
🗣️ Yolo v1에 대하여 알아보자 !
Object Detection의 메인 모델이라고 할 수 있는 Yolo 시리즈의 첫 시작, Yolo v1 논문을 리뷰해보자.
Yolo v1이란?
이전 리뷰한 논문들, RCNN 들은 2-stage detector로, localization 과 classification을 수행하는 network가 분리되어있었다. 이렇게 네트워크가 분리되었다는 것은 각 task가 순차적으로 진행된다는 의미이며, 여기서 bottleneck 현상 이 일어나 detection 속도가 느려지게 된다.
반면 1-stage detector는 하나의 통합된 네트워크가 두 task를 동시에 진행합니다. YOLO v1은 대표적인 1-stage detector로, FPS를 개선하여 real-time에 가까운 detection 속도를 보였습니다.
Yolo는 object detection 에 대해 새로운 접근방식을 제안한 모델로, 1-stage detector 하나로 통합된 네트워크의 대표적인 모델이며, 단일 신경망의 경우 evaluation 한번으로 이미지의 bounding box와 클래스 확률을 즉시 예측할 수 있다는 이점이 있다.
Yolov1에 대해 간략하게 정리해보면
- 1-stage detector의 대표적인 모델
- 이미지의 bounding box와 classification 확률 한번에 도출 가능
- 단일 네트워크이기 때문에 end-to-end 학습이 가능
- 초당 45frame으로 실시간 이미지 처리 가능
- localization 오류가 많으나 배경에 대한 false positive 예측률 거의 X
Yolo v1의 전반적인 개요
Yolo v1은 localization과 classification을 하나의 문제로 정의하여 network가 동시에 두 task를 수행하도록 설계하였다. input이미지를 특정 grid 로 나누고, 각 grid cell이 한번에 bounding box와 class 정보라는 2가지 정답을 도출하도록 구성되어있다. 또한 각 grid cell에서 얻은 정보를 잘 feature map 이 잘 encode할 수 있도록 독자적인 Convolutional Network인 DarkNet을 도입하였다. 이를 통해 얻은 feature map을 활용하여 자체적으로 정의한 regression loss 를 통해 전체 모델을 학습시킨다.
1-Stage detector
Yolo v1은 전체를 한번에 처리하는 단일 네트워크로 이루어져있다. 1-stage detector 방식은 다음과 같이 이루어진다.
-
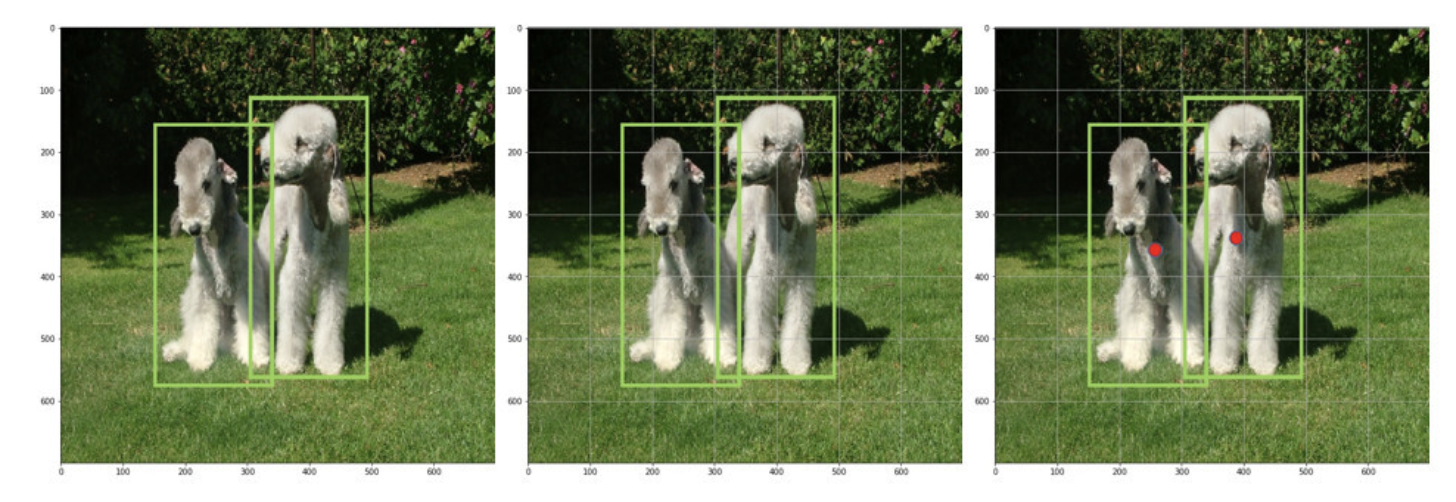
region proposal을 사용하지 않고 전체 이미지를 입력하여 사용한다. 우선 전체 이미지를 7 * 7 size의 grid로 나눠준다.
-
객체의 중심이
특정 grid cell에 위치한다면, 해당 grid cell은 그 객체를 detect하도록 그 파트에 할당된다. (나머지 grid cell은 그 객체에 할당되지 않는다. -
각각의
grid cell은 B개의 bounding box와 해당 bounding box에 대한 confidence score를 예측한다.confidence score는 해당 bounding box에 객체가 포함되어 있는지 여부와, box가 얼마나 정확하게 ground truth box를 예측했는지를 반영하는 수치를 나타낸다.
confidence score는
로 정의된다. 만약 gird cell 안에 객체가 존재하지 않는다면, confidence score는 0이 된다. 반대로 gird cell 내에 객체가 존재한다면 confidence score은 IoU값과 같아진다.
-
각각의 bounding box는 box의 좌표 정보(x, y, w, h) 와 confidence score이라는 5개의 예측값을 가진다. 여기서 (x, y)는 grid cell의 경계에 비례한 box의 중심 좌표를 의미한다. 높이와 너비는 역시 마찬가지로
grid cell에 비례한 값입니다.
여기서 주의할 점은 x, y는 grid cell 내에 위치하기에 0~1 사이의 값을 가지지만 객체의 크기가 grid cell의 크기보다 더 클 수 있기 때문에 width, height 값은 1 이상의 값을 가질 수 있다. -
하나의 bounding box는 하나의 객체만을 예측하며, 하나의 grid cell은 하나의 bounding box를 학습에 사용한다.
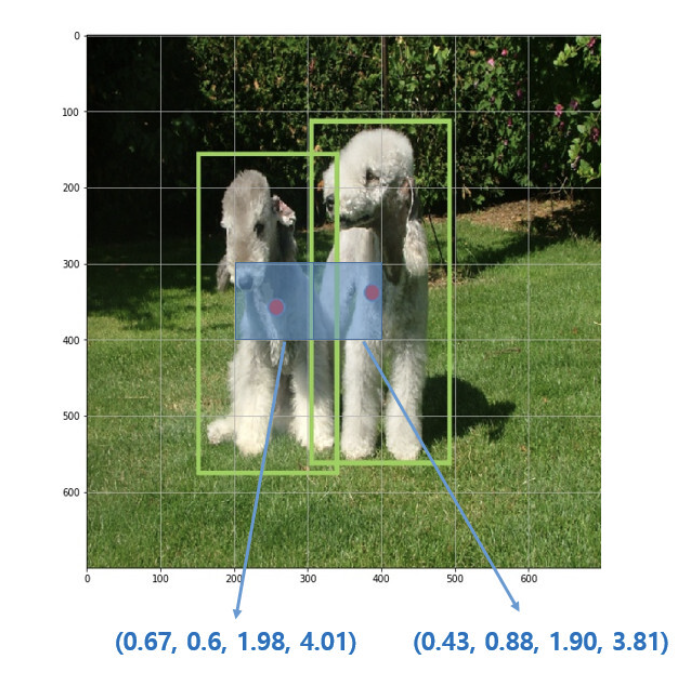
각 grid cell은 C개의 conditional class probabilities인 Pr(class_i | object) 를 예측하며, 이는 특정 grid cell에 객체가 존재한다고 가정하였을 때, 특정 class_i일 확률인 조건부 확률값이다. 다음과 같은 과정을 통해 위치, 크기, class 에 대한 정보를 예측할 수 있다.
- yolo v1 모델은 앞서 살펴본 최종 예측값의 크기인 7x7x30에 맞는 feature map을 생성하기 위해 DarkNet이라는 독자적인 Convolutional Network을 설계하여 사용한다. DarkNet에 이미지를 입력하여 7x7x30 크기의 feature map을 loss function을 통해 학습시킨다.
Object detection
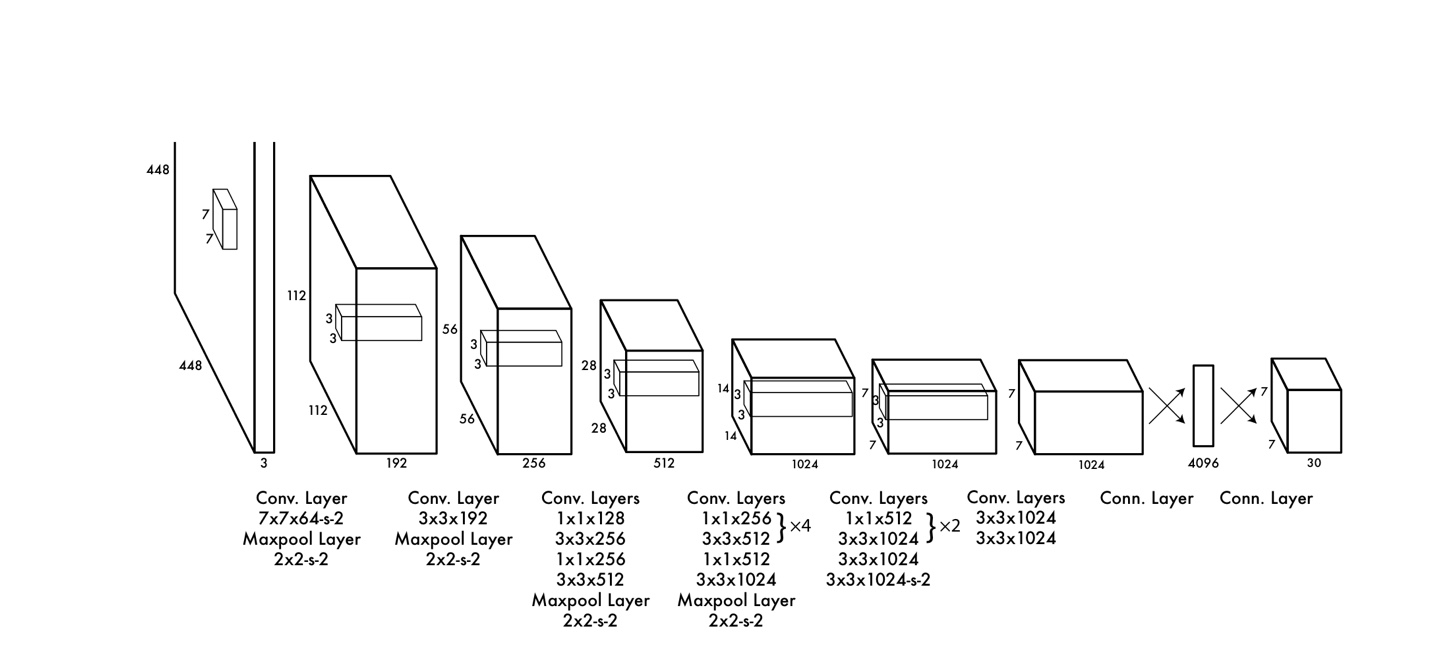
논문에서는 448x448 크기의 이미지를 입력받아 여러층의 layer를 거쳐 이미지에 있는 객체 위치와 객체의 정체를 알아내는 구조이다. 이를 1-stage detector라고 하는 것 !
object detection의 모델의 구조는 크게 두가지로 나뉘어져 있는데, backbone 과 head 로 이루어져있다. backbone은 입력받은 이미지의 특성을 추출하는 역할을 하며 head에서는 특성이 추출된 특성 맵을 받아 object detection 역할을 수행한다.
Backbone
논문이 출간되던 시기의 backbone 모델로는 VGG-16 를 많이 사용하였다. 이 모델의 경우 특성 추출 이 목적이기 때문에 classification에 focus된 모델로써 많이 활용되었으나, yolo v1 에서는 자신만의 backbone인 darknet이라는 모델을 만들었다. 결과적으로 DarkNet의 특성은 입력받는 이미지의 해상도가 448 448 로 VGG가 받던 224 224 보다 4배나 더 크고, 처리 속도가 빠른 결과를 가져왔다.
- 추가적으로
DarkNet은 CNN layer 20층으로 구성되어있으며, head 에는 CNN layer 4층, FCN 2층으로 구성되어있다.
Head
Head 에서는 마지막 출력값의 양식을 확인해야하는데, 448 * 448 해상도를 가진 이미지 한장을 입력받았을 때, 7730 size의 3차원 텐서를 출력값으로 내놓는다.
이는 출력값의 셀 하나가 원본 이미지의 64 * 64 영역을 대표하며, 이 영역에서 검출된 30개의 데이터가 담겨 있다는 의미이다. (448 / 7 = 64)
30개의 데이터는 다음과 같이 구성되어있다.
1. 해당 영역을 중점으로 하는 객체의 bounding box 2개(x, y, w, h, confidence)
2. 해당 영역을 중점으로 하는 객체의 class score 20개(객체 갯수가 20개이기 때문에)
한 cell 에서 2개의 bounding box를 검출하므로, 총 검출되는 박스는 7 7 2 = 98 이며, 이 98개의 box는 각각 confidence를 가지고 있다.
로 구할 수 있다. x, y 의 경우, 해당 셀에 대해 normalize 된 값이며, w, h 는 전체 이미지에 대하여 normalize 된 값이다.
loss function
손실 함수는 multi-task loss를 사용한다.
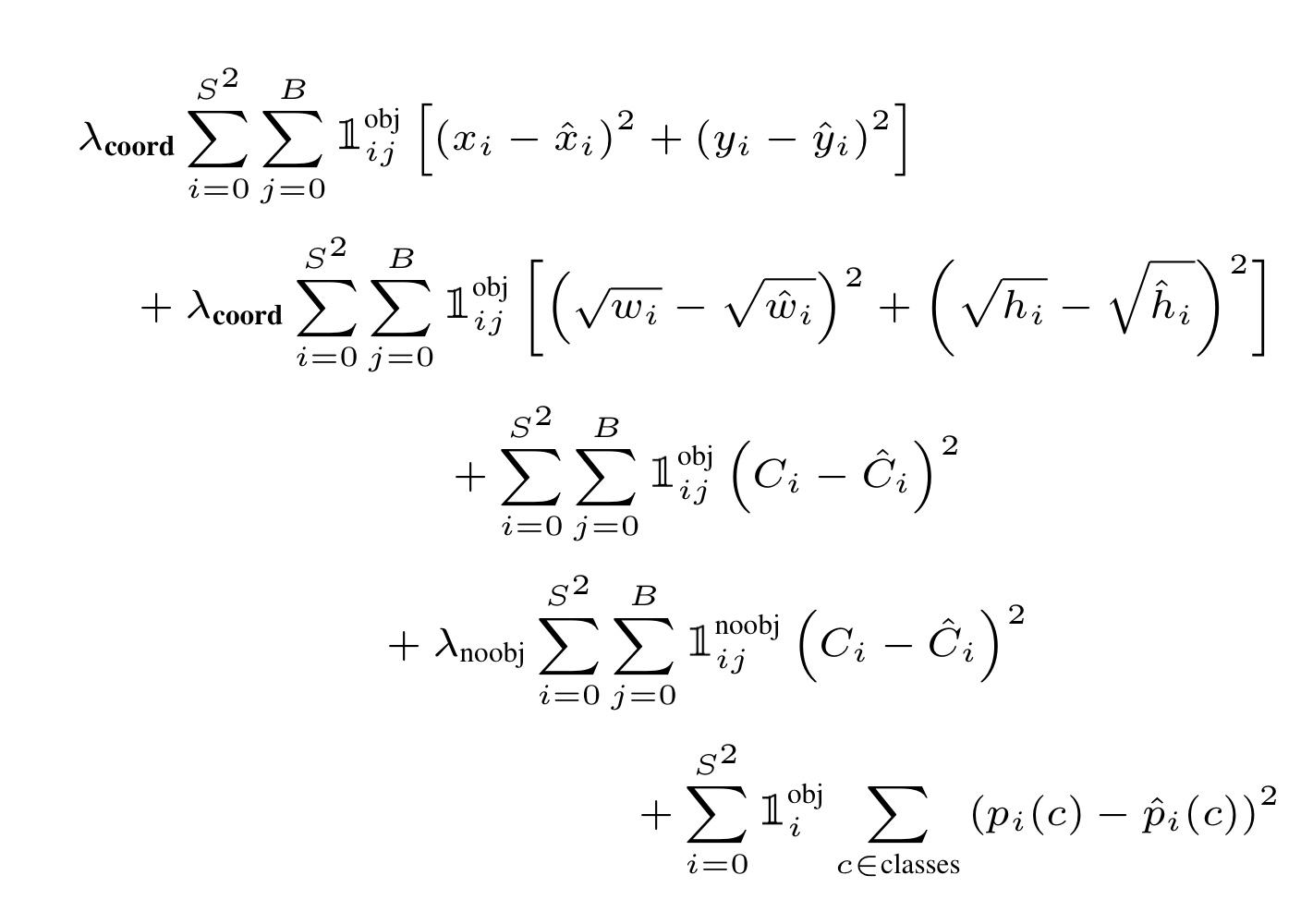
위의 두 줄은 bounding box 의 위치에 관한 손실을 나타내며(localization loss), 중간 3,4번 째 줄은 confidence score 에 관한 손실이며, 마지막 한줄은 class score 에 관한 손실이다. (classification loss)
여기서, localization loss confidence loss 는 해당 셀에 실제 객체의 중점이 있을 경우, 해당 셀에서 출력한 셀에서 얻은 2개의 bounding box 중 ground truth box 와 IoU 가 더 높은 bounding box 와 ground truth box loss를 계산한 것들이다.
Training
훈련 방식은 다음과 같은 방법으로 진행된다.
1. backbone : ImageNet 2012 dataset으로 1주일간 훈련을 진행한다.
2. Head : weight decay = 0.0005 , momentum = 0.9, batch size = 65, epoch = 135로 설정하였으며, 처음에는 learning rate 를 0.001로 맞춘 후, epoch = 75까지 0.01로 점점 상승시킨다. 이후 30회는 0.001로 훈련시키고 마지막 30회는 0.001로 훈련시킨다.
3. 데이터 증강(data augmentation)의 경우, 전체 이미지 사이즈의 20% 만큼 random scaling을 진행하고, translation 도 진행하며 원본 이미지의 1.5배 만큼 HSV를 증가시킨다.
