
Efficient Training of Visual Transformers with Small Datasets
본 논문은 작은 데이터셋에서 ViT(Visual Transformer)의 효율적인 학습을 위한 방법을 제안하는 논문입니다. 작은 데이터셋에서 ViT의 성능을 향상시키기 위해 보조 자기 지도 학습(auxiliary self-supervised task)을 제안하였는데요,
보조 자기 지도 학습(auxiliary self-supervised task) 은 ViT가 이미지의 공간적인 관계를 학습하도록 유도하여, 작은 데이터셋에서도 높은 분류 정확도를 달성할 수 있도록 합니다. 구체적으로, 보조 자기 지도 학습은 ViT의 출력 토큰 임베딩 간의 공간적인 관계를 학습하는 것으로, 이미지에서 무작위로 샘플링한 페어(pair) 간의 기하학적 거리를 예측 하는 과정을 가집니다. 이를 위해 임베딩에 지역 정보(local information) 와 문맥 정보(contextual information) 가 모두 인코딩되어야 합니다. 이 방법은 작은 데이터셋에서 ViT의 generalization을 향상시키는 데 효과적이며, 다른 종류의 신경망에도 적용될 수 있다는 이점이 있습니다.
Introduction : ViT for Small Size Datasets
먼저, 작은 사이즈의 데이터셋에서 ViT의 효율적인 학습에 대해 다루고 있습니다. 이는 실제 응용 분야에서 데이터셋이 작거나 제한적인 경우가 많지만, 기존의 ViT 모델들은 대부분 대규모 데이터셋(ImageNet) 에서 사전 학습된(pre-trained) 모델을 사용하는 것이 일반적이며, 작은 데이터셋에서는 성능이 크게 저하될 수 있습니다.
따라서, 본 논문에서는 small size datasets 에서의 ViT의 성능을 향상시키기 위한 모델을 구축하였습니다.
small size datasets 에서도 높은 분류 정확도를 달성할 수 있는 vision transformer 모델을 탐색하고, 이를 위한 보조 자기 지도 학습 방법 을 제안합니다. 이 방법은 ViT가 이미지의 공간적인 관계를 학습하도록 유도하여, 작은 데이터셋에서도 높은 분류 정확도를 달성할 수 있습니다.
Related work : Self Supervised Learning
본 논문에서 제시하는 방법 중 중요한 것은, Self supervised learning 입니다.
Self-supervised learning 은 지도 학습(supervised learning)과 달리, 사람이 직접 레이블을 달지 않고도 데이터로부터 스스로 학습하는 방법입니다. 이를 위해 데이터셋에서 자동으로 생성된 레이블을 사용하거나, 데이터셋 내에서 특정한 패턴이나 관계를 학습하는 방법을 사용합니다.
이러한 self-supervised learning은 비용이 많이 드는 labeling 작업을 대신할 수 있으며, 대규모 데이터셋에서 효과적으로 작동할 수 있습니다. 또한, 이를 통해 사전 학습(pre-training)된 모델을 사용하여 다양한 computer vision task에서 높은 성능을 달성할 수 있습니다.
이 논문에서는 self-supervised learning의 한 종류인 보조 자기 지도 학습(auxiliary self-supervised learning) 을 사용하여 작은 데이터셋에서 ViT의 성능을 향상시키는 방법을 제안합니다.
이 방법은 작은 데이터셋에서도 높은 분류 정확도를 달성할 수 있는 비전 트랜스포머 모델을 탐색하기 위해 사용되며, ViT가 이미지의 공간적인 관계를 학습하도록 유도합니다.
보조 자기 지도 학습 : Auxiliary self-supervised learning
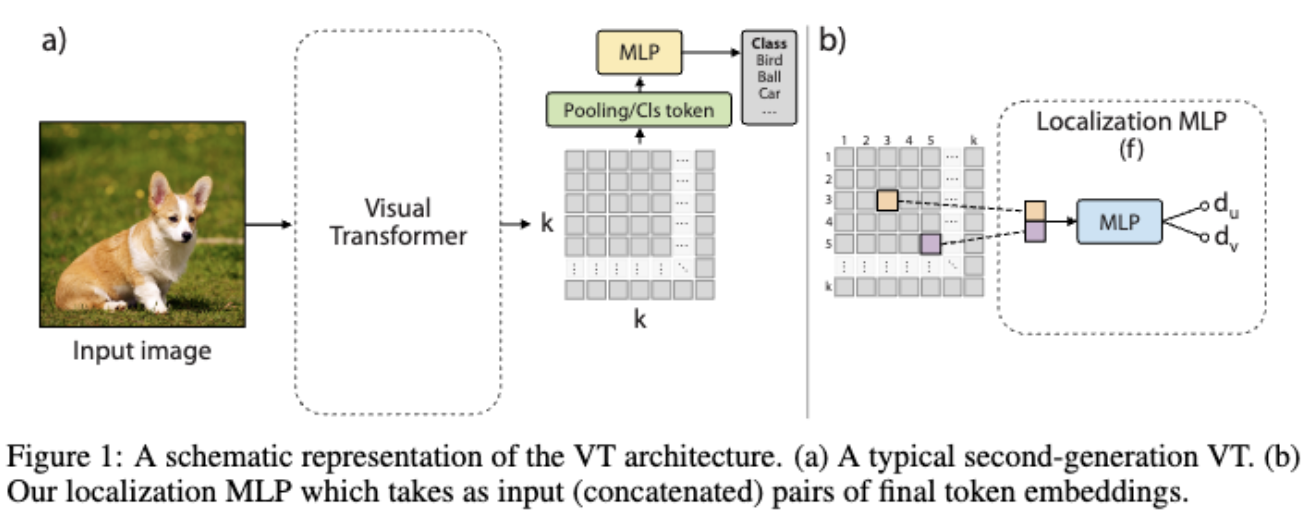
보조 자기 지도 학습 방법은 self supervised learning 의 종류 중 하나로,데이터셋에서 레이블을 직접 사용하지 않고, 데이터셋 내에서 이미지의 특정한 패턴이나 관계를 학습하는 방법입니다.
일반적으로 보조 자기 지도 학습은 이미지에서 두 가지 다른 view(다른 crop 된 이미지들)를 추출하고, 이를 서로 다른 이미지로 간주하여 서로 공유하는 semantic contents를 학습하는 방법을 사용합니다.
이러한 방법은 contrastive learning, clustering methods, asymmetric networks, feature-decorrelation methods 등이 다음과 같이 학습을 진행합니다.
여기서, VT 네트워크란?
VT 네트워크는 Computer Vision에서 사용되는 딥러닝 모델 중 하나로, 이미지를 grid 형태의 패치로 분할하고, 각 패치를 linear embedding하여 "토큰"으로 만든 후, 이를 multi head attention과 feedforward layer를 통해 처리합니다. (그냥 ViT 안의 구조라고 보면 됩니다. 본 논문에서는 다음과 같은 워딩을 사용합니다.)
SSL은 VT에서 이미지의 공간적인 관계를 학습하도록 유도하기 위해,VT의 출력 토큰 임베딩 간의 공간적인 관계를 학습하기 위해, VT에서 생성된 임베딩 간의 상대적인 거리를 사용하여 embedding grid 형태로 재구성하여, 각 임베딩 벡터의 위치가 입력 이미지의 고정된 위치에 해당하는 기하학적 레이아웃을 만듭니다.
이러한 임베딩의 기하학적 배치를 사용하여, convolution layer를 인접한 임베딩에 적용하여 네트워크가 이미지의 지역적 특성에 집중하도록 유도합니다. 이러한 hybrid architecture는 초기 임베딩에서만 conv layer를 사용하는 방법부터, 모든 레이어에서 conv layer를 사용하는 방법까지 다양하게 제안되었습니다.
Preliminaries
VT 네트워크의 입력 및 출력과정을 살펴볼까요?
VT 네트워크는 입력 이미지를 K × K patch 로 분할하고, 각 패치를 입력 임베딩 공간으로 투영하여 K × K input token set 를 얻습니다. VT는 Transformer의 multi attention layer를 기반으로 하며, 토큰 중간(intermediate) 표현에서 pairwise relations를 모델링합니다.
Hybride architecture 에서는 순수 Transformer와 달리, 이러한 토큰 임베딩의 시퀀스를 spatial grid로 형태를 변형하여 이웃,인접하는 토큰 임베딩의 작은 집합에 대해 conv 연산을 적용할 수 있습니다.
이를 통해 초기 K × K token grid의 해상도를 줄일 수 있으며 CNN의 계층 구조를 simulation할 수 있습니다. conv 연산을 사용하여 초기 K × K 토큰 그리드의 해상도를 줄이면서도, VT 네트워크의 입력 이미지의 공간적 구조를 유지할 수 있다는 이점을 가지게 됩니다.
결과적으로 본 논문의 방법을 사용하여, VT 네트워크의 최종 임베딩 그리드는 k × k의 해상도를 가지며, 이는 일반적으로 K보다 작습니다. 이러한 VT 네트워크의 최종 k × k 임베딩 그리드는 입력 이미지를 나타내며, 이를 이용하여 classification task 등의 판별적인 작업을 수행할 수 있습니다.
Dense Relative Localization task
Auxiliary Self Supervised Learning 을 위한 방식은 Dense relative localization task 을 활용하여 진행합니다.
Dense relative localization task 는 VT 네트워크를 이용하여 이미지의 공간 정보를 학습하는 방법 중 하나로, 추가적인 수작업 주석 없이도 VT 네트워크가 이미지의 공간 정보를 학습할 수 있도록 하는 것을 목표로 합니다.
이 방법은 각 이미지의 k × k grid에서 embedding pairs 를 밀도 있게 샘플링하고, 각 pairs의 상대적인 거리를 추측하도록 네트워크에 요청합니다.
이를 위해, 각 이미지 x에 대해 해당 이미지의 k × k grid를 로 표현합니다. 여기서 는 임베딩 벡터이며, d 차원의 임베딩 공간에서 정의됩니다.
그런 다음, 각 에서 임의의 쌍 에 대해 2D로 정규화된 대상 이동 오프셋 (2D normalized target translation offset) 을 계산합니다.
이때, 와 는 각각 i와 p, j와 h의 차이를 k로 나눈 값이며, 이러한 target translation offset은 [0, 1] 범위 내에 존재합니다.
이러한 방법을 통해 뽑아낸 대상 이동 오프셋을 이용하여, VT 네트워크는 이미지의 공간 정보를 학습하고, 이를 이용하여 classification task 등을 수행할 수 있습니다.
Expectations of this method
본 논문의 방법은 이전의 이미지 self supervised learning 과는 달리, 이미지의 여러 부분을 추출하거나, 이미지를 회전시키는 등의 추가적인 전처리 과정이 필요하지않으며, 이미지의 spatial information를 남김없이 꼼꼼하게 학습할 수 있답니다.
또한 VT 네트워크가 이미지의 공간 정보를 학습하는 데 훨씬 효율적인 정규화 작업을 수행하므로, VT 네트워크가 일반적인 inductive bias를 가지고 있지 않아도 더 나은 성능을 보여줄 수 있게됩니다. 이 방법은 큰 데이터셋을 사용하지 않으면 학습하기 어려울 수 있습니다. 따라서 Auxiliary self supervised learning 을 추가적으로 진행해 작은 데이터셋에서도 활용할 수 있도록 진행하는 것이죠 !
Results

논문에서의 방법을 사용하면 작은 데이터셋에서도 dense relative localization을 사용하여 학습한 VT 네트워크가 다른 자기 지도 학습 방법보다 더 높은 성능을 보인다는 것을 확인할 수 있습니다.
CIFAR-10 데이터셋에서 학습한 VT 네트워크는 다른 자기 지도 학습 방법보다 더 높은 정확도를 보입니다. 이러한 결과는 dense relative localization이 작은 데이터셋에서도 VT 네트워크가 이미지의 공간 정보를 보다 밀도 있게 학습할 수 있도록 하기 때문임을 볼 수 있겠죠?
Understanding Why ViT Trains Badly on Small Datasets : An Intuitive Perspective
본 논문에서는 제목 그대로 '왜 ViT 는 작은 사이즈의 데이터셋에서 잘 작동하지 않을까?' 를 바탕으로 다양한 실험을 통해 그 원인을 분석하였습니다.
메인 실험의 경우, 적은 파라미터를 가진 ResNet-18과 비교하였는데요, 이렇게 적은 양의 파라미터를 가진 모델보다도 ViT가 성능이 낮음을 결과로, feature map visualization 등을 통해 결과를 해석하였습니다.
또한, 큰 사이즈의 데이터셋으로 훈련한 ViT와 작은 사이즈의 데이터셋으로 훈련한 ViT간의 performance 정도도 비교하는 등 다양한 실험을 통해 원인을 분석하였습니다.
Introduction
attention mechanism은 NLP에서 시작되어 이제는 computer vision 에서도 높은 성능을 보이고 있지만, 여전히 작은 사이즈의 데이터셋에서는 성능이 현저히 낮음을 확인할 수 있습니다. 이를 보완하기 위해 고안된 Shifted Patch Tokenization (SPT) 라던지, Locality Self-Attention (LSA) 등은 small size datasets 에서 transformer의 정확도를 높이는 것을 입증 받았지만, 그 결과 또한 CNN보다는 성능이 낮은 것을 확인할 수 있습니다.
본 논문에서 저자들은 왜 vision transformer들이 CNN 보다 작은 데이터셋에서 낮은 퍼포먼스를 보이는지를 입증하였고, 그 결과를 시각적 증거와 유사도 분석을 통해 제공하였습니다.
결과적으로,
- ViT 와 ResNet : CIFAR-10,CIFAR-100,SVHN datasets에서, ViT는 좋은 퍼포먼스를 보이지 못한다. ( CNN 승)
- ViT 에서 attention visualization을, ResNet 에서 feature map visualization을 통해 각 모델안 각 레이어의 가중치를 시각적으로 보여주었다.
- ViT와 ResNet을 작은 데이터셋과 큰 데이터셋에서 각각의 표현 유사도를 경험적으로 측정하였고 ViT에서 작은 데이터셋에서 performance drop을 focus 하여 확인하였다.
Model and Data
이 파트에서는, 본 실험에서 사용한 모델과 데이터를 소개하였습니다.
간단하게 ViT 와 파라미터 개수도 비슷하고 모델의 효율성을 따져 ResNet-18을 비교 대상으로 사용하였고, 데이터셋의 경우 작은 데이터셋들인 CIFAR-10,CIFAR-100,SVHN(Street View House Numbers) datasets 을 사용하였다고 합니다.
training 시에는 두 모델이 조건이 동등하도록 옵티마이저들을 동일하게 맞추고, 500에폭, wandb 등을 사용하였다고합니다. (wandb를 사용하면 로스나 정확도등에 동일 데이터셋의 다른 모델들을 비교할 수 있습니다.)
Visualization of Layers
Top-1 acc 부터 확인해보겠습니다. 비교적 데이터셋이 단조로운 SVHN 같은 경우, 학습 시간은 느렸지만 비슷한 정확도를 보이는 것을 확인할 수 있었습니다. 하지만 CIFAR-10과 CIFAR-100의 경우에는, 정확도가 현저히 떨어지는 것을 볼 수 있습니다.
Visualization of Layers를 확인할 때 ViT 의 경우 attention weights 를 확인할 수 있고, ResNet 의 경우 feature mapping을 볼 수 있기 때문에 두개가 완전히 비교할만한 동등한 대상일 수는 없지만, 저자는 여기서 파라미터의 black box 이면을 보면서 Logic을 이해할 수 있다고 이야기하고 있습니다.
Attention weights for ViT
Attention weight 를 뽑아내는 과정은 다음과 같이 간단하게 볼 수 있습니다.
- 처음 attention layer를 로 각 트랜스포머 블록 마다 추출합니다.
- weight 값들을 평균을 내고 잔차 연결(residual connection)을 설명하는 identity matrix를 더해줍니다.
- weight mask 를 만들기 위해, matrix를 normalize 하고 reshape 하는 과정을 거칩니다.
- 시각화를 촉진시키기위해서, 각 weight mask 는 모든 mask 합이 1이 되도록 조정됩니다.
- 마지막으로, 각 weight mask 를 기존 이미지의 맨 첫번째 층으로 겹쳐서 attention map을 뽑아냅니다.
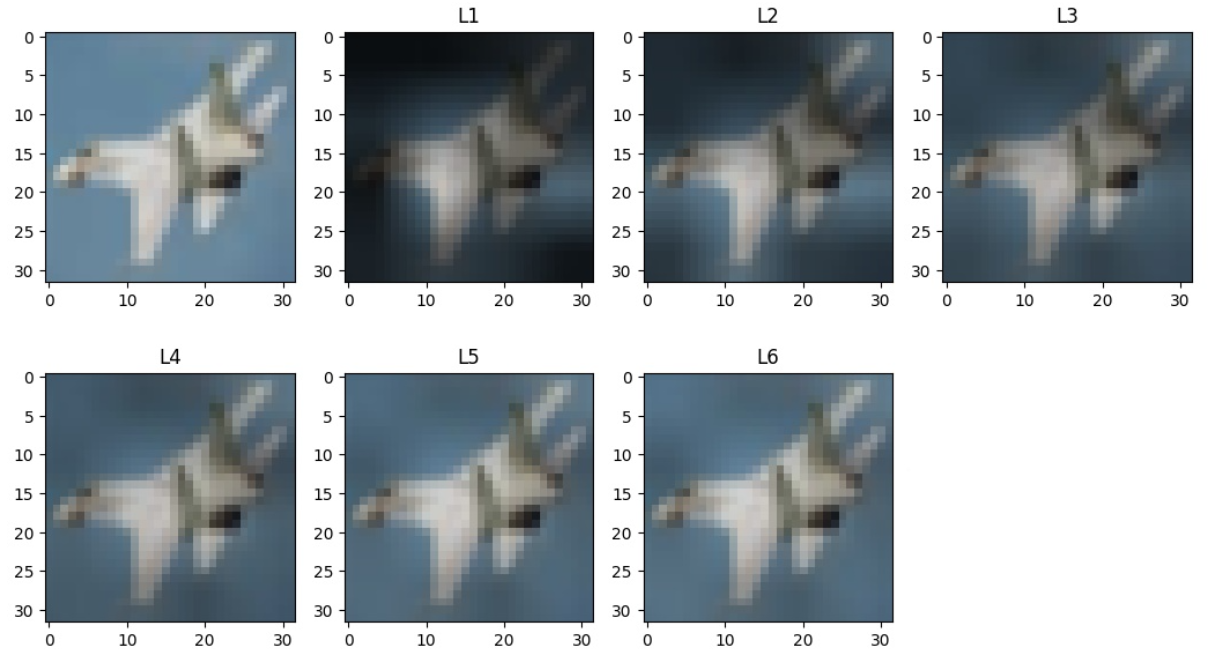
뽑아낸 이미지를 보면 L1의 경우 첫번째 레이어 층으로, 모든 weight mask 들이 합쳐진 attention map 입니다. 결과적으로 층이 1로 갈수록 인접한 영역과 대조되어 특정 area가 highlight 되는 것을 확인할 수 있습니다.
따라서 ViT에서는 higher local contrast 영역에 더 높은 attention을 준다는 것을 확인할 수 있습니다.
Feature Map Visualization for ResNet
feature map은 conv layer의 결과물로, 여기서는 17개의 피처맵을 뽑아냈다고 합니다.
Representation Similarity Analysis
유사도 분석은 CKA(Centered Kernel Alignment) 를 활용하여 분석을 진행하였습니다. 계산식은 다음과 같습니다.
두 layer 사이의 CKA 값이 커지면, 두 layer 가 유사도가 높다는 의미가 됩니다.
이를 통해 확인한 representation similarity를 확인해보면,
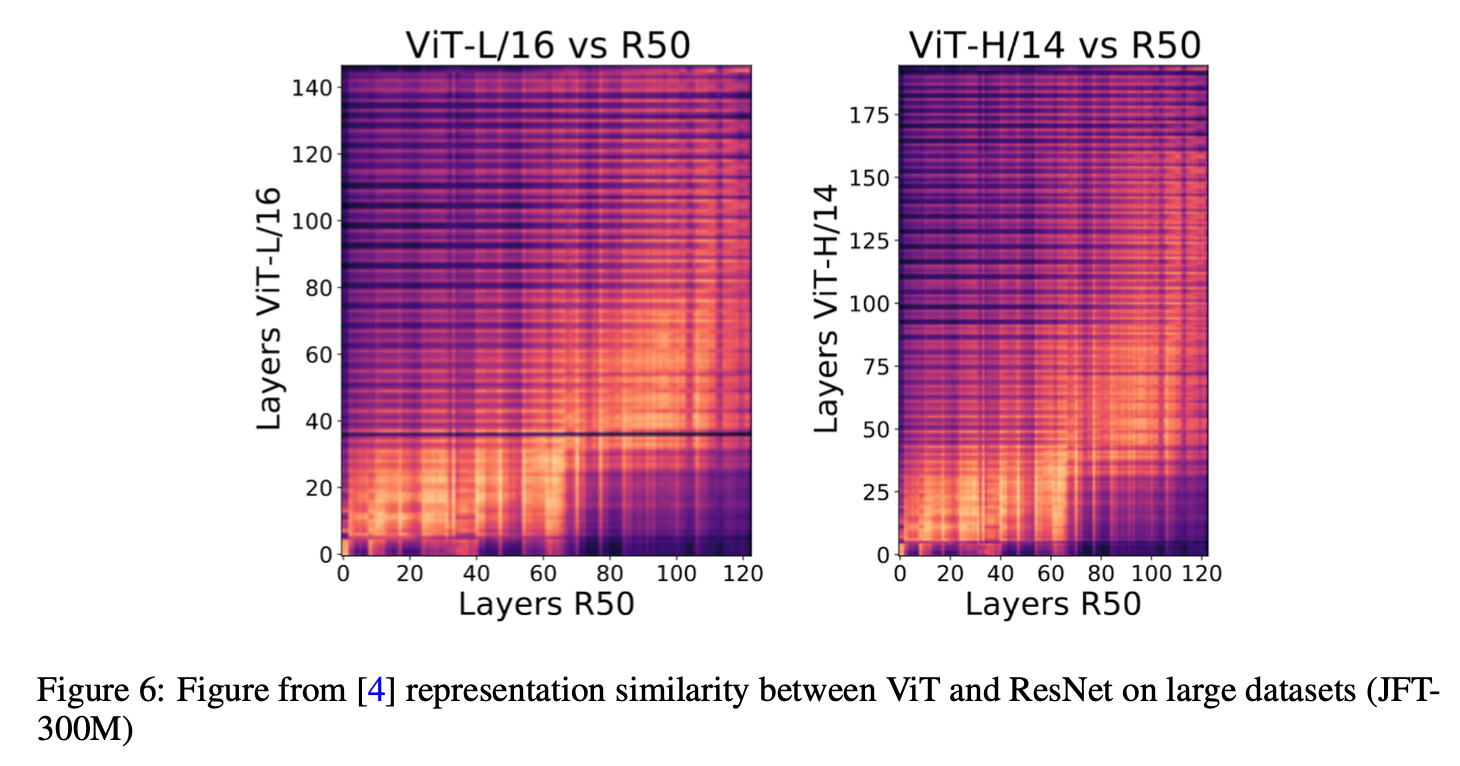
large dataset의 경우, ResNet 과 ViT 모두 비슷한 layer 층에서 similar representation이 잘 나타나는 것을 확인할 수 있습니다. 유사도가 비슷하다는 것을 뜻합니다.

(a) 와 (b) 를 확인해보면 figure 6에서 확인했었던 뚜렷한 패턴들이 사라져있는 것을 확인할 수 있습니다. 이 말은 즉 CIFAR-10과 CIFAR-100에서는 마지막 performance 가 크게 떨어진다는 것을 의미합니다. (c)의 경우 FIgure 6 과 비슷한 경향성을 보이지만, 중간 층에서의 ViT 가 높은 층에서의 ResNet과 비슷해지고, 높은 층에서의 ViT는 모든 층의 ResNet과 유사도가 거의 없는 모습을 확인할 수 있습니다. (검은색 부분)
이러한 결과를 따라서, 비슷한 숫자의 층마다 같아지게 하려면 ViT의 layer 가 더 많아져야한다는 것을 의미하는데요, 그것 뿐만아니라 왜 SVHN dataset에서만 이러한 비슷한 결과가 나왔느냐가 중요합니다.
이는 SVHN dataset이 다른 작은 사이즈의 데이터셋들보다 훨씬 단순하였기 때문에 ViT 모델이 지역적인 (국소적인) inductive bias 를 찾아내기 훨씬 쉬웠기 때문이라고 판단하였습니다.
Results
저자들은 결과적으로 ViT가 왜 작은 사이즈의 데이터셋에서 performance drop이 나타나는지를 다음과 같은 이유로 제시하였습니다.
- 작은 사이즈의 데이터셋을 훈련시킬 때, ViT의 표현이 큰 사이즈의 데이터셋을 훈련시켰을 때보다 차이가 많이 나기 때문이다.
(당연한소리를..?) - 이런 큰 표현의 차이가 나는 이유는 ViT의 지역적인 (국소적인) inductive bias의 부족 때문이다.
낮은 층의 ViT는 이런 국소적인 관계를 잘 학습하지 못하는데, 특히 작은 데이터셋 + 복잡할 경우 에는 더더욱 학습을 못하게 된다. 만약 작은 데이터셋이라고 하더라고 단순한 데이터셋일 경우에는, 성능이 조금 좋아질 수 있다.
Efficient Training of Visual Transformers with Small Datasets - 논문 보기
Understanding Why ViT Trains Badly on Small Datasets : An Intuitive Perspective - 논문 보기

좋은 글 감사합니다.