
이번 포스트에서는 코드를 조금씩 구현해보자.
이전 Priority Scheduler 구현 시, 팀원들과 역할을 분담하여 진행했던 것 처럼 이번 작업도 팀원들과 분배를 하였다.
구현 전 다시 한번 흐름을 잡고 시작해보자
전체적인 흐름
-
필드 및 초기 구조 설계
thread구조체에nice와recent_cpu필드를 추가해주기 !load_avg전역 변수 선언해주기 !/include/threads/fixed-point.h구현 및 활용 해주기 !
- 추가가 필요한 함수 시그니처 정의 👇
// 시스템 평균 부하(load_avg)를 매 1초마다 갱신
static void update_load_avg(void);
// 해당 스레드의 recent_cpu 값을 갱신
static void update_recent_cpu(struct thread *t);
// 모든 스레드의 recent_cpu 값을 갱신 (1초마다 호출)
static void update_all_recent_cpu(void);
// 해당 스레드의 priority 값을 recent_cpu 및 nice 값 기반으로 갱신
static void update_priority(struct thread *t);
// 모든 스레드의 priority 값을 갱신 (4tick마다 호출)
static void update_all_priority(void);
// timer tick마다 호출되어 MLFQS 관련 주기적 업데이트 수행
void mlfqs_on_tick(void);- 수정이 필요한 함수들 👇
/* 👇 내부 구현이 필요한 함수들(비어있는 상태) 👇 */
int thread_get_nice(void);
void thread_set_nice(int);
int thread_get_recent_cpu(void);
int thread_get_load_avg(void);
/* 👆 내부 구현이 필요한 함수들(비어있는 상태) 👆 */
/* 👇 내부 수정이 필요한 함수들 👇 */
// nice, recent_cpu 초기화 추가 필요
static void init_thread(struct thread *, const char *name, int priority);
// mlfqs_on_tick() 호출 추가 고려
void thread_tick(void);
// 초기 recent_cpu, nice 설정 필요
tid_t thread_create(const char *name, int priority,
thread_func *function, void *aux);
/* 👆 내부 수정이 필요한 함수들 👆 */
함수 흐름 👇
[타이머 인터럽트 발생]
│
▼
timer_interrupt()
│
▼
thread_tick()
│
▼
mlfqs_on_tick()
├─ recent_cpu += 1 // 매 tick
├─ update_load_avg() // 매 100 tick
├─ update_all_recent_cpu()
└─ update_all_priority() // 매 4 tick
└─ list_sort(ready_list)
출처 : 그냥코딩
mlfqs_on_tick()
→ MLFQS 전체 로직의 중심
void mlfqs_on_tick(void)
{
// 매 tick마다 실행
if (thread_current() != idle_thread) {
thread_current()->recent_cpu = add_fixed(thread_current()->recent_cpu, int_to_fixed(1));
}
// 1초(100tick)마다 실행
if (timer_ticks() % TIMER_FREQ == 0) {
update_load_avg();
update_all_recent_cpu();
}
// 매 4tick마다 실행
if (timer_ticks() % TIME_SLICE == 0) {
update_all_priority();
list_sort(&ready_list, cmp_priority, NULL);
}
}-
tick마다 실행되는 스케줄러의 하위 루틴
-
thread_current()가 idle이 아니면recent_cpu1 증가 -
100tick(1초)마다 시스템 전체 값을 갱신
-
4tick마다 priority 재계산 + ready_list 우선순위 정렬
-
TIMER_FREQ== 100 -
TIME_SLICE== 4
update_load_avg()
load_avg = (59/60) * load_avg + (1/60) * ready_threads;void update_load_avg(void) {
int ready_threads = list_size(&ready_list);
if (thread_current() != idle_thread)
ready_threads++;
fixed_t coeff_59_60 = div_fixed(int_to_fixed(59), int_to_fixed(60));
fixed_t coeff_1_60 = div_fixed(int_to_fixed(1), int_to_fixed(60));
LOAD_AVG = add_fixed(
mul_fixed(coeff_59_60, LOAD_AVG),
fixed_mul_int(coeff_1_60, ready_threads));
}-
ready_threads는 현재 ready_list의 길이 + 실행 중인 스레드 -
fixed-point연산으로 실수 계산 흉내
update_recent_cpu(struct thread *t)
recent_cpu = (2*load_avg)/(2*load_avg + 1) * recent_cpu + nice;void update_recent_cpu(struct thread *t) {
if (t == idle_thread) return;
fixed_t coeff = div_fixed(
fixed_mul_int(LOAD_AVG, 2),
add_fixed(fixed_mul_int(LOAD_AVG, 2), int_to_fixed(1)));
t->recent_cpu = add_fixed(
mul_fixed(coeff, t->recent_cpu),
int_to_fixed(t->nice));
}-
현재 스레드가 얼마나 CPU를 점유했는지를 기록
-
idle_thread는 갱신 대상에서 제외
→ 이 함수는 update_all_recent_cpu() 에서 thread_foreach()로 전 스레드에 적용
update_priority()
priority = PRI_MAX - (recent_cpu / 4) - (nice * 2);void update_priority(struct thread *t) {
if (t == idle_thread) return;
int priority = PRI_MAX
- fixed_to_int_round(fixed_div_int(t->recent_cpu, 4))
- t->nice * 2;
if (priority < PRI_MIN) priority = PRI_MIN;
if (priority > PRI_MAX) priority = PRI_MAX;
t->priority = priority;
}-
recent_cpu가 클수록 우선순위 낮아짐 -
nice가 클수록 (더 양보적일수록) 우선순위 낮아짐
→ 이 함수도 update_all_priority()를 통해 모든 스레드에 일괄 적용
thread_foreach()
MLFQS에서는 recent_cpu, priority를 갱신할 때 모든 스레드를 순회해야 한다.
이를 위해 PintOS는 내부적으로 다음과 같은 보조 함수인 thread_foreach()를 제공한다:
void thread_foreach(void (*func)(struct thread *t, void *aux), void *aux) {
for (e in all_list)
func(t, aux); // 각 스레드에 대해 func 호출
}- 즉, "모든 스레드에게 어떤 함수를 적용한다" 는 작업은 대부분 thread_foreach() 기반으로 이루어진다.
update_all_recent_cpu()
static void update_all_recent_cpu(void) {
thread_foreach(update_recent_cpu, NULL);
}- 내부적으로 각 스레드에 대해 update_recent_cpu()를 호출해주는 wrapper 함수
update_all_priority()
static void update_all_priority(void) {
thread_foreach(update_priority, NULL);
}- 역시 thread_foreach()를 통해 전체 스레드의 우선순위를 재계산
MLFQS 인터페이스 함수들
MLFQS에서는 사용자(또는 테스트 케이스)가 시스템 상태를 확인하거나
nice 값을 직접 조정하기 위해 몇 가지 인터페이스 함수가 제공된다:
thread_set_nice(int nice)
void thread_set_nice(int nice) {
struct thread *curr = thread_current();
curr->nice = nice;
update_priority(curr); // nice 값 변경 반영
preempt_priority(); // 우선순위 역전 시 yield 유도
}-
현재 스레드의 nice 값을 변경하고, 해당 변경을 기반으로 priority를 재계산한다.
-
만약 더 높은 우선순위 스레드가 ready_list에 있다면 현재 스레드는 CPU를 양보하게 된다.
thread_get_nice(void)
int thread_get_nice(void) {
return thread_current()->nice;
}-
현재 스레드의 nice 값을 반환한다.
-
nice 값은 우선순위 계산식에 직접 사용된다.
thread_get_load_avg(void)
int thread_get_load_avg(void) {
return fixed_to_int_round(fixed_mul_int(LOAD_AVG, 100));
}-
시스템의 평균 load 값(load_avg)을 100배 스케일로 반환한다.
-
예: load_avg == 0.85 → 85 반환
thread_get_recent_cpu(void)
int thread_get_recent_cpu(void) {
return fixed_to_int_round(fixed_mul_int(thread_current()->recent_cpu, 100));
}- 현재 스레드가 최근 얼마나 CPU를 사용했는지를 나타낸 recent_cpu를 100배 스케일로 반환한다.
이 함수들은 주로 PintOS 테스트에서 스레드 상태를 검사할 때 사용된다.
예: mlfqs-load- 또는 mlfqs-fair- 테스트들은 이 함수들의 반환 값을 검증하여 통과 여부를 판단한다.
함께 봐야 할 조건 분기
예: thread_set_priority()
void thread_set_priority(int new_priority) {
if (thread_mlfqs) return;
...
}→ MLFQS 모드일 때는 우선순위를 수동으로 변경하는 모든 코드가 무시됨.
예: thread_create()에서도 MLFQS 조건 확인
if (thread_mlfqs) {
t->recent_cpu = thread_current()->recent_cpu;
update_priority(t);
}→ 새로 생성된 스레드도 MLFQS 기준 값을 복사해서 시작함
코드를 모두 완성하고 테스트를 돌려보면?
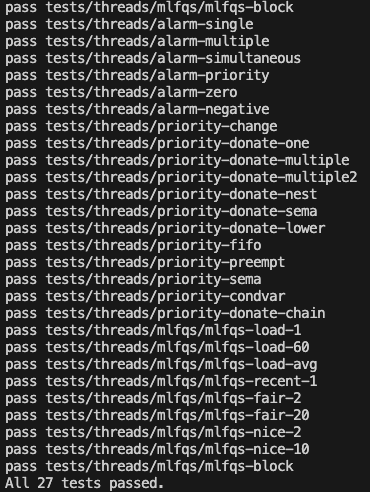
이와 같이 모든 테스트를 통과하게 된다 !!!
생각보다 어렵지 않은 것 같은데 디버깅을 하는게 아직 감이 잘 안잡히는 것 같아서 보완해야 할 것 같다 !
같이 고생한 팀원들에게 감사인사를 올리며 20000 🙏
