
Mask-RCNN 이란?
마지막에 Faster-RCNN을 리뷰했었는데, Faster-RCNN은 Fast-RCNN + RPN을 더한 모델이였다. Mask-RCNN은 Faster-RCNN에서 어떻게 달라졌을까?
- Faster-RCNN에 Classification, Bounding Box Regression 구간에
Mask-branch가 추가되었다.- RPN 전에
FPN(Feature Pyramid Network)과정이 추가되었다.- Image Segmentation에서
RoI pooling으로 진행된다.
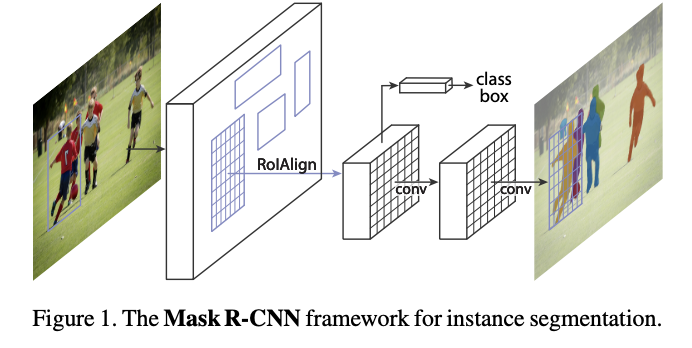
Mask RCNN의 개략적인 전체 흐름은 다음과 같다.
1. N * N 사이즈 의 input image가 주어졌을 때, 800 ~ 1024의 사이즈로 이미지를 resize 한다.
2. Backbone Network의 input size 로 맞추기 위해 1024 * 1024 로 맞춰준다.
3. ResNet-101을 통해 각 layer(stage)에서 feature map 을 만든다. (C1, C2, C3, C4, C5)
4. FPN 을 이용하여 이전의 생성된 feature map에서 다른 feature map을 만든다. (P2, P3, P4, P5, P6)
5. 마지막 feature map에 RPN 을 이용해 classification, bounding box regression output 을 만든다.
6. Output으로 얻은 bounding box regression 값을 원래 이미지로 영사하여 anchor box 를 생성한다.
7. Non-max-suppression 을 통해 생성한 anchor box 중에 score가 가장 높은 anchor box를 남겨두고 나머지는 제거한 후, 크기가 다른 anchor box들을 RoI align 을 통해 size를 맞춘다.
8. Fast-RCNN에서의 classification, bounding box regression 과 mask branch에 anchor box값을 통과 한다.
Mask-RCNN에서 나온 추가된 과정들을 자세하게 확인해보자.
Resize Input Image
Mask-RCNN의 backbone으로 ResNet-FPN 을 사용하는데, ResNet 에서는 이미지의 input size를 조절하는 전처리 과정을 진행해야한다. 원본 이미지의 width, height 중 더 짧은 쪽을 target size로 resize 한 후, 더 긴쪽은 aspect ratio 를 보존하는 방향으로 resize된다. 논문에서 말하길, 더 긴 쪽이 maximum size를 초과하면 maximum size로 resize 되며, 더 짧은 쪽이 aspect ration를 보존하는 방향으로 resize된다.
- Input : image
- Process : image pre-processiong
- Output : resized image
Bilinear interpolation 이란?
이 resize 과정 에서 2D 선형보간법인 bilinear interpolation 방식을 활용한다. 여기서 Interpolation이란, 알려진 지점의 값 중간에 위치한 값을 알려진 값으로부터 추정하는 것을 말한다.
Bilinear interpolation 은 이설명을 참고하였다.
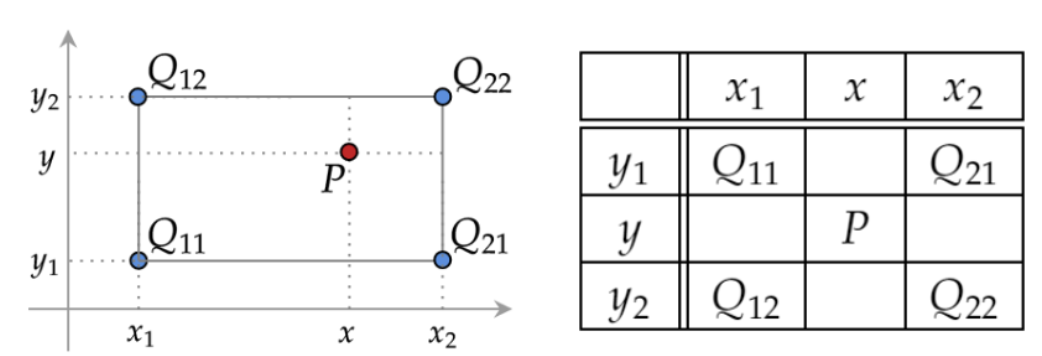
사각형의 변 및 내부의 임의의 점에서 값을 추정한다고 한다면,
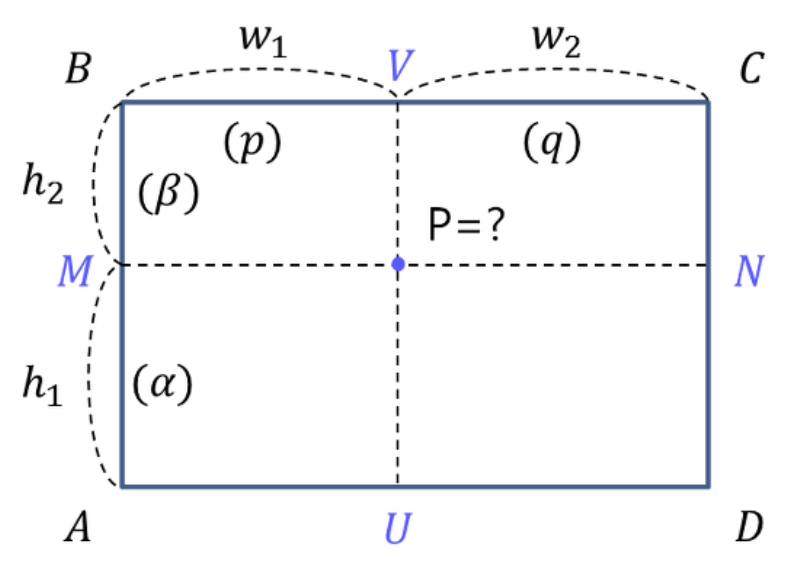
그림과 같이 점 P에서 닿기까지의 거리를 각 변에 표시하였다. 각각의 값은
α=h1/(h1+h2), β=h2/(h1+h2), p=w1/(w1+w2), q=w2/(w1+w2)
이 되며, P는 최종적으로
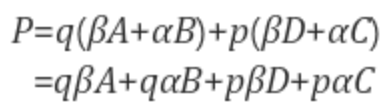
계산 방식은 A와 B를 보간하여 M을 얻고, C와 D를 보간하여 N을 얻은 뒤 M과 N을 보간하여 P를 얻는 방식으로 진행된다.
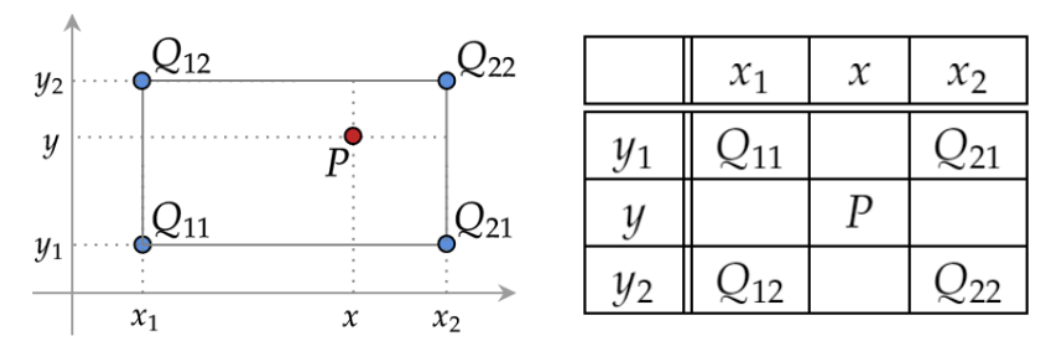
여기서 값을 구하는 방식을 적용하면
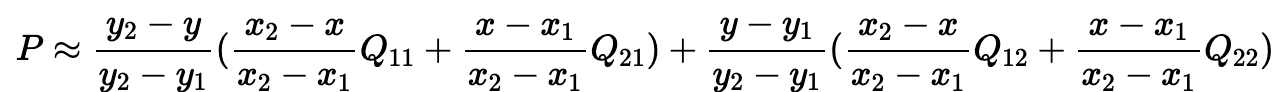
x,x1,x2,y,y1,y2 는 4개의 sampling point 좌표 이며, Q11, Q21, Q12, Q22는 sampling point 에 인접한 cell값이다.
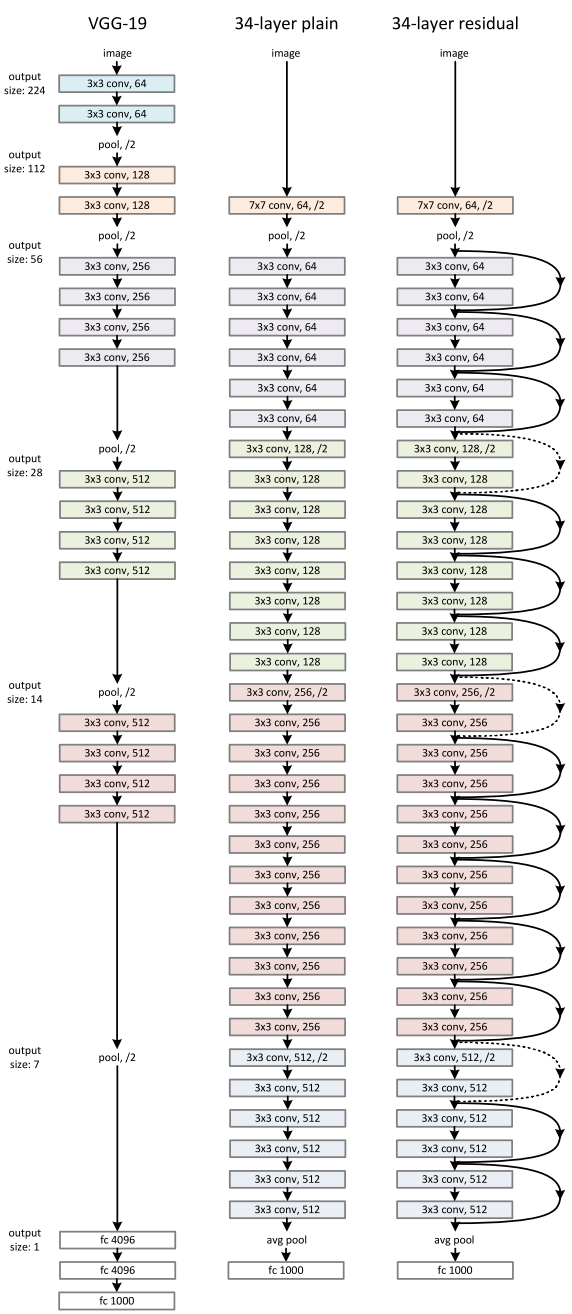
ResNet-101 Backbone 모델
ResNet-101 모델의 전체적 구조는 다음에서 확인할 수 있다 (VGG19랑 같이 존재)
Faster-RCNN의 경우에는 backbone 에서 나온 결과값이 1개의 feature map에서 RoI를 만들고,
classification 및 bounding box regression을 진행하였다.
여기서 남은 한개의 feature map을 만드는 과정 중에서 layer를 통과할수록 중요한 feature map만 남고 중간 feature map들은 모두 잃어버리기 때문에 -
" 이 과정에서 최종 layer에서만 다양한 크기의 object들을 검출해야하, 여러 scale 값으로 anchor를 생성하기 때문에 비효율적이게된다. "
이를 극복하기 위한 방법이 FPN(Feature Pyramid Network) !
FPN은 이내용 을 참고하여 공부하였다. FPN 이란, 컴퓨팅 자원을 적게 차지하며 다양한 크기의 객체를 인지하는 방법을 제시한다.
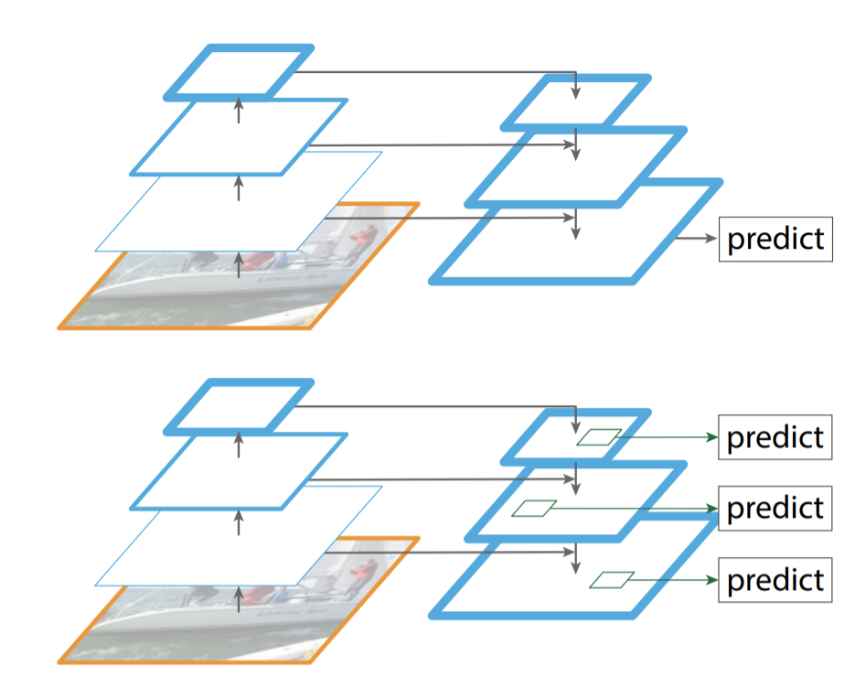
FPN 구조는 다음과 같은데, 여기서 Pyramid 란, convolutional network에서 얻을 수 있는 다른 해상도의 feature map들을 쌓아올린 형태이다. level 은 pyramid 각 층에 해당하는 feature map 이다.
feature map 의 경우, 입력층에 가까울수록 높은 해상도를 가지고, 가장저리, 곡선 등과 같은 저수준 특징(low-level feature) 을 갖는다. 입력층을 지나가 깊은층에 갈수록 feature map이 낮은 해상도를 가지며, 질감, 물체 일부 등 class를 추론할 수 있는 고수준의 특징(high-level feature)을 가지고 있다.
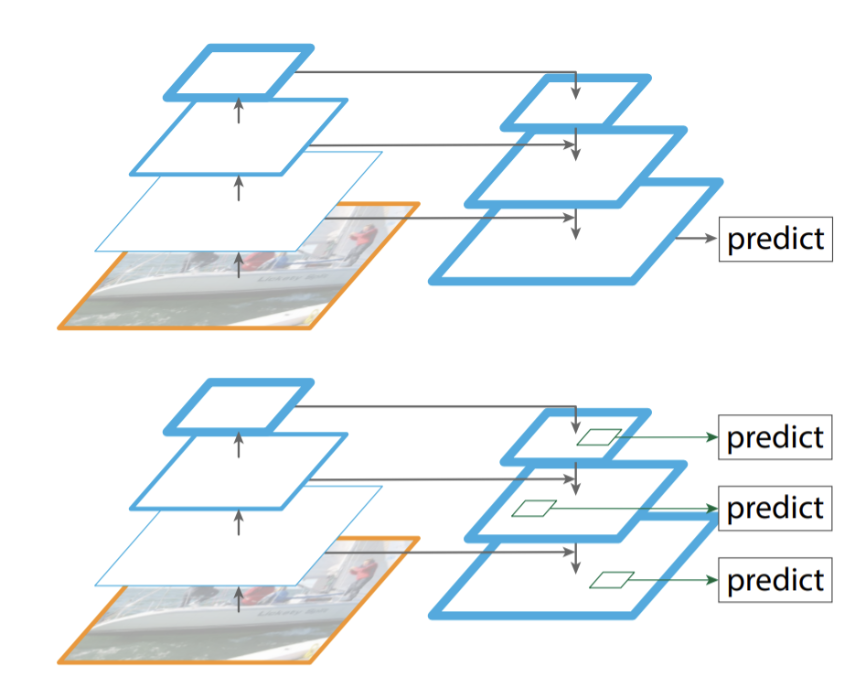
다양한 크기의 객체를 detection 하도록 모델 학습 시, 다양한 방식들이 존재하였으나(featurized image pyramid, single feature map, pyramidal feature hierarchy) 각각의 단점이 존재하는 와중
feature pyramid network는 임의의 크기 single-scale 이미지를 convolutional network에 입력하여 다양한 scale의 feature map을 출력하는 네트워크이다. FPN은 새롭게 설계된 모델이 아닌 기존 conv network에서 지정한 layer 별로 feature map을 추출하여 수정을 진행한 네트워크이다. FPN이 feature map을 추출해 피라미드를 건축하는 과정은
Bottom-up pathway: 이미지를 conv network에 입력하여 forward pass하여 2배씩 작아지는 feature map을 추출한다. 이 때, 각 stage의 마지막 layer의 output feature map을 추출한다. 각 stage의 마지막 layer 이 output feature map을 추출한다. ( 위에서 언급한 듯 더 깊은 layer 일수록 더 강력한 feature를 보유하고 있기 때문이다.)
Mask-RCNN 에서는 ResNet-101 을 backbone으로 사용하고 있기 때문에 마지막 residual block의 output feature map을 활용하여 feature pyramid를 구성하고, Output값을 {c2,c3,c4,c5} 라고 지정한다.
이는 conv2{4stride}, conv3{8stride}, conv4{16stride}, conv5{32stride}의 output feature map을 의미한다. (여기서 conv1의 경우, output feature map이 너무 많은 메모리를 차지하기에 피라미드에서 제외되었다고 한다.)
Top-down pathway: 각 pyramid level에 있는 feature map을 2배로 upsampling 하고, channel 수를 동일하게 맞춰주는 과정이다.
각 pyramid level의 feature map을 2배로 upsampling 해주면, 바로 아래 level의 feature map과 크기가 같아진다. (여기서 사용되는 방식이 nearest neighbor upsampling 방식이다.)
그 다음, 모든 pyramid level의 feature map에 1 * 1 conv 연산을 적용하여 channel을 256으로 맞춰준다. upsampling이 지난 feature map과, 바로 아래의 level feature map 둘을 element-wise addition 연산 을 하여 lateral connections 과정을 진행한다. 마지막으로 feature map 에 3 * 3 conv 연산을 하여 나온 feature map 이 {p2, p3, p4, p5} 가 되는 것이다 !
이것은 각각 {c2, c3, c4, c5} feature map의 크기와 같다.
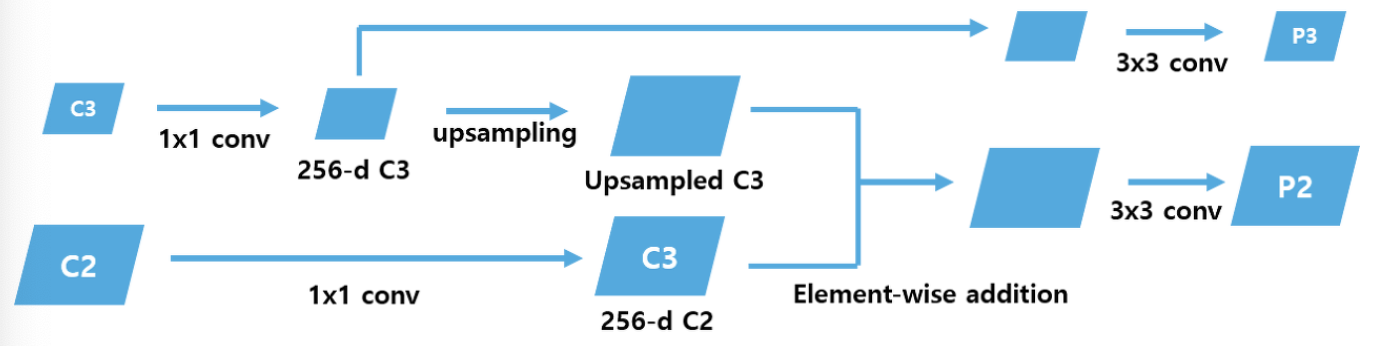
결과적으로 FPN 과정에서는 single-scale 의 이미지를 입력으로 넣어 4개의 서로다른 scale을 가진 feature map을 얻게 되고, 단일 이미지의 크기를 입력받기에 빠르고 메모리 차지도 덜하다. 또한, 4개의 multi-scale feature map을 출력하기 때문에 더 높은 detection 성능을 보여준다 !
가장 중요한 성능은, detection을 진행할 때 고해상도 feature map은 저수준 특징을 가지지만, 객체의 위치에 대한 정보를 상대적으로 정확하게 보존하고 있는데, 이 고해상도 feature map의 특징을 element-wise addition 하여 저해상도 feature map에 전달하기 때문에 작은 크기의 객체들을 더 잘 detect한다는 이점도 !
FPN에서 이전 정보를 유지할 수 있게 되면서 , 더이상 여러개의 scale값 으로 anchor를 생성할 필요가 없게 되었으며
동일한 scale의 anchor를 생성한다. 따라서 작은 feature map에는 큰 anchor를 생성해 큰 object를,
큰 feature map에서는 작은 anchor를 생성하여 작은 object를 detect할 수 있게되었다고 한다.
ResNet-101 속 FPN을 진행하며 C1, C2, C3, C4, C5 의 feature map을 생성하고, C1은 사용하지 않으며(C1은 너무 많은 메모리를 차지 !)C5부터 F2, F3, F4, F5, F6 이렇게 5개의 feature map이 생성된다. 이때 F5에서 maxpooling을 통해 F6을 추가로 생성한다.
RPN 통과하기
Faster-RCNN 에서 언급하였듯이, RPN의 구조는 아래 이미지와 같으며, anchor box를 추려주는 과정을 진행해준다.
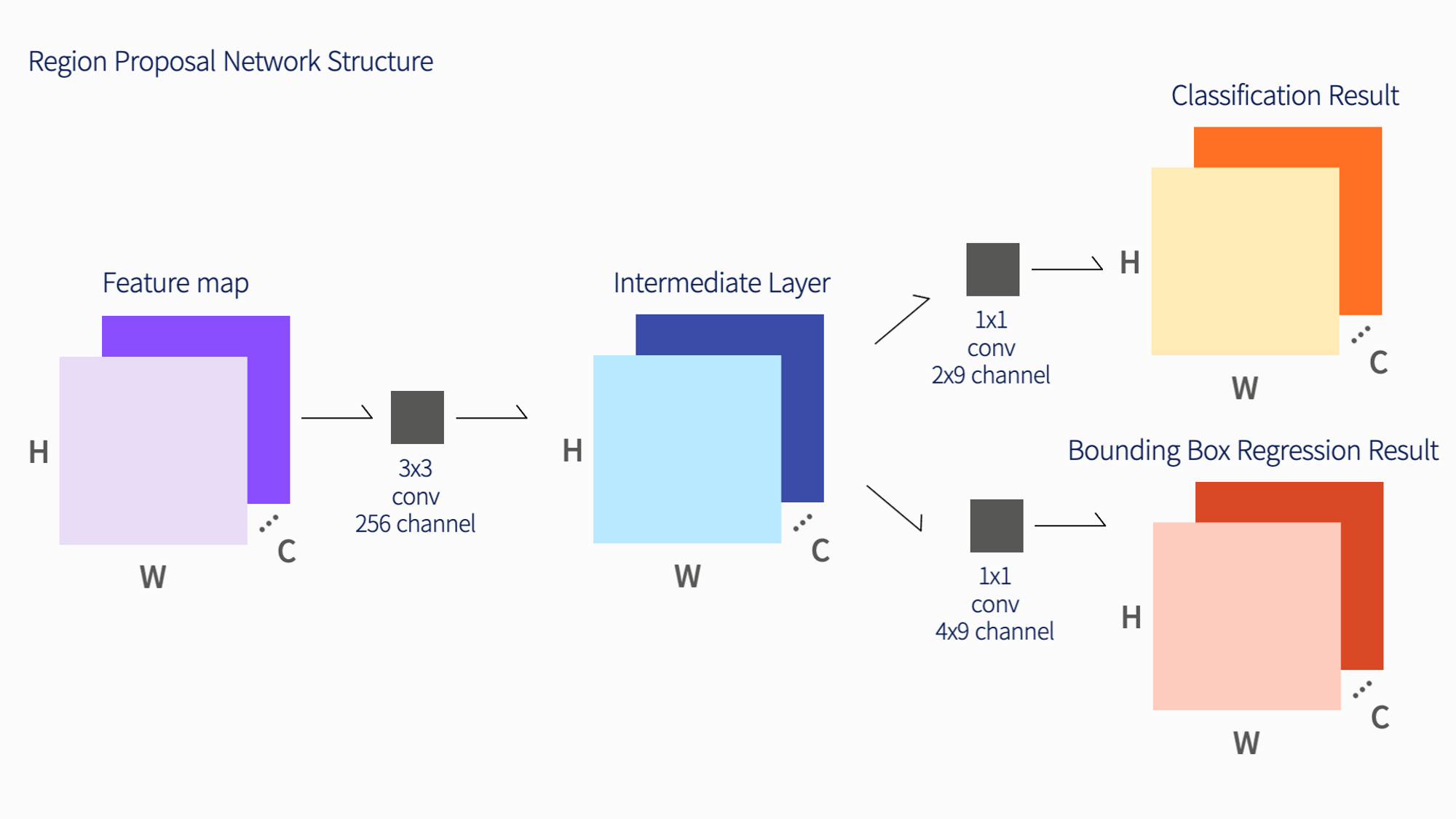
ResNet-101 + FPN 을 통해 생성된 F2, F3, F4, F5, F6을 각각 RPN 모델에 전달을 진행한다. Mask-RCNN에서는 1개의 scale의 anchor를 생성하므로 각 pyramid feature map 마다 scale 1개 * ratio 3개 = 3개의 anchor를 생성한다. 이외의 과정들은 모두 RPN을 동일~ 하게 따라간다.
Non-Max-Suppression 과정 진행하기
한국말로는 비최대억제라고도 하는 non-max-suppression 이란, object detector가 예측한 bounding box 중 정확한 bounding box를 선택하도록 하는 기법이다.
이미지에서 객체는 다양한 크기와 형태로 존재한다. 완벽 검출을 위해 object detection 알고리즘은 여러개의 bounding box를 생성하는데, 하나의 bounding box를 선택해야하는 과정에서 적용하는 기법이 이 NMS가 된다.
작동 과정을 간단하게 보면 다음과 같다.
-
하나의 class 에 대한 bounding box 목록에서 가장 높은 점수를 갖고 있는 bounding box를 선택하고, 목록에서 제거한다. 이를 final box에 추가한다.
-
선택된 bounding box를 bounding boxes 목록에 있는 모든 bounding box와 IoU를 계산하여 비교한다.
IoU가 threshold 보다 높으면 bounding boxes 목록에서 제거한다. -
bounding boxes 목록에 남아있는 bbox 에서 가장 높은 점수를 가진 것을 선택하고 목록에서 제거한다. 이를 final box에 추가한다.
4.선택된 bounding box를 목록에 있는 다른 box들과 IoU를 비교한다. threshold보다 높으면 목록에서 제거한다.
- bounding boxes 목록에 아무것도 안남을 때 까지 반복, 각 클래스에 대해서도 반복한다.
다음 과정에 대한 시각적 자료는 여기를 참고하면 된다 !
이렇게 해서 하나의 bbox를 크기별로 쏙 빼낸다. 이게 anchor box !
RoI align 진행하기
기존의 Faster-RCNN 에서도 RoI pooling 을 진행하였는데, 그때는 object detection을 위한 과정이였기 때문에 정확한 위치 정보를 담는 것이 존재하지 않았으나, 이제는 위치 정보를 명확히 알고싶다 !
RoI Pooling 방식은 RoI 가 소수점 좌표를 가지면 반올림하여 Pooling을 진행했기에 input image 의 원본 위치정보가 왜곡되어 classification 하는데 문제가 되지 않지만, 픽셀별로 detection하는 경우에는 개체에 대한 정보가 일부 누락되기 때문에 문제가 발생한다.
RoI align과 RoI Pooling의 중요한 차이점은 양자화(Quantitization) 이다. RoI Align은 데이터 pooling 에서 양자화를 사용하지 않는다.
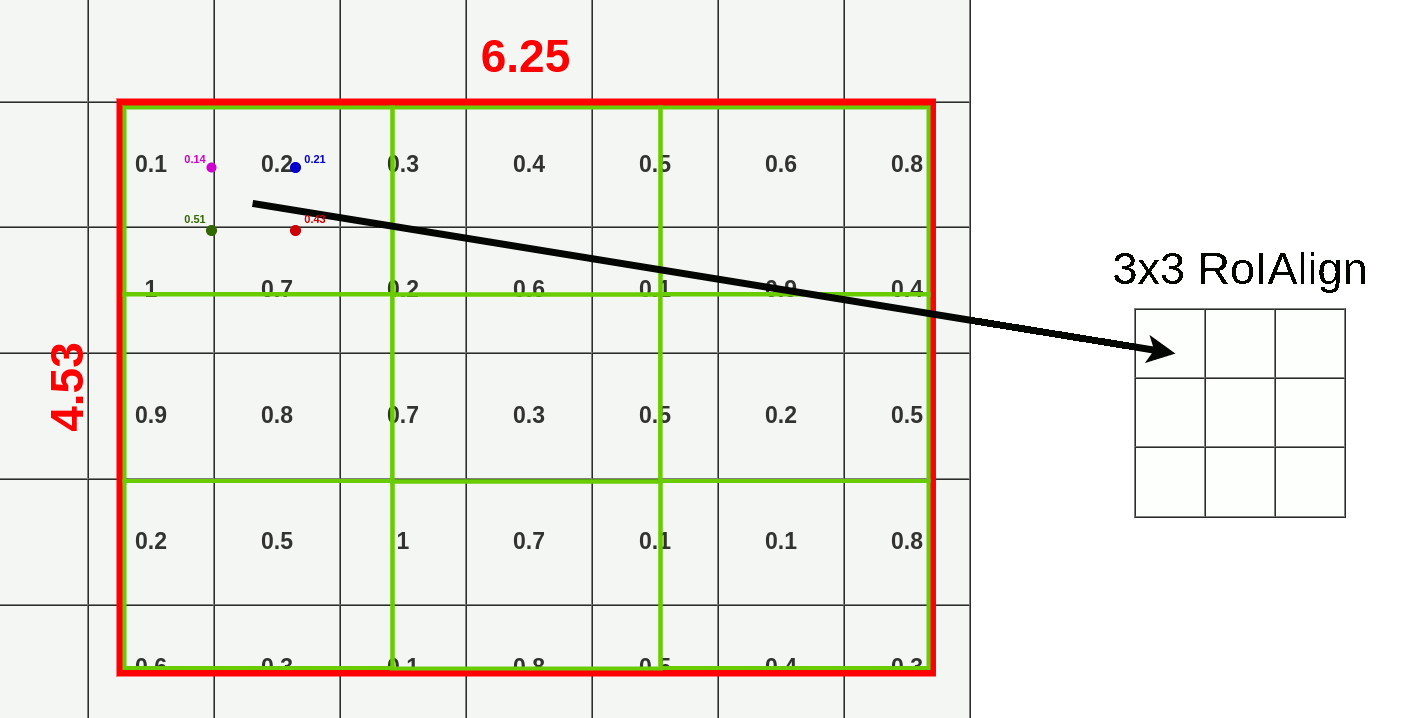
RoI align 에서는 위에서 설명한 Bilinear interpolation을 활용하여 값을 선형 보간하고, 하나의 cell에 있는 4개의 sampling point에 대해 max pooling 을 진행한다. 이 과정을 통해 RoI Align 이 RoI pooling 보다 전체 영역을 사용하여 데이터를 풀링한다는 것을 확인할 수 있다.
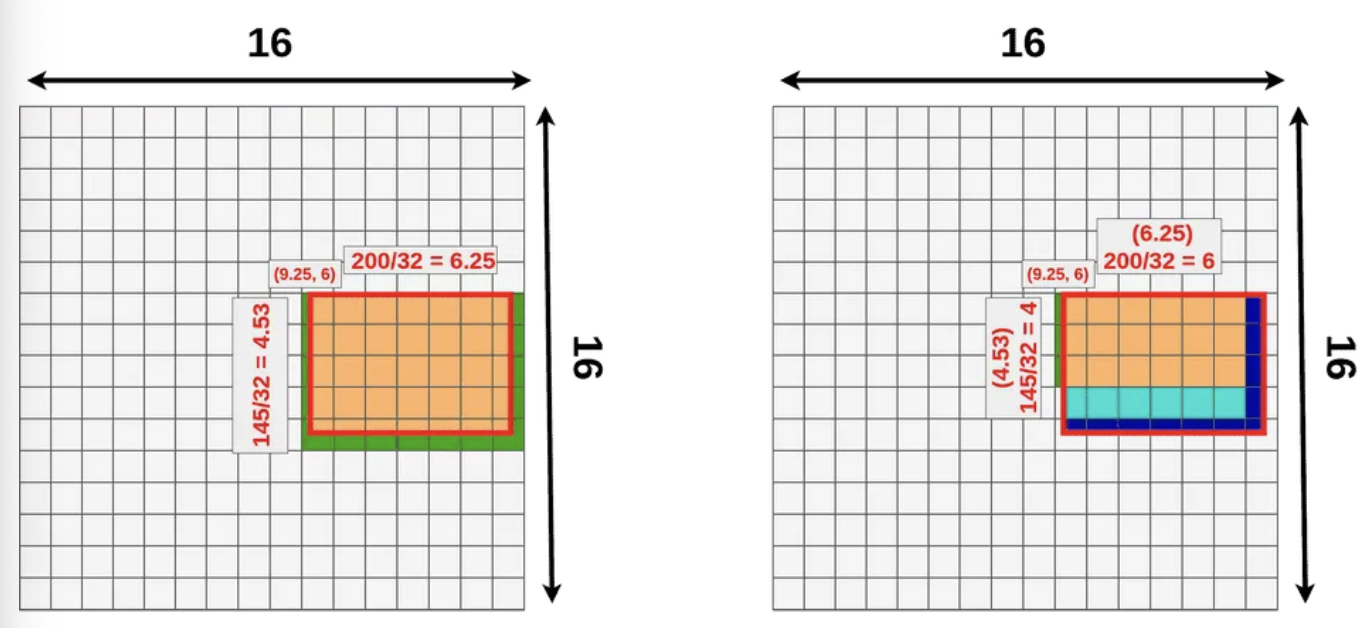
다시 ! Bilinear interpolation이란?
2차원 좌표 상에서 두 좌표가 주어졌을 때 중간에 있는 값을 추정하는 방법이다. 이 과정을 모든 cell에 대해 반복한다.
이로써 여러 scale을 가진 feature pyramid {p2, p3, p4, p5, p6} 이 생성되었다. 또한 RPN 과 Proposal layer를 거쳐 N 개의 RoI가 선택되었다. feature pyramid 에서는 multi-scale feature map이므로 RoI를 어떤 Scale의 feature map 과 매칭시킬지 결정해야하는데, 위의 공식에 따라서 매칭을 진행한다.
w,h는 RoI의 크기를 의미하고, k는 feature pyramid의 level의 index를 의미한다.
RoI align 에 관해서는 논문에서 깊게 다루지 않았기 때문에 추가적으로 이 자료를 확인하며 작성하였다.
마무리 과정 : Classification + Bounding box regression
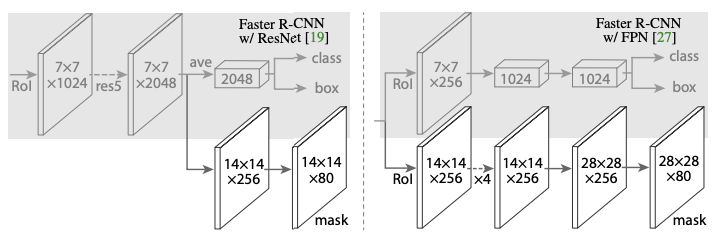
RoI Align 과정을 통해 얻은 7 * 7 크기의 feature map을 FC layer에 거쳐 classification branch 와 bbox regression branch에 전달한다. 여기서 최종적인 class score 와 bbox regressor 를 얻을 수 있다.
추가적으로 mask-rcnn에서 Mask Branch에도 전달을 하는데, mask branch는 3 3 conv - ReLU - deconv(by2) - deconv(by 2) - 1 1 (* k) conv layer 로 구성되어있다. (K 는 class 수)
이를 통해 14 14 ( K) size의 feature map을 얻을 수 있다. 이 feature map은 class 별로 생성된 binary mask 라고 할 수 있다. 14 14 ( K) size의 feature map 중 앞에 classification branch 에서 얻은 가장 높은 score의 class 에 해당하는 feature map을 선정하여 최종 prediction에 사용한다.
여기서 하나의 feature map 이 선정되는 셈 !
이후에 각 feature map의 cell 별로 sigmoid 함수를 적용해 0부터 1사이의 값을 가지도록 정규화를한다.
Loss Function 확인하기
Mask-RCNN에서는 multi-task loss function을 통해 네트워크를 학습시키는데, L_cls는 classification loss, L_box는 bounding box로 Faster-RCNN과 동일하다.
L_mask 는 mask loss 로 binary cross entropy loss값이다.
길고긴 Mask-RCNN 리뷰가 끝이났다..
Mask-RCNN의 장점
-
3개의 branch를 동일하게 학습하지는 않지만, inference 시간을 줄여주고 정확도가 훨씬 높게 상승되었다.
-
당시 instance segmentation 과제 중 가장 좋은 성능을 보였다.
Mask-RCNN의 한계점
-
이미지 분할 알고리즘의 경우, class 안에 있는 것은 따로 구별하지 못한다는 한계가 존재한다. 이 알고리즘을 사용한 Mask-RCNN도 지나칠 수 없는 한계점이 되었다.
-
FCN(fully convolutional network)를 사용했기 때문에, 물체가 어떤 클래스에 속하는지 예측해낼 수 있지만, 그 물체가 어디에 존재하는지 예측할 수 없다는 한계점이 존재한다. (분류용 CNN 알고리즘의 단점)
