
Grad-CAM : Visual Explanation from Deep Networks via Gradient-based Localization
Andrew Ng 교수님이 알려주신 논문 리뷰 방식대로 진행
1. 저자가 뭘 해내고 싶어했는가?
시각적으로 설명 가능한 & 해석 가능 & 정확한 결과물을 만들어 내고 싶었다. 딥러닝 구조의 변화 없이 시각적으로 무엇이 중요한지 설명 가능하며, 이를 class activation mapping + gradient 를 통해 보여주었다.
2. 이 연구의 접근에서 중요한 요소는 무엇인가?
CNN파트에서 이미지를 통과시키고 특정 타겟을 정하는 계산을 통해 카테고리별 row score를 얻고, 이를 통하여 gradient를 사용한 역전파 파트에서 특정 피처맵의 가중치 값을 수정하고, 이를 통하여 Grad-CAM 을 얻는다.
최종적으로 guided backpropagation 과 Grad-CAM을 합쳐 Guided Grad-CAM을 얻는다( 높은 resolution과 특정 개념적인 내용을 담고 있다)
3. 당신(논문독자)은 스스로 이 논문을 이용할 수 있는가?
이제는 가능하다!
4. 당신이 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
Grad CAM++ 에 차후 논문 리뷰를 추가적으로 진행할 예정이다.
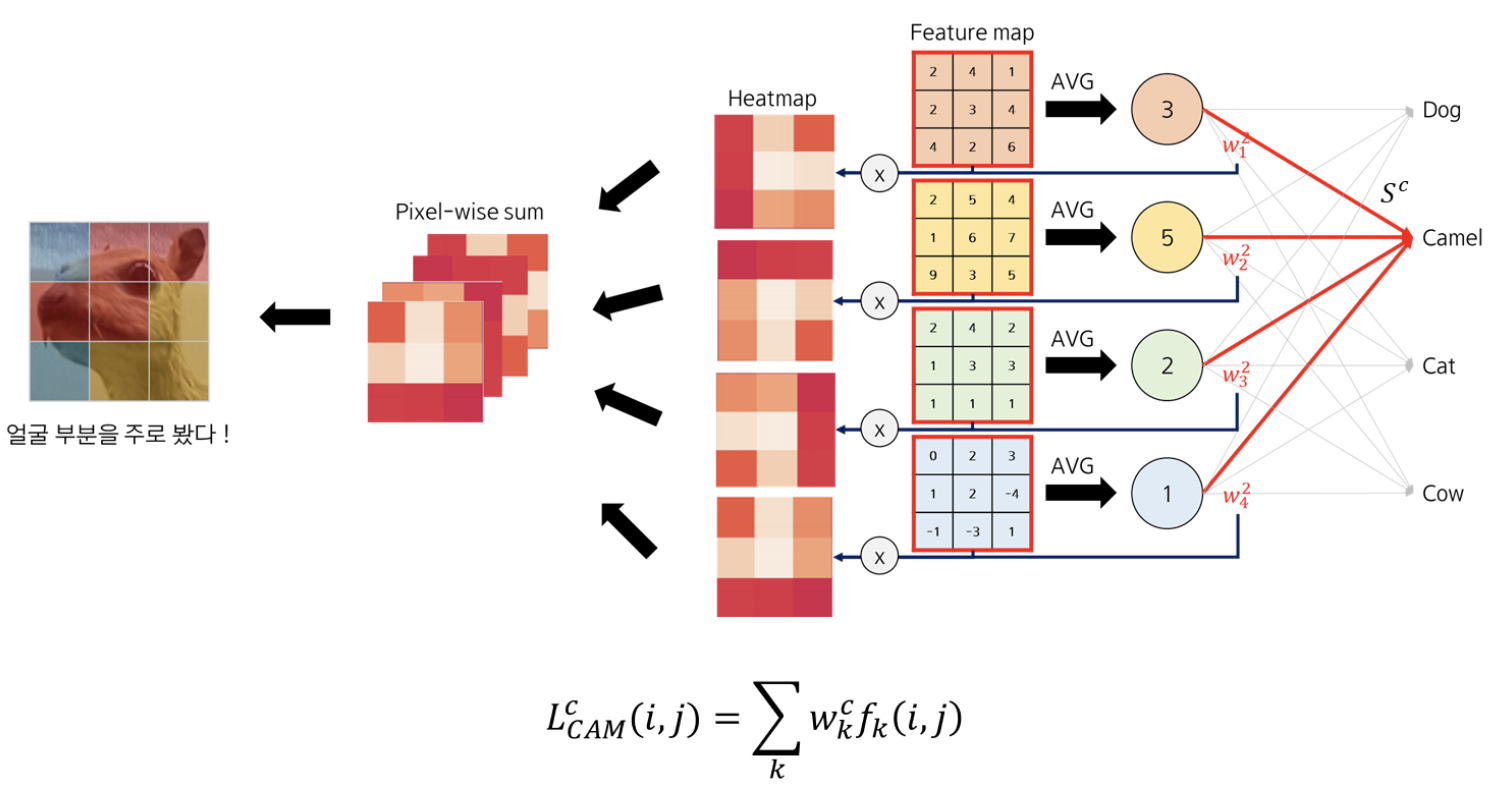
CAM에 대하여
CNN의 구조에서 Input → Conv Layers → FC layers 과정 중 FC-layer층 에서 flatten 시키면 위치 정보를 잃어버리게 된다. 따라서 Classification의 정확도가 높아도, CNN이 무엇을 보고 특정 class로 분류한 것인지 모르게 된다.
따라서, 이 FC layer 대신에 Global Average Pooling을 적용하여 특정 클래스 이미지의 Heat map을 생성하여 CNN이 어떻게 이미지를 특정 클래스로 예측했는지 알 수 있다.
Grobal Max Pooling 이란?

Global Average Pooling을 통해 각각의 feature map 마다 그 맵에 포함된 모든 원소 값의 평균합을 진행한다. 결과적으로 그 층으로 들어오는 feature map의 channel 수와 동일한 길이의 벡터를 얻게 된다.
GAP 층을 지나고 FC layer을 붙여서 fine-tuning 을 진행한다.
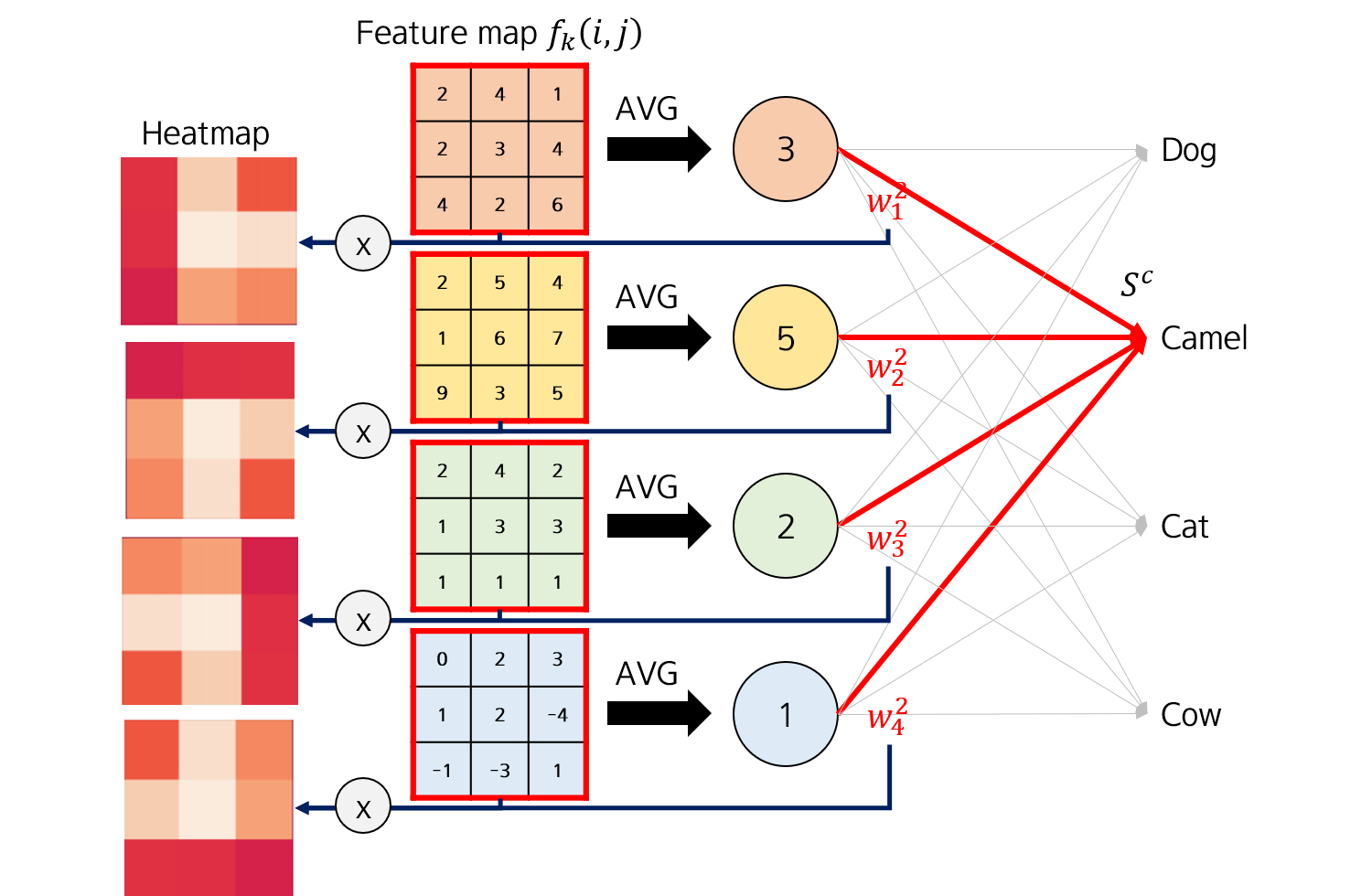
feature map f_k 에 대한 가중치 w_k를 곱해주면 heatmap을 feature map 갯수 만큼 뽑을 수 있다.
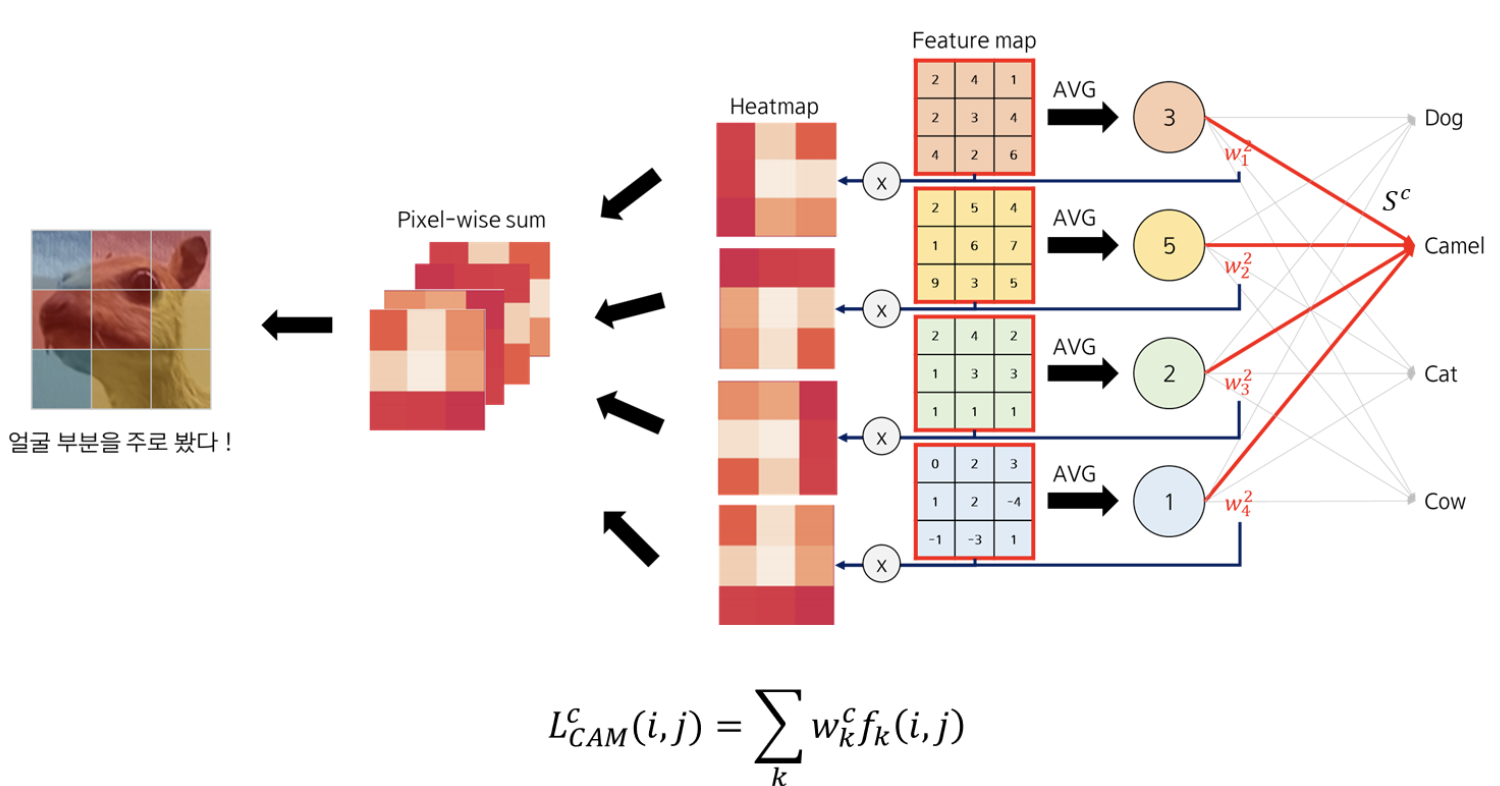
이 heatmap 이미지를 Pixel-wise sum을 진행하면 하나의 CAM heatmap을 얻을 수 있다.
그렇다면 CAM이 잘 작동하는 이유는 무엇일까?
마지막 convolution layer를 통과한 feature map은 input image의 전체 내용을 함축하고 있기 때문이다 !
마지막 feature map 이 아닌 중간에 위치한 feature map에서는 CAM을 통해 heatmap을 추출할 수 없다는 순서의 중요성에서 문제가 발생한다.
CAM 의 단점 : Global average pooling layer 를 만드시 사용하고, 뒤에는 FC layer 가 붙어있어야한다는 점
FC layer의 weight 를 구하기 위해 학습을 시켜야한다.
마지막 convolution layer를 통과해 나온 feature map 에 대해서만 CAM을 통하여 Heat map 추출이 가능하다.
CAM의 문제점
소프트맥스 층을 가기 전에 피처맵을 바로 얻는 것을 필요로 한다는 것. 그래서 특정 CNN 구조에만 적용 가능한데, 이 CNN 구조는 합성곱 맵을 넘고 바로 global average-pooling을 하는 방식을 지닌다.
(순서 : conv feature maps → global average pooling → softmax layer)
이 CNN 구조의 문제점은 클래스 분류에 있어서 낮은 정확도를 가진다는 것 & image captioning VQA와 같은 다른 일에 적용 불가능하다는 것
그래서 적용한 것이 피처 맵을 gradient signal과 합친 것인데, CNN 구조를 바꿀 필요 없이 합치기만 하면 된다.
Grad- CAM의 등장
CAM의 단점을 보완하기 위하여 나온 Grad-CAM은, 기존 CNN 모델의 구조 변화가 없으며, Global Average Pooling 없이 FC layer가 두개 존재한다.
각 feature map에 곱해줄 weight를 학습을 통해서가 아닌 미분(gradient)을 통해 구하기 때문에 기존 CNN의 학습이 필요 없게 된다.
여기서 gradient 는, class C 에 대해 input 값이 주는 영향력이라고 할 수 있다.
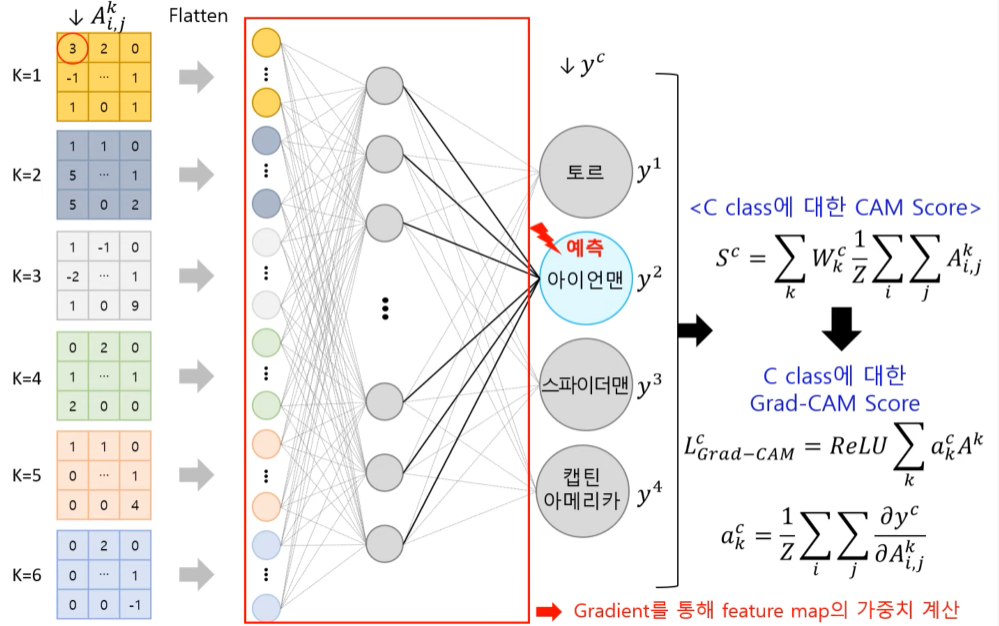
다음 이미지는 한땀한땀 딥러닝 컴퓨터 백과사전에서 이해하기 쉬운 구조도 하나를 가져왔다.
k=6개의 feature map을 이용해 y=2, 아이언맨으로 분류한다면, class C 에 대한 점수 y_c을 softmax로 거쳐지기 전에 각 원소로 미분한다. 이 미분값은 feature map의 원소가 특정 class에 주는 영향력이 된다.
각 feature map 에 포함된 모든 원소의 미분값을 더하여 뉴런 중요 가중치값 a를 구하면, 이 a는 해당 feature map 이 특정 class 에 주는 영향력이 된다.
![]()
a_k는 k 번째 feature map 의 f_k의 원소 i,j 가 ouput class 값 C의 S^c에 주는 영향력 이다.
CAM 에서 weight 로 주었던 가중치를 feature map의 gradient 로 주었다고 생각하면 된다.
neuron importance weight, a와 각 K 개의 feature map을 곱해 weight sum of feature map을 구한다. → ReLU를 취해 최종 Grad-CAM에 의한 Heatmap을 출력한다.
(ReLU를 사용해야 관심 있는 class 에 positive한 영향을 주는 feature 에만 집중하기 때문이다. y_c를 증가시키기 위해 증가되어야할 intensity를 가지는 pixel을 말한다. )
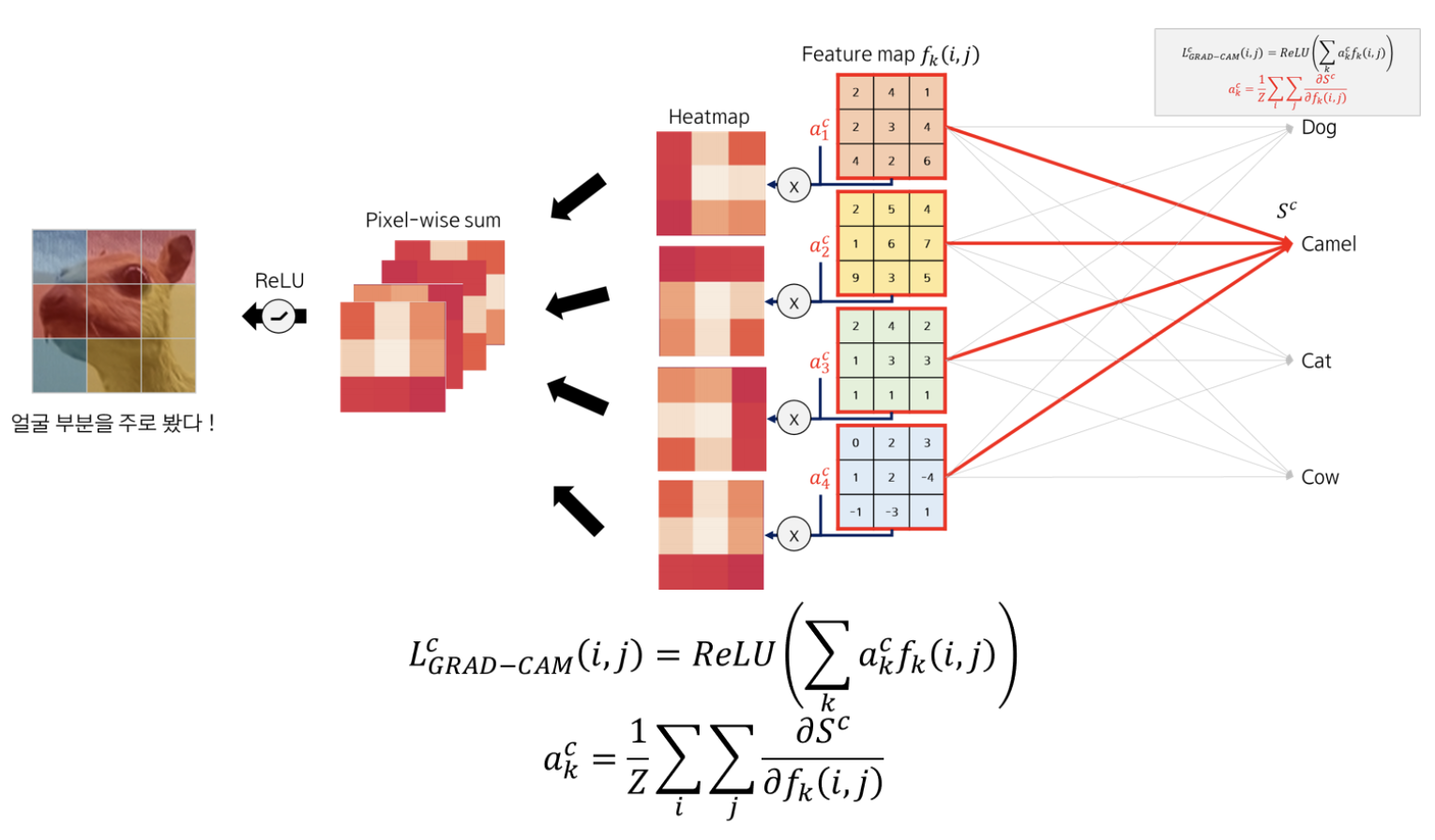
pixel-wise sum을 한 후, ReLU 함수를 적용해 양의 가중치를 갖는 (중요하게 여기는) 부분을 골라내면 Grad-CAM이 된다.
Guided backpropagation 이란?
specific 한 곳은 visualization 해주는 것.
![]()
Guided backpropagation은 gradient가 0보다 크면서, relu의 output이 양수인 부분만 backward로 넘겨준다. Guided backpropagation을 보게 되면 gradient가 현재 -2, 3, -1, 6, -3, 1, 2, -1, 3이다.
여기서 먼저 0보다 큰 부분을 남기면 0, 3, 0, 6, 0, 1, 2, 0, 3이 될 것이고, ReLU의 output이 양수인 부분만 다시 한번 걸러서 남겨주게 되면 0, 0, 0, 6, 0, 0, 0, 0, 3이 된다.
따라서 local 한 특성을 보여주는 Grad-CAM 과 specific한 특성을 보여주는 Guided backpropagation을 pixel-wise multiplication 해주면, Local하고 specific한 특성을 모두 갖게되는 Guided grad-CAM이 된다는 것 !
reference :
