[논문 리뷰]_Rethinking CAM & weakly supervised semantic segmentation and weakly supervised object detection
PapersReview

Rethinking CAM
Rethinking CAM - semantic segmentation
기존의 Grad-CAM 과 CAM의 주요 목적은 '어디 위주로 봐서 이를 어떤 클래스로 지정했느냐' 라는 '어디'를 알기 위해서 확인한 것인데, 이 Fully-CAM의 경우는 이를 넘어 '지역화' 에 더욱 신경 써서 만든 방식이다.
지역화(localization) 란? : 모델이 주어진 이미지 안의 Object가 이미지 안의 어느 위치에 있는지 위치 정보를 출력해주는 것이다. 주로 bounding box를 많이 사용하며, bounding box의 네 꼭지점 pixel 좌표가 출력되는 것이 아닌, left top 또는 right bottom의 좌표를 출력한다.
Grad CAM의 성능을 올림과 동시에 기존 classifier의 성능을 올리는 과정을 진행해본 논문이다. 여기서는 Fully-CAM 이라는 방식을 따로 활용하는데, 이를 통하여 정확하고 상세한 위치 정보를 찾아낼 수 있으며, 어떤 layer의 feature map에서도 localization을 얻을 수 있다. 따라서 어떤 backbone 모델이든 상관없이 위치 정보를 찾아낼 수 있다는 것 !
CGM : Computing Gradients Module
CGM은 Fully-CAM의 핵심 요소 중 하나로, 특정 class 의 gradient를 계산하기 위하여 사용한다. 훈련된 분류기에서 추출한 feature map을 전달하고, 해당 클래스에 대한 gradient를 계산한다. 이러한 gradient는 localization을 위해 사용된다.

y_ci 가 각 클래스 ci 에 대한 predicted score 값, I 가 input image이고 이 class 에 대한 지정된 parameter를 θ 라 할때, 예측 점수는 다음과 같이 계산한다.
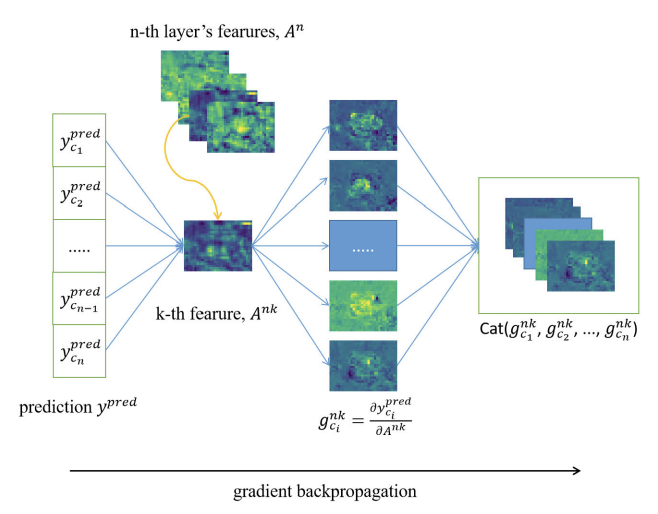
각 클래스에 대해 예측점수 y_cn 값만큼 계산해주고, (여기서 n은 layer feature map 개수) class c 에 대한 모든 gradients 들을 g_ci^nk라고 부른다.
이것들을 conv layer 층 갯수대로 쫙 모아서 class 덩어리 별로 gradients를 구하면 다음과 같다.

Fully-CAM의 진행 단계
기존 CAM(Class Activation Map)은 특정 layer의 feature map에서 클래스에 대한 활성화 정도를 계산하여 객체의 위치를 찾는 방법이다. 이 방법은 해당 layer에서만 정보를 추출하므로, 다른 레이어에서 발생하는 정보는 활용하지 못한다.
본 논문에서의 Fully-CAM 은 전체 네트워크의 feature map 을 사용하여 객체의 위치를 찾는 방법이다. 이를 위해, CGM(Computing Gradients Module)을 사용하여 전체 네트워크의 gradient를 한 번에 계산하고, FLM(Fusing Localization Module) 을 사용하여 모든 feature map을 가중치로 결합하여 최종 CAM(Class Activation Map)을 생성한다. 이 방법은 모든 레이어에서 발생하는 정보를 활용할 수 있으므로, 기존 CAM보다 더욱 정확한 객체 위치 추정이 가능해진다는 것 !
Fully-CAM 은 총 세단계로 진행된다.

-
forward pass: 각 conv layer 의 객체 위치 정보가 담긴 출력 피처와 각 클래스의 예측score를 얻는다. -
backward propagation: 각 feature 의 gradient를 얻는다. -
generation: gradient feature를 사용하여 최종적인 CAM을 생성한다. 위의 CGM은 gradient를 계산하며, FLM(Fusing Localization Module) 은 gradient와 feature를 결합하여 CAM을 생성한다.
input image는 conv layer에서 feature map으로 변환된다. 이후 classifier에서는 각 class 에 대한 confidence score 점수(예측 신뢰 점수)를 출력한다. 이 score 와 feature map은 CGM(Computing Gradients Module)을 통해 각 클래스에 대한 gradient를 계산한다.
이 gradient 와 feature map은 FLM(Fusing Localization Module)을 통해 최종 CAM으로 결합된다. 이 CAM을 통해 객체의 위치를 나타내는 과정으로 사용된다.
FLM : Fusing Localization Module
FLM을 활용하여 계산한 CAM은 다음과 같은 수식으로 작성된다.

여기서 볼 수 있듯이, nk 가 각각 다 살아있는 것을 통해서 , 각 conv layer 층과 각 feature map 별로 CAM을 뽑아낼 수 있는 것을 확인할 수 있다.
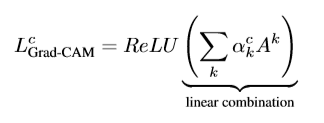
Grad-CAM++ 와 비교해보면, 동일하게 relu 가 위치값이 각 class 에 영향을 주는 변수값인 A_ij^nk에도 붙은 것을 확인할 수 있는데, CAM의 값이 음수가 될 경우, 해당 위치의 feature가 해당 클래스와 관련이 없다는 것을 의미하기 때문이다. 따라서, 음수값을 0으로 만들어주는 ReLU 함수를 적용하여 불필요한 정보를 제거하고 CAM의 정확도를 높이기 위해 사용된다.

결과적으로, 어디 부분을 잘 봐서 이 클래스로 예측했는가 에서 나아가서, 어디에 이 클래스가 위치해 있는가 를 제대로 표현한 모습을 확인할 수 있다.
여기까지 !
CAM 시리즈에 대해 발전된 과정까지 살펴보았다.
지금부터는 Weakly Supervised Object Localization과 결합한 CAM에 대해 살펴보자 !
Rethinking Class Activation Mapping for Weakly Supervised Object Detection
본 논문에서는 Weakly Supervised Object Detection (이하 WSOL) 문제를 해결하기 위해 CAM의 뼈대를 따르는 것에서 벗어나, CAM의 뼈대에서 각 모듈을 교체하여 모든 WSOL 방법에 보편적으로 적용하는 방식을 제안한다.
기존 Weakly Supervised Object Detection
WSOL(Weakly Supervised Object Localization) 는 이미지 수준의 클래스 레이블만 사용하여 개체를 localization하는 작업이다. 따라서 WSOL 과 CAM을 활용하는 목표는 개체 위치에 대한 추가적인 annotation 없이 이미지 수준 클래스 레이블에서 훈련된 분류 모델을 사용하여 이미지에서 개체를 정확하게 찾는 것이다.
기존의 WSOL의 문제점을 해결하기 위하여, CAM을 활용하는 방식은 다음과 같다.
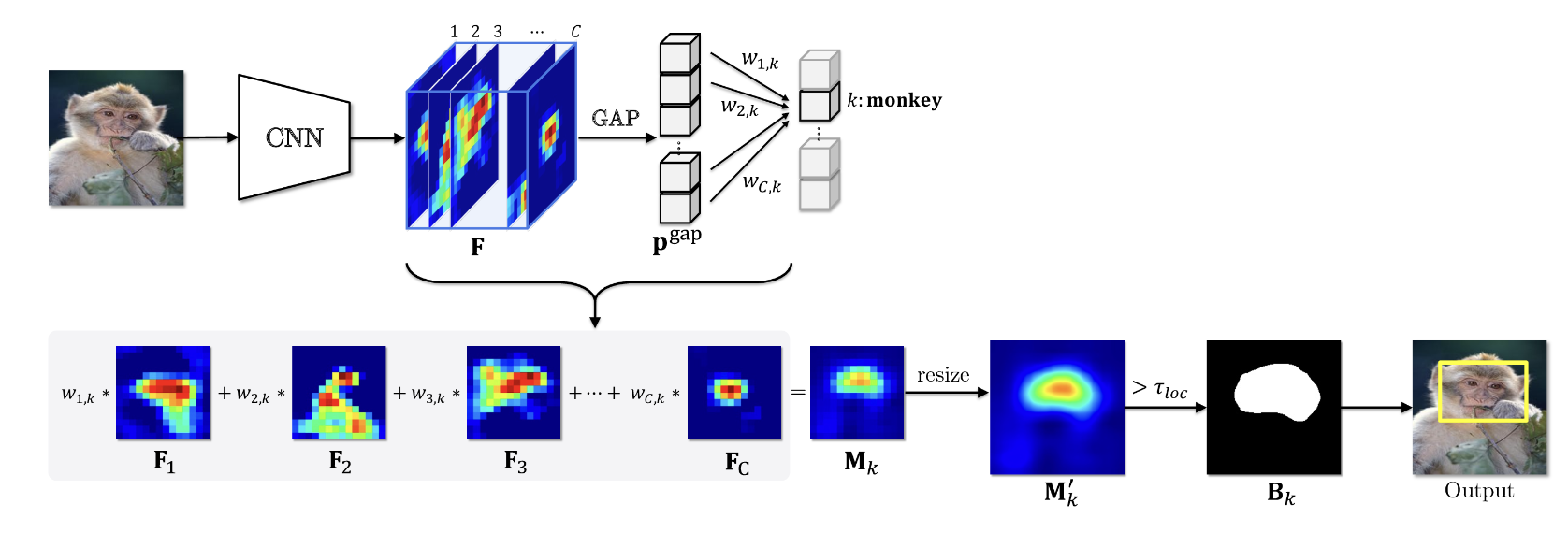
train시 classification model은 이미지 수준 클래스 레이블만 사용하여 학습한다.inference시 CAM은 특징 맵 F 와 해당 가중치 W를 채널별로 weighted-averaging하여 생성한다.- bounding box 형식으로 객체 위치를 추정하는 임계값을 통해 binary mask B 가 만들어진다.
이 기존 CAM 방식을 활용했을 때의 문제점이 무엇이냐,

CAM을 localization으로 활용하게 되면, 원숭이 예에서와 같이 작게 식별되는 영역으로 제한된다는 것이다. 각 feature map F 28장을 확인해보면, 작은 식별 영역이 엄청나게 분산되어 activate 되어있는 것을 확인할 수 있는데, 이는 WSOL의 모델 특성상 제한된 loacalization 문제가 발생될 수 밖에 없다는 것을 확인할 수 있다.
이 제한된 영역을 풀기위해서 기존에서는 non-discriminative object regions들까지 확장하여 activation 을 시키려고 진행하였으나, 위의 빨간색 박스와 같이 일부 feature map에서 그러한 진행상황까지 포함하고 있는 것을 확인할 수 있다.
따라서 이 논문에서는 기존에 있던 CAM 정보들을 적절하게 활용하여 전체 영역을 activate 하는 방식을 제안하고 있다.
TAP : Thresholded Average Pooling
GAP(Global average pooling) 을 대신 갈아끼운 방식이다.
기존 GAP의 식을 확인해보면, 각 feature 의 활성화된 영역을 고려하지 않고 뭉개버린다.
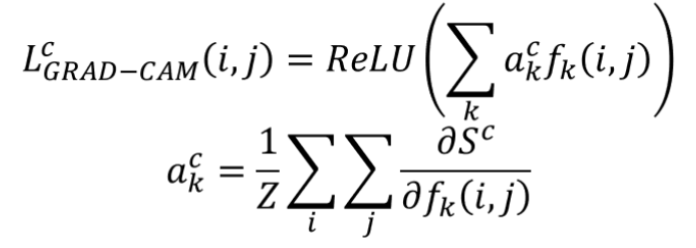
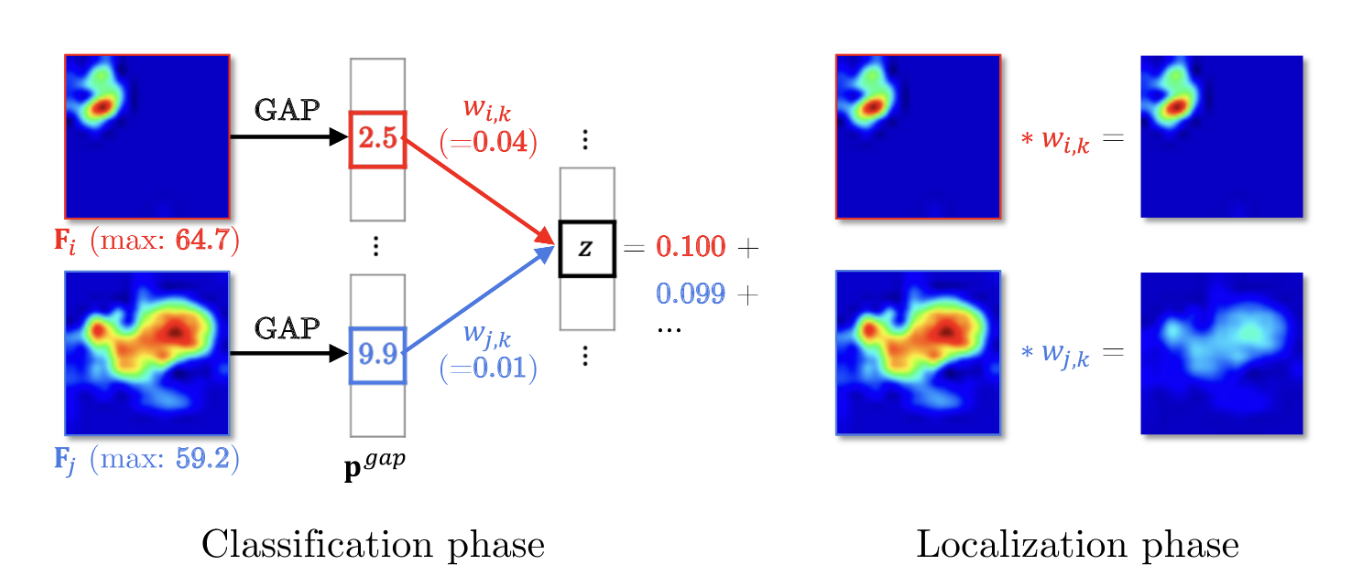
각 feature 한장 한장을 F_i, F_j 라하면, F_i의 활성화된 area가 작기 때문에, GAP 후에 F_i 에 해당하는 값을 확인해보면, 최대값을 비슷하나, F_j 에 비해서 과소 평가 되는 것을 확인할 수 있다.
0.1 와 0.099로 z에 대한 두 기능의 거의 동일한 영향력임에도 불구하고 가중치는 GAP에 의해 도입된 차이를 보상하기 위해 훈련 과정에서 매우 다르게 진행되는 것을 확인할 수 있다. Localization 단계 에서 활성화된 영역이 작은 가중 기능이 크게 과장되어있는 것을 볼 수 있다.
그래서, 이 GAP를 사용하는 대신 각 채널의 최대값에 비례하는 임계값보다 큰 활성화만 평균 풀링하는 TAP(Thresholded Average Pooling)를 제안하였다. 따라서 TAP은 각 채널을 과대 평가하거나 과소 평가하지 않고 평균 풀링을 진행한다.

NWC : Negative Weight Clamping
기존 CAM의 또다른 방식에서, negative weight 에 해당하는 값까지 날 것의 가중치까지 모두 합산해서 계산하는 과정이 있다.
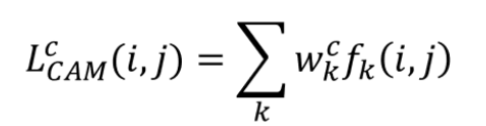
바로 이 과정! (w_k^c) 합산한거 다 쓰는 모습 !
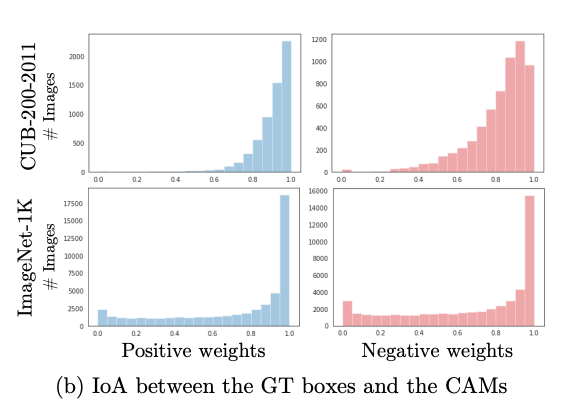
다음과 같은 결과를 보면, Negative weight 또한 일부 class 에서 positive 와 같이 활성화 되는 모습을 확인할 수 있다.
따라서 일부를 잃는 naively weighted averaging all the features 하는 방식 대신에 Negative Weight Clamping 을 진행한다. 양의 가중치에 해당하는 기능만을 사용하여 class activation map을 생성한다. 이러한 방식으로 가중치가 음수인 기능이 객체 영역의 활성화를 방해하는 것을 막을 수 있다.
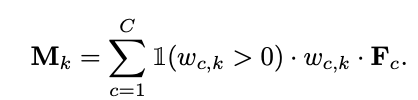
w_c,k 가 0일 경우에만 차례대로 더하는 모습이고, F_c는 그대로 와있는 모습을 확인할 수 있다.
표준 백분위수 (PaS) : Percentile as a Standard
마지막으로 논문에서 건든 내용은 binary mask 사용시 class activation map의 max 에 비례하는 임계값을 사용하는 것인데, 여기서 표준으로써 최댓값으로 처리해버리면, 임계값을 높게 만들어버리는 문제가 종종 발생한다고 한다.
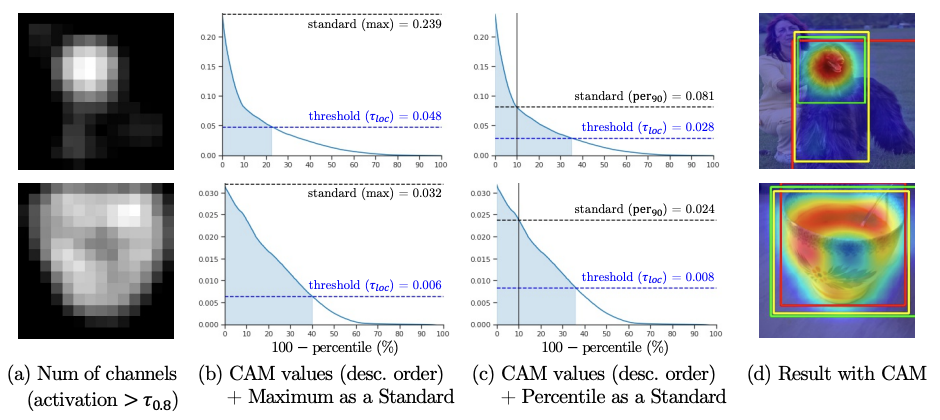
따라서 백분위수를 표준(PaS)으로 제안하였다. 높은 activation의 중첩과 관계없이 훨씬 더 견고하게 임계값을 결정할 수 있게 됨을 위의 이미지에서 확인할 수 있다.
결과적으로
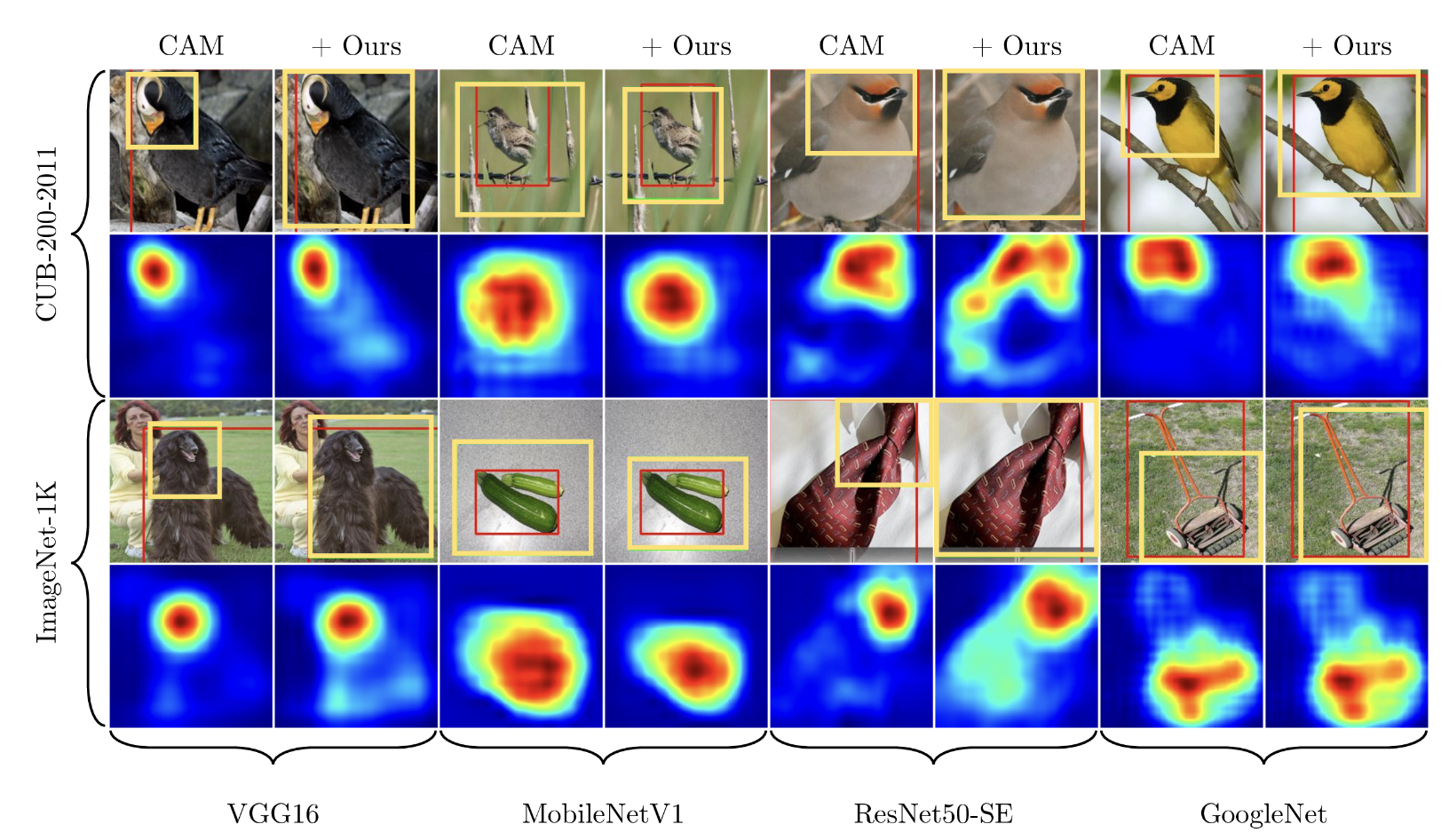
CAM의 예측 결과인 작은 영역으로 제한되는 문제점을 해결하였고, class activation map 또한 작은 영역에서 활성화 되는 것이 아닌, 전체를 아우르는 영역으로 활성화 됨을 확인할 수 있다.
어떤식으로 bounding box 가 쳐지나
모델의 OUTPUT 으로 총 3개의 결과물이 나오게 되는데, classification 결과로 가장 높은 class 의 prediction 값, rethinkingcam 이 지나가고 난 후 output 으로 feature map(score map) 중 iou 가 가장 높은 스코어 맵과 이에 대한 weight(=pred) 값이 나오게된다. 이 스코어맵을 바탕으로 4개의 양끝 좌표가 나오게 되고, 이 좌표로 bounding box 가 그려지게 된다.
참고자료
- 논문 : Rethinking CAM 1 : Rethinking CAM in Weakly Supervised Semantice SegmentationY. Song et al., "Rethinking CAM in Weakly-Supervised Semantic Segmentation," in IEEE Access, vol. 10, pp. 126440-126450, 2022, doi: 10.1109/ACCESS.2022.3220679.
- 논문 : Rethinking CAM 2 : Rethinking CAM for weakly supervised object detection
