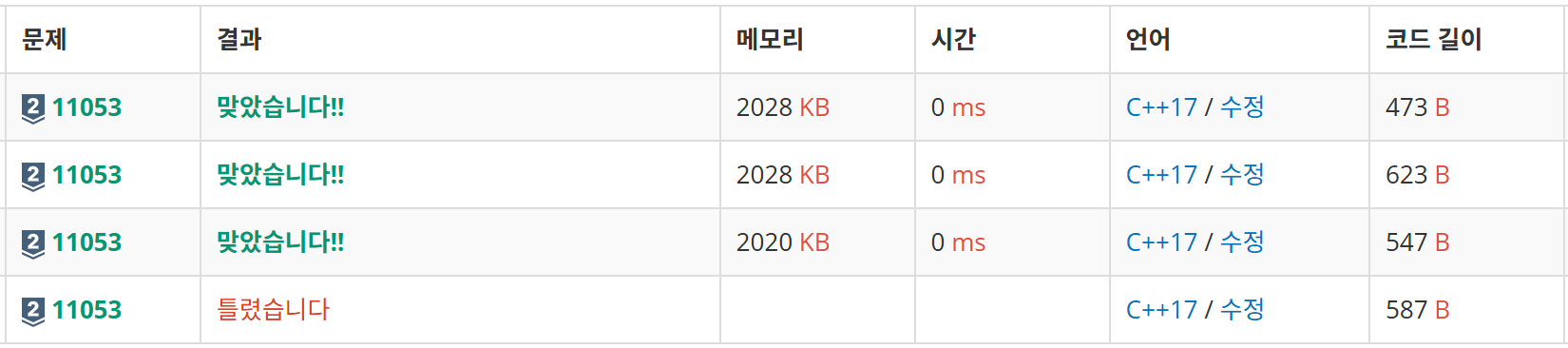
🌽 문제

🥕 입출력
🥔 풀이(Dynamic Programming)
LIS(Longest Increasing Subsequence)는 DP와 이진 탐색으로 풀 수 있다.
dp[i]는 arr[i]로 끝나는 LIS의 길이를 뜻한다.
자기 자신만이 LIS가 될 수도 있으므로, 초기값을 1로 설정한다.
이 때 i번째 원소를 포함하는 증가 부분 수열의 최대 길이(dp[i])는,
그 앞에 있는 작은 수들 중에서 가장 긴 증가 부분 수열 길이에
(arr[i] 원소를 LIS에 포함시킨,) 1을 더한 값이다.
따라서 for문에서 i는 0부터 N까지, j는 0부터 i까지로 두고,
arr[j]가 arr[i]보다 작은 경우 dp[i]를 아래와 같이 갱신한다.
dp[i] = max(dp[i], dp[j] + 1)
🥬 코드(Dynamic Programming)
#include <iostream>
#include <algorithm>
using namespace std;
int arr[1001];
int dp[1001];
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
int n;
cin >> n;
for (int i = 0; i < n; i++)
cin >> arr[i];
for (int i = 0; i < n; i++)
dp[i] = 1;
for (int i = 1; i < n; i++)
for (int j = 0; j < i; j++)
if (arr[i] > arr[j])
dp[i] = max(dp[i], dp[j] + 1);
int maxi = 0;
for (int i = 0; i < n; i++)
maxi = max(maxi, dp[i]);
cout << maxi;
return 0;
}🥔 풀이(Binary Search)
이진 탐색 풀이는, LIS 배열을 만들어가며 그 길이를 구하는 방식이다.
즉 lis 배열은 lis 자체를 저장하는 게 아니라, 길이를 유지하기 위한 배열이다.
lower_bound(first, last, value)는 정렬된 배열에서 value 이상의 값이 처음 등장하는 위치를 반환한다.
이 함수를 갖다가 lis에서 x 이상이 처음 나오는 위치를 찾는다.
it는 lis 벡터에서 x가 들어갈 인덱스를 가리키게 된다.
이 때 it == lis.end()면, x가 lis 배열 중 가장 큰 값이라는 뜻이다.
그러면 lis 배열의 끝에 x를 추가한다.
즉, 현재 x를 증가하는 부분 수열에 포함시킨다.
반대로 it != lis.end()면, lis 배열 내에 x보다 크거나 같은 값이 있는 위치를 찾았다는 말이다.
이 때는 *it = x를 수행하여 기존 원소를 x로 교체한다.
lis의 길이에는 영향이 없지만,
원소를 더 작은 값으로 교체하여 더 좋은 lis를 만들 수 있다.
예를 들어 입력이 10 50 20 30 일 때 코드는 아래와 같은 방식으로 돌아간다.
lis = [10] // 10 추가
lis = [10, 50] // 50 추가
lis = [10, 20] // 50을 20으로 대체 (더 작은 값으로 갱신)
lis = [10, 20, 30] // 30 추가따라서 lis의 길이인 3이 답이 된다.
🥬 코드(Binary Search)
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
int n;
cin >> n;
vector<int> lis;
for (int i = 0; i < n; i++) {
int x;
cin >> x;
auto it = lower_bound(lis.begin(), lis.end(), x);
if (it == lis.end()) lis.push_back(x);
else *it = x;
}
cout << lis.size() << '\n';
return 0;
}🥜 채점
이진 탐색이 O(N log N)으로 O(N^2)인 DP보다 쬐끔 더 빠르다!