
Vision Transformer for small size datasets
Introduction : 문제 제기 및 요약
약한 토큰화 ( weak tokenization )
기존의 ViT에서는 성능을 제한하고 지역적인 (국소적인,localiy) 귀납편향성(inductive bias)을 줄이는 두 가지 문제를 발견하였습니다. 첫 번째 문제는 약한 토큰화입니다. ViT는 주어진 이미지를 동일한 크기의 중첩되지 않는 패치로 나누고, 각 패치를 시각적 토큰으로 linear projection을 진행 합니다.
이 선형 투영이 모든 패치에 동일하게 적용하는데, 중첩되지 않는 패치들은 시각적 토큰이 상대적으로 작은 수용 영역(receptive field) 을 가지게 됩니다.
일반적으로 중첩 비율이 동일한 중첩 패치를 기반으로 하는 토큰화는 수용 영역이 더 작은데, 작은 수용 영역은 ViT가 너무 적은 픽셀로 토큰화하게 만들게 되며, 결과적으로 인접한 픽셀과의 공간적인 관계가 각 시각적 토큰에 충분히 포함되지 않습니다.
약한 어텐션 메커니즘 ( Weak attention mechanism )
두 번째 문제는 약한 어텐션 메커니즘입니다. 이미지 데이터의 특성 차원은 자연어 및 오디오 신호보다 훨씬 크기 때문에 embedded token 의 개수가 많아집니다. 따라서 토큰의 어텐션 점수 분포가 매끄럽게 되는데, 이는 ViT가 중요한 시각적 토큰에 국소적으로 어텐션을 집중할 수 없는 문제를 만들게됩니다.
위의 두 가지 주요 문제로 인해 중복(redundant) 어텐션 이 발생하여 대상 클래스에 집중할 수 없게 됩니다. 이는 ViT가 일반적으로 배경에 집중하고 대상 클래스의 모양을 잘 포착하지 못하는 문제를 만들게됩니다.
Proposal : 제안
본 논문은 ViT가 작은 크기의 데이터셋을 처음부터 학습하는데 있어서 지역성 귀납 편향(locality inductive bias) 을 효과적으로 향상시키기 위한 두 가지 해결책을 제시합니다.
첫째, 이미지의 토큰화 과정에서 인접한 픽셀들 간의 공간적 관계를 더 잘 활용하기 위해
Shifted Patch Tokenization (SPT)을 제안하였습니다.
SPT는TSM(Temporal Shift Module, 시간적 모델링)로부터 아이디어를 얻었는데, TSM은 일부 시간 채널을 이동시키는 효과적인 시간 모델링입니다. 이를 바탕으로 우리는 공간적 모델링을 제안하여 공간적으로 이동한 이미지를 입력 이미지와 함께 토큰화하였습니다. SPT는 표준 토큰화보다 ViT에 더 넓은 receptive field (수용 영역) 을 제공할 수 있는데요, 이는 각 시각적 토큰에 더 많은 공간 정보를 임베딩하여 지역성 귀납 편향을 증가시키는 효과를 줍니다.
둘째, 우리는 ViT가 locally하게 어텐션할 수 있도록 허용하는Locality Self-Attention (LSA)를 제안합니다.
LSA는 자기 토큰을 제외하고, 소프트맥스 함수에 학습 가능한 temperature를 적용함으로써 어텐션 점수 분포의 smoothing(부드러워지는) 현상을 완화시킵니다. LSA는 각 토큰이 자신과 관련이 큰 토큰에 집중하는 것을 제한함으로써 좁은 지역에 국소적으로 작동하는 어텐션을 유도합니다.
이러한 SPT와 LSA는 구조적 변경 없이 다양한 ViT에 추가 모듈로 쉽게 적용할 수 있으며, 성능을 효과적으로 개선할 수 있습니다.
Proposed Method
제안된 방법은 앞서 설명한 SPT와 LSA 라는 두 가지 주요 아이디어를 통해 ViT의 국소성 규칙성(locality inductive bias) 을 증가시키려는 것입니다.
SPT : Shifted Patch Tokenization
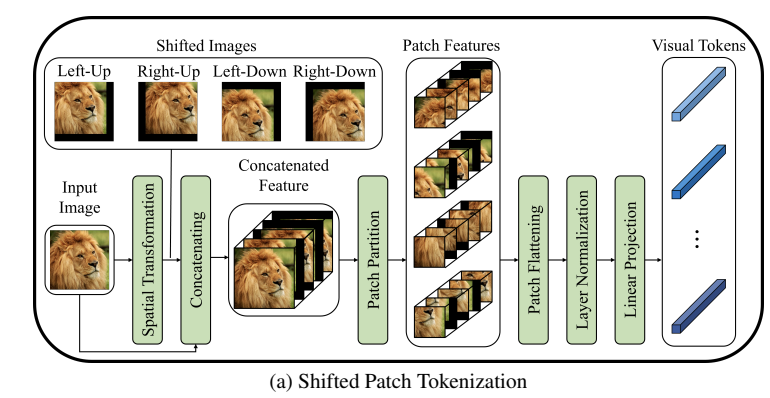
SPT는 입력 이미지를 여러 방향으로 공간적 이동시키고 이를 입력 이미지와 연결하는 것을 의미합니다. SPT는 대각선 방향으로 4번 이동하는 과정을 거칩니다.
그럼 결과적으로 입력이미지 + 공간적으로 이동한 4개의 이미지 가 들어가는 거겠죠?
그 후는 기존 ViT와 동일하게 패치 분할을 진행합니다. visualization token의 임베딩을 위해 flatten, layer regularization 및 linear projection 세 가지 과정이 차례대로 수행됩니다. 이와 같은 처리를 통해 SPT는 visualization token에 더 많은 공간 정보를 임베딩하고 ViT의 localiy inductive bias를 증가시킬 수 있게됩니다.
우선 SPT 의 효용성을 확인하기 위해 기존 ViT의 r 토큰의 크기가 적절한지논문에서는 체크하고 넘어가고있습니다.
ViT의 visual token의 receptive field는 토큰화에 의해 결정됩니다.
transformer encoder 이후의 receptive field는 조정되지 않으므로 입니다. 따라서 은 커널 크기와 동일합니다. (커널 크기는 ViT의 패치 크기)
여기서, receptive field란 ?
수용 영역(receptive field)은 알고리즘이 주변 정보를 인식하는 데 사용하는 영역을 말합니다. 일반적으로 수용 영역은 주변 정보에 대한 적용 범위 또는 태스크 수행에 필요한 정보에 대한 영역을 포함하고 있습니다.
ImageNet 데이터셋에서 ResNet50을 학습할 때 마지막 특성의 수용 영역 크기와 r 토큰을 비교합니다. ImageNet의 이미지 크기는 224 × 224이며, 표준 ViT의 패치 크기는 16이므로 시각적 토큰의 r 토큰도 16입니다. 그러나 ResNet50 특성의 수용 영역 크기는 483입니다. 따라서 ViT의 시각적 토큰은 ResNet50 특성보다 약 30배 작은 수용 영역 크기를 갖습니다. 저자는 이러한 토큰화의 작은 수용 영역을 spatial relationship 부족의 주요 요소로 판단하였습니다.
따라서 SPT는 수용 영역을 증가시켜 풍부한 공간 정보를 활용하기 위해 사용됩니다.
LSA : Locality Self-Attention

일반적으로 소프트맥스 함수는 온도(temperature) 조절을 통해 출력 분포의 smoothing 정도를 조절 할 수 있습니다. (b)에서 확인할 수 있는 LSA 는 주로 소프트맥스 함수의 온도 매개변수를 학습하여 어텐션 점수의 분포를 날카롭게 만듭니다.
또한 쿼리와 키에 의해 계산된 similarity 행렬의 대각 성분을 강제로 억누르는 대각선 마스킹을 적용함으로써 self-token 관계를 제거합니다.
이 마스킹은 서로 다른 토큰 간의 어텐션 점수를 상대적으로 증가시키므로 어텐션 점수의 분포를 더 날카롭게 만듭니다. 따라서 LSA는 ViT의 어텐션을 지역적으로 집중시켜 국소성 귀납편향성(localiy inductive bias)을 증가시키는 역할을 하죠.
self-attention 메커니즘은 다음과 같이 동작합니다.
먼저, 각 토큰에 대해 linear projection을 통해 Query, Key 및 Value를 얻습니다. 그 다음, Query와 Key의 내적 연산을 통해 토큰 간의 의미론적 관계를 나타내는 유사도 행렬인 R을 계산합니다. R의 대각 성분은 self-token 관계를 나타내고, 비대각 성분은 토큰 간의 관계를 나타냅니다.
여기서, LSA 가 어떻게 진행되고, 적용되는지 (smoothing이 왜 발생하는지) 확인해봅시다.
와 는 각각 Query와 Key에 대한 학습 가능한 선형 투영을 나타내며, 와 는 Query와 Key의 차원입니다. 다음으로, R은 Key 차원의 제곱근으로 나누고, 그 후 소프트맥스 함수를 적용하여 어텐션 점수 행렬을 얻습니다. 마지막으로, 소프트맥스 함수의 어텐션 점수 행렬과 Value의 내적에 의해 정의되는 self-attention을 계산합니다.
위의 식은 관계가 큰 토큰의 어텐션을 더 크게 만들기 위한 식입니다. 그러나 표준 ViT의 어텐션은 관계와 관계없이 서로 유사한 경향이 있습니다.
첫번째는 Query 와 Key 는 동일한 입력 토큰에서 선형 투영됩니다. 따라서 Query와 Key에 속하는 토큰 벡터는 보통 유사한 크기를 가집니다.
R(x)는 Query와 Key의 내적입니다. 따라서 유사벡터의 내적인 self-token 관계는 일반적으로 토큰 간 관계보다 크게되죠. SA(x)의 소프트맥스 함수는 상대적으로 self-token 관계에 높은 점수를 할당하고 inter-token 관계에 낮은 점수를 할당합니다.
SA(x)에서 의 제곱근으로 R을 나누는 이유는 소프트맥스 함수가 작은 기울기를 가지지 않도록 하기 위함입니다. 그러나 이로 인해 자연스럽게 softmax 함수의 고온이 작용하여 어텐션 점수 분포의 smoothing 현상이 발생할 수 있습니다.
논문에서의 실험을 통해 높은 온도로 인해 어텐션 점수가 smoothing되면 ViT의 성능이 하락하는 것을 확인할 수 있습니다.

CIFAR100과 Tiny-ImageNet과 같은 작은 크기의 데이터셋에서 표준 ViT의 top-1 정확도를 나타낸 Table 1을 살펴보면, softmax의 온도가 보다 낮을 때 최상의 성능을 관찰할 수 있습니다. 이러한 smoothing 문제를 해결하기 위해 LSA 를 사용하였다고 볼 수 있습니다.
Results

SPT와 LSA를 ViT에 적용했을 때, 최종 class token의 attention score를 시각화한 결과, 어텐션이 target class 에 집중되는 모습을 확인할 수 있습니다.(여기서, 모델명 앞에 SL이 붙은 것이 SPT와 LSA를 적용한 내용입니다.)
locality inductive bias를 증가시키고 ViT의 attention을 개선하도록 유도되는 것을 확인할 수 있습니다.

