
Auto-Encoding Variational Bayes : Variational Autoencoder
Variational Autoencoder 는 GAN 과 같이 generative model 의 한종류로, input 과 output 을 같게 만드는 과정인 autoencoder 와 비슷하게 encoder 와 decoder 를 활용하여 latent space를 도출하고, 이 latent space 로부터 원하는 Output을 decoding 함으로써 data generation 을 진행하는 과정을 말합니다.
이번 논문에서는 정확한 이해를 위해서 JINSOL KIM 님의 블로그 내용을 참고하였습니다. 잘 작성해주셔서 감사합니다 !
Autoencoder
AutoEncoder(이하 AE)는 저차원의 representation z 를 원본 x 로부터 구하여 스스로 네트워크를 학습하는 방법을 뜻합니다. 이 방식은 Unsupervised Learning 중 하나로 레이블이 필요 없이 원본 데이터를 레이블로 활용합니다.
AE의 주 목적은 Encoder를 학습하여 유용한 Feature Extractor로 사용하는 것인데요, 현재는 잘 쓰지는 않지만 기본 구조를 응용하여 다양한 딥러닝 네트워크에 적용할 수 있습니다.(ex/ VAE, U-Net, Stacked Hourglass ...)

AE 는 입력 x 와 출력 y 가 최대한 동일한 값을 가지도록 하는 것이 목적이며,
입력의 정보를 압축하는 구조를 encoder 라 하고, 압축된 정보를 다시 복원하는 구조를 decoder 라고 합니다. 마지막으로 그 사이에 있는 variable 을 latent variable Z 라고 하게됩니다.
encoder 는 latent variable 자체를 만드는 역할을 수행하고, decoder 는 latent variable 로 부터 데이터를 생성하는데 사용됩니다.

AE 에서 저차원의 표현인 z 는 위의 그림과 같이 원본 데이터의 함축적인 의미를 가지도록 학습됩니다. 물론 위의 이미지 박스 내용처럼 명시적으로 latent variable 이 저장되지는 않지만 어떠한 특징 정보가 저장된다는 점이라고 보시면 됩니다.
쉽게 생각하면 다른 머신 러닝 모델에서 feature 이라는 것과 같은 의미가 되고, 학습 과정에서 겉으로 드러나지 않는 숨겨진 변수라는 의미를 지니므로 latent variable 이라고 불리게 됩니다.
Auto Encoder 학습 과정
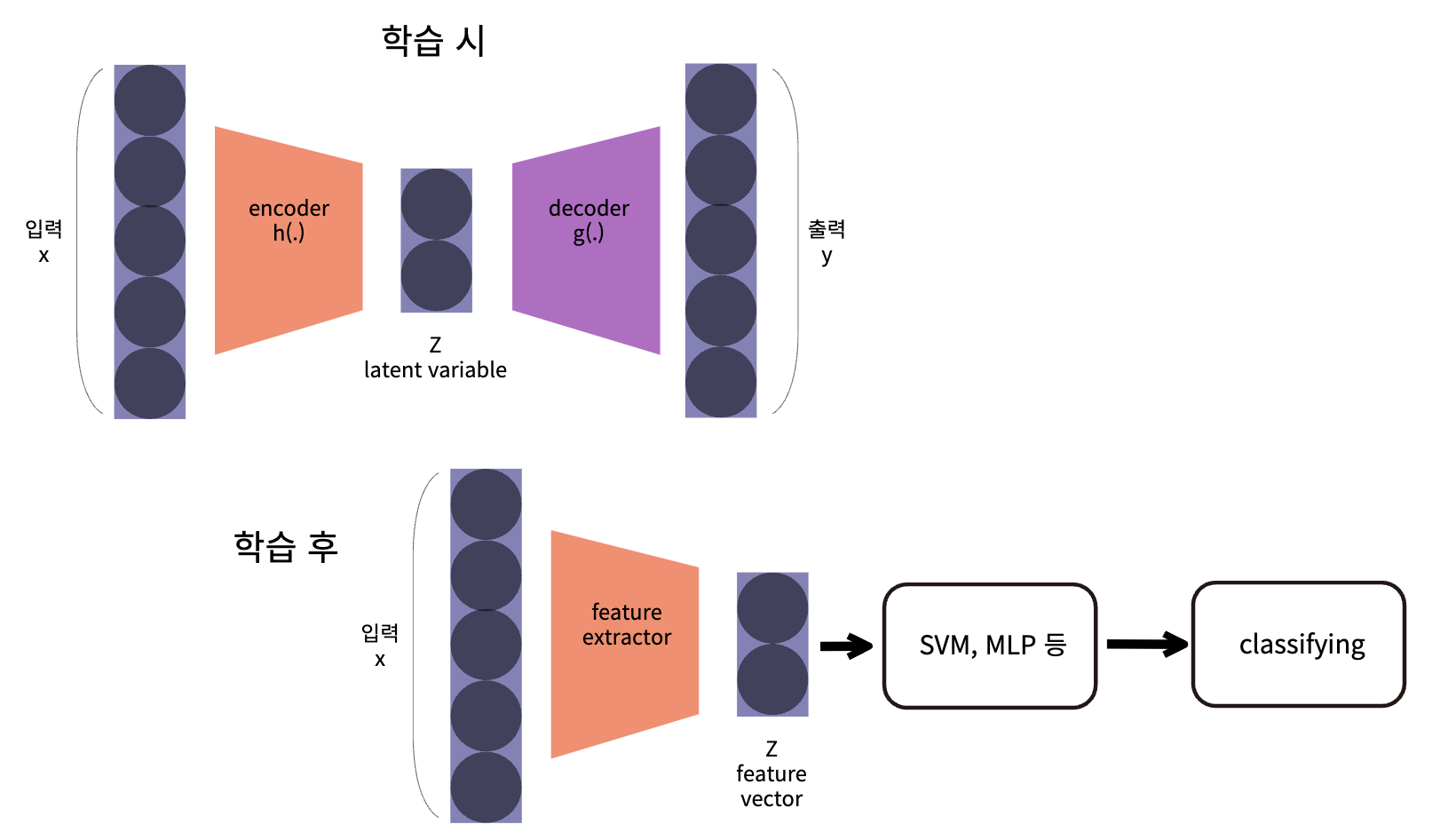
AE 의 latent variable 은 입력을 압축하여 feature 를 만들기 때문에, Feature Extractor의 역할 을 할 수 있습니다. 따라서 위 그림과 같이 학습이 완료된 AE에서 Encoder와 Latent Variable 까지만 가져와 Feature
Z 를 추출하고 그 값을 이용하여 다른 머신 러닝 Classifier와 섞어서 사용하곤 하였습니다.
Variational AutoEncoder
Variational AutoEncoder 는 (VAE) AE 와 같은 오토인코더이지만 많이 다르면서 유사한 구조를 가집니다.
VAE 는 랜덤한 노이즈로부터 원하는 영상을 얻을 수 없는지에 대한 의문에서 시작되었다고 합니다. 2D 랜덤 노이즈를 입력으로 받았을 때 어떠한 영상을 만들어낼 수 있는지에 대한 문제인데요,
영상에서 랜덤 노이즈를 이용하여 만들 수 있는 영상의 갯수는 정도입니다. 예를 들어 랜덤 노이즈를 통해 여러개의 이미지 중 하나의 이미지를 얻을 확률을 라고 생각할 수 있습니다.
여기서 , VAE 의 첫 시작이 '랜덤 노이즈로부터 원하는 영상을 얻을 수 없을까?' 였는데, 이에 대한 답변은 천문학적인 경우의 수에서 임의로 생성한 데이터로 원하는 영상을 얻을 수 없다 였습니다.
VAE 작동 방식
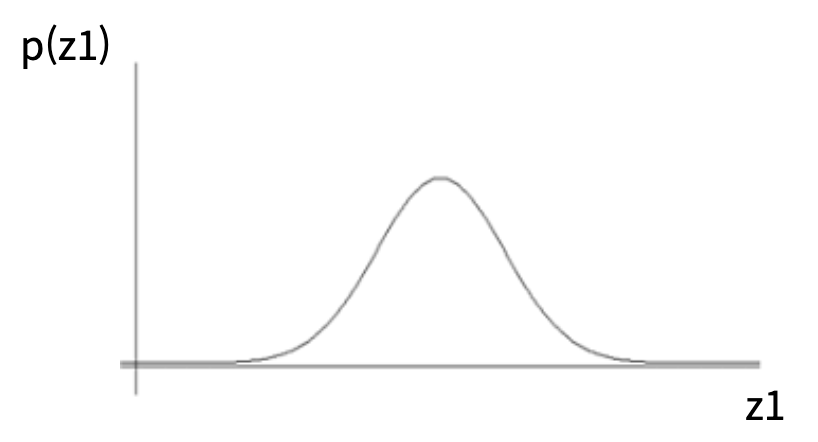
만약에 라는 데이터셋이 있고, 이 데이터셋을 활용하여 데이터셋을 잘 나타내는 분포를 만들고, 랜덤 노이즈가 그 분포 중 하나에 해당되도록 한다면, 데이터셋을 나타내는 분포 내에서 랜덤값이 생성되기 때문에, 데이터셋과 유사한 값을 뽑아낼 수 있습니다.
위의 분포는 VAE 의 latent variable 의 분포에 해당됩니다.
이러한 방법은 앞서 uniform 한 랜덤 노이즈를 만드는 것과 다르게 데이터셋이 가지는 확률 분포 내에서 랜덤 노이즈를 만드는 것에서 차이가 있습니다.
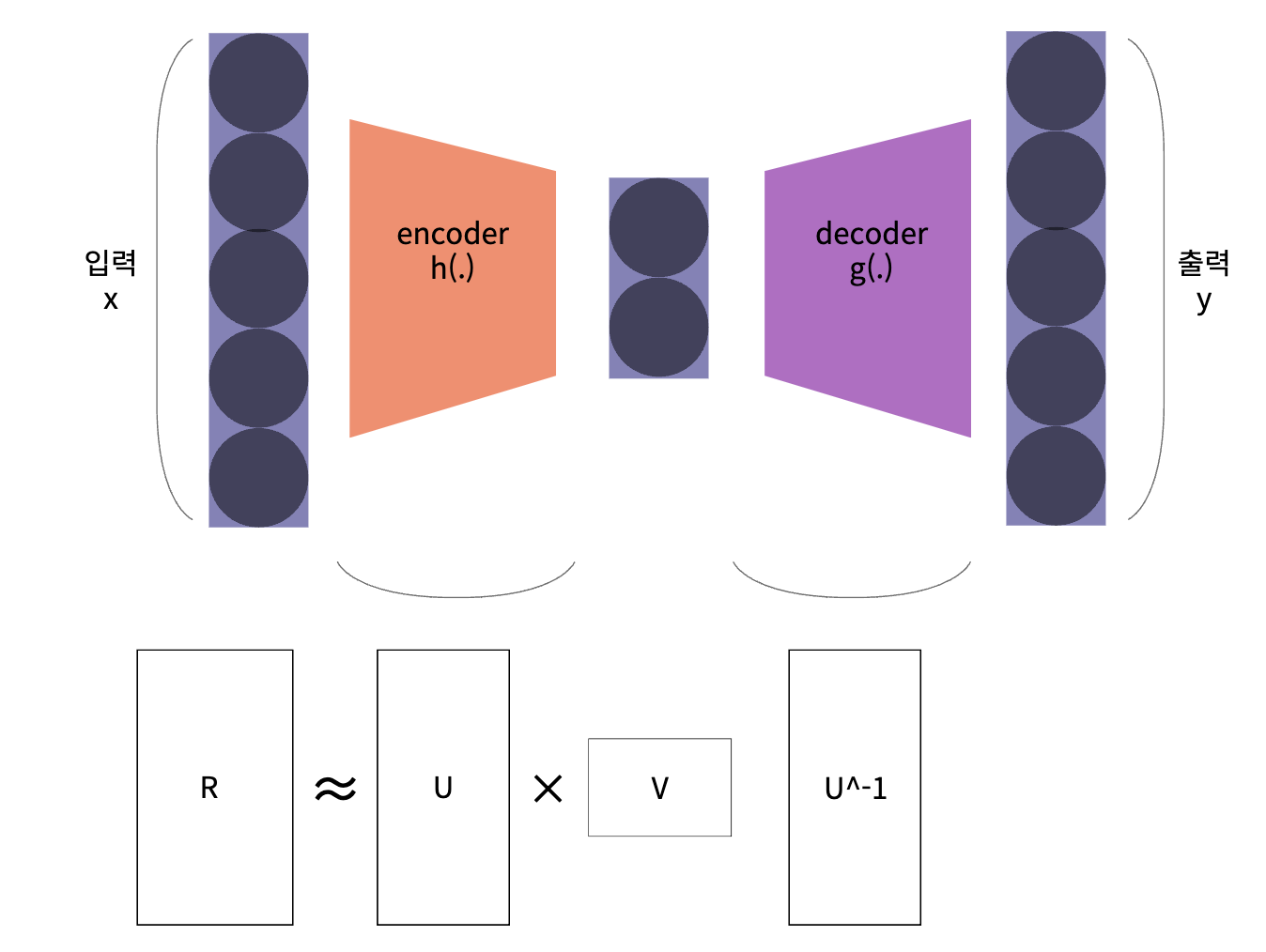
AE의 주 목적은 차원 축소를 통하여 latent variable을 얻는 것에 있습니다. 즉, latent variable의 값이 특징들을 나타내는 것처럼 feature extractor 의 기능을 가지고 있습니다.
AE는 sample을 통해 위 그림과 같은 Encoding, Decoding을 학습을 하고 이는 선형대수학에서 다루는 Nonlinear Matrix Factorization 또는 Nonlinear dimension reduction 방식과 일치하게 학습을 진행한다고 보면 됩니다.
Sample의 차원을 줄였다 늘리는 과정을 통하여 sample을 잘 설명하는 latent variable을 도출하는 네트워크를 학습합니다.
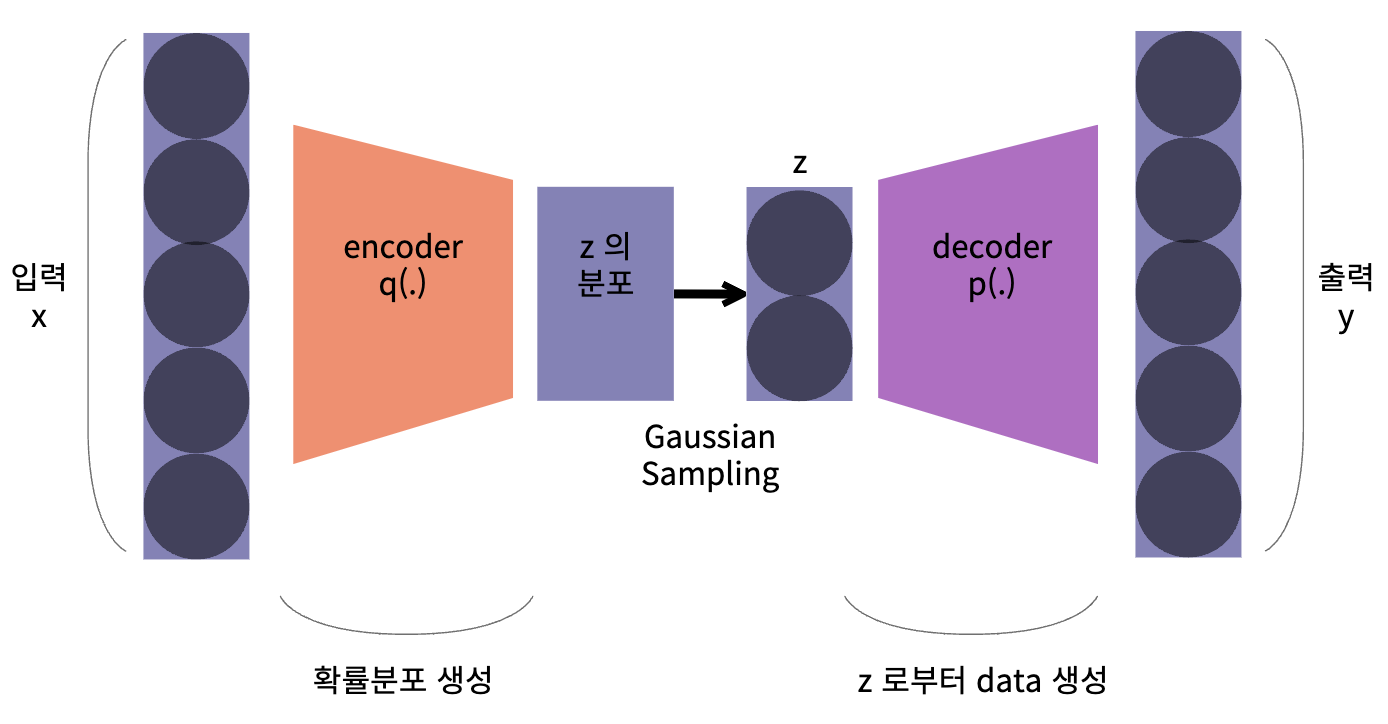
하지만 VAE 의 주 목적은 데이터를 생성하기 위함 이기 때문에, 데이터의 분포 자체를 학습합니다. 여기서 latent variable 분포로부터 sampling 된 latent variable 을 decoder 에서 Input 으로 활용합니다.
데이터셋이 VAE의 Encoder 쪽으로 들어가면 latnet variable의 분포인latent distribution으로 나타나게됩니다.
또한, latent distribution 에서 랜덤값으로 샘플링을 하면 latent distribution에 대응 되는 의미에 따라 다른 출력의 이미지를 생성하도록 할 수 있습니다.
- VAE의 전체 구조를 보면 input으로 데이터를 받은 뒤 Encoder 부분에서는 latent variable을 생성하도록 학습합니다.
- 이 때, AE와는 다르게 latent variable로 μ,σ를 생성합니다.
- 가우시안 노이즈 N(0,1) 과 ① latent variable σ 와 곱해지고 ② μ 와 더해져서 Decoder의 Input으로 전달되어 집니다.
- Decoder에서는 이 값을 원본 데이터 해상도 만큼 복원시켜서 원본 인풋과 유사해지도록 학습합니다.
AE와 VAE의 핵심적인 차이점?
AE와 VAE의 핵심적인 차이점은latent variable에 대한 표현 방식입니다. VAE에서는 latent variable의 distribution을 정규 분포 형태로 나타내고 그 분포에서 샘플링을 하도록 합니다.
여기서 중요한 점 중의 하나는 VAE 또한 딥러닝 네트워크이기 때문에 backpropagation을 통한 학습이 가능하도록 아키텍쳐를 구성해야 한다는 것입니다.
단순히 정규 분포에서 샘플링 하도록 하면 Encoder 와 Decoder 사이의 latent variable에서 미분이 불가능해집니다.
반면 Encoder의 출력부에서 μ,σ 를 출력하도록 하고 이 값의 선형 결합을 통해 가우시안 분포의 샘플링을 하도록 하면 μ,σ 에 대하여 미분이 가능해집니다. 이러한 방법을Reparametrization Trick이라고 합니다.
총 정리를 하면, training에서의 VAE에서는 Encoder, Decoder 그리고 Latent Variable Distribution을 이용하여 네트워크를 구성하고 네트워크의 입력과 출력이 Reconstruction 이 잘 되도록 학습을 합니다.
추론 단계에서는 Encoder 부분을 떼어내고 latent variable에서 샘플링을 한 후 Decoder를 통해 출력을 하면 새로운 이미지를 출력하도록 할 수 있습니다.

사람 얼국 데이터셋을 학습하여 VAE를 통해 샘플링 한 결과를 확인해 보면, 기본적인 VAE를 통해 데이터를 생성하면 위 그림과 같이 약간 blur한 특징을 가집니다.
이 점은 VAE의 특징이자 단점이라고 설명합니다.
Variational Autoencoder(VAE) : Auto-Encoding Variational Bayes - 논문보기
