[논문 리뷰]_Swin Transformer : Hierarchical Vision Transformer using Shifted Windows
PapersReview

Swin Transformer : Hierarchical Vision Transformer using Shifted Windows
Swin Transformer 는 이미지 분류, 객체 검출 및 시맨틱 세그멘테이션 작업에서 높은 성능을 보이는 모델로, Hierarchical(계층적인) 아키텍처와 shifted windowing scheme을 사용하여 다양한 크기에서 모델링이 가능하며, 이미지 크기에 대해 선형적인 계산 복잡도를 지니는 특징을 가지고 있다.
ViT & Swin Transformer
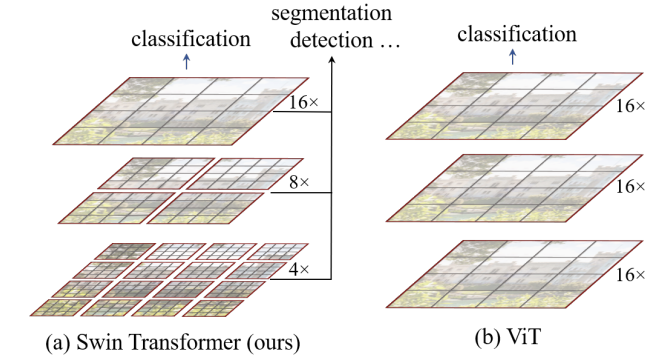
ViT와 Swin Transformer는 모두 Transformer 를 사용하는 비전 모델이지만, 몇가지 차이점을 제시하였다.
- 첫째,
ViT는 이미지를 작은 패치로 나누어 각 패치를 하나의 토큰으로 취급하여 Transformer 모델에 입력한다. (이미지에서 패치로 진행)
반면,Swin Transformer는 이미지를 비교적 작은 패치로 나누어 각 패치에서 self-attention을 계산하고, 병합해서 또 계산하고, 이 과정을 반복하는 hierarchical feature maps를 구성하여 진행한다. (패치에서 이미지 부분부분, 이미지 전체로 진행)
이러한 방식으로 Swin Transformer는 이미지의 다양한 크기에서 효과적으로 모델링이 가능하며, 계산 복잡도를 낮출 수 있다.
- 둘째, Swin Transformer는
shifted windowing scheme을 사용하여 self-attention을 계산하는데, 연속적인 self-attention 레이어 간의 window partition을 이동시키는 과정이다. (이전의 window 와 현재의 window 사이를 이어주는)
이러한 방식으로 Swin Transformer는 self-attention 계산을 비교적 작은 영역에서 수행하므로 계산 복잡도를 낮출 수 있게된다.
- 셋째, 성능적으로 Swin Transformer는 ViT와 달리 객체 검출 및 sementic segmenation과 같은 dense recognition 테스크에서 높은 성능을 보인다. 이는 Swin Transformer가 hierarchical feature maps를 구성하고, 다양한 스케일에서 모델링이 가능하기 때문이다.
Shifted Window 기법
Swin Transformer 의 대표적인 기법인 shifted window partitioning 는 이전 레이어의 window와 현재의 window 사이를 이어주며 모델의 성능을 향상시킨다.
Window란?
M개의 인접한 patch 들로 구성되어있는 patch set 이다.

기존 transformer base의 문제점을 논문에서는 'computational complexity on high-resolution images'가 존재한다고 하는데,
이미지의 픽셀이 증가할수록 모든 patch의 조합에 대해 self-attention을 수행하는 것은 불가능해진다는 것이다. (너무 많아지기 때문에) 따라서 계산 복잡도가 증가하게 되는데,
Swin transformer는 계산 복잡도 (computational complexity) 의 한계를 극복하기 위해 각 window 안에서만 patch끼리의 self-attention을 계산하는 방법을 제안하였다.
여기서 단순히 window를 중심으로 나누게되면 각 window의 경계 근처 patch(작게 말하면 픽셀)들은 인접해 있음에도 self-attention 계산이 수행되지 않는데, 레이어 l 의 분할이 발생한 patch에서 칸 떨어진 patch에서 레이어 l + 1 의 window를 나눔으로써 window 간의 연결을 통해 문제를 해결하였다.
장점으로는 self-attention 계산이 M개의 patch들로만 제한되기 때문에 연산의 효율성도 획득하여 계산 복잡도도 단축시키는 것을 들 수 있다.
Hierarchical Transformer
Hierarchical 방식은 이미지를 비교적 작은 패치로 나누어 각 패치에서 self-attention을 계산하고, hierarchical feature maps를 구성하는 과정이다.
위에서 설명하였듯 Swin Transformer는 이미지를 비슷한 크기의 패치로 나누어 각 패치에서 self-attention을 계산한다. 이때, 패치들은 서로 겹치지 않으며, 각 패치는 하나의 토큰으로 취급한다.
그러나, 이 방식에서는 각 패치에서 계산된 self-attention 정보만으로는 이미지의 전체적인 구조를 파악하기 어렵게 되는데, 본 논문에서는 이를 hierarchical feature maps를 구성 하여 해결한다.
각 패치에서 계산된 self-attention 정보를 이용하여 hierarchical feature maps를 구성한다.
이렇게 계층적 피처맵을 구성하게되면, FPN 또는 Segmentation의 U-Nset처럼 계층적인 정보를 활용할 수 있다. 그래서 Swin Transformer 가 object detection task 에서 뛰어난 성능을 보인다는 것 !
( 객체 검출에서 다양한 scale의 object를 검출하기 위해 FPN의 feature pyramid 구조를 사용하고, Segmentation에서 detail한 정보를 활용하기 위해 피쳐맵을 축소했다가 다시 확대하여 mask를 생성하듯이 )
이처럼 object detection과 segmentation task들은 hierarchical representation을 활용하는 것이 중요하다는 것 또한 알 수 있다.
Overall Architecture
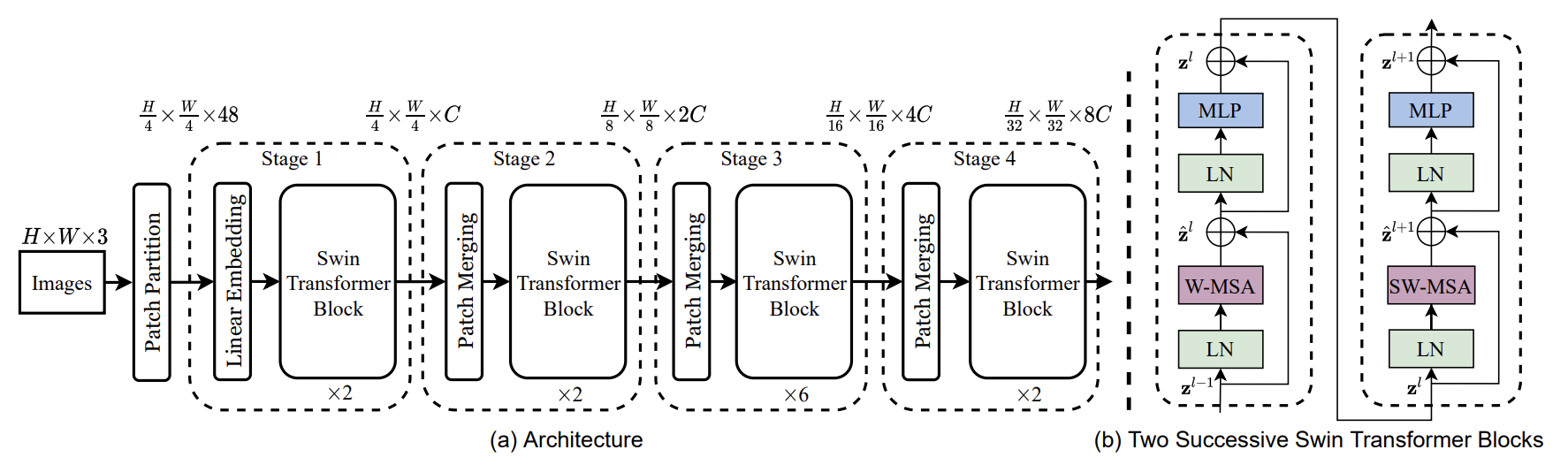
과정 (1) Positional embedding 과정이 없다.
ViT와의 차별점이기도 한데, 원래는 각 이미지 토큰의 위치 정보를 파악하기 위해서position embedding 을 초반에 더해주었는데, Swin transformer는 이러한 과정이 없고, self-attention을 수행하는 과정에서 Relative position bias 를 추가해준다.
계산하는 식을 살펴보면, attention score를 구하는 값에다가 B를 더해주는 것을 볼 수 있다.
M 개의 patch 가 하나의 window를 계산하도록 식이 짜여져 있고,
상대적인 위치는 결과적으로 안에 존재한다.
작은 크기의 positional bias 행렬을 안에 속하는 B 로 파라미터화 할 수 있다.
과정 (2) Patch Merging 이 존재
아키텍처 구조를 확인해보면, 각 stage가 진행될 때 마다 patch merging이 진행된다. 여기서 hierarchical feature map이 만들어지는데, 이전 레벨에서 구성된 feature maps를 더 큰 패치로 결합하여 더 큰 feature maps를 구성하는 과정이라고 보면 된다.
과정 (3) Swin Transformer Block
W-MSA: feature map을 M개의 window로 나누는 과정SW-MSA: W-MSA 모듈에서 발생한 패치로부터 칸 떨어진 patch에서 window 나누는 과정
Swin transformer block은 기존 transformer block과 다르게 multi-head self-attention(MSA) 을 window 기반의 W-MSA와 SW-MSA 모듈로 변경하였고, 각 MSA 모듈을 포함한 2개의 연속적인 트랜스포머로 하나의 Swin block을 만들고 있다.
window 기반의 MSA 모듈을 거치면 활성화 함수를 사이에 둔 2층 linear layer로 구성된 MLP block이 자리잡고 있으며, 각 MSA 모듈과 MLP 앞에 LN(Layer Norm) 층이 적용되고, 각 모듈 뒤에 residual connection으로 구성되어있다.
Swin transformer는 효율적인 모델링을 위해, local window 내에서만 self-attention을 계산하는데, 여기서 window는 겹치지 않는 방식으로 이미지를 균등하게 분할할 수 있도록 배열되어 있다.(self-attention in non-overlapped windows) 각 window에 개의 patch들이 포함되어 있다고 하면, global MSA 모듈의 computational complexity와 크기의 patch를 기반으로 하는 window는

여기서 MSA 부분은 patch에 대해 quadratic하고, W-MSA는 M 값이 고정될 때 linear하다는 특징을 지닌다.
window shifting을 진행하면서 겹치지않게 효율적으로 window를 배치해야하는데, 이를 위한 계산으로는 W-MSA 에서 개 였던 window 수가 SW-MSA 모듈에서는 개로 늘어나게 된다. 이 과정을 해결하기 위하여 논문에서는
padding & Cyclic shift
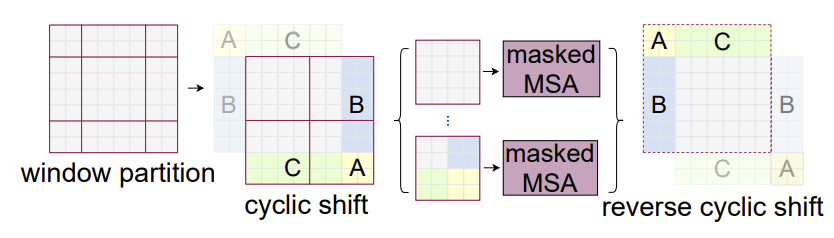
첫번째, 작아진 window들에 padding을 진행하여 크기를 다시 으로 맞추고, Attention 계산 시 padding된 값들을 마스킹 해준다. 여기서 window의 수는 여전히 늘어나게 되기 때문에 이러한 계산해야하는 크기는 늘어나는 단점이 여전히 존재한다.
두번째, 왼쪽 상단을 향해 cyclic하게 회전하는 방법을 사용한다. window는 window size //2 만큼 shift 하는데, 이미지 크기를 벗어나게 되면 padding 이 아닌 cyclic- shift를 사용하여
shift 이후 batch window는 feature map에서 인접하지 않은 여러 작은 단위의 window로 구성될 수 있기에, self-attention 계산을 각 하위 window 내에서 제한하기 위하여 마스킹 메커니즘이 사용된다.
이러한 cyclic-shift 를 사용하면 배치 window 개수가 regular window partitioning 때와 동일하게 유지되므로 효율적이다. - low latency(대기 시간)
Results
-
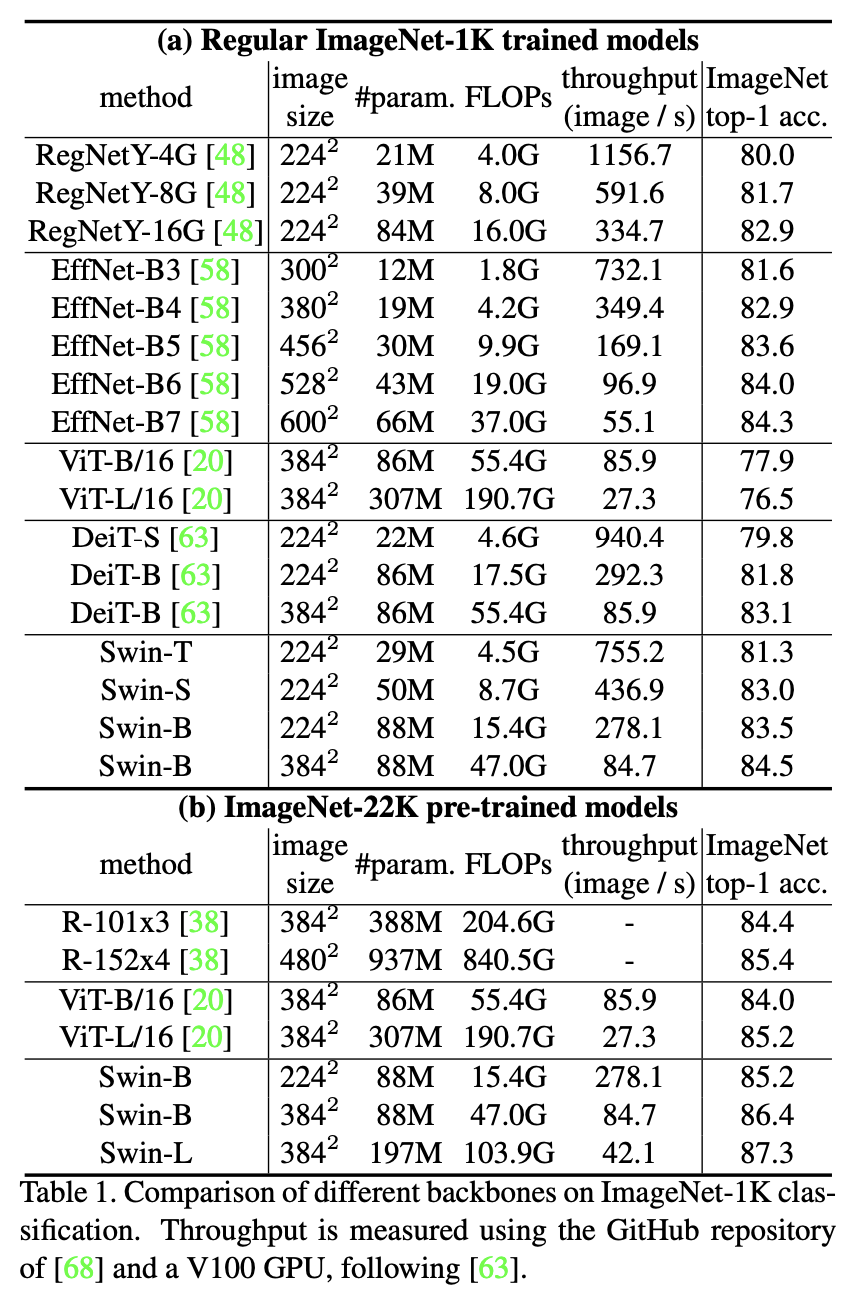
ImageNet 분류: Swin Transformer는 ImageNet 분류 태스크에서 다른 최신 모델들과 비교하여 우수한 성능을 보인다. Swin Transformer 모델은 Swin-T, Swin-S, Swin-B 세 가지 버전으로 구성되어 있으며,
이 중 Swin-B 모델은 Top-1 ACC 86.4%, Top-5 ACC 98.2% 를 달성하여 최고 성능을 내는 것을 확인할 수 있다. -
이 외에도, Object Detection에서는 Faster R-CNN, Mask R-CNN, Cascade R-CNN 등의 다양한 모델과 비교하여 우수한 성능을 보였으며, 특히 COCO 데이터셋에서 최고 성능을 보였다.
Semantic Segmentation에서도 DeepLabv3+, UperNet, HRNet 등의 다양한 모델과 비교해 우수한 성능을 보였으며, ADE20K 데이터셋에서 최고 성능을 보이는 것을 table 을 통해 확인할 수 있다.
Swin Transformer : Hierarchical Vision Transformer using Shifted Windows

안녕하세요. 도움이 많이 됐습니다. 한 가지 궁금한 것이 있는데 Swin Transformer가 object detection task에 강점을 가진다는 언급에 대한 레퍼런스가 있을까요?