
이번 게시글에선 PintOS 첫 번째 프로젝트인 Thread의 extra 과제 MLFQS에 대해서 알아보자
📌 Multilevel Feedback Queue Scheduler(MLFQS)
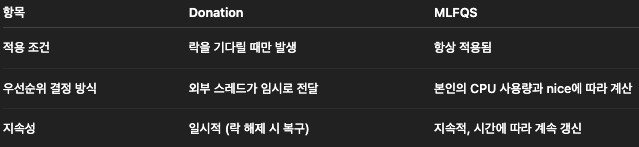
간단하게 말하면 MLFQS는 “우선순위 기반” + “CPU 사용량 반영” + “nice 값” 기반의 스케줄링.
→ 단순 priority만 보는 게 아니라, 최근 CPU 점유 시간 + nice값을 고려해서
→ 자동으로 우선순위를 점진적으로 조정한다.
기존 Priority와 다른 점
기존에 구현했던 Priority Scheduler는 Priority가 정적이였지만,
MLFQS는 Priority가 동적으로 변하는 매커니즘이다.
그렇기 때문에 ?
- Donation 기능은 사용하지 않는다(비활성)
- 사용하지 않더라도, All Pass를 받기 위해서는 분기 작업으로 Donation 부분을 살려는 놓아야 한다
- Why? : Donation을 사용하는 Test Case도 있기 때문임 (당연한 얘기)
Priority Donation은 락을 기다리는 상황에서 일시적으로 priority를 올려주는 메커니즘이다.
반면, MLFQS는 스레드 자체의 특성과 행동(사용량, 양보 정도)을 기반으로
내부적으로 동적으로 우선순위를 조정하는 방식이다.
-
MLFQS는 기본적으로 Donation을 끄고 동작하며,
-
관련 테스트 통과를 위해 Donation 로직은 남겨두되,
-
if (!thread_mlfqs) 와 같은 조건문으로 Donation을 우회하도록 설계해야 한다.
MLFQS가 사용하는 3가지 핵심 변수를 알아보자
nice : 유저가 수동 조정 가능한 CPU 사용 의지 (높을수록 우선순위 낮아짐)
- 타입 : 정수
nice는 일종의 젠틀함? 이라고 생각하면 좋다.nice이 높을수록, 젠틀하기 떄문에 양보를 더 많이한다.
recent_cpu : 해당 스레드가 최근 얼마나 CPU를 사용했는지 저장하는 값
- 타입 : 실수 (fixed-point로 구현)
load_avg : 시스템 전체의 평균 ready 스레드 수
- 타입 : 실수 (
recent_cpu와 동일하게 fixed-point로 구현)
계산 공식
MLFQS는 아까 말했듯 동적으로 Priority값이 변하기 때문에 계산을 해줘야 한다. 이 계산에는 공식이 있다.
Priority 공식
priority = PRI_MAX - (recent_cpu / 4) - (nice * 2)recent_cpu 공식
recent_cpu = (2 * load_avg) / (2 * load_avg + 1) * recent_cpu + niceload_avg 공식
load_avg = (59/60) * load_avg + (1/60) * ready_threads여기서 정수는 priority , nice , ready_threads 이다
recent_cpu 와 load_avg 는 둘 다 실수이기 때문에 계산을 하기 위해서 fixed-point.h를 만들어서 진행했다
위의 문서를 보면 fixed-point 구현에 도움이 되는 표가 나오니 참고하자. (참고 : 다 영어임)
그거 말고도 유용한 정보가 있으니 한번씩 확인 읽어보길 바란다
이 공식이 언제 실행이 되는가 ?
- 시점 :
- 매 tick 마다 : recent_cpu 증가
- 매 4tick 마다 : priority 재계산
- 매 100tick(1초) 마다 : load_avg값 재계산
nice값과 recent_cpu값을 이용해 현재 스레드의 priority를 재조정 해준다.
이러한 계산이 필요한 이유는 공정한 CPU 사용 기회를 보장하기 위함이다.
MLFQS는 우선순위를 단순히 고정된 값으로만 비교하지 않고,
각 스레드가 얼마나 CPU를 점유해왔는지(recent_cpu),
얼마나 양보하려는 의지를 보이는지(nice)를 함께 고려한다.
-
CPU를 많이 사용한 스레드는 priority가 점점 낮아진다.
→ CPU 점유를 줄이고 다른 스레드에게 기회를 넘기기 위해. -
nice 값이 높은 스레드는 priority가 더 낮아진다.
→ 실행을 양보하고 싶은 “젠틀한” 태도를 반영한 것.
결국 MLFQS는 "점유가 많을수록 우선권은 낮아지고",
"양보할수록 덜 점유한다"는 원칙 아래에서
스레드 간에 더욱 균형 잡힌 CPU 분배를 실현한다.
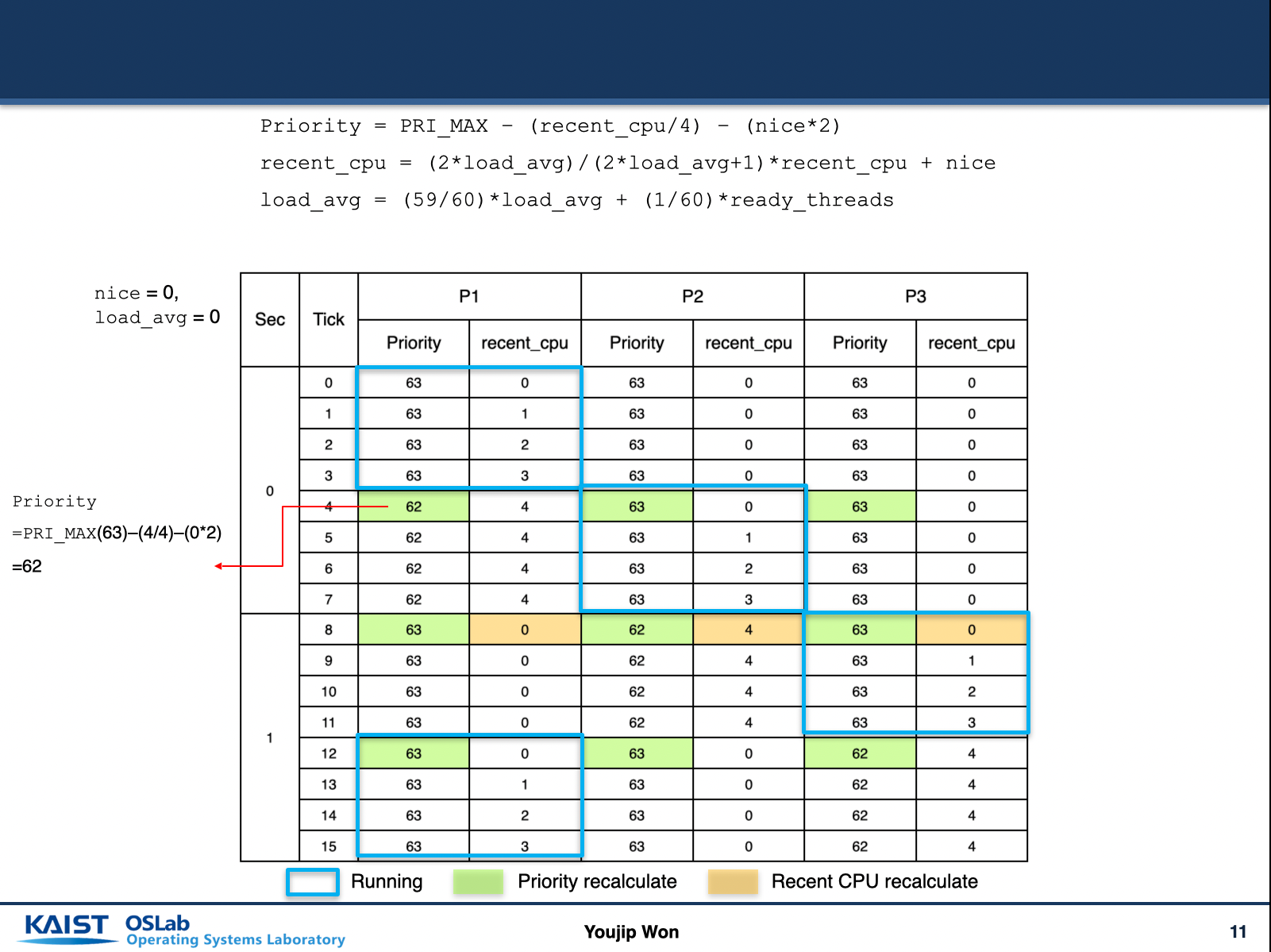
위 표를 보면 실행중인 스레드/프로세스 의 Priority 값과 recent_cpu 값이 바뀌는 것을 확인 할 수 있었다.
MLFQS 관련 함수는 어디서 호출되나?
MLFQS의 핵심 로직은 모두 mlfqs_on_tick() 내부에서 호출된다.
이 함수는 thread_tick()에서 호출되며, 결국 timer interrupt가 트리거가 된다.
예시 흐름:
timer_interrupt() → thread_tick() → mlfqs_on_tick()-
이로 인해, MLFQS는 CPU의 하드웨어 시계(tick)에 따라
-
자동으로 우선순위와 recent_cpu 값을 계산하고 갱신한다.
Fixed-point가 필요한 이유 간단 요약
recent_cpu, load_avg는 실수(floating-point) 계산을 요구하지만,
PintOS 커널은 성능 및 안전성 이유로 부동소수점 연산을 지원하지 않는다.
따라서 우리는 fixed-point.h를 만들어 정수로 실수 계산을 흉내낸다.
(예: x / 4 → (x * F) / (4 * F) 처럼 연산)
이번 포스트에서는 MLFQS의 핵심 개념과 계산 흐름에 대해 정리해보았다.
다음 포스트에서는 실제 PintOS 내부 코드가
어떻게 이 수식들을 반영해 우선순위를 동적으로 조정하는지 구체적으로 살펴보자.
