
Transformer : Attention Is All You Need
CNN 네트워크를 지나 새로운 네트워크를 공부해보자 !
2017년 NIPS에서 발표한 Transformer 는 그전까지 NLP(Natural Language Processing)분야에서 많이 쓰이던 인공신경망 구조가 아닌 Attention이라는 메커니즘을 새로 발명하여 좋은 성과를 내다가, 분야를 넓혀 Image classification 이나 Image detection, Image retrieval 등 NLP를 넘어 컴퓨터 비전분야까지 좋은 성능을 내며 새롭게 등장하였다.
Background
여기서는 기존 모델들의 한계점에 대해 개략적으로 이야기한다.
이전의 computation 모델들은 RNN, LSTM, GRU, CNN 등의 구조를 사용하여 입력 시퀀스를 처리하고 출력 시퀀스를 생성한다. 그러나 이러한 모델들은 병렬화, 메모리 접근, 장기 의존성 처리 등의 측면에서 한계가 있다.
Transformer 구조 의 이점에 대해 비교하여 알아보자면,
- Sequential computation
sequence to sequence의 문제를 푸는 과정에서, Encoder-Decoder 구조의 RNN 모델들이 좋은 성능을 냈다.
기존 문제점 : sequence to sequence 에서 context vector 𝑣에 소스 문장의 정보를 압축하게 되는데, 이 과정에서 병목(bottleneck)이 발생하여 성능 하락의 원인이 만들어지게 된다. 압축하는 과정이 없는 transformer 구조가 이를 해결하였다는 것 !
- Long term dependency
RNN의 경우, Long term dependency의 문제가 매번 존재하며, CNN의 경우 kernel 안에서 O(1)이나, kernel 간 정보가 공유되지 않는다.
이러한 한계를 극복하기 위하여, Transformer 모델은 self-attention 메커니즘을 사용하여 입력 시퀀스의 각 위치를 가중치로 나타내고, 이를 활용하여 출력 시퀀스를 생성한다.
self-attention 메커니즘 은 입력 시퀀스의 모든 위치를 동시에 처리할 수 있으며, 장기 의존성 처리 능력이 뛰어나다는 장점이 있다. 이러한 self-attention 메커니즘을 사용한 Transformer 모델은 기존의 모델들보다 더욱 효율적이고 정확하게 다양한 테스크들을 수행할 수 있다고 한다. (핵심 부분만 요약하기, 기계 번역하기 등)
Model Architecture
논문에서 나온 기본 구조를 도식화하면 다음과 같다.
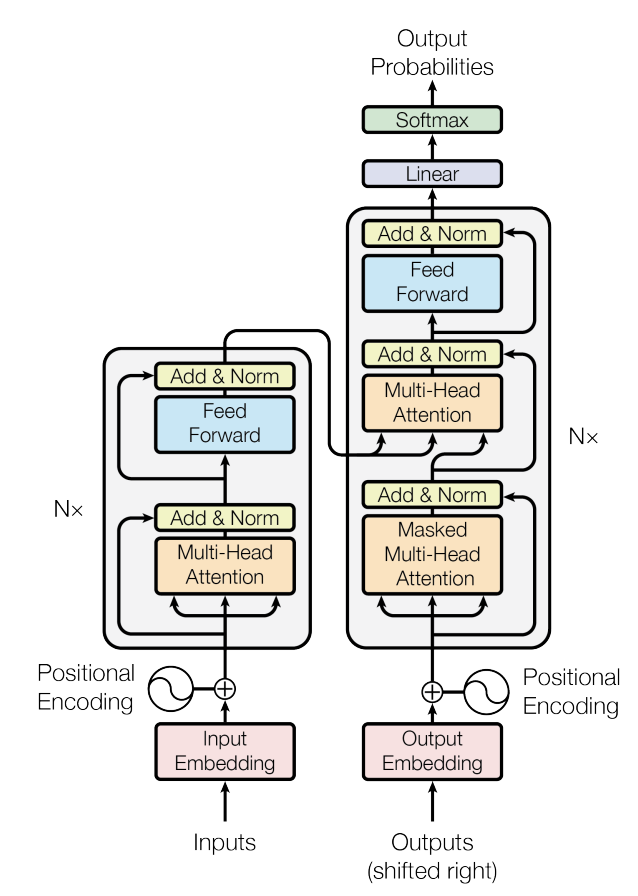 각각 내용들을 확인해보자 ! 크게 `Encoder` 와 `Decoder` 로 구성되어있다.
각각 내용들을 확인해보자 ! 크게 `Encoder` 와 `Decoder` 로 구성되어있다.
Encoder
표현을 이미지로 잘 해놓은 Jay Alammar 의 블로그를 참고하였다.
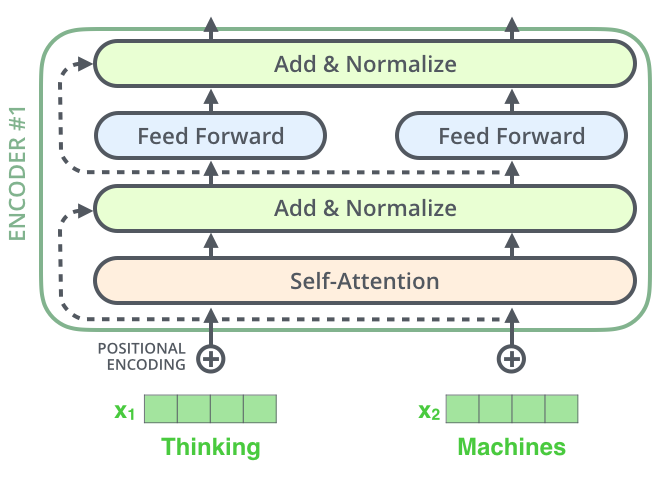
인코더에서,N = 6개의 stack 으로 구성되어 있다고 했다.
하나의 인코더는 Self-Attention Layer와 Feed Forward Neural Network로 이루어져있다. 즉, 2개의 sub-layer 를 가지고있는 것 !
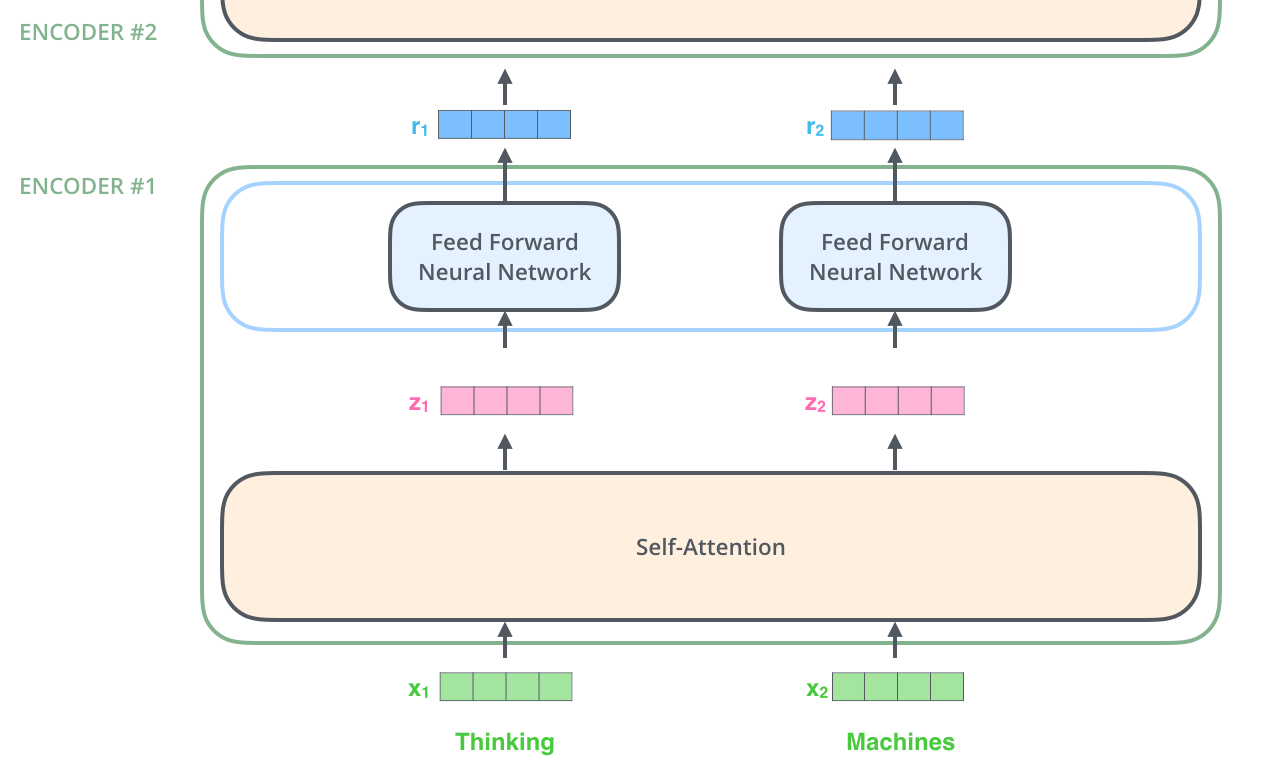
ENCODER #1 에서 내부 sub-layer 들을 확인할 수 있다.
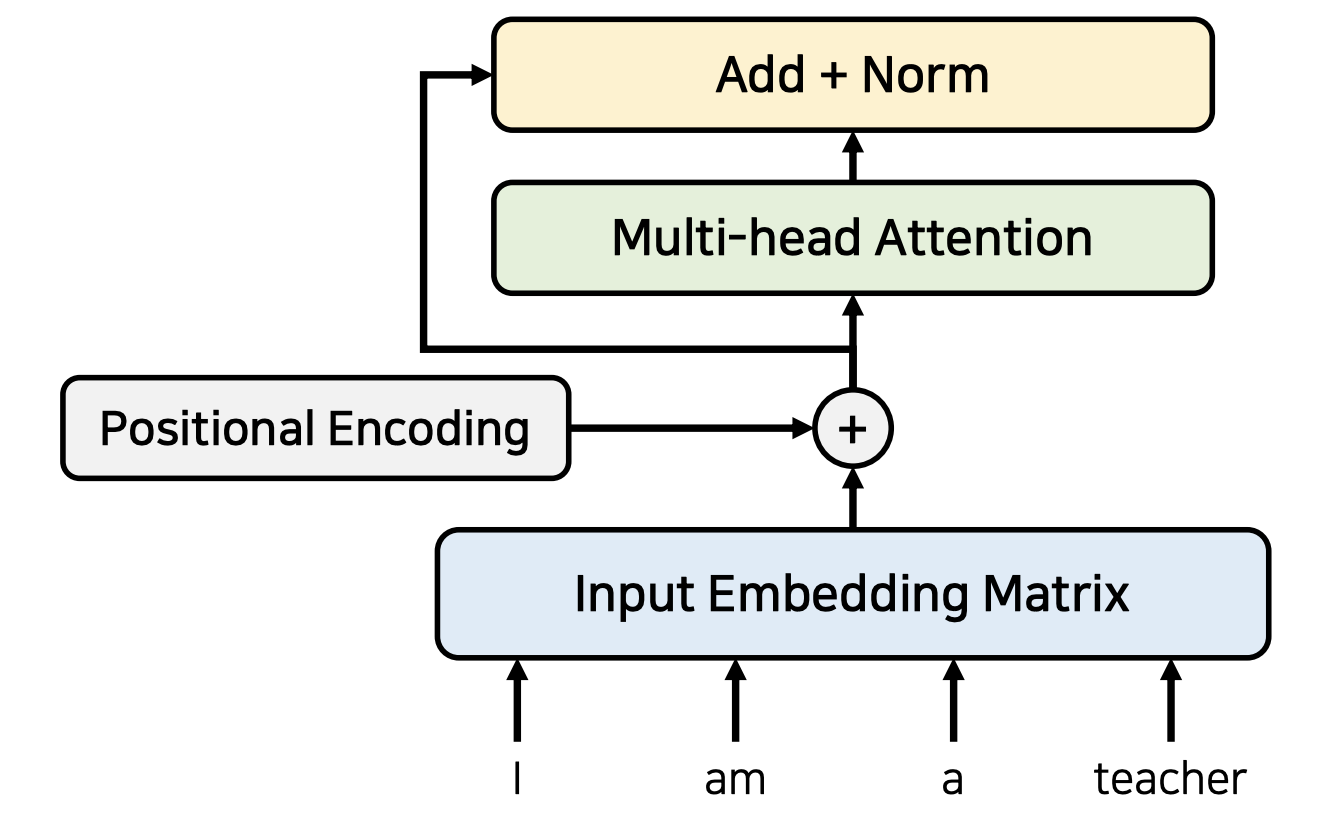
인코더의 전반적인 구조를 확인하면 위의 이미지와 같다.
가장 중요한 Self-attention 단일층 구조부터 확인해보자.
Self-Attention Layer
Self-Attention Layer 부터 살펴보자.
Self-Attention 에 사용되는 개념부터 확인해야한다.
- Query(Q) : 영향을 받는 단어 A를 나타내는 변수
- Key(K) : 영향을 주는 단어 B를 나타내는 변수
- Value(V) : 그 영향에 대한 가중치
여기서, Query 벡터 와 Key 벡터 를 Dot-Product 를 진행하면 영향을 받는 단어와 영향을 주는 단어간 유사도를 측정할 수 있는 수치가 나오게 된다.
Dot-Product Attention은 다음과 같이 계산한다.
Q와 K 를 내적한 값을 softmax 함수로 돌려 0부터 1사이의 값으로 만든 후, V를 곱해서 최종적으로 Feed forward neural network의 Input 값으로 만들어준다.
이제부터는 Self-Attention 의 전체 과정을 확인해보자.
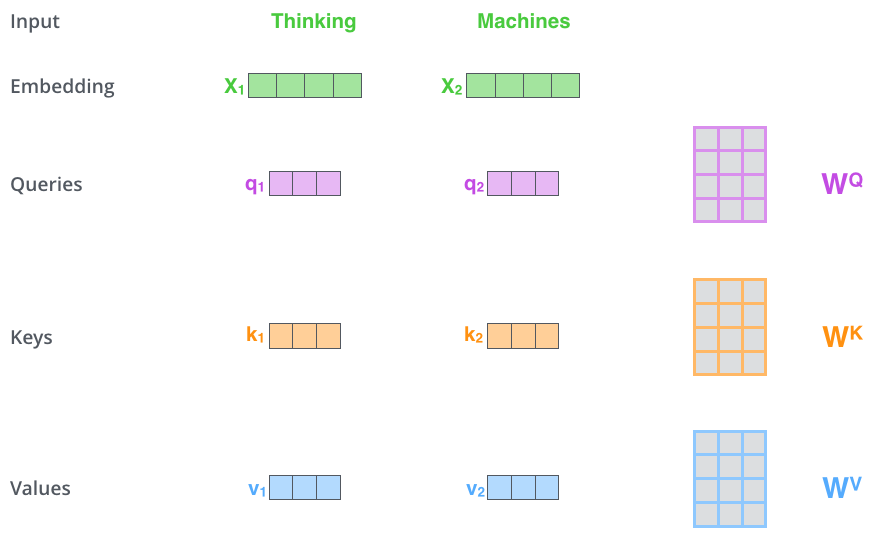
첫번째 : 3개의 벡터 만들기
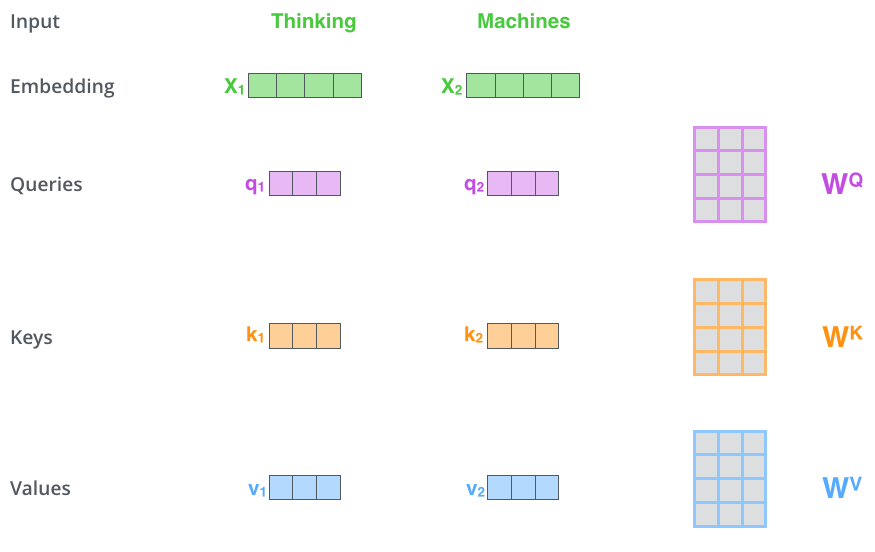
Self-attention 을 계산하는 첫 번째 단계는 각 인코더의 입력 벡터(이 경우 각 단어의 임베딩) 에서 세 개의 벡터(Q, k, V) 를 만드는 것이다.
각 단어에 대해 쿼리 벡터, 키 벡터 및 values 벡터를 만든다.
이러한 벡터들은 embedding 중 3개의 행렬을 곱하여 생성된다.
위의 그림에서 x1 에 WQ 가중치 행렬을 곱하면 해당 단어와 관련된 "쿼리" 벡터인 q1이 생성된다. 입력 문장에서 각 단어의 "쿼리", "키" 및 "값" projection을 만들게된다.
여기서 는 train 과정 중 훈련된 가중치 행렬로, 이들을 embedding vector인 X 에 각각을 곱하면 쿼리, 키, 벨류 값이 나오게 된다.
두번째 : score(내적) 계산하기
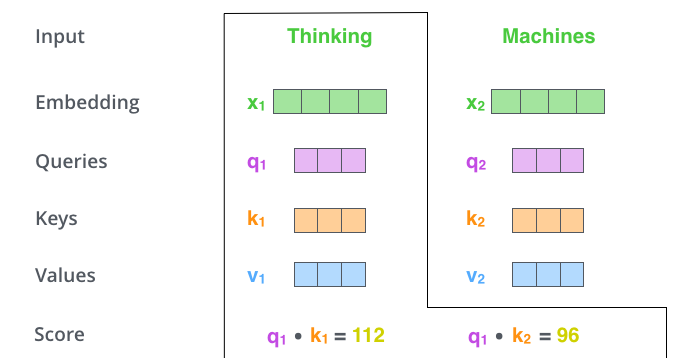
Self-Attention 계산의 두 번째 단계는 내적을 진행하여 score를 계산한다.
위 그림의 첫 번째 단어인 Thinking 에 대한 self-attention을 계산한다고 가정한다면, 이 단어에 대해 입력 문장의 각 단어에 대해 집중도, 즉 점수를 매겨야 한다.
점수는 특정 위치에서 단어를 인코딩할 때 입력 문장의 다른 부분에 얼마나 많은 focus를 둘 것인지를 결정한다. (이것이 바로 집중도 !)
점수는 점수를 매기는 각 단어의 키 벡터 와 쿼리 벡터 의 내적을 취하여 계산된다.
따라서 위치 ENCODER#1 에 있는 단어에 대한 셀프 어텐션을 처리하는 경우 첫 번째 점수는 q1 과 k1 의 내적이 되는 것이다.
세번째 : score를 8로 나누기 (면적으로 나누기)
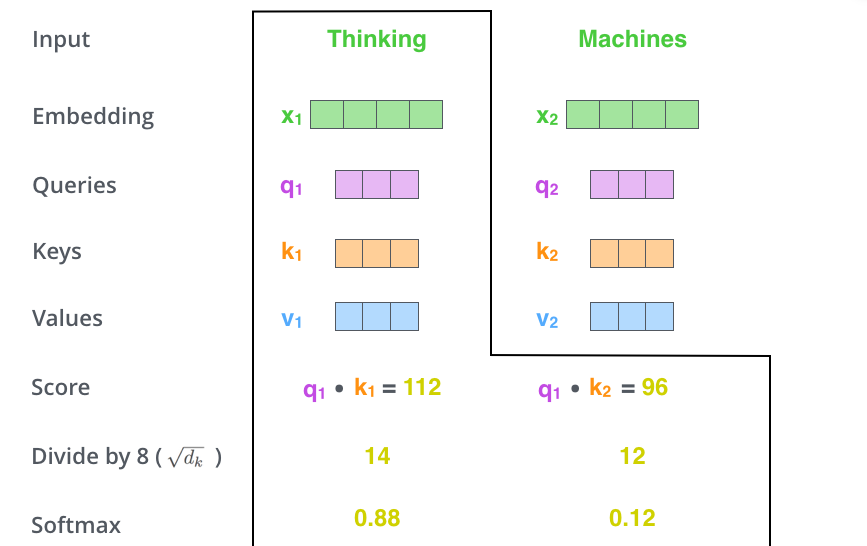
본 논문에서 사용된 키 벡터 차원의 제곱근 64를 사용하면 더 안정적인 gradient를 얻을 수 있다고 한다. 이는 내적을 진행하면 행렬값이 커지기 때문인데, 이를 output 크기로 맞춰주기 위해서 진행하는 과정이다.
이렇게 나눠진 score는 softmax 과정 을 통해 결과를 전달한다. Softmax는 score를 정규화하여 모두 양수이고 합이 1이 되도록 만들어준다.
이렇게 변환된 점수는 각 단어가 이 위치에서 표현되는 양을 결정한다.
단, 이는 주위 단어만의 연관도를 계산하였기에 아예 다른 단어와의 영향력은 다르게 봐야한다.
네번째 : 각 값 벡터에 score 곱하기, weight 값 벡터 합산하기
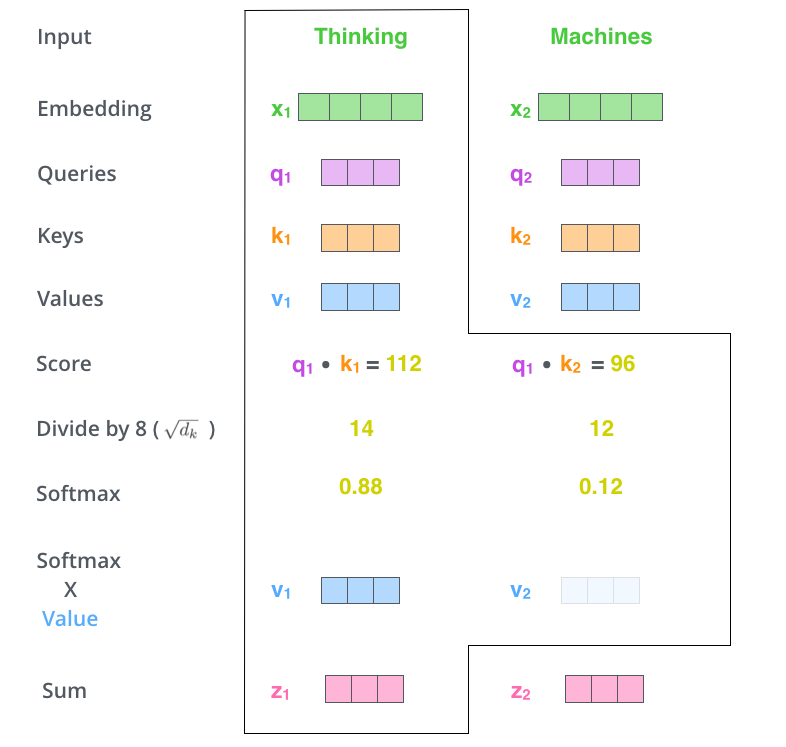
다음으로 각 value 벡터에 softmax 를 거친 score를 곱한다.
여기서 insight는 focus하려는 단어의 값을 그대로 유지하고 관련 없는 단어를 제거한다. 0.001과 같은 작은 숫자를 곱해서 말이다 !
마지막으로 각 encoder attention 에 계산된 weight 값 벡터를 합산을 진행한다. 해당 위치에서 self-attention layer의 출력을 생성하면서 마무리 짓는다.
Multi-head Attention
Multi-head attention 이란, self-attention layer를 다중으로 구현한 것으로, 다음과 같은 이점을 지니고있다.
-
다른 포지션에 Attention하는 모델의 능력을 향상시켰다.
self-attention은 다른 단어들과의 관계들도 보지만, 자기 자신의 단어에 영향력이 막대하는데, 이를 줄일 수 있다. -
여러 개의
representation subspaces를 생성할 수 있다.
Multi-head Attention 을 사용하면 여러 세트의 쿼리/키/값 가중치 matrix가 존재한다. 이러한 각 세트는 무작위로 초기화된다.
그런 다음 각 세트는 입력 embedding(또는 하위 인코더/디코더의 벡터)을 다른 representation subspaces로 투영하는데 사용된다. 그러므로 여러개 생성이 가능해진다는 뜻 !
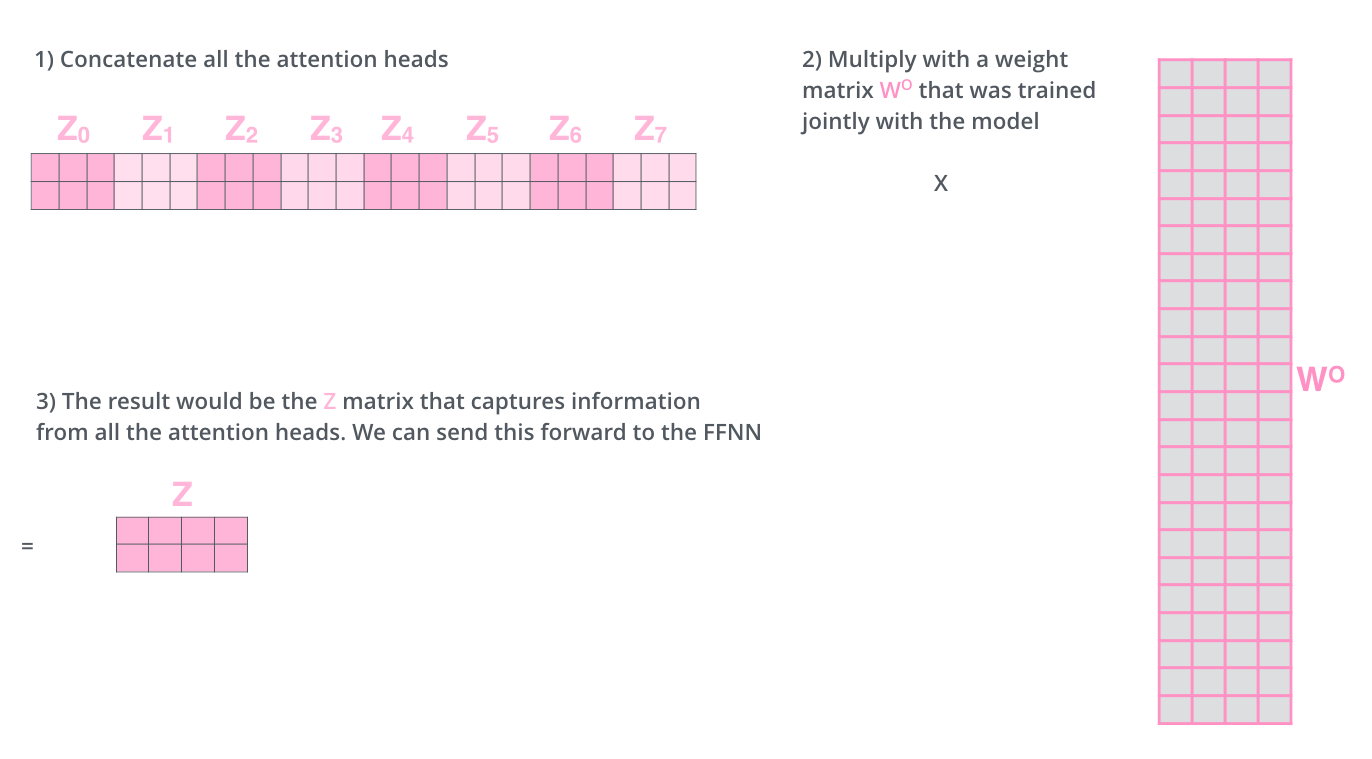
자, 여기서 동일한 self-attention 계산을 서로 다른 가중치 행렬로 8번만 수행하면 결국 8개의 서로 다른 Z 행렬이 생성 되는데, feedforward layer 는 8개의 행렬을 처리하지 않고 단일 행렬(각 단어에 대한 벡터)를 처리하기 때문에, 8개의를 하나의 단일 행렬로 압축을 진행한다.
압축 방법 !
위의 그림과 같이 각 헤드에서 나온 z벡터를 concatenate 시킨 다음, W⁰ (weight matrix)로 곱해줘서 z차원을 맞춰준다.
Positional Encoding
Transformer가 만들고 싶은 모델은 sequence to sequence지만, 위치 정보를 포함하고 있어야 하기에, positional encoding 기법 으로 각 단어의 상대적인 위치 정보를 포함하도록 만들었다.
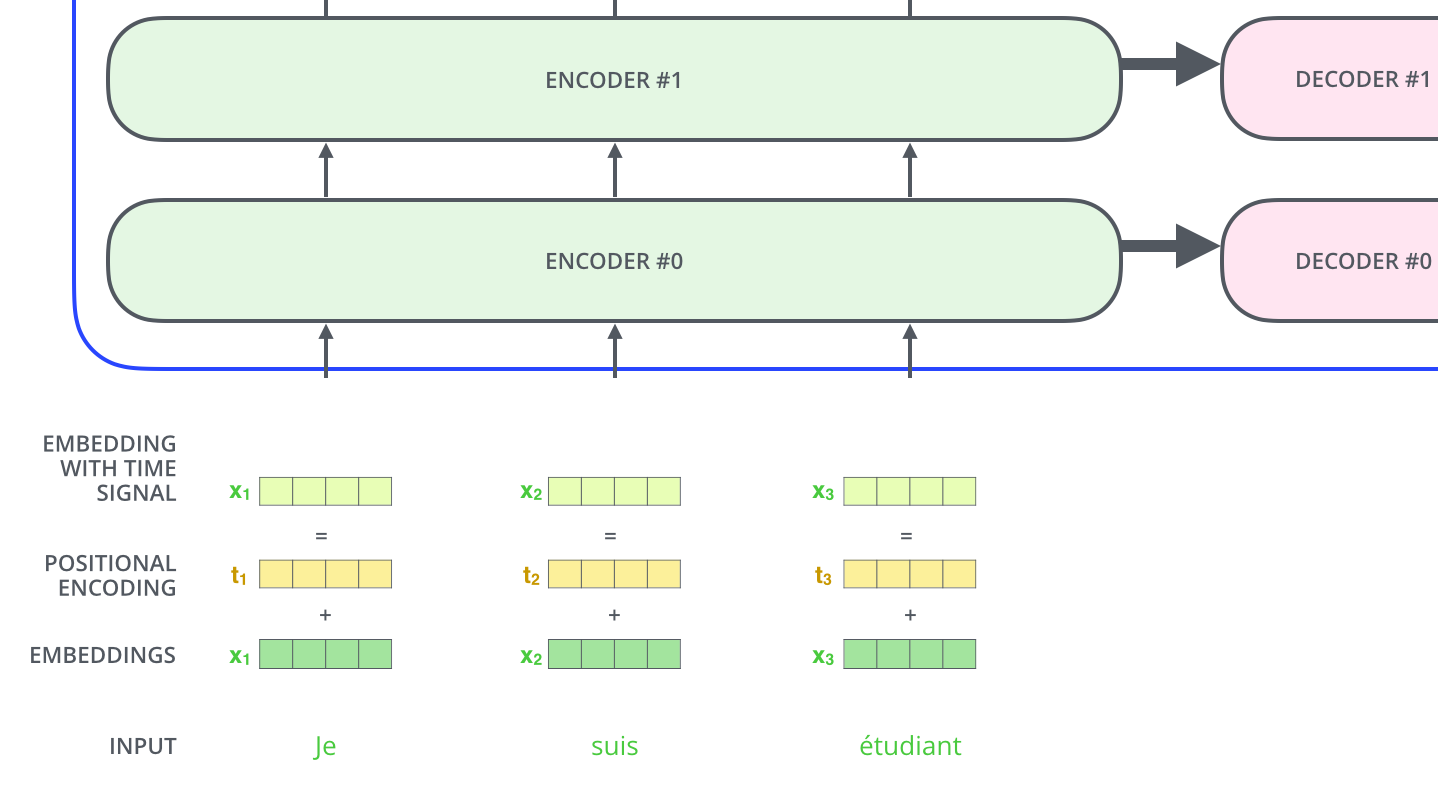
각 입력 embedding에 벡터를 추가한다. 벡터는 모델이 학습하는 특정 패턴을 따르므로 각 단어의 위치 또는 시퀀스에서 서로 다른 단어 사이의 거리를 결정하는 역할을 한다.
(detail 과정은 임베딩에 본 벡터를 추가하면 임베딩 벡터가 Q/K/V 벡터로 투영되고 내적 과정 동안 임베딩 벡터 사이에 유의미한 거리값이 생성된다.)
기존 Embedding과 같은 차원의 Positional encoding을 만들어 더해줌으로써, time signal을 가진 embedding을 input으로 받을 수 있다.
논문에서는 Positional Encoding의 식을 sinusoidal version 을 사용했는데, 그 이유는
- 각 포지션의 상대적인 정보를 나타내야하는데 적합
- 선형 변환을 통해 나타낼 수 있기 때문
We chose the sinusoidal version because it may allow the model to extrapolate to sequence lengths longer than the ones encountered during training. - page6
The Residuals
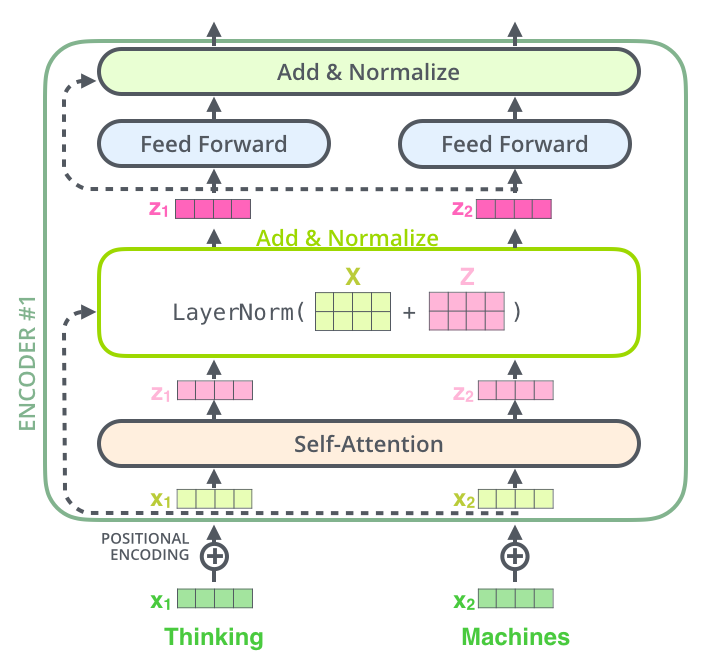
encoder 구조를 자세히 살펴보면, 각 sub layer마다 residual connection 을 가지고 있다. residual connection 이후, 바로 layer-normalization이 나온다.
이를 그림으로 확인해 보면 아래와 같다.
Decoder
Encoder 에서 대부분의 개념을 봤기에(거꾸로 버전이니까 디코더는) Decoder 에서는 구성 요소 와 작동 방식을 알아보면된다. 어떻게 같이 작동할까?
Encoder는 입력 시퀀스를 처리한 후, 상단 인코더의 출력은 어텐션 벡터 K 및 V 세트로 변환된다. 이들은 디코더가 입력 시퀀스의 적절한 위치에 focus하는 데 도움을 주는 Encoder-Decoder Attention layer 의 각 디코더에서 사용된다.
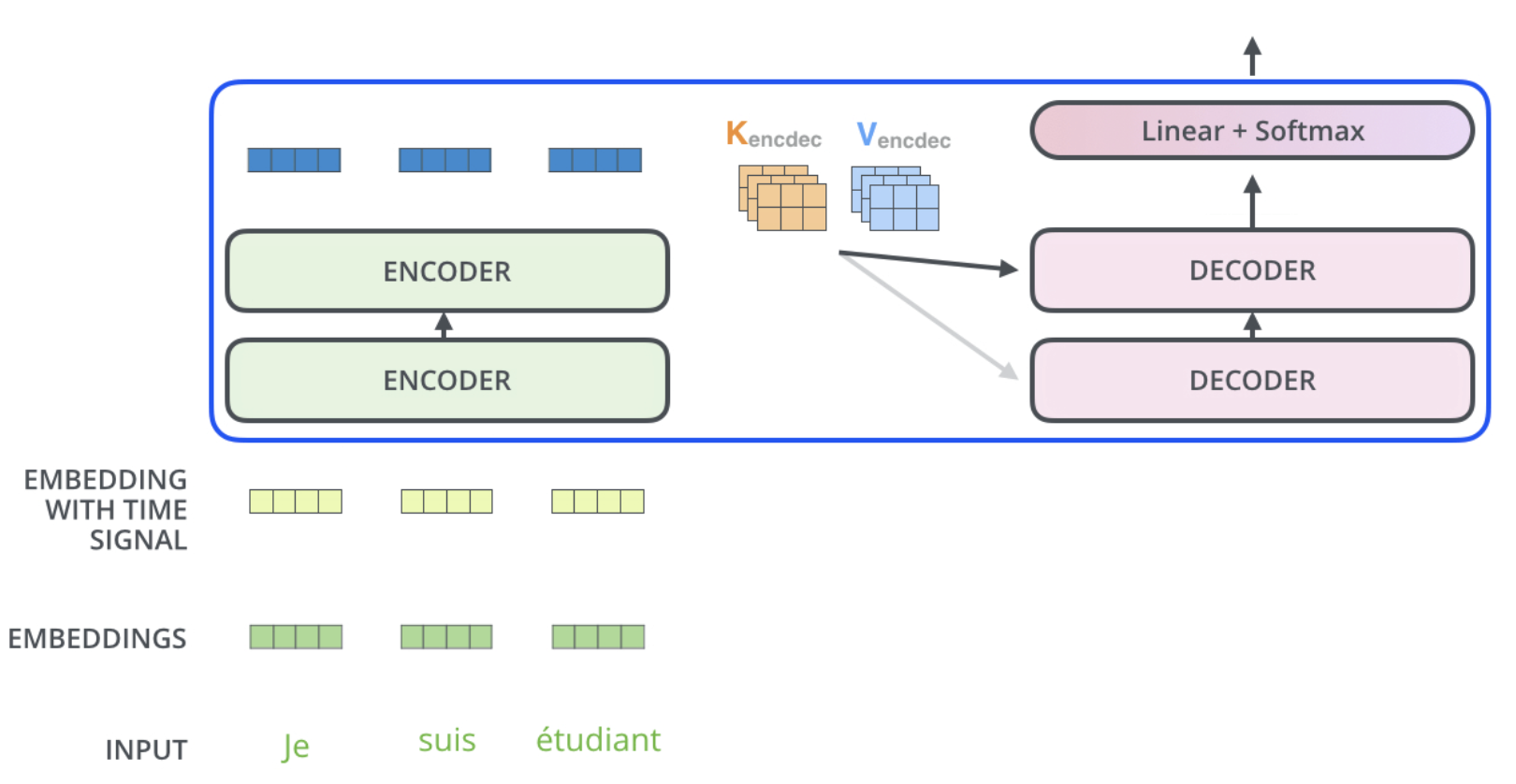
다음 time-step에서는 decoder의 직전 output을 input으로 다시 받아, Decoder stacks를 거쳐 Linear+Softmax를 한 뒤, 다시 output으로 출력하는 과정을 거쳐 번역된 문장을 마무리한다.

Encoder-Decoder Attention layer 는 아래 레이어에서 쿼리 매트릭스를 생성하고 인코더 스택의 출력에서 키 및 value 매트릭스를 가져오는 것을 제외하면 multi-head self attention과 동일하게 작동한다.
이로써 Transformer 의 전체적인 큰 틀에 대해 잡아봤다. 다소 어려운 논문이였기 때문에, 다양한 내용들을 참고하면서 작성해보았다.
