파이썬에서 오라클 데이터베이스에 있는 데이터를 불러와서 작업하고 그 결과를 다시 오라클에 저장해야하는 임무가 생겼다. 이걸 수행하기 위해서 사용했던 cx_Oracle의 내용을 정리해보고자 한다. 오라클 같은 경우에 INSERT를 해야 할 때 다른 모듈을 추가로 사용해야한다는 이야기도 보았는데, 해 본 결과 cx_Oracle만으로도 동작이 잘 되었다.
cx_Oracle
cx_Oracle은 파이썬이 오라클 데이터베이스에 엑세스 할 수 있도록 만드는 파이썬 확장 모듈이다.
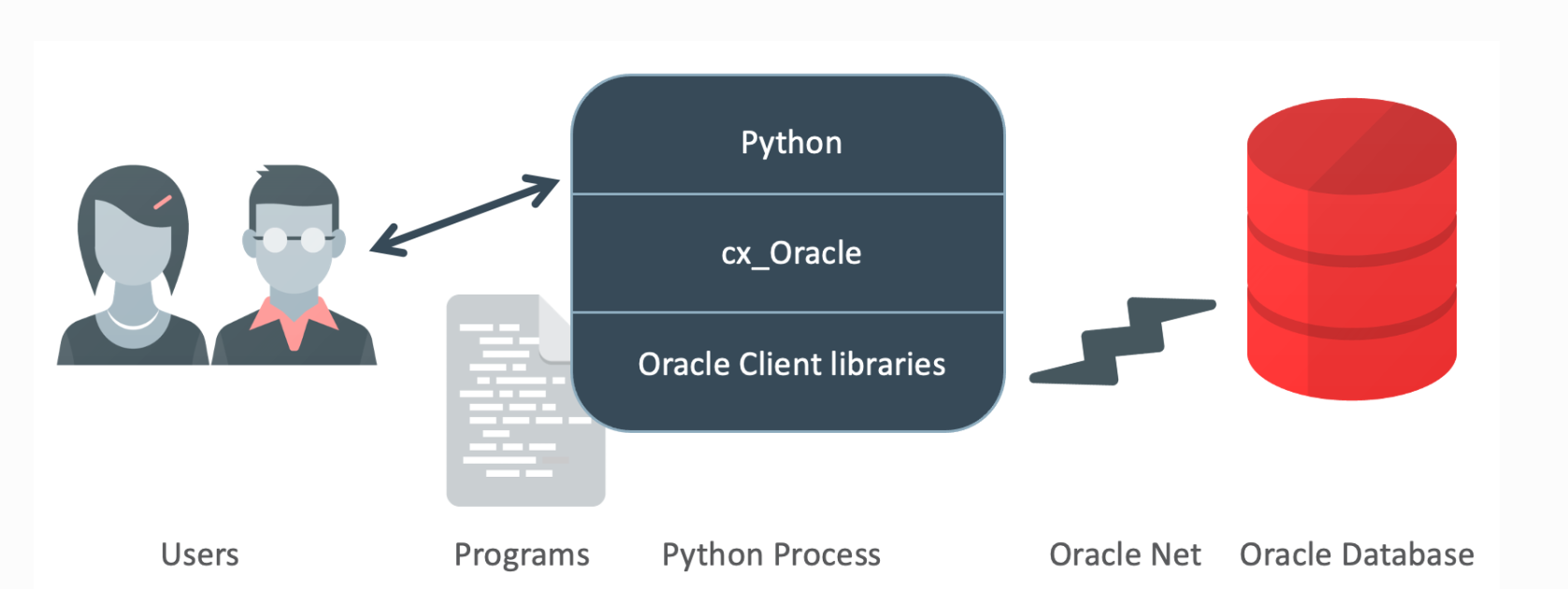
cx_Oracle 아키텍쳐, 출처 : https://cx-oracle.readthedocs.io/en/latest/user_guide/introduction.html
pip를 이용하여 설치를 할 수 있으며, 오라클 인스턴트 클라이언트가 설치가 되어 있어야 한다. 만약 설치가 되어 있지 않다면 https://www.oracle.com/database/technologies/instant-client.html 에서 설치할 수 있다.
사용하기
연결 및 데이터 가져오기
import cx_Oracle as oci
user = "유저아이디"
pw = "유저 비밀번호 "
dsn = "data source name"
# 연결
con = oci.connect(user=user, password=pw, dsn=dsn)
# 커서
cur = con.cursor()사용하는 방법은 굉장히 간단하다. 모듈을 임포트하고 데이터베이스의 유저 아이디, 비밀번호, 데이터 소스 이름을 인자로 주고 connect한다.
그리고 명령문을 실행하거나 결과를 가져올 수 있는 커서도 만들어준다.
import pandas as pd
query = 'select * from database'
df = pd.read_sql_query(query,con)데이터를 읽어오는 방법도 굉장히 간단한데, 판다스의 read_sql_query를 이용해서 csv를 이용할 때와 같이 바로 데이터프레임으로 읽어올 수 있었다. con 같은 경우, 위에서 연결했던 데이터베이스 커넥션을 의미한다.
데이터를 데이터베이스에 INSERT
데이터베이스에 다시 데이터를 넣기 위해서 사용되는 execute 함수가 있다. 하지만 이 경우 하나하나씩 진행이 되기 때문에 executemany를 사용해서 오버헤드를 줄이고 훨씬 더 간편하게 진행할 수 있다. 단, 이 경우에 데이터프레임을 그대로 넣을 수는 없어서 다른 객체로 변환이 필요한데,

# 데이터프레임 변경
df_list = df.to_records(index=False)
# INSERT문 실행
cur.executemany("INSERT INTO database (ID, R, F, M, GROUP, DATE) VALUES (:1,:2,:3,:4,:5,:6)",
df_list, batcherrors = True)공식 문서에서는 이런 식으로 진행을 했기 때문에 리스트 안에 튜플로 값이 들어있는 형태로 따라하려고 했다.
또다시 판다스의 to_record를 이용해서 예시와 같은 형태로 만들었고, executemany를 실행했으나

NotSupportedError: Python value of type numpy.int32 not supported.
NotSupportedError: Python value of type numpy.int64 not supported.
이런 오류들이 발생했다...
to_records를 사용하니 넘파이 어레이 형태로 변환이 되어서 숫자가 int형태가 아니라 numpy.int 형태로 들어가게 되는 문제가 발생한 것 같았다. 다른 datetime이나 문자의 경우에는 발생하지 않지만 값이 숫자 형식인 경우에 발생하는 문제였는데, 다음과 같은 두 가지 방법으로 해결했다.
방법1
for 문과 execute를 이용해서 각각 하나씩 형변환을 진행하기
def row_to_list(row):
'''
데이터프레임 한 행을 받아서 형 변환 후 list로 리턴
'''
return [row['ID'].item(),row['R'].item(),row['F'].item(),row['M'].item(),row['GROUP'],row['DATE']]
for i in range(len(df)):
cur.execute("INSERT INTO database (ID, R, F, M, GROUP, DATE) VALUES (:1,:2,:3,:4,:5,:6)",row_to_list(df.loc[i]))각각 한 행씩을 정확한 형태로 들어갈 수 있도록 변환을 해서 넣어준다. 이렇게 하는 경우 한 행씩 들어가기 때문에 executemany를 사용하지는 못하고 for문으로 한 행씩 처리할 수 있도록 처리한다.
방법2
데이터프레임을 그냥 2차원 리스트로 만들어서 진행하기
df_list = df.values.tolist()
cur.executemany("INSERT INTO database (ID, R, F, M, GROUP, DATE) VALUES (:1,:2,:3,:4,:5,:6)",
df_list, batcherrors = True)방법 1로 해도 되긴하지만 데이터가 많은 경우 오래 걸리기도하고 한줄한줄 처리한다는게 마음에 굉장히 걸렸다. 그래서 executemany를 정녕 사용하지 못하는걸까? 싶어서 도전해 본 방법이다. 처음에 to_record로 하면 numpy array로 변환이 되는게 문제였다. 게다가 그 안에는 튜플이라 수정도 되지 않았는데..생각해보니 그냥 단순하게 2차원 리스트로 만들어도 되지 않을까?!해서 시도해봤다. 튜플 형태로 넣는 건지 이해는 가지만..굳이 튜플을 고수할 필요는 없겠다는 생각이 들어서 시도해보았다.
데이터프레임의 값들을 to_list를 이용해서 2차원 리스트로 만들어서 executemany로 했더니 한번에 깔끔하게 들어갔다.
상-쾌-
참고로, batcherrors가 True 면 몇가지 행에서 오류가 나더라도 계속 진행은 되지만 autocommit 설정이 되어 있을 때에는 커밋이 실행되지 않기 때문에 따로 커밋을 해줘야 한다!
커밋 및 확인
# 커밋
cur.execute("commit")
# 들어간 갯수 확인
cur.execute('select count(*) from database where 조건')
cur.fetchone()커밋은 cur.execute를 이용해서 커밋을 진행해주면 된다.
이후 데이터베이스에 잘 반영이 되었는지 확인하려면 저렇게 들어간 갯수를 확인해도 되고, 오라클 디벨로퍼에서 확인을 할 수도 있다.
나는 이미 만들어 둔 빈 테이블이 있어서 그 테이블에 INSERT되도록 진행했지만, cur.execute를 이용해서 create table 문을 실행할 수도 있다.
INSERT가 안되었을 때 무지하게 당황했지만.. 잘 해결해서 다행이다...새로운걸 해내니 뿌듯

매우 도움이 되는 내용이네요!!