
Weakly Supervised Learning 이란?
기존 컴퓨터 비전 분야에는 크게 이미지 인식(Recognition) 과 이미지 분할(Segmentation) 과 객체 탐지(Object Detection)로 이루어져 있다. 이미지 분할과 객체 탐지 영역에서 Labeling 하는 과정에서는 많은 인력과 시간, 비용이 소모되게 되는데, (이미지 분할에서는 픽셀단위로 진행되기 때문에 라벨링이 더욱~ 많은 시간이 소모된다) Weakly Supervised Learning은 학습에 있어 필수적인 Label을 최대한 사용하지 않는 방법에 대해 연구하기 위하여 나타났다.
- 여기서 , 지도학습이란?
지도학습의 경우, 모델은 학습을 위해 (x,y) set를 사용하고, 여기서 x는 feature vector이고, y는 label를 나타낸다.- 비지도 학습이란?
모델은 학습을 위해 label 정보없이 feature vector만 사용하며, unlabeled data에서 pattern을 학습하는 것이다.- 준지도 학습이란?
label이 지정된 sample과 label 지정되지 않은 smaple의 조합이 training에 사용되는 학습 방법이다.

따라서 이미지 분할이나 객체 탐지 시, 상대적으로 약한 정보로 분할이나 탐지를 해보자는 아이디어이다. 약한 정보 란, 기존에 주어지던 분할 Mask(label) 또는 Bounding box는 강한 정보이고, Class 에 대한 label 정보는 약한 정보이다. 실제로 픽셀별로 분할을 하거나 bounding box를 치는 것은 해당 이미지의 어떤 물체의 Class가 있다라는 labeling 보다 비용이 훨씬 많이 들기 때문에 이미지 분할 또는 객체 탐지 시 class 에 대한 정보만을 이용하자는 학습 방식이다.
Semantic Segmentation 진행방식

(a)가 입력 이미지, (b)는 학습이 아닌 평가에 사용되는 Ground truth, (c)는 labeled mask 가 아닌 박스 형태로 해당 영역에 어떤 물체들이 있다는 box형태로 주어진 label이다.
라벨링 시 (b) 로 진행하는 경우가 (c)로 진행하는 경우보다 어려운 작업임을 알 수 있다. 따라서, 해당 논문에서는 사람과 말이라는 class 정보와 위치 정보인 bounding box 만을 이용하여 segmentation을 진행한다.
Recursive Learning 이란?
recursive : 재귀 - 반복해서 learning 한다 !
매 round마다 3가지의 후처리를 거친 후 segment된 영역을 다음 영역의 ground truth 로 사용하는 학습 방식이다.
여기서, ground truth란?
ground truth 는 학습하고자 하는 데이터의 원본 혹은 실제 값을 표현할때 사용되며, 모델의 결과와 ground truth 값을 비교하여 얼마나 정답에 근접하게 모델 결과가 나왔는지를 확인할 수 있는 잣대가 된다.
즉, ground truth는 ‘우리가 만든 모델이 우리가 원하는 정답으로 예측해주길 바라는 답’ 을 의미한다.
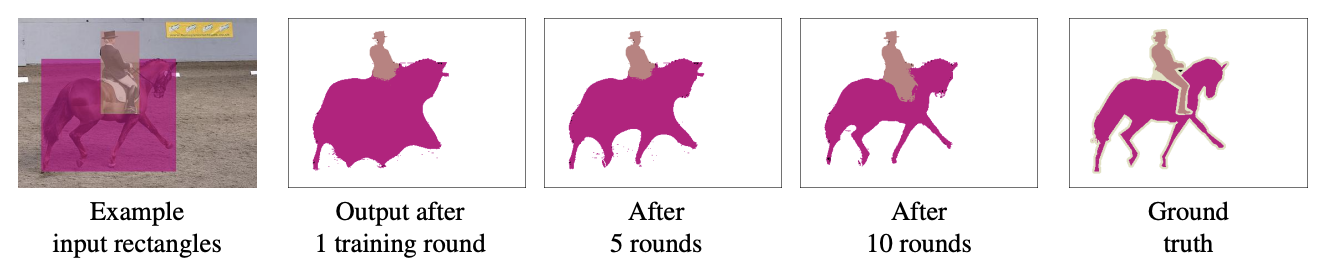
Recursive Learning 의 순서는 다음과 같다.
- 처음에는 ground truth의 형태가 bounding box이기 때문에 1round에는 이 box를 활용하여 모델을 학습시킨다.
- 다음 round 전부터 후처리 과정을 거치는데, bounding box 외부의 모든 픽셀을 배경 label로 설정한다.
(후처리)segment된 영역이 해당 bounding box에 비해 매우 작은 경우, (IOU < 0.5)는 bounding box에 그대로 label 로 가져간다.- 이미지 경계 부분을 더 잘 보존하기 위하여, 후처리 방법으로 자주 사용되는
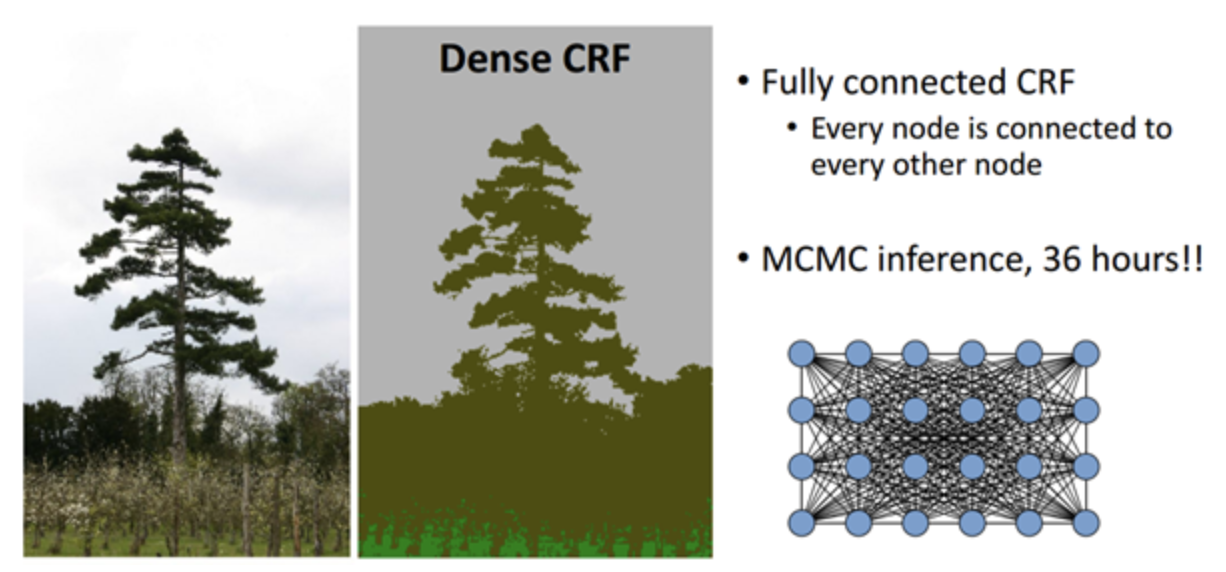
Dense CRF(Conditional Random Field)기법을 사용하였다.
Dense CRF란 ?
semantic segmentation 시에는 픽셀 단위의 조밀한 예측이 필요한데, 예측의 정확도를 높이기 위하여 segmentation을 수행한 뒤 생기는 잡음을 없애는 후처리 용도로 사용한다.

CRF의 수식을 살펴보면 unary term(단항) 과 pariwise term(쌍항) 으로 이루어져 있으며, x는 각 픽셀의 위치에 해당하는 픽셀의 label이며, i와 j 는 픽셀의 위치를 나타낸다. unary term 은 CNN 연산을 통해 얻고,
픽셀 간 디테일한 예측의 경우 pairwise term 이 중요한 역할을 한다. 픽셀값의 유사도와 위치적인 유사도를 함께 고려하기 때문이다.

pairwise term 을 좀 더 뜯어보자 !
k(f,f) 항 을 보면,
2개의 kernel 로 구성되어 있으며, 표준편차 값인 alpha, beta, gamma값으로 scale을 조절할 수 있다. Gaussian kernel은 비슷한 위치와 컬러를 갖는 픽셀들에 대해 비슷한 label이 붙을 수 있도록 하며, 두번째 gaussian kernel은 원래 픽셀의 근접도에 따라서 smooth 수준을 결정한다. p_i, p_j 는 픽셀의 위치(Position) 를 나타내고, I_i, I_j 는 픽셀의 컬러값(Intensity) 을 나타낸다. (*여기서 smoothness kernel은 노이즈를 줄이거나 외부의 영향을 최소화하기 위한 커널이다)
참고자료 (이미지)
http://swoh.web.engr.illinois.edu/courses/IE598/handout/fall2016_slide15.pdf
다음과 같은 과정을 거쳤을 때, 10 rounds 쯤을 거치게 되면 예측 맵은 ground truth와 꽤 디테일하게 동일한 결과물을 만들어내는 것을 볼 수 있다.
추가적인 성능 개선 : GrabCut,GrabCut+,MCG
grabcut은 기초적인 computer vision 알고리즘으로, 물체가 있는 곳에 bounding box를 치면 물체 외의 배경 부분을 제거해주는 알고리즘이다.
grabcut+ 또한 사용하였는데, 이는 MCG(Multiscale combinatorial grouping) 알고리즘을 적용한 것을 ground truth로 사용한 알고리즘이다.
(MCG 알고리즘 : 그룹을 세분화시켜서 나누는 방식)
이렇게 세가지 알고리즘을 추가적으로 넣어 성능을 개선시킨 결과물은 다음과 같다.
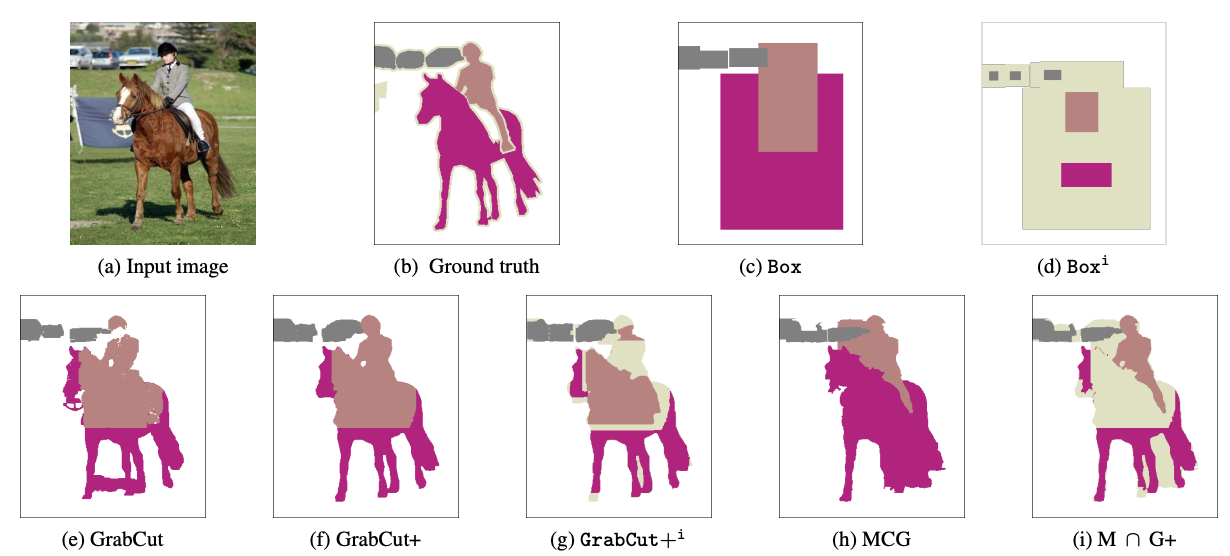
초기 ground truth 결과물로, i가 붙은 이미지의 경우에는 해당 방식들에 ignore region 이라는 방법을 사용하여 box 내부의 20%만 ground truth mask 로 사용하고, 나머지 영역은 무시하겠다는 의미이다. 정확도를 높이는 방식 중 하나로 사용된다.
모델의 결과 및 성능
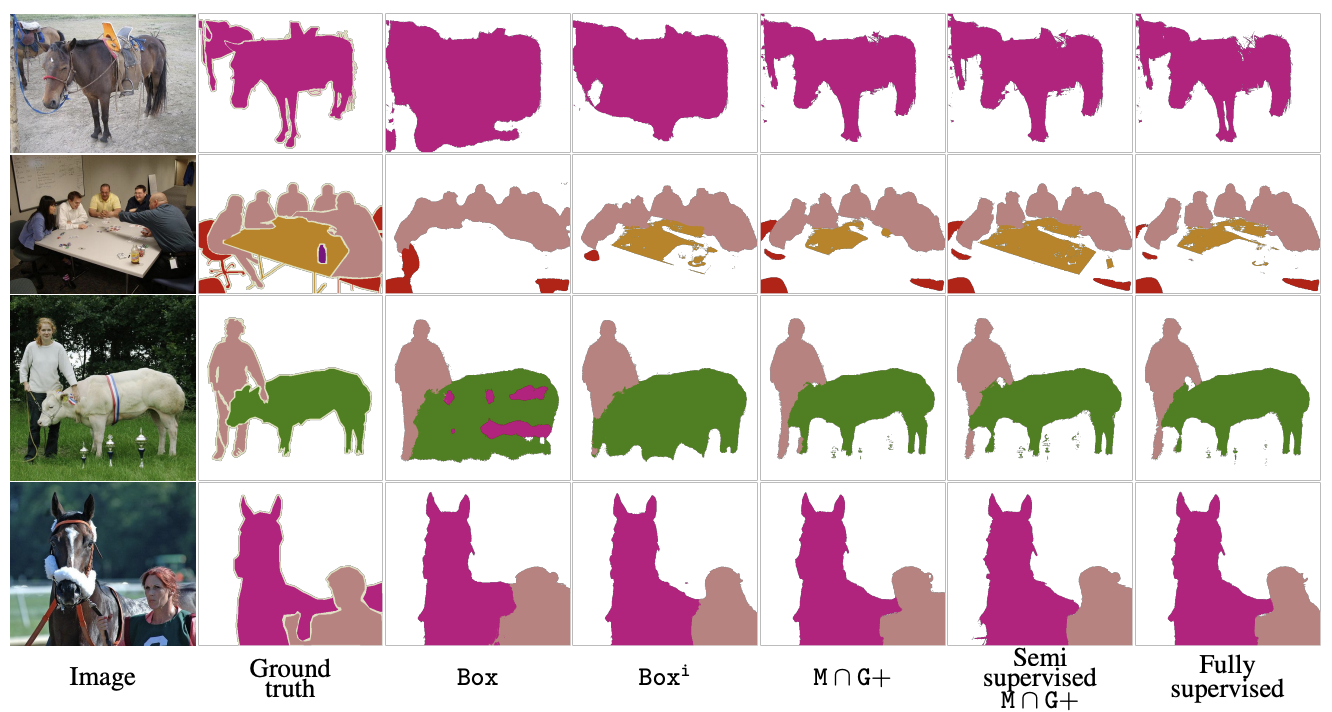
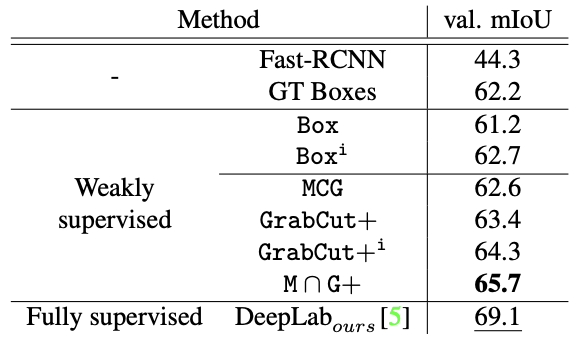
결과적으로, 위에서 아래로 내려갈수록 (알고리즘을 적용할수록) 점점 Mean IOU 가 좋아지는 것을 확인할 수 있다.
중요하게 봐야할 것은, label이 섬세하게 되어있는 ground truth를 사용한 fully supervised 방법의 성능과 비교하였을 때에도 3.4 정도만 차이가 나는 것으로 보아, 구체적으로 labeling된 mask 가 없어도 weak information 만으로 좋은 성능을 내는 결과를 확인할 수 있다.
정리
- labeling 의 문제점과 불편사항을 weakly supervised learning으로 해결하였다.
- 기존의 computer vision 알고리즘을 조합하여 fully supervised model과 비슷한 수준의 결과물을 낼 수 있었다.
Weakly supervised learning 과 CAM을 연관지어 생각해보자 !

다음 논문 을 참고하면, CAM에서 나온 GAP(global average pooling)을 처음부터 이어붙여 training 시킨 모델을 객체 인지 뿐만아니라 행동 인지 등 다양한 도메인에서 실험을 진행해봤는데,
Action, Event 같이 한 object가 아닌 것도 CAM을 통해 visualization이 가능한데, 예를 들어 rowing을 하는 것은 사람이 배를 타고 노를 젓는 활동이므로 이러한 영역에 activation이 일어난다.
이런 방식을은 이미지에 concept이 tagging 이 잘 되어서 예를들어 cleaning the floor 의 어느 부분에서 activation 되었는지를 (위치 정보 학습 X) 모두 weakly supervised 임에도 잘 CAM이 작동 되는 것을 확인할 수 있다.
https://colab.research.google.com/drive/1B4Fj-VCrMek8HIrlIKRPohCqSwqq7VrQ?usp=sharing
