[논문 리뷰]_Discriminative Sampling of Proposals in Self-Supervised Transformers for Weakly Supervised Object Localization (DiPS)
PapersReview

Discriminative Sampling of Proposals in Self-Supervised Transformers for Weakly Supervised Object Localization
DiPS 란?
본 논문에서 메인 포인트로 제안하고자 하는 것은 WSOL 모델을 학습시키기 위하여,
Self Supervised Vision Transformer (SSTs) 를 사용하여 가짜 라벨을 수집하고, 이 라벨들을 사용하여 WSOL 모델 훈련을 진행하는 것이다.
DiPS 과정
- SSTs에서 이미지를 분석하여 다중 맵을 생성한다.
- 생성된 다중 맵에서 대상 객체와 다른 객체를 구분할 수 있는 가짜 레이블을 획득한다. 이를 위하여, SSTs에서 생성된 multiple map을 활용하여 객체의 특징을 추출하고, 이를 기반으로 대상 객체와 다른 객체를 구분할 수 있는 가짜 레이블을 생성한다.
- 획득한 가짜 레이블을 기반으로 localization network를 훈련한다. 이를 위해, 획득한 가짜 레이블을 사용하여 localization network를 훈련한다. 이때, localization network는 대상 객체와 다른 객체를 구분할 수 있는 능력을 가지고 있어야 한다.
- 훈련된 localization network를 사용하여 입력 이미지에서 대상 객체를 위치 지정한다. 이때, localization network는 대상 객체를 정확하게 위치 지정할 수 있어야 한다.
DiPS에서 TS-CAM 의 활용
DiPS(Discriminative Proposals Sampling) 는 TS-CAM(Token Semantic Coupled Attention Map) 을 기반으로 하여, SSTs(Self-supervised vision transformers)에서 생성된 multiple map을 활용하여 localization network를 훈련하는 방식을 진행한다. 이를 통해, DiPS는 SSTs에서 생성된 multiple map을 활용하여 대상 객체와 다른 객체를 구분할 수 있는 가짜 라벨을 생성한다.
여기서 TS-CAM 은 SSTs에서 생성된 multiple map을 활용하여 Semantic Aware CAM을 생성하는 방식을 사용하므로, DiPS에서 TS-CAM이 사용된다.
SSTs에서 생성된 multiple map을 활용하여 Semantic Aware CAM을 생성하는 방식은 TS-CAM에서 사용하는 방식으로 진행되고, 이를 기반으로 localization network를 훈련을 진행하는 것이다.
Semantic Aware CAM 이란?
Semantic Aware CAM 은 TS-CAM(Token Semantic Coupled Attention Map) 에서 사용되는 객체 위치 지정 방법 중 하나로, Semantic Aware CAM은 입력 이미지에서 대상 객체의 위치를 정확하게 지정하기 위해, Attention Mechanism을 이용하여 생성된다.
Semantic Aware CAM을 생성하는 과정은
- 입력 이미지를 patch 단위로 나눈다.
- 나눈 patch를
Convolution Layer를 이용하여embedding으로 변환한다. - 변환된 patch embeddings를 이용하여, Transformer Block을 거쳐 class token을 생성한다. (여기서 patch embedding은 입력 이미지에서 대상 객체와 관련된 정보를 추출)
- 생성된 class token과 patch embeddings를 이용하여, Attention Mechanism을 활용해 Semantic Aware CAM을 생성한다.
(patch embeddings 중 대상 객체와 관련된 부분에 높은 가중치를 부여하여 Semantic Aware CAM을 생성한다.)
이를 통해, Semantic Aware CAM은 입력 이미지에서 대상 객체의 위치를 정확하게 지정할 수 있게된다.
Semantic Aware CAM은 Semantic Agnostic CAM과 결합하여 Final CAM을 생성하는 과정에 사용된다.
여기서 Semantic Agnostic CAM 은 입력 이미지에서 대상 객체와 관련 없는 부분을 강조하는 CAM이며, Semantic Aware CAM 은 입력 이미지에서 대상 객체와 관련된 부분을 강조하는 CAM이다.
결과적으로 Semantic Aware CAM과 Semantic Agnostic CAM을 결합하여 Final CAM을 생성하면, 입력 이미지에서 대상 객체의 위치를 더욱 정확하게 지정할 수 있게된다.
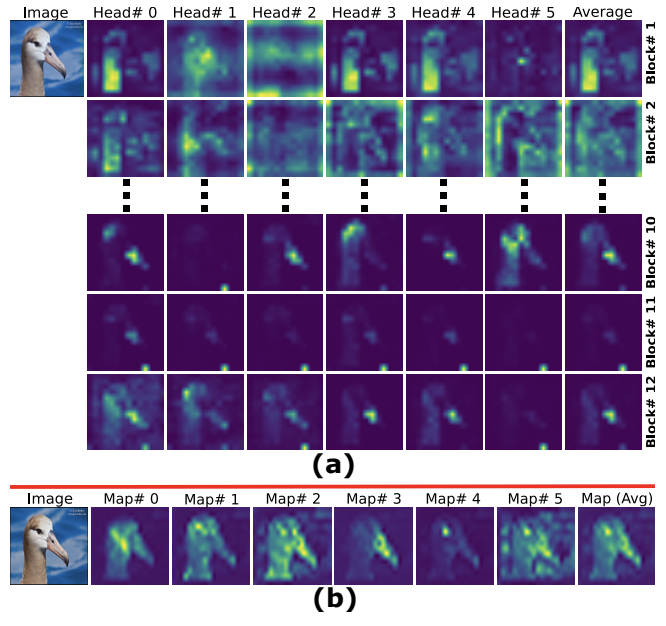
여기서 (a) 이미지는 TS-CAM map 을 사용하여 각 class token 의 attention을 뽑은 이미지인데, 여기 이미지에는 배경만을 강조하는 map과 객체를 강조하는 map들이 섞여있다.
(b) 이미지는 self supervised 과정 중 트랜스포머의 마지막 층에 있는 class token 의 attention을 뽑아놓은 이미지로, Map(Avg)를 통해 Semantic Aware CAM과 Semantic Agnostic CAM이 합쳐져 위치를 더욱 정확하게 확인할 수 있는 모습을 볼 수 있다.
Self Supervised vision transformer (SSTs)
본 논문에서 제안하는 WSOL 모델을 훈련하는 방법은 먼저, self-supervised vision transformers(SSTs) 에서 가짜(pseudo) 라벨을 수집한다.
여기서 Pseudo-label 이란?
가짜 라벨(pseudo-label)은 실제 라벨이 아닌, 모델이 예측한 라벨이다.
이 논문에서는 self-supervised vision transformers(SSTs)에서 가짜 라벨을 효율적으로 수집한다.
SSTs는 이미지를 분석하여 객체의 특징을 추출하고, 이를 기반으로 이미지의 특정 부분이 객체에 속하는지 여부를 예측한다.
이 예측 결과를 가짜 레벨로 사용하여 WSOL 모델을 훈련을 진행한다.
이러한 방법을 통해 추가적인 레이블링 작업 없이도 WSOL 모델을 효과적으로 훈련할 수 있도록 도와주는 역할을 하게된다.
그러나 SSTs는 임의의 객체에 대한 지식만을 가지고 있기 때문에, WSOL에서 필요한 대상 객체와 다른 객체를 구분할 수 없다.
즉, SSTs는 이미지 내의 모든 객체에 대한 정보를 가지고 있지만, 특정 객체에 대한 정보를 구분할 수 없다는 것 !
이 문제를 해결하기 위해, 다른 트랜스포머 헤드에서 생성된 multi-map을 활용하여 가짜 레이블을 획득한다.
그 후, CNN classifier 를 사용하여 차별적인 영역을 식별하는 새로운 DiPS(Discriminative Proposals Sampling) 방법을 도입한다. 이것이 논문의 메인 포인트이다.
본 방법은 전경과 배경 픽셀을 샘플링하여 특정 클래스에 속하는 객체를 정확하게 지정할 수 있는 WSOL 모델을 훈련한다. 이후, 위의 방법으로 훈련된 WSOL 모델은 입력 이미지를 처리하여 객체를 위치 지정할 수 있게된다.
왜 CAM 보다 DiPS가 더 좋을까?
DiPS는 기존의 CAM(Class Activation Map) 방법과 달리, 다른 트랜스포머 헤드에서 생성된 multiple map을 활용하여 pseudo label을 얻으며, 이를 통해 DiPS는 차별적인 영역을 식별하여 특정 클래스에 속하는 객체를 정확하게 지정할 수 있는 WSOL 모델을 훈련하게된다. 이후, 이 방법으로 훈련된 WSOL 모델은 입력 이미지를 처리하여 객체를 위치 지정할 수 있다.
이러한 방법은 기존의 CAM 방법보다 더욱 정확하고 효율적인 객체 위치 지정을 가능하게 하는데, 기존의 CAM 방법은 대상 객체의 일부분만을 강조하고, 다른 부분은 무시하는 경향이 있었다. (object의 특정한 작은 영역에만 집중하는)
반면에, DiPS는 차별적인 영역을 식별하여 대상 객체 전체를 정확하게 지정할 수 있다.
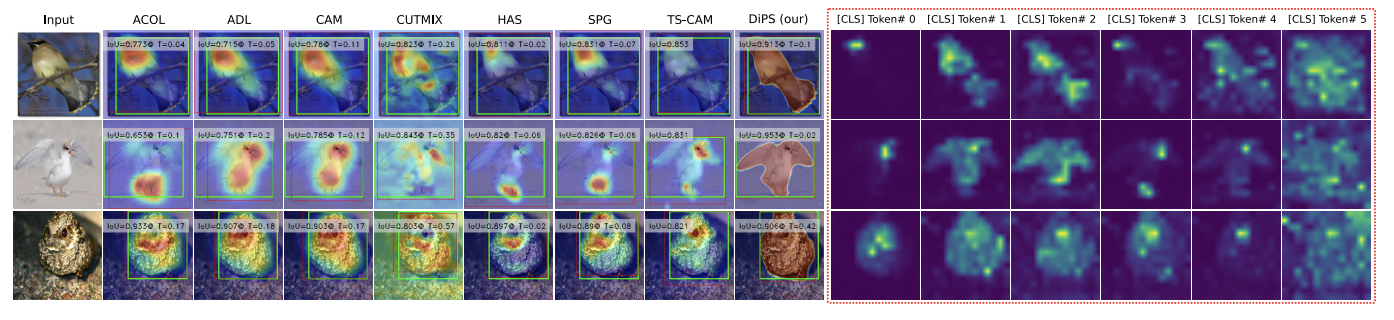
visual results also show that our method produces CAMs with a better coverage of the entire foreground regions, and a clearer distinction between foreground and background regions. - page 3, papers
Related Work
DiPS 에서 사용한 기법들과 관련있는 내용들을 이 부분에서 정리해놓았다.
Background 1 - CAM
첫 번째 방법은 CNN의 내부 활성화(activation)를 이용하여 객체 위치를 추정하는 방법이다. 이 방법은 CNN의 내부 활성화를 이용하여 객체의 위치를 추정하는 CAM(Class Activation Map)을 생성한다.
이때, CAM은 입력 이미지에서 객체의 위치를 강조하는 히트맵으로 표현된다. 하지만 CAM을 생성하는 방법에 따라 정확도가 크게 달라지고, CAM의 근본적인 문제인 작은 극소영역만, 집중해서 본다는 단점이 존재한다.
Background 2 - WSOL based Transformer
두 번째 방법은 Transformer 기반의 WSOL 방법이다. Transformer는 Attention Mechanism 을 이용하여 입력 시퀀스의 각 요소들 간의 상호작용을 모델링하는 방법으로, 입력 이미지를 patch 단위로 나눈 후, Transformer를 이용하여 patch 간의 상호작용을 모델링한다.
이때, Transformer는 입력 이미지에서 대상 객체와 관련된 정보를 추출하여 class token을 생성하고, Attention Mechanism을 이용하여 Semantic Aware CAM을 생성합니다. 이 방법은 CNN 기반의 방법보다 정확도가 높은 것을 연구를 통해 확인할 수 있다.
Proposed Method - DiPS

DiPS 방법에서는 먼저 SST에서 나온 saliency map을 이용하여 pre-trained CNN classifier를 이용하여 discriminative proposals을 생성하는 것이 메인 과정이라고 볼 수 있다.
이때, discriminative proposals은 saliency map에서 대상 객체와 관련된 부분을 추출한 것으로 볼 수 있다.
Transformer 부분
Saliency map은 입력 이미지에서 대상 객체와 관련된 부분을 강조하는 히트맵으로, SST에서 생성된다. 이때, SST는 입력 이미지를 patch 단위로 나눈 후, 각 patch를 Transformer를 이용하여 embedding으로 변환한다.
이후, embedding을 이용하여 patch 간의 상호작용을 모델링하고, 이를 이용하여 saliency map을 생성한다.
즉, 픽셀값의 변화가 급격한 부분을 모아서 매핑한 후에 관심있는 물체를 관심이 없는 배경과 분리시키는 방법으로 만들어진 map 이 saliency map !
CNN CLassifier 부분
Discriminative proposals은 saliency map에서 대상 객체와 관련된 부분을 추출한 한 것으로, pre-trained CNN classifier는 discriminative proposals을 생성하기 위해 사용된다. Pre-trained CNN classifier는 입력 이미지에서 대상 객체와 관련된 부분을 추출하는 역할을 한다. 이를 이용하여, discriminative proposals을 생성한다.
Localizer & Activation Map 부분
이후, DiPS는 pseudo-label sampling을 이용하여 localization map을 만든다. 이때, pseudo-label sampling은 discriminative proposals을 이용하여 localization map을 생성하는 방법이다.
Pseudo-label sampling은 discriminative proposals에서 foreground와 background pixel을 샘플링하여 localization map을 생성하는데, 이를 통해서 객체의 명확한 위치를 찾아낼 수 있게 된다.
Results
DiPS 는 TelDrone 데이터셋과 CUB-200-2011 데이터셋에서 실험한 결과, 다른 최신 WSOL 방법들보다 높은 localization accuracy를 보인다.
또한, DiPS 는 threshold 값에 덜 민감하며, foreground와 background 영역을 더욱 명확하게 구분하는 CAMs를 생성하는 것을 결과 이미지를 통해 확인할 수 있다.
Accuracy 똑바로 보기
MaxBoxAcc는 bounding box의 IoU(Intersection over Union) 값이 0.5 이상인 경우의 localization accuracy를 의미한다. 이 값이 높을수록, 모델이 더욱 효과적으로 객체 검출을 진행하였다는 것을 알 수 있다.
Top-1 localization accuracy는 가장 높은 확률을 가진 localization map의 IoU 값이 0.5 이상인 경우의 localization accuracy를 의미한다.Top-5 localization accuracy는 상위 5개의 localization map 중 하나의 IoU 값이 0.5 이상인 경우의 localization accuracy를 의미한다.
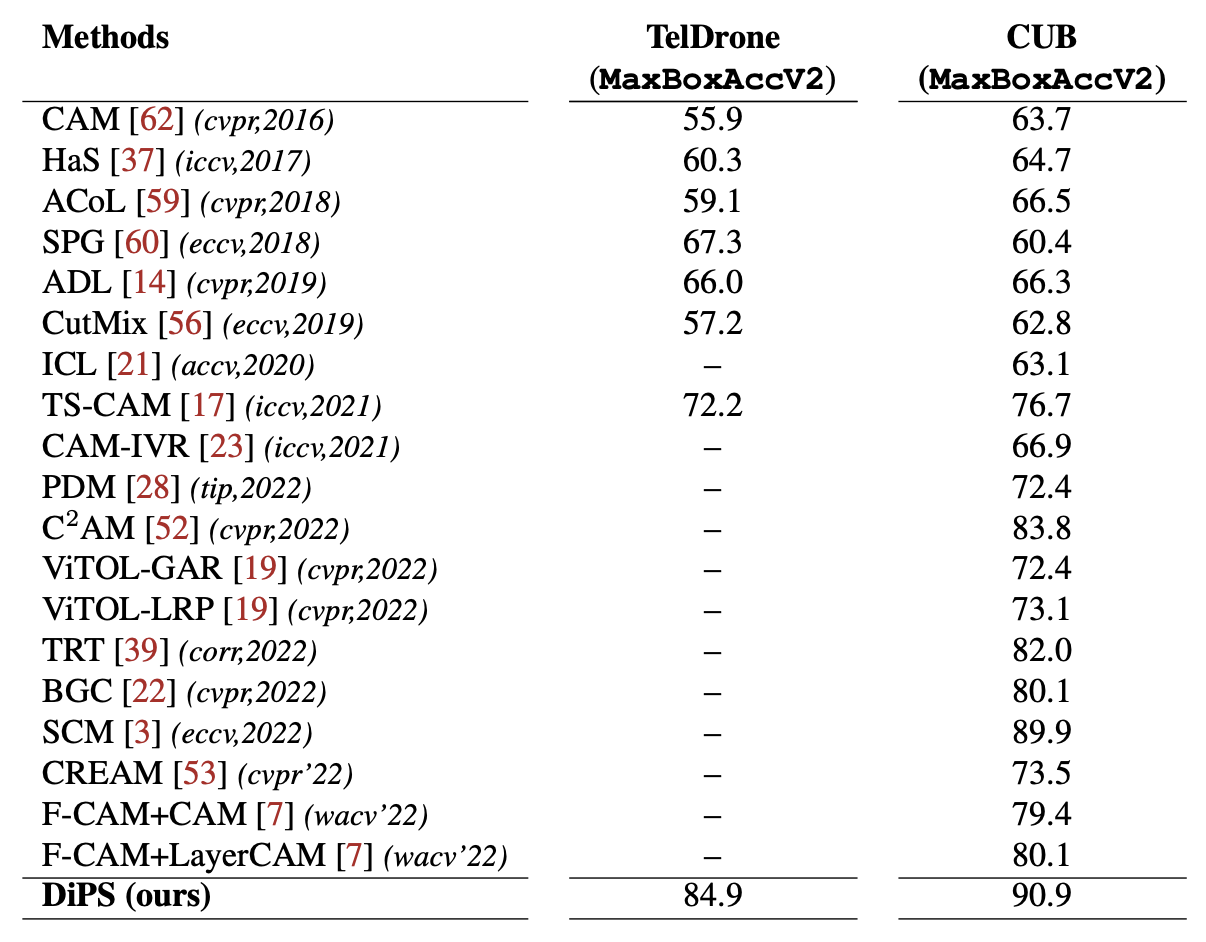
DiPS 는 TelDrone 데이터셋에서 MaxBoxAcc 값이 96.2, top-1 localization accuracy 값이 92.9, top-5 localization accuracy 값이 98.3으로 WSOL 방법들 중 가장 성능이 뛰어난 것을 확인할 수 있다.
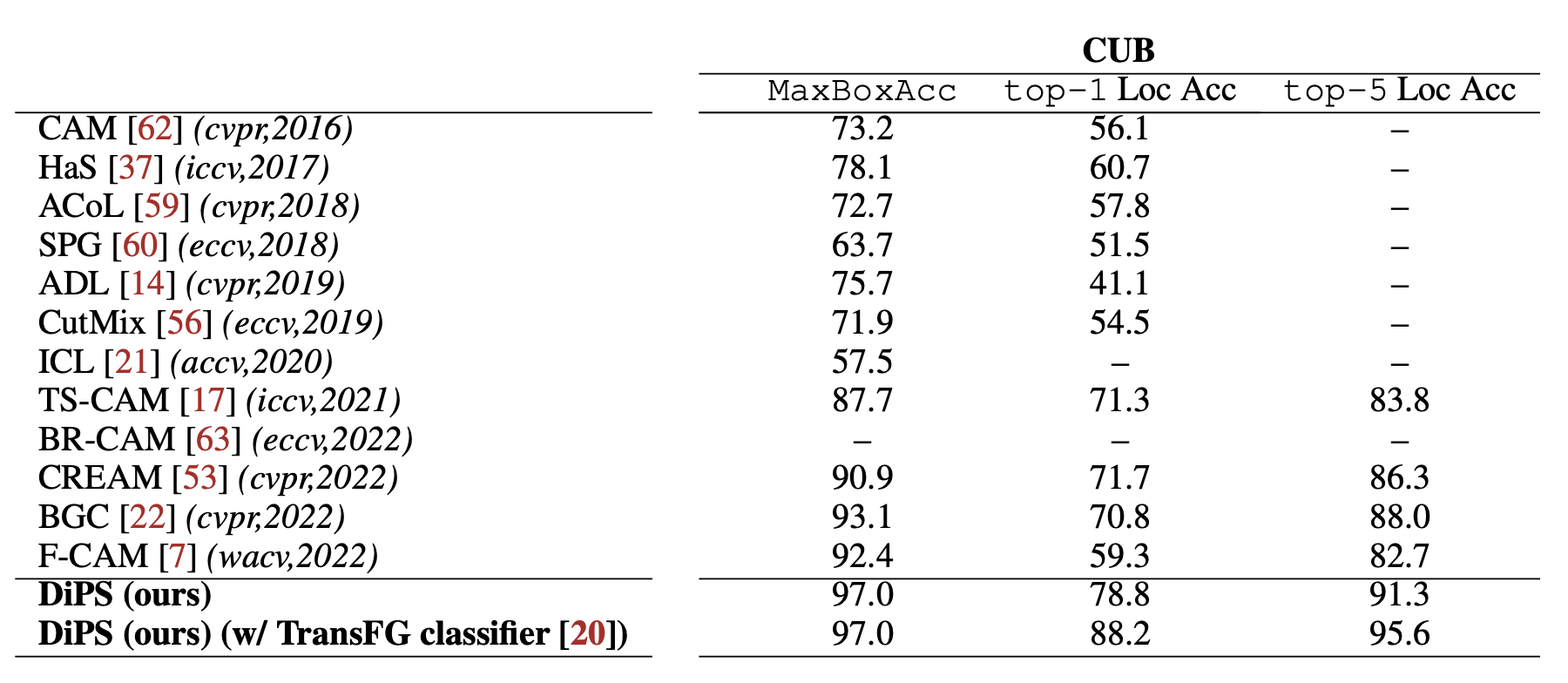
CUB-200-2011 데이터셋에서는 MaxBoxAcc 값이 97.0, top-1 localization accuracy 값이 93.3, top-5 localization accuracy 값이 98.3으로, 뛰어난 성능을 확인할 수 있다.
