
DETR : End-to-End Object Detection with Transformers
Facebook 팀에서 개발한 DETR 은 DEtection TRansformer의 약자 Transformer 구조 를 활용하여, end-to-end로 object detection을 수행함과 동시에 높은 성능을 보이고 있습니다.
구조를 간단하게 설명해보면, DETR은 DEtection TRansformer의 약자로, Object Detection을 Direct Set Prediction Problem 으로 바라보는 새로운 방법론이다. DETR은 object detection의 기존 파이프라인을 간소화하고, non-maximum suppression procedure나 anchor generation과 같은 많은 수동적으로 해야하는 설계 요소를 제거하여 이전 방법론들보다 더욱 간단하고 높은 정확도와 빠른 속도를 볼 수 있다.

DETR은 bipartite matching loss와 transformer encoder-decoder architecture를 사용하여, 고정된 작은 수의 object queries를 기반으로 객체들의 관계와 전역 이미지 컨텍스트를 추론하여 병렬로 최종 예측 결과를 출력한다. 이 모델은 개념적으로 간단하며, 많은 다른 최신 검출기와 달리 전문 라이브러리를 필요로하지 않으며, 이전 방법론들과 다르게 새로운 시각에서 object detection을 다루고 있다는 점이 특별하다고 뽑을 수 있다. (근데 막상 실제로 이해하면 어려움...)
Object detection set prediction loss
DETR에서 사용하는 Object detection set prediction loss는 bipartite matching loss 를 기반으로 진행된다. 이 loss는 predicted objects와 ground truth objects 간의 최적의 bipartite matching을 찾아내는 것이 목표이다. 이를 위해, predicted objects와 ground truth objects 간의 pairwise similarity matrix를 계산하고, 이를 이용하여 최적의 matching을 찾아낸다.
최적의 matching 찾기
기존의 연구는 수 천개의 anchor를 생성하여, 객체를 예측하기 위한 proposal로 사용하는데 이는 객체가 얼마나 있는지 알 수 없기에 여러개의 anchor 를 생성한다.
본 논문에서 제안한 DETR은 고정된 크기의 N개의 prediction만을 수행함으로써, 수많은 anchor를 생성하는 과정을 생략하였다.
N 은 일반적으로 이미지 내 존재하는 객체의 수보다 훨씬 더 큰 수로 지정하였는데, 이는 DETR을 통해 예측하는 객체의 수는 최대 N개임을 알 수 있다. 이를 통해 적은 수의 prediction이 생성되어, ground truth와의 최적의 matching을 상대적으로 쉽게 수행할 수 있게된다.
y 는 객체에 대한 ground truth set이며 는 N개의 prediction이다. 이 때 y의 크기 역시 N개이며, 객체의 수를 제외한 나머지는 ∅(no object)로 pad된다. 즉 이미지 내 객체의 수가 3개이면,
y에서 97개는 ∅로 pad된다. 이 때 두 개의 set에 대하여 bipartite matching을 수행하기 위하여,다음과 같은 식을 통해 cost를 minimize할 수 있는 N의 permutation을 탐색을 진행한다.
수식을 이해하기 위하여,
- : Ground truth의 object set의 순열(permutation)
- : 를 최소로 하는 예측 bounding box set의 순열
- y : Ground truth의 object set & : 예측한 N개의 object set
- c : class label
- p(c): 해당 class에 속할 확률
- b : bounding box의 위치와 크기 (x, y, w, h)
여기서 는 ground truth 인 와 index가 인 prediction 사이의 pair-wise matching cost 이다. (이 값이 낮을 수록 두개가 잘 match 되었다는 뜻)
이 matching cost는 class prediction과 predicted bounding box와 ground truth box 사이의 similarity(유사도)를 모두 고려한다.
기존 연구에서는 predicted objects와 ground truth objects 간의 거리(distance)를 계산하는 방법은 bounding box regression loss 를 사용하였었다.
하지만 DETR의 loss는 predicted bounding box와 ground truth bounding box 간의 거리를 계산하여, 이 거리가 작을수록 더 좋은 예측이라고 판단한다. 이렇게 계산된 bipartite matching loss는 predicted objects와 ground truth objects 간의 일대일 대응을 보장하며, predicted objects의 순서에 불변한다.
여기서 순서에 불변한다는 의미는,
predicted objects를 출력할 때 그들의 순서가 중요하지 않다는 것을 의미한다. 예를 들어, 이미지 내에 세 개의 객체가 있다고 가정해 보자. DETR은 이 세 개의 객체를 각각 object query로부터 예측한다.
이때, DETR은 predicted objects를 출력할 때, predicted objects를 어떤 순서로 출력하더라도, 이들이 ground truth objects와 일대일 대응되는 한 bipartite matching loss를 최소화할 수 있다.
이러한 특징은 predicted objects를 병렬로 출력할 수 있도록 하며, 이는 DETR의 빠른 속도와 높은 정확도를 보장하는 중요한 요소 중 하나라고 볼 수 있다.
"Object detection set prediction loss를 계산하기 위해서 Hungarian Algorithm을 사용한다."
Hungarian Algorithm
기존의 algorithm을 활용하여 Loss 를 줄이기 위해 모든 조합의 경우의 수를 구해야한다는 단점이 존재한다.
Hungarian algorithm 은 bipartite graph에서 비용이 적게 드는 최적의 매칭을 찾는 알고리즘이다. 이 알고리즘은 bipartite graph에서 각 vertex가 두 개의 partition으로 나뉘어 있을 때, 각 vertex를 연결하는 edge들의 weight가 주어졌을 때, 최적의 매칭을 찾아내는 방식이다. 다음과 같은 단계로 이뤄진다.
- 각 row에서 가장 작은 값을 찾아 그 값을 row의 모든 원소에서 빼준다.
- 각 column에서 가장 작은 값을 찾아 그 값을 column의 모든 원소에서 빼준다.
- 남은 원소들 중에서 최적의 매칭을 찾는다.
- 만약 최적의 매칭이 아직 찾아지지 않았다면, 3번 과정에서 선택된 원소들을 이용하여 새로운 bipartite graph를 만들고, 1번부터 다시 진행한다.
이 알고리즘은 시간 복잡도가 O(n^3)으로 비교적 느리지만, 최적의 매칭을 보장한다는 장점이 있다. DETR에서는 이 알고리즘을 사용하여 predicted objects와 ground truth objects 간의 최적의 bipartite matching을 찾아내고, 이를 이용하여 bipartite matching loss를 계산한다.
matching된 pair를 기반으로 loss function인 Hungarian loss 계산을 진행한다. 이 때 loss는 class loss와 box loss로 구성되어있다. class loss는 prediction에 대한 negative log-likelihood를 구하고, box loss는 Preliminaries에서 l1 loss와 generalized IoU loss를 결합하여 사용한다.
는 이전 단계에서 구한 최적의 할당값이다. 실제 학습 시 예측하는 객체가 없는 경우인 에 대하여 log-probability를 1/10로 down-weight한다. 이는 실제로 객체를 예측하지 않는 negative sample의 수가 매우 많아 class imbalance를 위해 해당 sample에 대한 영향을 감소시키기 위해서이다.
DETR Architecture
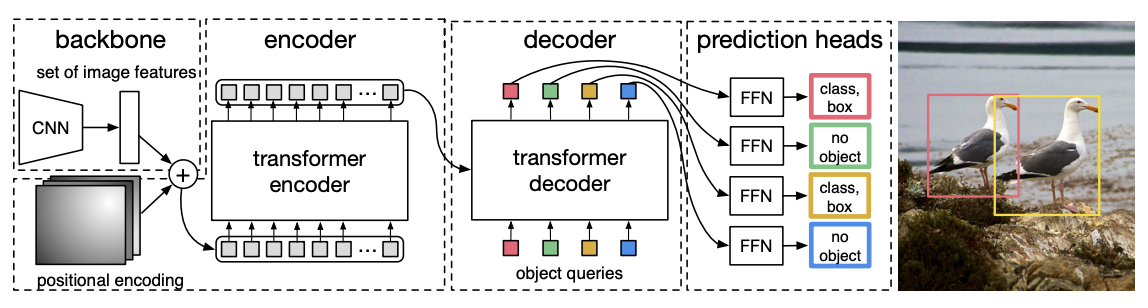
DETR은 CNN backbone , Transformer encoder와 decoder , FFN(Feed Forward Network) 로 구성되어 있다.
CNN backbone
CNN backbone 은 입력 이미지에서 feature map을 추출하는 역할을 한다. 본 논문에서는 ResNet-50을 사용하여 CNN backbone을 구성한다. ResNet-50은 50개의 layer로 이루어진 convolutional neural network로, 이미지에서 feature map을 추출하는 데 효과적이며, 이 feature map은 DETR의 transformer encoder에 입력되어, object queries와 함께 처리된다. 이때, CNN backbone에서 추출된 feature map의 크기는 입력 이미지의 크기와 다르며, 일반적으로 입력 이미지의 크기보다 작은데, 이는 DETR에서 사용되는 transformer encoder의 입력 크기를 줄이는 데 도움이 된다. 결과적으로 DETR의 빠른 속도와 높은 정확도를 보장하는 중요한 요소 중 하나이다.
수식으로 확인해보면, 입력이미지 를 CNN backbone network 에 입력하여, feature map 를 생성한다. 이 때 이다.
Input image를 CNN Backbone을 통과시켜 feature map을 만들어내는 과정은
- input image 크기는
- CNN을 통과하여 출력된 feature map은 (ResNet50을 사용하였기 때문에 )
- 1x1 convolution을 적용하여 형태로 변환 (d 가 C 보다 작다)
- transformer에 들어가기 위해서는 2차원이어야 하므로, 의 3차원에서 의 2차원으로 구조를 바꿔준다.
feature map 을 추출한 후, 1 X 1 convolution 을 통해 C 차원의 feature map을 d 차원으로 감소시켜서 새로운 feature map인 를 만든다. 이 때, transformer encoder는 sequence 를 입력으로 받기 때문에 의
spatial dimension을 flatten 하여 크기를 로 변경해준다.
Transformer Encoder
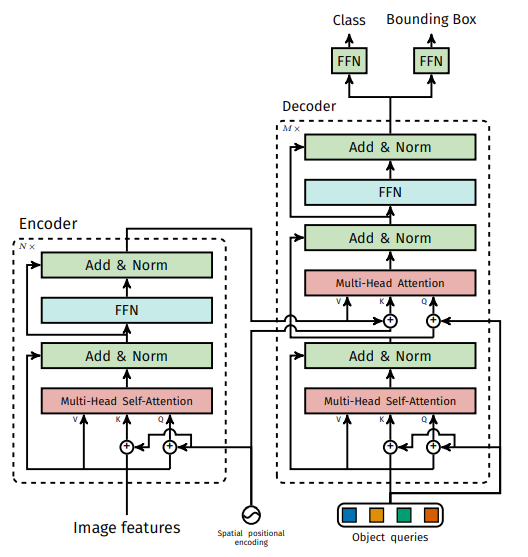
여기서 각 encoder layer 는 multi-head self attention module 과 feed forward network(FFN) 으로 구성되어있으며, transformer 구조는 입력 embedding 의 순서와 상관없이 같은 출력값을 생성하는 속성(permutation-invariant) 이 있기 때문에 encoder layer 로 입력하기 전에 입력 embedding 에 Positional encoding을 더해준다.
Transformer Decoder
Transformer Decoder는 입력 이미지에서 추출된 feature map과 object queries를 이용하여, object detection set을 예측하는 역할을 한다. 이때, Transformer Decoder는 다음과 같은 구성 요소로 이루어져 있다.
여기서, object queries란?
: prediction 하고자하는 모든 object class 를 의미한다.
Object queries는 각 object의 위치와 크기를 나타내는 벡터로, Transformer Decoder에서 object detection set을 예측하는 데 사용된다.
Object queries는 초기에는 0으로 초기화되며, Transformer Decoder의 Multi-Head Self-Attention Layer와 Multi-Head Decoder-Encoder Attention Layer에서 계산된 context vector와 결합하여, object detection set을 예측한다.
이때, Object queries는 Spatial Positional Encoding과 함께 사용되며, 이는 입력 feature map의 위치 정보를 반영하는 역할을 한다.
-
Multi-Head Self-Attention Layer:
입력 feature map과 object queries를 이용하여, 각 object의 context vector를 계산한다. 이때, Multi-Head Self-Attention Layer는 여러 개의 attention head를 사용하여, 입력 feature map과 object queries를 병렬로 처리한다. -
Multi-Head Decoder-Encoder Attention Layer : 입력 feature map과 object queries를 이용하여, 각 object의 context vector를 계산합니다. 이때, Multi-Head Decoder-Encoder Attention Layer는 여러 개의 attention head를 사용하여, 입력 feature map과 object queries를 병렬로 처리한다.
-
Feed-Forward Network: Multi-Head Self-Attention Layer와 Multi-Head Decoder-Encoder Attention Layer에서 계산된 context vector를 이용하여 3개의 linear layer 와 ReLU function으로 구성된 FFN에 입력하여, object detection set을 예측한다.
여기서 object detection set 이란, 이미지에 대한 class label 과 bounding box의 좌표(normalized center coordinate, width, height)를 예측한다.
결과

Number of decoder layer의 decoder를 추가할수록 성능이 향상되었으며, decoder attention map을 시각화한 결과로, fig14와 같이 다소 Local 하게 객체를 포착하고 있다.
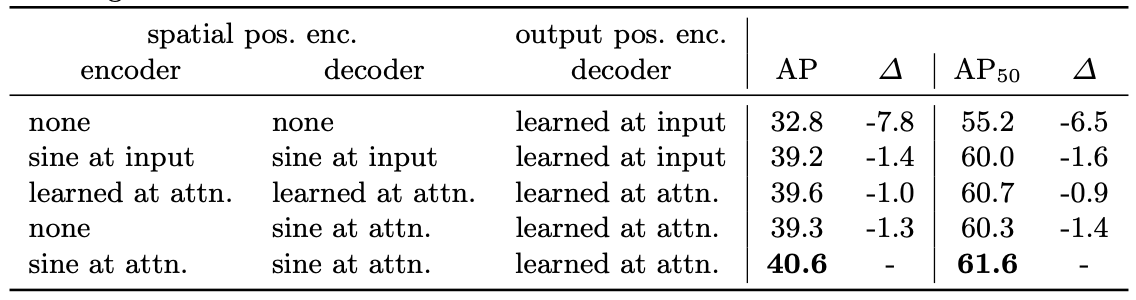
다음 성능 지표를 통해 positional encoding 을 사용함에 있어서 중요성을 파악할 수 있다.
positional encoding 을 사용하지 않고 decoder 에 object queries 만 사용하게되면, 베이스라인에 비해서 AP 값이 7.8% 감소하는 것을 확인할 수 있다. 또한 decoder 에 한번 object query 를 입력한 결과로 모든 attention layer 마다 object query 를 더해주었을 때 보다 AP 값이 약 1.4% 정도 감소하는 것을 확인할 수 있다.
정리
-
DETR은 object detection을 set prediction task로 정의하여 prediction과 ground truth 사이의 일대일 matching을 수행하여, post-processing 과정이 없는 end-to-end 프레임워크를 제안하였다.
-
이 과정에서 encoder-decoder 구조의 Transformer를 활용함으로써 입력 token 사이의 pairwise interaction과 global reasoning을 통해 괜찮은 성능을 보였다.
-
결과적으로 Faster R-CNN과 비슷한 성능을 보이면서도 heuristic(어림짐작하는)한 과정이나 post-processing을 필요하지 않다는 점에서 큰 의의를 가진다.
-
단점 : 여러 크기의 anchor를 사용하지 않기 때문에 다양한 크기, 형태의 객체를 포착하지 못한다.
-
또한 하나의 예측 bounding box를 ground truth에 matching 하기 때문에 converge하는데 훨씬 긴 학습시간이 필요하다.
