minibatch discrimination 은 배치(batch) 안에서 다른 데이터간의 관계를 고려하도록 설계하는 방법입니다.

여기서 Discriminator는 여전히 실제/생성 데이터를 분류하는 일을 하고, minibatch의 정보를 side information 으로 사용할 수 있게 됩니다.
미니배치 안에서 평균을 구해 배치 안 feature map 들끼리 loss 를 계산하여 비교하는 방식입니다.
각 샘플이 minibatch내의 다른 샘플들과의 유사도(L1 norm) 를 계산하여 합치고, 이를 판별 단계에서 추가적인 정보로 사용하게 됩니다.
Minibatch Discriminator 를 사용하면 시각적으로 매력있는(중요한) 샘플을 feature matching보다 잘 생성 합니다.
하지만 feature matching은 semi-supervised learning에서는 더 성능이 좋았다고 논문에서 이야기하고있습니다.
Historical averaging
이 방식은 discriminator 와 generator의 손실함수 모두에
를 추가합니다.
는 모델의 파라미터를 나타내며, 는 i 번째 학습과정에서의 파라미터를 나타냅니다.
Moving average filter 와 동일한 방식으로 작동한다고 보시면 되는데,

weight 가 너무 심하게 바뀌는 경우에 대비하여, 이를 안정화시키기 위해서 평균값도 유동적으로 바꾸는 과정입니다.
이와같은 방식은 가상 게임 알고리즘에서 영감을 받았다고 하는데요, 이는 저차원이고 지속적인 정점이 아닌 게임에서 동일한 부분을 찾을 수 있는 방법이라고 합니다.
(예를 들어 minimax game 에서 한 선수가 x를 컨트롤하고, 다른 선수가 y를 컨트롤 한다고 할때, value function 이 이라면, 조건은 가 되는데, 이렇게 평형 조건을 찾을 때 그라디언트 계산 만으로는 평형 포인트를 도달할 수 없는 넓은 궤도에 갈 수 없기 때문에 실패한다고 합니다. )
One-sided label smoothing
Label smoothing 과정은 0과 1 타겟 대신 0.9, 0.1 등의 smoothed value로 classifier 를 훈련하는 방법입니다.
구체적으로는 positive target을 α, negative target을 β 로 두는데, 이 때 negative data가 더 좋은 방향으로 생성되는 것을 위해 β 는 0으로 설정하기 때문에 one-sided 라는 말이 붙게됩니다.
이렇게 바꾸게되면 optimal discriminator 는
이 되는데요, 의 존재는 문제가 되는데, 가 대략 0이 되고 이 커지게 되면, 로부터의 오류 샘플은 쪽으로 수렴하게 되도록 유인책이 될 수 없기 때문이라고 합니다. 따라서 β 는 0으로 설정되는 것이지요.
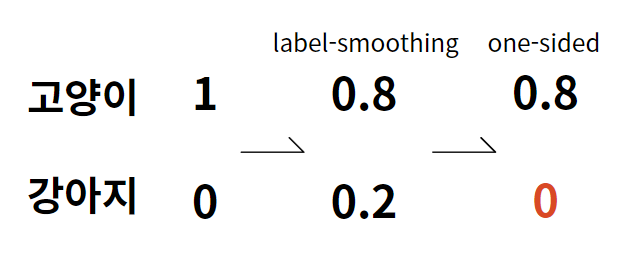
간단히 설명하면 다음과 같습니다. 0과 1 로 만 표현되던 분포에서 label-smoothing을 진행하면 도합 1이 되는 확률로 normalize되었습니다. 마지막으로 현재 제안하는 one-sided label smoothing은 도합 1이 되는 것을 고려하지 않고 가장 높은 확률에만 확률값을 주는 smoothing 방식입니다.
Virtual batch normalization
batch normalization은 뉴럴 네트워크의 옵티마이징을 크게 개선시켰고, DCGANs 에서 매우 효율적입니다. 하지만 이는 뉴럴 네트워크의 Output을 몇개의 다른 input x' 와는 (동일한 미니배치로) 매우 의존적인 결과를 낳는다고 합니다.
따라서 Virtual batch normalization 은 mini batch의 다른 값들의 영향을 많이 받는 것을 방지하기 위해 고정된 배치(reference batch) 를 이용 하는 방식입니다.
(고정된 배치(reference batch) : 각 데이터값인 x 는 고정된 배치에서 모아진 통계에 의해서 normalized 되고, 한번 선택되면 학습 진행시간동안 변하지 않습니다.)
reference batch는 학습 초기에 한번 걸러져서 학습이 진행되는 동안 변하지 않습니다. 이렇게 변하지 않는 값을 이용하여 normalize를 진행합니다.
하지만 2개의 minibatch를 forward propagation하는 것은 느리기 때문에 generator에서만 진행한다고합니다.
Assessment of image quality
본래 GAN의 경우 다른 모델들과 다르게 객관적으로 성능을 평가할 지표가 부족합니다. 생성된 이미지를 평가하기 위해서는 사람의 판단이 필요했지만, 주관이 들어간다는 명확한 한계점이 있습니다. 따라서 논문에서는 이를 대신할 평가지표를 제안합니다.
논문에서는 Inception model 을 적용합니다. 이는 생성된 이미지의 conditional label distribution p(y|x) 를 구합니다.
p(y|x)가 작다는 것은 이미지가 객체의 의미있는 정보를 포함하고 있다는 것입니다. 또한, 생성되는 이미지의 다양성 측면에서 p(y)를 사용하는데 p(y)가 높은 entropy를 가짐으로써 이미지의 생성이 다양하다고 볼 수 있습니다.
최종적으로는 위의 식 형태로 평가지표를 사용하였고, exponential을 통해 비교가 용이하도록 하였습니다.
p(y)와 p(y|x) 간 entropy가 커지는 것은 이미지 생성이 정확하면서 다양하다는 것입니다. 이러한 지표는 CatGAN의 목적함수와 유사합니다.
이 지표를 통해 학습을 성공한 것은 아니지만 인간의 판단력만큼 평가할 수 있다고 제안합니다.
Semi-supervised learning
기존 classification task에서 GAN generator에서 생성된 sample을 generated 라는 라벨로 추가하여 semi-supervised를 진행하였습니다.
기존 label K개에서 K+1개로 만들어 진행하는 방식입니다.
는 x가 생성된 가짜 이미지일 확률이며 이는 GAN에서 과 대응됩니다. 즉 을 최대화하는 것이 unlabeled data를 사용하여 학습할 수 있다는 것을 알 수 있습니다.
논문에서는 이를 바탕으로 두 개의 loss로 semi-supervised learning을 진행합니다. 현재 데이터셋이 절반은 real, 나머지는 generated로 가정하고 classifier를 위한 loss function은 아래와 같습니다.

위 식에서 L 은 각 supervised, unsupervised loss를 더한 것이며
supervised loss 는 데이터셋의 진짜 데이터를 분류하기 위한 loss입니다. 반면, unsupervised loss 는 일반적인 GAN의 loss와 동일하며 위와 같이
식을 이용하여 계산합니다. 이러한 semi-supervised learning에서 좋은 성능을 내는 것을 확인하였다고합니다.
Results
본 논문에서는 MNIST, CIFAR-10, SVHN, ImageNet에서 실험을 진행하였습니다.

MNIST에 대한 결과를 확인해보면 이미지 생성은 minibatch dicrimination 을 적용했을 때 좋았지만 모델 classification 에서는 semi-supervised로 진행하였을 때 더 좋은 성능 을 보였다고합니다.
