1. critical section에 두 프로세스가 동시에 접근하려 할 때 발생하는 문제점은? 이를 어떻게 해결할 수 있을까?
-
병행성은 프로세스 간 통신, 자원에 대한 공유와 경쟁, 프로세스 활동들의 동기화, 프로세스에 대한 처리기 시간 할당 등 다양한 이슈를 포함한다.
-
전역 자원의 공유가 어렵다 어떤 순서로 읽기, 쓰기가 지행되는지에 따라 결과가 달라진다.
-
critical section에 두 프로세스가 동시에 접근하려는 상태를 경쟁 상태(Race condition)라고 부른다. 즉 다중 프로세스 / 쓰레드가 공유 데이터를 읽거나 쓸 때 발생한다.
-
프로세스들이 경쟁하면 다음 3가지 제어 문제가 발생
- 상호 배제 (지원해야 함)
-
상호배제 (mutual exclusion) 요구 조건
-
어느 한 순간에는 오직 하나의 프로세스 만이 임계영역에 진입할 수 있다.
-
임계영역이 아닌 곳에서 수행이 멈춘 프로세스는 다른 프로세스의 수행을 간섭해서는 안 된다.
-
교착 상태, 기아가 일어나지 않아야 한다.
-
프로세서의 개수나 상대적인 수행 속도에 대한 가정은 없어야 한다. (편애 x)
-
프로세스는 유한 시간 동안만 임계 영역에 존재할 수 있다.
-
-
교착 상태 (deadlock)
: 서로 상대방이 자원을 제공해 줄 때까지 기다릴 뿐, 자신이 이미 할당받은 자원을 반납하지 않는다. 따라서 두 프로세스는 대기만 할 뿐 더 이상 수행을 진행하지 못한다. -
기아 (starvation)
: 교착 상태는 아닌데, 접근이 계속 거절되는 것
-
해결 방법
-
소프트웨어적 접근 방법
-
모든 책임을 병행 수행하려는 프로세스들이 담당하는 것
-
프로그래밍 언어 또는 운영체제의 특별한 자원 없이, 프로세스 간 협력을 통해 직접 상호배제를 보장하는 것
-
수행 부하가 높고, 놀리적 오류의 위험이 크다 (atomic이 아닐 수 있다)
-
-
하드웨어 지원
-
인터럽트 금지(오버헤드가 크다)
- 클럭도 없어짐, 멀티 프로세서 시스템에서는 보장 x
-
특별한 기계 명령어
: Test and Set, Exchange(=Compare & Swap)
- 기계 명령어가 수행되는 동안, 같은 메모리 위치를 접근하려는 다른 명령어들은 블록된다.

-
-
-
사용하기 쉬운 동기화 기법들
-
세마포어
- 상호배제를 운영체제와 프로그래밍 언어 수준에서 지원하는 매커니즘
-
모니터
- 상호배제를 위한 소프트웨어 모듈(프로그래밍 언어 수준에서 제공)
-
메세지 전달
-
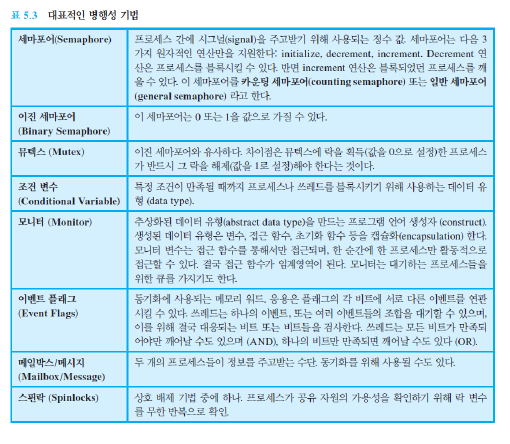
2. 가상 메모리(Virtual Memory)란?
-
실제 메모리 크기와 상관 없이 메모리를 이용할 수 있도록 가상의 메모리 주소를 사용하는 방법이다.
-
가상 메모리를 사용하면 다음과 같은 이점이 있다.
-
실제 메모리(RAM) 크기 보다 더 큰 공간을 사용할 수 있다. (보조 기억장치 공간 사용)
-
가상의 주소 공간을 사용하여 논리적인 연속성을 제공해준다.
-
물리 메모리 주소 공간을 알 필요가 없어진다.
-
-
대표적인 가상 메모리 기법으로 페이징(paging), 세그멘테이션(segmentation)이 있다.
-
현대 운영체제에서는 두 가지 방식이 혼용되어 사용된다.
-
두 방식 모두 매핑 테이블 형태로 관리 된다.
-
페이징 - 고정 분할 - 페이지 테이블
-
세그멘테이션 - 가변 분할 - 세그멘테이션 테이블
-
-
3. 프로세스와 스레드의 차이는?
-
프로세스(태스크) : 프로그램을 메모리 상에서 실행중인 작업
-
자원 저장소 (Resource Container)
-
사용자 문맥, 시스템 문맥
-
-
스레드 : 프로세스 안에서 실행되는 여러 흐름 단위
-
제어 흐름 (=경량 프로세스)
-
실행 정보, 레지스터 문맥
-
문맥 교환이 쓰레드 교환일 수 있다. 프로세스 교환보다 훨씬 비용이 적다.
(다른 프로세스 안에 쓰레드가 있을 땐 프로세스 교환일 수 있다. )
-
프로세스
-
컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램
-
메모리에 올라와 실행되고 있는 프로그램의 인스턴스(독립적인 개체)
-
운영체제로부터 시스템 자원을 할당받는 작업의 단위
- 즉, 동적인 개념으로는 실행된 프로그램을 의미한다.
-
특징
-
프로세스는 각각 독립된 메모리 영역(Code, Data, Stack, Heap의 구조)을 할당받는다.
-
Code : 코드 자체를 구성하는 메모리 영역(프로그램 명령)
-
Data : 전역변수, 정적변수, 배열 등
-
초기화 된 데이터는 data 영역에 저장
-
초기화 되지 않은 데이터는 bss(block started by symbol) 영역에 저장
- bss는 초기화가 되지 않은 공간을 한곳에 모아두는 곳
-
-
Heap : 동적 할당 시 사용 (new(), malloc() 등)
-
Stack : 지역변수, 매개변수, 리턴 값 (임시 메모리 영역)
-
-
-
기본적으로 프로세스마다 최소 1개의 스레드 소유 (메인 스레드 포함)
- 하나의 프로세스가 생성될 때, 기본적으로 하나의 스레드 같이 생성
-
각 프로세스는 별도의 주소 공간에서 실행되며, 한 프로세스는 다른 프로세스의 변수나 자료구조에 접근할 수 없다.
-
한 프로세스가 다른 프로세스의 자원에 접근하려면 프로세스 간의 통신(IPC, inter-process communication)을 사용해야 한다.
- 파이프, 파일, 소켓 등을 이용한 통신 방법 이용
스레드
-
프로세스 내에서 실행되는 여러 흐름의 단위
-
프로세스의 특정한 수행 경로
-
프로세스가 할당받은 자원을 이용하는 실행의 단위
-
특징
-
스레드는 프로세스 내에서 각각 Stack만 따로 할당받고 Code, Data, Heap 영역은 공유한다.
-
스레드는 한 프로세스 내에서 동작되는 여러 실행의 흐름으로, 프로세스 내의 주소 공간이나 자원들(힙 공간 등)을 같은 프로세스 내에 스레드끼리 공유하면서 실행된다.
-
같은 프로세스 안에 있는 여러 스레드들은 같은 힙 공간을 공유한다. 반면에 프로세스는 다른 프로세스의 메모리에 직접 접근할 수 없다.
-
각각의 스레드는 별도의 레지스터와 스택을 갖고 있지만, 힙 메모리는 서로 읽고 쓸 수 있다.
-
한 스레드가 프로세스 자원을 변경하면, 다른 이웃 스레드(sibling thread)도 그 변경 결과를 즉시 볼 수 있다.
-
4. 페이징 기법과 세그멘테이션 기법의 차이는?
페이징(Paging)
-
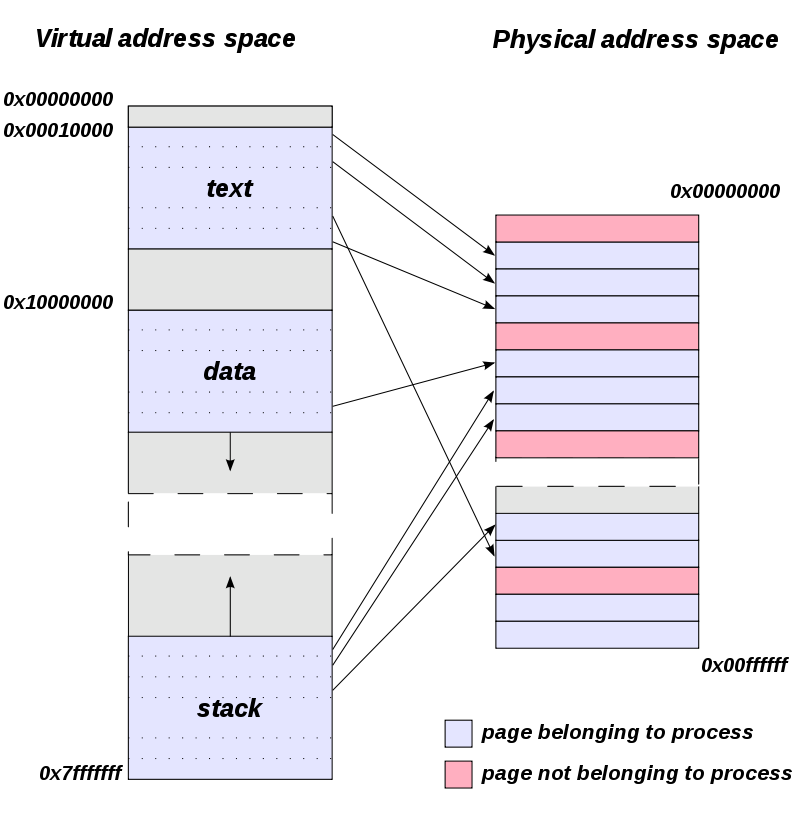
페이징이란 고정 크기로 분할된 페이지(page)를 통해 가상 메모리를 관리하는 기법이다.
-
페이지(page) : 가상 메모리를 고정 크기로 나눈 블록
-
프레임(frame) : 실제 메모리를 페이지와 같은 크기로 나눈 블록 (= 페이지 프레임)
-
프레임과 페이지는 메모리를 일정한 크기의 공간으로 나누어 관리하는 단위이며, 프레임과 페이지의 크기는 같다.
-
-
페이지와 프레임간의 관계
-
Vitual Memory의 page가 하나의 frame을 할당 받으면, 물리 메모리에 위치하게 된다.
-
프레임을 할당 받지 못한 페이지들은 외부 저장장치에 저장되며, 이때도 프레임과 같은 크기 단위로 관리된다.
-
-
페이지 테이블(Page Table)
-
프로세스의 페이지 정보를 저장하고 있는 테이블
=> page에 매핑되는 frame을 찾을 때 참조한다.
-
페이지 테이블 정보
-
key(or index) : 페이지 번호
-
value
-
page와 매핑된 frame번호
-
기타 플래그 정보(페이지 존재 여부, 읽기/쓰기 권한, 접근 권한 등)
-
-
-
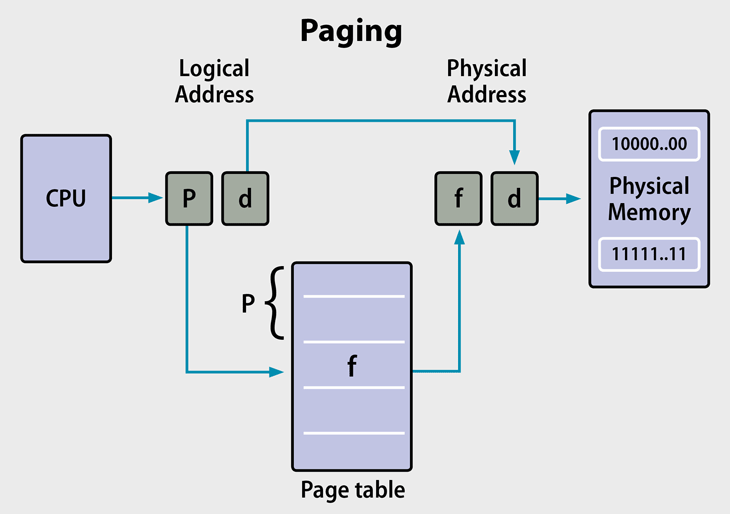
페이징 기법에서의 주소 바인딩 과정
-
<P, d> -> <f, d>
P : 페이지 번호
d : 변위
f : 프레임 번호(또는 프레임 시작 주소)
-
-
CPU에서 사용하는 logical address는 페이지 번호(P)와 변위(d)로 구성
-
Page Table에서 페이지 번호에 해당하는 프레임 시작 주소를 찾는다.
-
프레임 시작 주소(f) + 변위(d)를 통해 물리 주소를 계산하여 실제 물리 주소에 접근
-
이러한 변환 과정은 MMU에서 이루어 지며, 페이지 정보가 캐싱 되어 있을 경우 TLB를 통해 빠르게 접근하도록 한다.
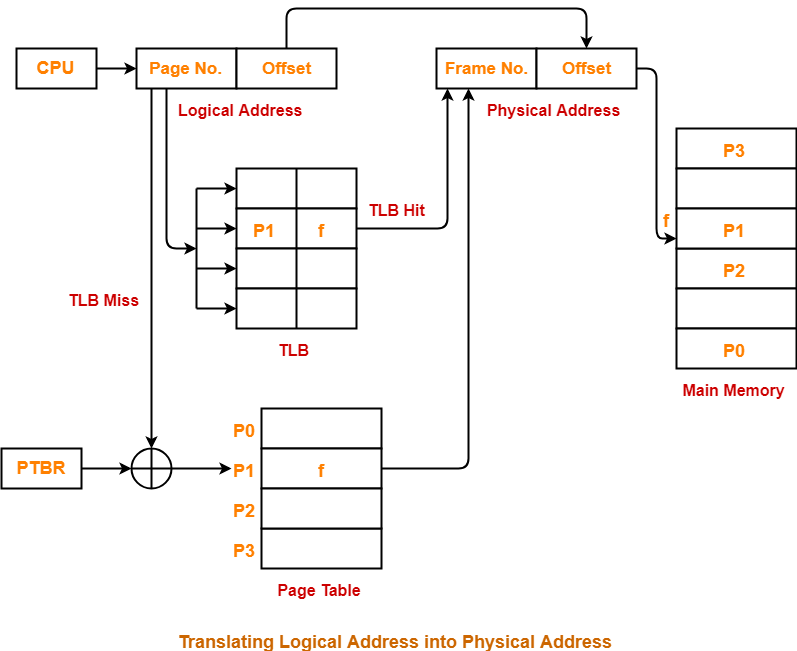
메모리 관리 장치(Memory Management Unit, 줄여서 MMU)는 CPU가 메모리에 접근하는 것을 관리하는 컴퓨터 하드웨어 부품이다. 가상 메모리 주소를 실제 메모리 주소로 변환하며, 메모리 보호, 캐시 관리, 버스 중재 등의 역할을 담당하며 간단한 8비트 아키텍처에서는 뱅크 스위칭을 담당하기도 한다.

MMU가 이와 같이 따로 분리된 하드웨어였지만 최근의 아키텍처에서는 프로세서와 같은 칩에 회로로 삽입된다.
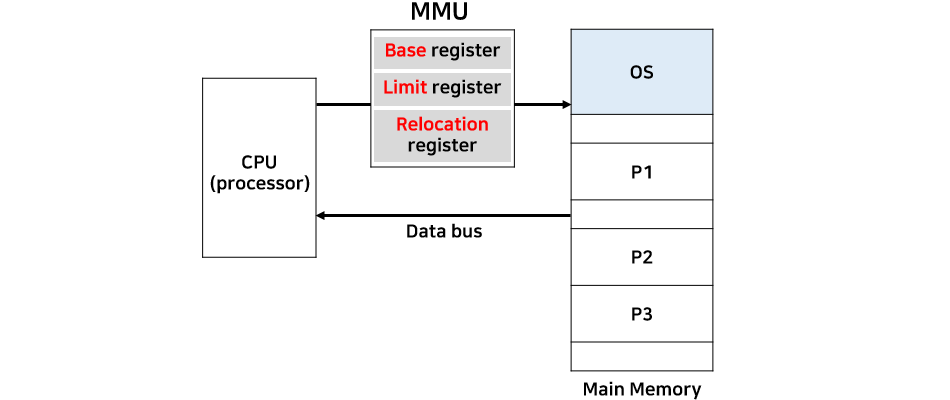
참고- MMU(Memory Management Unit)의 기능을 살펴보면, 이전에 메모리 보호를 위해 base와 limit 레지스터가 있었다. 이는 CPU에서 주소를 사용하는데 이 주소가 해당 프로그램의 base나 limit 범위를 벗어나면 인터럽트가 발생하여 그 프로그램을 강제로 종료시킨다.
- MMU는 이 기능 이외에도 재배치 레지스터를 사용해서 프로그램이 어느 주소를 사용하더라도 실제 메인 메모리에 할당된 주소를 찾아갈 수 있도록 address translation 동작을 수행한다. 즉, CPU는 프로그램에 설정된 주소를 계속 사용하고 메모리에 명령을 보내지만, MMU에 의해 실제로 프로그램이 할당된 메모리 주소로 변환해서 사용할 수 있는 것이다. 그 결과, 프로그램의 실제 메모리 주소 공간의 위치는 CPU에 전혀 영향을 미치지 않고 정상적으로 사용할 수 있는 것이다.
- MMU(Memory Management Unit)의 기능을 살펴보면, 이전에 메모리 보호를 위해 base와 limit 레지스터가 있었다. 이는 CPU에서 주소를 사용하는데 이 주소가 해당 프로그램의 base나 limit 범위를 벗어나면 인터럽트가 발생하여 그 프로그램을 강제로 종료시킨다.
-
-
페이지 테이블은 PTE라고 하는 레코드를 갖는데, 이 PTE를 통해 캐싱 되어 있는지 알 수 있다.
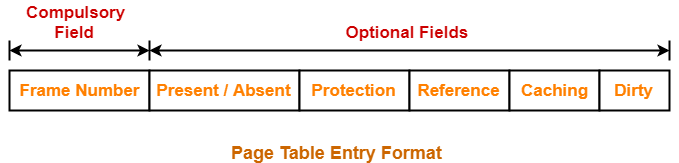
-
페이지 테이블 엔트리(PTE, Page Table Entry)
-
페이지 테이블의 레코드로 프레임 번호와 여러 플레그로 이루어져 구성되어 있다.
-
Frame Number : 프레임 번호
-
Present/Absent : 메인 메모리에 페이지가 존재하는지 확인하는 비트 필드 => 이를 통해 page fault 판별이 가능
-
Protection : 읽기만 가능한 경우 0, 읽기 쓰기 모두 가능한 경우 1
-
Reference : 참조 비트 (최근 참조 됐는지 판단하여 페이지 교체 알고리즘을 적용 시킬 수 있음)
-
Caching : 해당 페이지를 캐싱할지 선택
-
Dirty (or modified bit) : 오염 또는 수정 여부를 판단하는 비트로, 페이지 내용이 변경됐음을 알려 페이지 교체시 하드 디스크에 다시 기록하게 한다.
-
-
-
요구 페이징(Demand Paging)과 페이지 부재(Page Fault)
-
요구 페이징(Demand Pagin) : 요청할 때 해당 페이지를 메모리로 가져오는 것
-
페이지 부재(Page Fault) : 요청한 페이지가 메모리에 존재하지 않는 경우를 말한다.
세그멘테이션
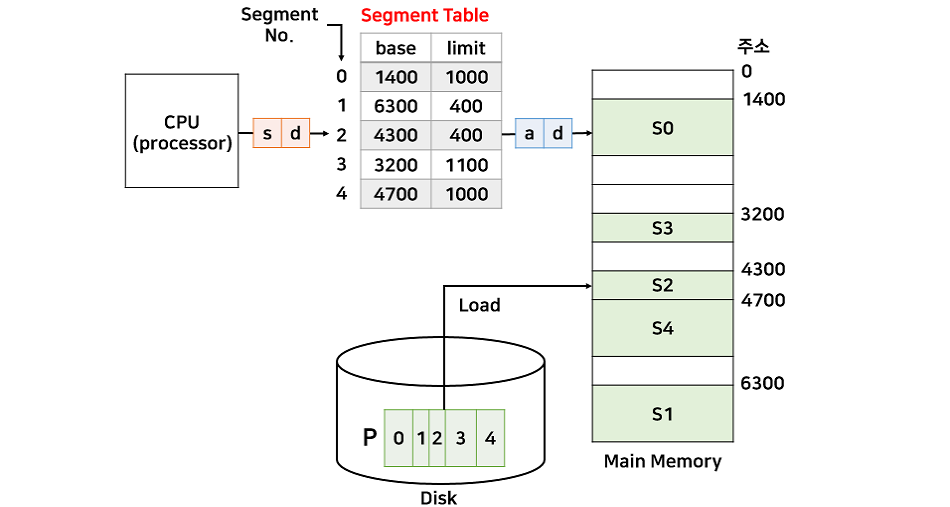
-
페이징 주소변환과 동일하게 d는 논리주소와 물리주소가 동일하다. 물리주소 a는 base[s] + d 로 계산된다.
-
논리주소 (2, 100) => 물리주소 4400번지
-
논리주소 (1, 500) => 인터럽트로 인해 프로세스 강제 종료(범위를 벗어남)
-
-
먼저, 결론부터 말하면 페이징보다 세그먼테이션에서의 보호와 공유는 더 효율적이다.
-
보호에서는 세그먼테이션 역시 r, w, x 비트를 테이블에 추가하는데, 세그먼테이션은 논리적으로 나누기 때문에 해당 비트를 설정하기 매우 간단하고 안전하다. 페이징은 code + data + stack 영역이 있을 때 이를 일정한 크기로 나누므로 두 가지 영역이 섞일 수가 있다. 그러면 비트를 설정하기가 매우 까다롭다.
-
공유에서도 마찬가지다. 페이징에서는 code 영역을 나눈다해도 다른 영역이 포함될 확률이 매우 높다. 하지만 세그먼테이션은 정확히 code 영역만 나누기 때문에 더 효율적으로 공유를 수행할 수 있다.
-
페이징과 세그멘테이션의 혼용
세그먼테이션에는 치명적인 단점이 있다.
메모리 할당을 처음 시작할 때 다중 프로그래밍에서의 문제는 크기가 서로 다른 프로세스로 인해 여러 크기의 hole이 발생한다. 이로 인해 어느 hole에 프로세스를 할당하는 것에 대한 최적화 알고리즘이 존재하지 않고, 외부 단편화로 인해 메모리 낭비가 크다고 했었다.
세그먼테이션도 똑같은 문제점이 발생한다. 왜냐하면 세그먼테이션은 논리적인 단위로 나누기 때문에 세그먼트의 크기가 다양하다. 이로 인해 다양한 크기의 hole이 발생하므로 같은 문제가 발생한다.
결론적으로 세그먼테이션은 보호와 공유에서 효율적이고, 페이징은 외부 단편화 문제를 해결할 수 있다. 그러므로 두 가지를 합쳐서 사용하는 방법이 나왔다.
두 장점을 합치기 위해서는 세그먼트를 페이징 기법으로 나누는 것이다.(Paged segmentation)
- 하지만 이 역시 단점이 존재한다. 세그먼트와 페이지가 동시에 존재하기 때문에 주소 변환도 두 번해야한다. 즉 CPU에서 세그먼트 테이블에서 주소 변환을 하고, 그 다음 페이지 테이블에서 또 주소 변환을 해야한다.
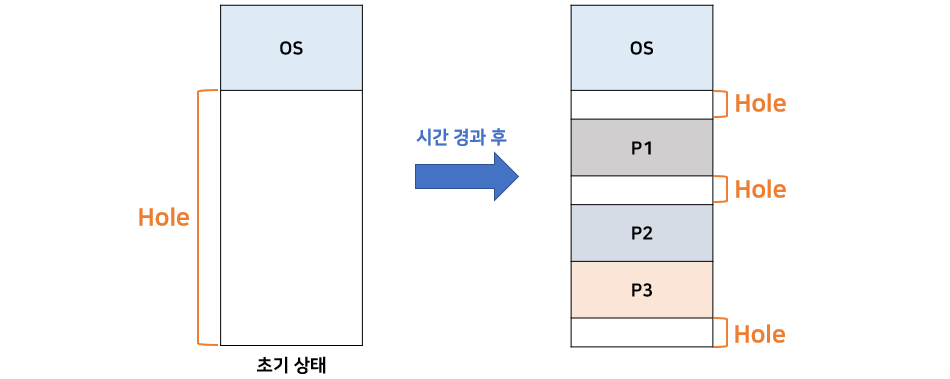
5. 교착상태란?
-
영속적인 블록 상태로, 공유자원을 기다리면서 실행대기를 서로 하는 것 (서로 놓지 않음)으로 영구적인 이유는 기다리던 사건이 결코 발생하지 않기 때문이다.
- 2개 이상의 프로세스들의 자원을 기다리면서 자신도 블록된다.
-
소모성 자원은 싱크가 맞지 않으면 교착상태가 발생
- 인터럽트, 시그널, 메세지, I/O 버퍼에 존재하는 정보 등
-
재사용 가능한 자원은 교착상태는 한 프로세스가 자원을 획득한 후에 다른 자원을 원하며, 다른 프로세스는 반대 순서로 자원을 획득한 후 다른 자원을 원하면 발생
- 처리기, I/O 입출력 채널, 주/보조 메모리, 장치, 파일이나 데이터베이스나 세마포어와 같은 자료구조
<교착상태 가능 vs 발생>
가능: 상호배제, 점유대기, 비선점
발생: 상호배제, 점유대기, 비선점, 환형대기
1) 상호배제(Mutual exclusion) : 프로세스들이 필요로 하는 자원에 대해 배타적인 통제권을 요구한다.
2) 점유대기(hold and wait): 이미 자원을 보유한 프로세스가 다른 자원을 요청하여 기다리고 있다.
3) 비선점 (no preemption): 프로세스에 의해 점유된 자원을 프로세스가 강제적으로 빼앗을 수 없다.
4) 환형대기(circular wait): 프로세스들 간에 닫힌 연결 (closed chain)이 존재한다.
- 즉 자원 할당 그래프에서 환형이 만들어지는 것
- 닫힌 연결에서 블록 된 프로세스가 자원을 점유하고 있는데, 이 자원을 체인 내부의 다른 프로세스가 원하여 대기하고 있다.
6. CPU 스케줄링에는 크게 선점형과 비선점형이 있다. 각각에서 하나의 알고리즘을 선택해 설명하자면?
스케줄링의 목적
너무나도 당연하게 스케줄링의 목적은 (앞에도 언급되어 있듯이) CPU를 할당받을 프로세스를 잘 골라 실행시켜 결과적으로 시스템의 성능을 향상시키는 것입니다.
사용자에게 성능이 우수한 시스템이란 응답 시간(response time)이 빠를 수록 좋을 것입니다. 여기서 응답 시간이란 프로세스의 요청에 대해 시스템이 최초로 출력을 내주기 시작할 때까지 걸린 시간을 뜻하는데, 이 외에도 요청한 일이 얼마 후 쯤에 완료 될 수 있을 것이라는 예측 가능성도 성능 평가의 지표로 쓸 수 있습니다.
시스템에게 뛰어난 성능으로 평가받으려면 처리량, 활용도, 응답시간 등을 평가 지표로 삼으면 됩니다.
대화형 시스템의 경우 응답 시간이 중요하고, 일괄처리 시스템에서는 처리량이 가장 중요한 지표입니다. 그러나 이 기준들은 서로 상충하는 것들도 있어 모든 기준에게 우수한 평가를 받을 수는 없습니다.
- 가령 응답시간을 높이기 위해 스케줄링을 자주 한다면 그때마다 CPU를 이용해서 문맥교환이 필요하기 때문에 결국 사용자 프로세스를 실행해 줄 시간이 줄어들어 전체 처리량은 감소하게 되는 것입니다.
- 반면 처리량을 높이기 위해 수행 시간이 짧은 프로세스들만 계속 처리한다면 수행 시간이 긴 프로세스는 처리가 늦어지거나 계속 기다려야 해서 응답 시간이 느려지는 것입니다. 이렇 듯 모든 기준을 만족시킬 수는 없으므로 시스템을 사용하는 목적과 환경에 맞게 설계하여 스케줄링을 해야합니다.
스케줄링의 목적
- 일반적인 시스템에서는 다음과 같은 목적을 공통적으로 지닌다.
- No starvation : 각각의 프로세스들이 오랜시간동안 CPU를 할당받지 못하는 상황이 없도록 함
- Fairness : 각각의 프로세스에 공평하게 CPU를 할당해줌.
- Balance : Keeping all parts of the system busy
- Batch System [일괄처리 시스템]
: 온라인처럼 일에 대한 요청이 발생했을 때, 즉각적으로 처리하는 것이 아닌 일정기간 또는 일정량을 모아뒀다가 한번에 처리하는 방식
- Throughput : 시간당 최대의 작업량을 낸다.
- Turnaround time : 프로세스의 생성부터 소멸까지의 시간을 최소화한다.
- CPU utilization : CPU가 쉬는 시간이 없도록 한다.
- Interactive System [대화형 시스템]
: 온라인과 같이 일에 대한 요청에 대해 즉각적으로 처리하여 응답을 받을 수 있는 시스템
- Response time : 즉각적으로 처리해야하는 시스템이므로 요청에 대해 응답시간을 줄이는 게 중요하다.
- Time Sharing System
: 각 프로세스에 CPU에 대한 일정시간을 할당하여 주어진 시간동안 프로그램을 수행할 수 있게하는 시스템
- Meeting deadlines : 데이터의 손실을 피하며, 끝내야하는 시간 안에 도달해야한다.
- Predictability : 멀티미디어 시스템에서의 품질이 저하되는 부분을 방지해야한다.
-
비선점 스케줄링 : 프로세스가 입출력 요구 등으로 CPU를 자진 반납할 때까지 CPU에 의한 실행을 보장해주는 스케줄링이다. 작업 실행 시간 전체 또는 한번의 CPU 배당에 적용된다.
- FCFS(First-Come-Fist-Served) / 최단 작업 우선(SJF, Shortest Job First) / 우선순위 스케줄링 (Priority Scheduling)
-
선점 스케줄링 : 시분할 시스템에서 타임슬라이스가 소진되었거나 인터럽트 혹은 시스템 호출 종료로 인한 여파로 현 프로세스보다 높은 우선순위의 프로세스가 나타나는 스케줄링이다. 현 프로세스로부터 강제로 CPU를 회수한다.
- 라운드 로빈 스케줄링 / 다단계 큐 스케줄링 / 다단계 피드백 큐
우선 순위 스케줄링(Priority Scheduling)
-
프로세스 자체적으로 우선순위를 정해두고, 우선순위 값이 제일 큰 프로세스에게 CPU를 할당한다. 순위가 같을 경우 FCFS를 적용한다.
-
SJF도 결국엔 우선 순위 스케줄링에 포함된다고도 할 수 있다. (우선순위가 CPU Burst Time의 역수)
-
내부적 우선순위 고려 : 제한시간, 메모리 요구량, 사용하는 파일 수, 평균 CPU Burst에 대한 평균 I/O Burst 비율
-
외부적 우선순위 고려 : 사용료, 정책적 변수
-
일반적으로 연산 위주(CPU-Bound) 프로세스보다 입출력 위주(I/O-Bound) 프로세스에게 높은 우선순위를 부여하여 대화성을 증진시킨다.
기아 상태(Starvation)가 유발될 수 있다. 우선순위가 높은 작업이 계속적으로 들어올 경우 우선순위가 낮은 작업이 준비 상태에서 보장없이 머물 수 있다.- 이러한 기아 상태는 에이징(Aging)으로 해결할 수 있다. 시스템에 머무는 시간이 증가하면 우선순위를 높여주는 것이다. 아무리 우선순위가 낮았던 프로세스라도 시간이 지나면서 우선순위가 높아져 결국은 CPU를 할당받을 수 있게 된다.
-
-
HRN(Highest Response Ratio Next)
- 스케줄링은 운영체제가 여러 프로세스 입력이 들어왔을 때 프로세스 실행 우선순위를 정하기 위한 기법
- HRN 스케줄링 기법은 SJF 스케줄링 기법의 약점인 긴 작업과 짧은 작업 사이의 불평등을 보완하기 위한 방법
- HRN의 우선순위 선정 방법은
- 우선순위 = (대기시간 + 실행시간) / 실행시간 = 시스템 응답시간
- 응답시간이 커질수록 우선순위가 높아짐
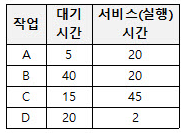 A : (5+20)/ 20 = 1.25
A : (5+20)/ 20 = 1.25
B : (40+20) / 20 = 3
C : (15 + 45) / 45 = 1.33
D : (20 + 2) / 2 = 11
D → B → C → A
-
라운드 로빈(Round Robin) 스케줄링
-
준비 큐를 원형 큐로 간주하고 순환식으로 각 프로세스에게 작은 단위의 시간량(타임퀀텀)만큼씩 CPU를 할당한다.
-
실행상태의 프로세스는 타임퀀텀이 지나면 선점된다. (타임퀀텀은 타임슬라이스와 마찬가지의 개념이다.)
-
새로운 프로세스가 부가될 때는 큐의 맨 뒤에 덧붙여 진다.
-
물론 입출력이 발생하면 CPU를 자진반납한다.
-
이론상 N개의 프로세스가 1/N 속도로 동시에 실행되는 셈이다. 준비 큐에 N개의 프로세스가 있고, 타임슬라이스가 Q이면 각 프로세스는 (N-1)* Q 시간 이내에 다음 슬라이스를 받게된다. (문맥교환 시간은 고려하지 않았다.)
-
아무리 짧은 작업이라도 앞선 다른 작업이 큐 앞에 있다면 한 번이라도 각각의 타임퀀텀을 거쳐야하기 때문에 일반적으로 평균반환시간이 SJF보단 크다.
- 하지만 모든 프로세스가 공정하게 기회를 얻게되어 기아상태가 발생하지 않는다는 장점이 있다.
-
타임퀀텀의 크기에 따라 성능이 큰 영향을 받는다. 타임퀀텀이 매우 커지면 FCFS와 유사해진다. 매우 작아지면 잦은 문맥교환에 따라 오버헤드가 커져 처리율이 감소한다.
-
일반적으로 타임퀀텀이 커지면 평균 반환시간이 개선될 수 있다. 많은 작업이 한번에 처리될 확률이 증가되기 때문이다. 다만 많은 짧은 작업이 긴 작업들보다 순서상 늦게 처리되는 경우가 발생할 수 있어 무조건 그런 것은 아니다.
- 만약 대부분의 프로세스가 타임퀀텀내에 하나의 CPU Burst를 처리한다면 평균반환시간이 개선될 것이다. 따라서 80% 정도의 CPU Burst Time은 타임퀀텀보다 짧도록 조정하는 것이 가장 적절하다.
7. 기아(starvation) 현상이란? 이를 어떻게 해결할 수 있을까?
-
기아상태 : 여러 프로세스가 부족한 자원을 점유하기 위해 경쟁할 때 발생
-
프로세스 우선순위 수시 변경을 통해 각 프로세스 높은 우선순위를 가지도록 기회 부여
-
오래 기다린 프로세스의 우선순위 높이기 (에이징)
-
우선순위가 아닌 요청 순서대로 처리하는 요청큐 사용
-
8. 컴퓨터 부팅 과정은?
CPU는 컴퓨터에 전원이 들어오면 제일 먼저 메모리의 0번지 주소의 데이터를 읽는다.
-
메모리의 0번지에는 ROM(Read-Only Memory)이라는, 컴퓨터를 구동하기 위한 기본 정보가 담긴 메모리가 있다.
- ROM은 컴퓨터의 전원을 꺼도 메모리가 지워지지 않아, 컴퓨터가 켜지면 이 곳의 정보를 읽어올 수 있다.
따라서 전원이 켜지면 ROM에서 읽어 들인 내용을 바탕으로 하드웨어의 상태를 확인하는 POST(Power On Self Test)를 수행한다.
그리고 운영체제를 로드하기 위해 디스크의 첫번째 섹터인 마스터 부트 레코드(Master Boot Record, MBR)를 읽는다.
-
MBR에서 부트 코드(Boot Code)가 실행된다.
-
부트 코드는 부팅 가능한 파티션을 찾아 해당 파티션의 부트 레코드(Boot Record)를 호출하고, 해당 파티션 부트 레코드는 RAM에 적재된다.
위의 과정이 모두 끝나면, 부팅이 시작된다.
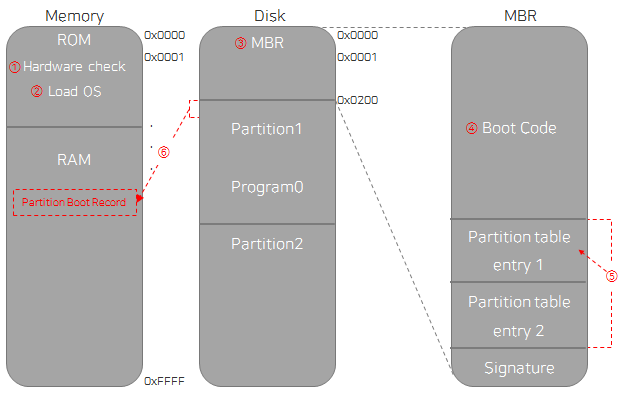
-
컴퓨터에 전원이 들어오면 POST 과정 수행
-
운영체제 로드를 위한 과정 시작
-
MBR 읽기
-
MBR의 부트 코드가 실행, 이는 부팅 가능한 파티션을 찾는 역할
-
파티션 테이블에서 부팅 가능한 파티션을 찾음 (Partition 1)
-
해당 파티션의 첫번째 섹터인 파티션 부트 레코드를 메모리에 적재하여 실행
-
해당 파티션으로 부팅이 시작
9. 리눅스에서 커널이란? 커널의 특징은?
-
Linux® 커널은 Linux 운영 체제(OS)의 주요 구성 요소이며 컴퓨터 하드웨어와 프로세스를 잇는 핵심 인터페이스입니다. 그리고 두 가지 관리 리소스 사이에서 최대한 효과적으로 통신합니다.
-
커널이라는 이름은 단단한 껍질 안의 씨앗처럼 OS 내에 위치하고 전화기, 노트북, 서버 또는 컴퓨터 유형에 관계없이 하드웨어의 모든 주요 기능을 제어하기 때문에 붙은 이름입니다.
커널의 기능
커널은 다음과 같은 4가지 기능을 수행합니다.
-
메모리 관리: 메모리가 어디에서 무엇을 저장하는 데 얼마나 사용되는지를 추적합니다.
-
프로세스 관리: 어느 프로세스가 중앙 처리 장치(CPU)를 언제 얼마나 오랫동안 사용할지를 결정합니다.
-
장치 드라이버: 하드웨어와 프로세스 사이에서 중재자/인터프리터의 역할을 수행합니다.
-
시스템 호출 및 보안: 프로세스의 서비스 요청을 수신합니다.
올바르게 구현된 커널은 사용자가 볼 수 없으며 커널 공간이라는 자신만의 작은 작업 공간에서 메모리를 할당하고 저장되는 모든 항목을 추적합니다.
-
웹 브라우저 및 파일과 같이 사용자가 볼 수 있는 것을 사용자 공간이라고 합니다.
- 이러한 애플리케이션은 시스템 호출 인터페이스(SCI)를 통해 커널과 통신합니다.
설명하자면 다음과 같습니다. 커널은 강력한 경영진(하드웨어)을 위해 일하는 바쁜 비서입니다. 비서의 할 일은 직원 및 대중(사용자)으로부터 수신되는 메시지 및 요청(프로세스)을 경영진에게 전달하고, 어디에 무엇이 저장되어 있는지 기억(메모리)하고, 특정한 시간에 누가 경영진을 얼마 동안 만날 수 있는지 결정하는 것입니다.
OS 내에서 커널의 위치
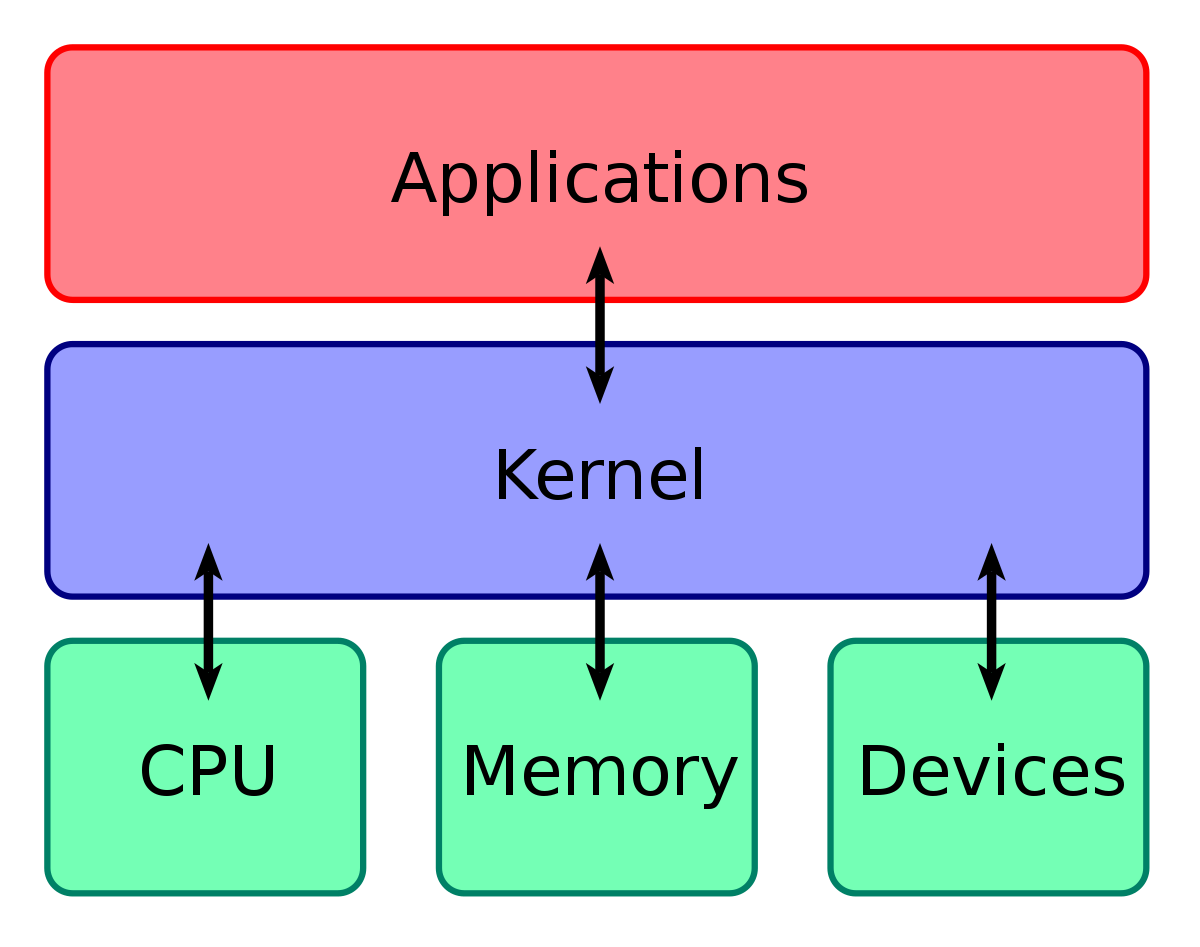
커널과 관련하여 Linux 시스템은 다음과 같은 3개 레이어로 구성되어 있다고 볼 수 있습니다.
-
하드웨어: 시스템의 토대가 되는 물리적 머신으로, 메모리(RAM)와 프로세서 또는 중앙 처리 장치(CPU) 그리고 입출력(I/O) 장치(예: 스토리지, 네트워킹 및 그래픽)로 구성됩니다. CPU는 계산을 수행하고 메모리를 읽고 씁니다.
-
Linux 커널: OS의 핵심입니다. (보시다시피 한가운데에 있습니다.)
- 메모리에 상주하며 CPU에 명령을 내리는 소프트웨어입니다.
-
사용자 프로세스: 실행 중인 프로그램으로, 커널이 관리합니다.
- 사용자 프로세스가 모여 사용자 공간을 구성합니다. 사용자 프로세스를 단순히 프로세스라고도 합니다. 또한, 커널은 이러한 프로세스 및 서버가 서로 통신(프로세스 간 통신 또는 IPC라고 함)할 수 있도록 해줍니다.
-
시스템에서 실행되는 코드는 커널 모드 또는 사용자 모드라는 두 가지 모드 중 하나로 CPU에서 실행됩니다.
-
커널 모드에서 실행 중인 코드는 하드웨어에 무제한 액세스가 가능한
-
사용자 모드에서는 CPU 및 메모리가 SCI를 통해 액세스하는 것을 제한합니다.
-
메모리도 이와 유사하게 구분됩니다(커널 공간 및 사용자 공간).
-
이러한 두 가지 작은 세부 사항이 보안, 컨테이너 구축 및 가상 머신을 위한 권한 구분과 같은 복잡한 작업의 토대가 됩니다.
-
-
이는 프로세스가 사용자 모드에서 실패할 경우 손상이 제한적이며 커널에 의해 복구될 수 있음을 의미합니다.
-
그러나 커널 프로세스는 메모리와 프로세서에 액세스할 수 있기 때문에 충돌이 발생하면 시스템 전체가 중지될 수 있습니다.
-
안전 장치가 마련되어 있고 경계를 넘기 위해서는 권한이 필요하기 때문에, 사용자 프로세스 충돌은 일반적으로 커다란 문제를 유발하지는 않습니다.
-
-
10. 컴파일러란? 컴파일러와 인터프리터의 차이는?
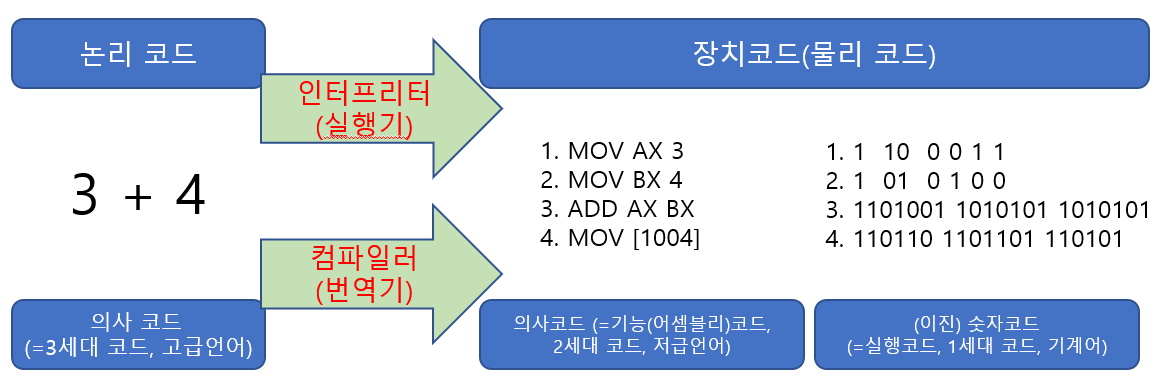
컴파일러와 인터프리터는 사람이 이해할 수 있는 고급언어로 작성된 소스 코드를 기계가 이해할 수 있는 기계어로 번역한 후에 프로그램을 실행하는 것
컴파일러(번역기)
-
컴파일러는 사람이 고급 언어를 작성을 하면 해당 고급 언어를 한 번에 번역을 합니다.
- 그렇기 때문에 줄 단위로 번역을 하는 인터프리터에 비해 번역 시간은 오래 걸리는 편입니다.
-
하지만, 컴파일러는 한 번 번역을 하면 실행 파일이 생성이 되어 다음에 실행을 할 때 기존에 생성되었던 실행 파일을 실행하기 때문에 인터프리터에 비해 실행 시간이 빠른 편입니다.
인터프리터(실행기)
-
인터프리터는 컴파일러와는 다르게 한 줄 한 줄씩 번역을 진행하기 때문에 한 번에 번역을 진행하는 컴파일러에 비해 번역 시간은 빠른 편입니다.
-
하지만 번역을 할 때 실행 파일을 생성하지 않기 때문에 매번 실행할 때마다 같은 번역을 진행해야 합니다.
그래서 매번 번역을 거치기 때문에 인터프리터를 사용하는 언어들은 컴파일러를 사용하는 언어들에 비해 실행 속도가 느린 편입니다.
언뜻 보기에는 컴파일러가 인터프리터보다 실행 속도가 빠르기 때문에 좋아보이는데 인터프리터도 사용하는 이유가 무엇일까요?
- 컴파일러는 플랫폼(하드웨어)에 종속적이지만, 인터프리터는 모든 플랫폼(하드웨어)에 종속되지 않는 특징이 있습니다.
- 서로 호환이 되는 CPU가 있을 것이고 호환이 되지 않는 CPU도 존재할 것입니다.
- 가령 A라는 CPU와 B라는 CPU가 존재하는데 서로 호환이 되지 않는다고 해봅시다.
- A CPU에서 돌아가는 프로그램을 만들고 컴파일러를 통해 실행파일을 만들고 이를 B CPU에서 실행시키면 실행이 될까요?
작동이 안됩니다.
- A CPU에서 컴파일러를 통해 실행파일을 만들게 되면 A 하드웨어의 환경에 맞게 변환을 하기 때문에 A CPU와 호환되는 CPU에서만 작동될 수 밖에 없습니다.
- 하지만 인터프리터는 해당 프로그램을 번역하는 하드웨어의 환경에 맞게 변환을 하기 때문에 B CPU에서 실행을 해도 잘 작동할 것입니다.
이러한 장점 때문에 인터프리터를 사용하기도 한답니다.
자바에서는 .java 파일을 javac 컴파일러가 바이트 코드인 .class 파일로 변환을 합니다.
.class 파일로 변환을 한 상태에서는 플랫폼에 종속적입니다.
11. LRU란?
-
페이지 교체(Page replacement)
-
페이지가 메모리에서 올라오고 쫒겨나고를 반복하기 때문에, 어떤 페이지가 쫒겨나야 하는지 결정 해줘야 한다.
-
이를 결정해주는 알고리즘을 페이지 교체 알고리즘이라고 한다.
ex) FIFO, LRU, LFU, NUR 등...
- 페이지 교체시 오버헤드가 발생하기 때문에 최대한 페이지 부재가 일어나지 않도록 적절한 알고리즘을 적용해줘야 한다.
-
- 스레싱(Thrasing)
잦은 페이지 부재로 인해 페이지를 교체 하는 시간이 많아져 CPU처리율이 저하되는 현상
-
메모리 부족, 부적절한 페이지 교체 등이 원인이 될 수 있다.
- cach hit rate와 관련 있음

