1. 클린코드 & 리팩토링 / 클린코드 & 시큐어코딩
전문가들이 표현한 '클린코드'
-
한 가지를 제대로 한다
-
단순하고 직접적이다
-
특정 목적을 달성하는 방법은 하나만 제공한다
-
중복 줄이기, 표현력 높이기, 초반부터 간단한 추상화 고려하기 이 세가지가 비결
-
코드를 읽으면서 짐작했던 기능을 각 루틴이 그대로 수행하는 것
클린코드란?
-
코드를 작성하는 의도와 목적이 명확하며, 다른 사람이 쉽게 읽을 수 있어야 함
- 즉, 가독성이 좋아야 한다.
-
가독성을 높인다는 것은?
- 다른 사람이 코드를 봐도, 자유롭게 수정이 가능하고 버그를 찾고 변경된 내용이 어떻게 상호작용하는지 이해하는 시간을 최소화 시키는 것이다.
클린코드를 만들기 위한 규칙
#1. 네이밍(Naming)
변수, 클래스, 메소드에 의도가 분명한 이름을 사용한다.
int elapsedTimeInDays;
int daysSinceCreation;
int fileAgeInDays;-
잘못된 정보를 전달할 수 있는 이름을 사용하지 않는다.
-
범용적으로 사용되는 단어 사용 X (aix, hp 등)
-
연속된 숫자나 불용어를 덧붙이는 방식은 피해야 한다.
2. 주석달기(Comment)
코드를 읽는 사람이 코드를 작성한 사람만큼 잘 이해할 수 있도록 도와야 함
-
주석은 반드시 달아야 할 이유가 있는 경우에만 작성하도록 한다.
-
즉, 코드를 빠르게 유추할 수 있는 내용에는 주석을 사용하지 않는 것이 좋다.
-
설명을 위한 설명은 달지 않는다.
-
// 주어진 'name'으로 노드를 찾거나 아니면 null을 반환한다.
// 만약 depth <= 0이면 'subtree'만 검색한다.
// 만약 depth == N 이면 N 레벨과 그 아래만 검색한다.
Node* FindNodeInSubtree(Node* subtree, string name, int depth);
3. 꾸미기(Aesthetics)
보기좋게 배치하고 꾸민다.
보기 좋은 코드가 읽기도 좋다.
-
규칙적인 들여쓰기와 줄바꿈으로 가독성을 향상시키자
-
일관성있고 간결한 패턴을 적용해 줄바꿈한다.
-
메소드를 이용해 불규칙한 중복 코드를 제거한다.
-
클래스 전체를 하나의 그룹이라고 생각하지 말고, 그 안에서도 여러 그룹으로 나누는 것이 읽기에 좋다.
4. 흐름제어 만들기(Making control flow easy to read)
- 왼쪽에는 변수를, 오른쪽에는 상수를 두고 비교
if(length >= 10)
while(bytes_received < bytest_expected)- 부정이 아닌 긍정을 다루자
if( a == b ) { // a!=b는 부정
// same
} else {
// different
}-
if/else를 사용하며, 삼항 연산자는 매우 간단한 경우만 사용
-
do/while 루프는 피하자
5. 착한 함수(Function)
함수는 가급적 작게, 한번에 하나의 작업만 수행하도록 작성
온라인 투표로 예를 들어보자
- 사용자가 추천을 하거나, 이미 선택한 추천을 변경하기 위해 버튼을 누르면 vote_change(old_vote, new_vote) 함수를 호출한다고 가정해보자
var vote_changed = function (old_vote, new_vote) {
var score = get_score();
if (new_vote !== old_vote) {
if (new_vote == 'Up') {
score += (old_vote === 'Down' ? 2 : 1);
} else if (new_vote == 'Down') {
score -= (old_vote === 'Up' ? 2 : 1);
} else if (new_vote == '') {
score += (old_vote === 'Up' ? -1 : 1);
}
}
set_score(score);
};총점을 변경해주는 한 가지 역할을 하는 함수같지만, 두가지 일을 하고 있다.
-
old_vote와 new_vote의 상태에 따른 score 계산
-
총점을 계산
별도로 함수로 분리하여 가독성을 향상시키자
var vote_value = function (vote) {
if(vote === 'Up') {
return +1;
}
if(vote === 'Down') {
return -1;
}
return 0;
};
var vote_changed = function (old_vote, new_vote) {
var score = get_score();
score -= vote_value(old_vote); // 이전 값 제거
score += vote_value(new_vote); // 새로운 값 더함
set_score(score);
};훨씬 깔끔한 코드가 되었다!
코드리뷰 & 리팩토링
-
레거시 코드(테스트가 불가능하거나 어려운 코드)를 클린 코드로 만드는 방법
-
코드리뷰를 통해 냄새나는 코드를 발견하면, 리팩토링을 통해 점진적으로 개선해나간다.
코드 인스펙션(code inspection)
작성한 개발 소스 코드를 분석하여 개발 표준에 위배되엇거나 잘못 작성된 부분을 수정하는 작업
-
절차 과정
-
Planning : 계획 수립
-
Overview : 교육과 역할 정의
-
Preparation : 인스펙션을 위한 인터뷰, 산출물, 도구 준비
-
Meeting : 검토 회의로 각자 역할을 맡아 임무 수행
-
Rework : 발견한 결함을 수정하고 재검토 필요한지 여부 결정
-
Fellow-up : 보고된 결함 및 이슈가 수정되었는지 확인하고 시정조치 이행
-
리팩토링
냄새나는 코드를 점진적으로 반복 수행되는 과정을 통해 코드를 조금씩 개선해나가는 것
-
리팩토링 대상
-
메소드 정리 : 그룹으로 묶을 수 있는 코드, 수식을 메소드로 변경함
-
객체 간의 기능 이동 : 메소드 기능에 따른 위치 변경, 클래스 기능을 명확히 구분
-
데이터 구성 : 캡슐화 기법을 적용해 데이터 접근 관리
-
조건문 단순화 : 조건 논리를 단순하고 명확하게 작성
-
메소드 호출 단순화 : 메소드 이름이나 목적이 맞지 않을 때 변경
-
클래스 및 메소드 일반화 : 동일 기능 메소드가 여러개 있으면 수퍼클래스로 이동
-
리팩토링 진행 방법
-
아키텍처 관점 시작 → 디자인 패턴 적용 → 단계적으로 하위 기능에 대한 변경으로 진행
-
의도하지 않은 기능 변경이나 버그 발생 대비해 회귀테스트 진행
-
이클립스와 같은 IDE 도구로 이용
시큐어 코딩
안전한 소프트웨어를 개발하기 위해, 소스코드 등에 존재할 수 있는 잠재적인 보안약점을 제거하는 것
-
보안 약점을 노려 발생하는 사고사례들
-
SQL 인젝션 취약점으로 개인유출 사고 발생
-
URL 파라미터 조작 개인정보 노출
-
무작위 대입공격 기프트카드 정보 유출
-
SQL 인젝션 예시
- 안전하지 않은 코드
String query "SELECT * FROM users WHERE userid = '" + userid + "'" + "AND password = '" + password + "'"; Statement stmt = connection.createStatement(); ResultSet rs = stmt.executeQuery(query);
- 안전한 코드
String query "SELECT * FROM users WHERE userid = ? + "AND password = ?"; PrepareStatement stmt = connection.prepareStatement(query); stmt.setString(1, userid); stmt.setString(2, password); ResultSet rs = stmt.executeQuery();
적절한 검증 작업이 수행되어야 안전함
입력받는 값으 변수를 `$` 대신 `#`을 사용하면서 바인딩 처리로 시큐어 코딩이 가능하다.
2. TDD(Test Driven Development)
- 테스트가 개발을 이끌어 나간다
-
우리는 보통 개발할 때, 설계(디자인)를 한 이후 코드 개발과 테스트 과정을 거치게 된다.

- 하지만 TDD는 기존 방법과는 다르게, 테스트케이스를 먼저 작성한 이후에 실제 코드를 개발하는 리팩토링 절차를 밟는다.
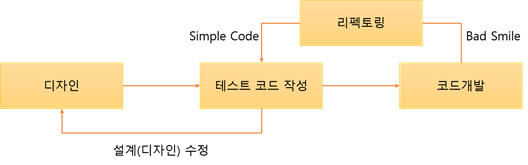
작가가 책을 쓰는 과정에 대해서 생각해보자.
책을 쓰기 전, 목차를 먼저 구성한다.
이후 목차에 맞는 내용을 먼저 구상한 뒤, 초안을 작성하고 고쳐쓰기를 반복한다.
목차 구성 : 테스트 코드 작성
초안 작성 : 코드 개발
고쳐 쓰기 : 코드 수정(리팩토링)`
- 반복적인 '검토'와 '고쳐쓰기'를 통해 좋은 글이 완성된다. 이런 방법을 소프트웨어에 적용한 것이 TDD!
- 소프트웨어 또한 반복적인 테스트와 수정을 통해 고품질의 소프트웨어를 탄생시킬 수 있다.
장단점
-
장점
-
작업과 동시에 테스트를 진행하면서 실시간으로 오류 파악이 가능하다 (시스템 결함 방지)
-
짧은 개발 주기를 통해 고객의 요구사항을 빠르게 수용 가능하다. 피드백이 가능하고 진행 상황 파악이 쉽다
-
자동화 도구를 이용한 TDD 테스트케이스를 단위 테스트로 사용이 가능하다 (java는 JUnit, C와 C++은 CppUnit 등)
-
개발자가 기대하는 앱의 동작에 관한 문서를 테스트가 제공해줌
-
테스트 케이스는 코드와 함께 업데이트 되므로 문서 작성과 거리가 먼 개발자에게 매우 좋다.
-
-
단점
-
기존 개발 프로세스에 테스트 케이스 설계가 추가되므로 생산 비용 증가
-
테스트의 방향성, 프로젝트 성격에 따른 테스트 프레임워크 선택 등 추가로 고려할 부분의 증가
-
점수 계산 프로그램을 통한 TDD 예제
-
중간고사, 기말고사, 과제 점수를 통한 성적을 내는 간단한 프로그램을 만들어보자
- 점수 총합 90점 이상은 A, 80점 이상은 B, 70점 이상은 C, 60점 이상은 D, 나머지는 F다.
-
TDD 테스트케이스를 먼저 작성한다.
-
35 + 25 + 25 = 85점이므로 등급이 B가 나와야 한다.
-
따라서 assertEquals의 인자값을 "B"로 주고, 테스트 결과가 일치하는지 확인하는 과정을 진행해보자
-
public class GradeTest {
@Test
public void scoreResult() {
Score score = new Score(35, 25, 25); // Score 클래스 생성
SimpleScoreStrategy scores = new SimpleScoreStrategy();
String resultGrade = scores.computeGrade(score); // 점수 계산
assertEquals("B", resultGrade); // 확인
}
}
현재는 Score 클래스와 computeGrade() 메소드가 구현되지 않은 상태다. (테스트 코드로만 존재)
테스트 코드에 맞춰서 코드 개발을 진행하자
우선 점수를 저장할 Score 클래스를 생성한다
public class Score {
private int middleScore = 0;
private int finalScore = 0;
private int homeworkScore = 0;
public Score(int middleScore, int finalScore, int homeworkScore) {
this.middleScore = middleScore;
this.finalScore = finalScore;
this.homeworkScore = homeworkScore;
}
public int getMiddleScore(){
return middleScore;
}
public int getFinalScore(){
return finalScore;
}
public int getHomeworkScore(){
return homeworkScore;
}
}
이제 점수 계산을 통해 성적을 뿌려줄 computeGrade() 메소드를 가진 클래스를 만든다.
우선 인터페이스를 구현하자
public interface ScoreStrategy {
public String computeGrade(Score score);
}
인터페이스를 가져와 오버라이딩한 클래스를 구현한다
public class SimpleScoreStrategy implements ScoreStrategy {
public String computeGrade(Score score) {
int totalScore = score.getMiddleScore() + score.getFinalScore() + score.getHomeworkScore(); // 점수 총합
String gradeResult = null; // 학점 저장할 String 변수
if(totalScore >= 90) {
gradeResult = "A";
} else if(totalScore >= 80) {
gradeResult = "B";
} else if(totalScore >= 70) {
gradeResult = "C";
} else if(totalScore >= 60) {
gradeResult = "D";
} else {
gradeResult = "F";
}
return gradeResult;
}
}
이제 테스트 코드로 돌아가서, 실제로 통과할 정보를 입력해본 뒤 결과를 확인해보자
이때 예외 처리, 중복 제거, 추가 기능을 통한 리팩토링 작업을 통해 완성도 높은 프로젝트를 구현할 수 있도록 노력하자!
통과가 가능한 정보를 넣고 실행하면, 아래와 같이 에러 없이 제대로 실행되는 모습을 볼 수 있다.
굳이 필요하나요?
- 실제 실무 프로젝트에서는 다양한 출력 결과물이 필요하고, 원하는 테스트 결과가 나오는 지 확인하는 과정은 필수적인 부분이다.
- TDD를 활용하면, 처음 시작하는 단계에서 테스트케이스를 설계하기 위한 초기 비용이 확실히 더 들게 된다. 하지만 개발 과정에 있어서 '초기 비용'보다 '유지보수 비용'이 더 클 수 있다는 것을 명심하자
- 또한 안전성이 필요한 소프트웨어 프로젝트에서는 개발 초기 단계부터 확실하게 다져놓고 가는 것이 중요하다.
- 유지보수 비용이 더 크거나 비행기, 기차에 필요한 소프트웨어 등 안전성이 중요한 프로젝트의 경우 현재 실무에서도 TDD를 활용한 개발을 통해 이루어지고 있다.
3. 애자일(Agile)
-
등장 배경
-
초기 소프트웨어 개발 방법은 계획 중심의 프로세스였다.
-
여러 단계로 나누어 세부적으로 계획을 짜고 하나의 단계를 끝마치면 다음 단계를 하는 Water Fall 방식으로 진행했다.
-
하지만 90년대 이후 소프트웨어 분야가 넓어지면서 사용자들이 '일반 대중'으로 바뀌기 시작했다. 또한 기술의 발전으로 빠르게 시대의 흐름에 맞는 프로그램을 개발해야했고 트렌드가 급격하게 빨리 변화하는 시대가 도달했다.
-
따라서 비즈니스 사이클이 짧아졌고, 빠르게 SW를 개발하고 중간에 수정도 자주 해야했다.
-
-
-
규칙을 적게 만들고, 가볍게 대응을 잘 하는 방법을 적용
-
'협력'과 '피드백'을 자주하고, 일찍하고, 잘 해야한다.
-
목표를 세분화 하고, 각자 맡은 역할을 동시에 진행
협력
소프트웨어를 개발한 사람들 안에서의 협력을 말한다. 개발자 끼리 만이 아니라 프로젝트에 참여한 모든 사람들의 협력이다.
-
좋은 일은 x2가 된다.
-
어떤 사람이 2배의 속도로 개발할 수 있는 방법을 발견
-
협력이 약하면?
→ 혼자만 좋은 보상과 칭찬을 받음. 하지만 그 사람 코드와 다른 사람의 코드의 이질감이 생겨서 시스템 문제 발생 가능성
-
협력이 강하면?
→ 다른 사람과 공유해서 모두 같이 빠르게 개발하고 더 나은 발전점을 찾기에 용이함. 팀 전체 개선이 일어나는 긍정적 효과 발생
-
-
안 좋은 일은 /2가 된다.
-
문제가 발생하는 부분을 찾기 쉬워짐
-
예상치 못한 문제를 협력으로 막을 수 있음
- 실수를 했는데 어딘지 찾기 힘들거나, 개선점이 생각나지 않을 때 서로 다른 사람들과 협력하면 새로운 방안이 탄생할 수도 있음
-
2. 피드백
-
학습의 가장 큰 전제 조건인 피드백
- 자신이 어떻게 했는지 피드백하면서 학습을 진행해야한다. 여러 사람에게 피드백을 받으며 모르는 것을 더 빨리 배워나간다.
-
내부적 피드백
- 내가 만든 것이 어떻게 됐는지 확인한다.
-
외부적 피드백
- 다른 고객이나 다른 부서가 사용해보고 나온 산출물을 통해 피드백을 받는다.
3. 불확실성
-
애자일에서 핵심은 '불확실성'이다.
- 불확실성이 높으면 '우리가 생각한거랑 다르다...'라는 상황에 직면한다.
-
애자일 방법론은 이러한 불확실성에 기존의 방법보다 유연하게 대처할 수 있다.
전통적 방법론
- '그때 계획 세울 때 좀 더 잘 세워둘껄..
이런 리스크도 생각했어야 했는데, 일단 계속 진행하자'
-
애자일 방법론
-
'이건 생각 못했네. 어쩔 수 없지. 다시 빨리 수정해보자'
진행 방법
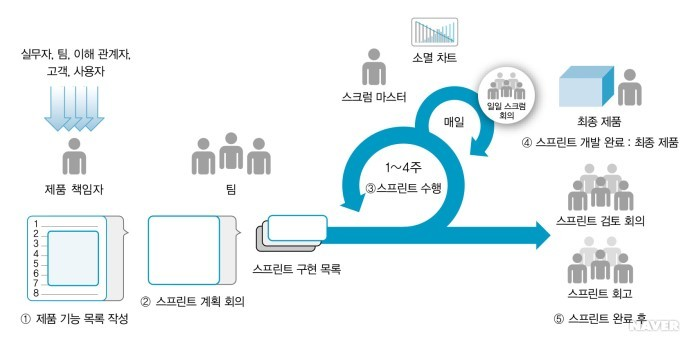
-
개발자와 고객 사이의 지속적 커뮤니케이션을 통해 변화하는 요구사항을 수용한다.
-
고객이 결정한 사항을 가장 우선으로 시행하고, 개발자 개인의 가치보다 팀의 목표를 우선으로 한다.
-
팀원들과 주기적인 미팅을 통해 프로젝트를 점검한다.
-
주기적으로 제품 시현을 하고 고객으로부터 피드백을 받는다.
-
프로그램 품질 향상에 신경쓰며 간단한 내부 구조 형성을 통한 비용절감을 목표로 한다.
제품 기능 목록 작성
개발할 제품에 대한 요구사항 목록을 작성한다.
-
우선 순위를 매겨, 사용자의 요구사항을 최대한 먼저 반영한다.
-
개발 중 수정이 가능하지만, 보통은 한 주기가 끝날때까지는 제품 기능 목록을 수정하지 않는다.
스프린트 Backlog
스프린트 각각의 목표에 도달하기 위해 필요한 작업 목록이다.
-
세부적으로 어떤 것을 구현해야하는지 작성한다.
-
작업자를 작성한다.
-
예상 작업 시간을 작성한다.
→ 최종적으로 개발이 어떻게 진행되고 있는지 확인하는 수단이다.
스프린트
팀원들과 토론을 통해 도출된 아이디어를 단기간 내에 프로토타입으로 제작하고 테스트하여 중요한 문제들에 대한 답을 찾아가는 과정이다.
-
작은 단위의 개발 업무를 단기간 내에 전력으로 개발한다.
-
한달 동안의 큰 계획을 3~5일 단위로 반복 주기를 정했다면 이것이 스크럼에서 스프린트에 해다한다.
-
이 주기가 결정되었다면(보통 2~4주) 목표와 내용이 개발 도중에 바뀌지 않아야 하고, 팀원들 동의 없이 바꿀 수 없다.
스크럼(scrum)
프로젝트 관리를 위한 상호 점진적 개발 방법론
-
모든 팀원이 참석하여 매일, 짧게(15분)정도 회의를하고, 진행 상황을 점검한다.
-
한 사람씩 어제 한 일, 오늘 할 일, 문제점 및 어려운 점을 이야기한다.
-
완료된 세부 작업 항목을 스프린트 현황판에 업데이트한다.
제품 완성 및 스프린트 검토 회의
-
모든 스프린트 주기가 끝나면, 제품 기능 목록에서 작성한 제품이 완성된다.
-
최종 제품이 나오면 고객 앞에서 시연을 통해 스프린트 검토 회의를 진행한다.
- 고객의 요구사항이 잘 만족됐는가?
- 개선점 및 피드백
스프린트 회고
-
스프린트에서 수행한 활동과 개발한 것을 되돌아보며 개선점이나 규칙 및 표준을 잘 준수했는지 검토한다.
-
팀의 단점보다는 강점과 장점을 찾아 더 극대화하는데 초점을 둔다.
4. 객체 지향 프로그래밍(Object-Oriented Programming)
객체 지향 프로그래밍은 현실 세계에 초점을 둔 프로그래밍 방식이다.
-
절차 지향 방식과 대비되는데 절차 지향은 컴퓨터의 입장에서 코드가 실행되기때문에 더 빠르지만 코드의 재사용, 디버깅 등을 하기 힘들고 코드가 직관적이지 않다.
-
객체지향 프로그래밍은 중복코드의 양이 줄어들고 유지보수에 유리하다.
객체지향에서 가장 큰 특징은 바로 Class와 Instance이다.
- 이 둘을 흔히 붕어빵 기계와, 붕어빵으로 얘기하는데 붕어빵 기계에서 붕어빵이라는 객체를 찍어내기 때문에 이렇게 비유하는 것 같다.
객체 지향 프로그래밍 특징
객체 지향 프로그래밍은 다음의 4가지 특징을 갖추고 있다.
- 이 특성들을 잘 이해하고 구현해야 객체를 통한 효율적인 구현이 가능하다.
-
추상화(Abstraction)
-
필요로 하는 속성이나 행동을 추출하는 작업
-
추상적인 개념에 의존하여 설계해야 유연함을 갖출 수 있다.
- 즉, 세부적인 사물들의 공통적인 특징을 파악한 후 하나의 집합으로 만들어내는 것이 추상화다
-
ex)아우디, BMW, 벤츠는 모두 '자동차'라는 공통점이 있다.
- 자동차라는 추상화 집합을 만들어두고, 자동차들이 가진 공통적인 특징들을 만들어 활용한다.`
예를 들면, '현대'와 같은 다른 자동차 브랜드가 추가될 수도 있다. 이때 추상화로 구현해두면 다른 곳의 코드는 수정할 필요 없이 추가로 만들 부분만 새로 생성해주면 된다.
- 즉 새로 생기는 객체에 유연함을 제공한다.
-
-
캡슐화(Encapsulation)
-
낮은 결합도를 유지할 수 있도록 설계하는 것
-
쉽게 말하면, 한 곳에서 변화가 일어나도 다른 곳에 미치는 영향을 최소화 시키는 것을 말한다.
- 객체가 내부적으로 기능을 어떻게 구현하는지 감추는 것
결합도가 낮도록 만들어야 하는 이유가 무엇일까?
결합도(coupling)란, 어떤 기능을 실행할 때 다른 클래스나 모듈에 얼마나 의존적인가를 나타내는 말이다.
- 즉, 독립적으로 만들어진 객체들 간의 의존도가 최대한 낮게 만드는 것이 중요하다. 객체들 간의 의존도가 높아지면 굳이 객체 지향으로 설계하는 의미가 없어진다.
-
우리는 소프트웨어 공학에서 객체 안의 모듈 간의 요소가 밀접한 관련이 있는 것으로 구성하여 응집도를 높이고 결합도를 줄여야 요구사항 변경에 대처하는 좋은 설계 방법이라고 배운다.
- 이것이
캡슐화와 크게 연관된 부분이라고 할 수 있다.
- 이것이
그렇다면, 캡슐화는 어떻게 높은 응집도와 낮은 결합도를 갖게 할까?
바로 정보 은닉을 활용한다.- 외부에서 접근할 필요가 없는 것들은 private으로 접근하지 못하도록 제한을 두는 것이다.
(객체안의 필드를 선언할 때 private으로 선언하라는 말이 바로 이 때문이다.)
-
-
상속
-
일반화 관계(Generalization)라고도 하며, 여러 개체들이 지닌 공통된 특성을 부각시켜 하나의 개념이나 법칙으로 성립하는 과정
-
일반화(상속)은 또 다른 캡슐화다.
-
자식 클래스를 외부로부터 은닉하는 캡슐화의 일종이라고 말할 수 있다.
-
자동차를 통해 예를 들어 추상화를 설명했었다.
여기에 추가로 대리 운전을 하는 사람 클래스가 있다고 생각해보자.
이때, 자동차의 자식 클래스에 해당하는 벤츠, BMW, 아우디 등은 캡슐화를 통해 은닉해둔 상태다.- 사람 클래스의 관점으로는, 구체적인 자동차의 종류가 숨겨져 있는 상태다. 대리 운전자 입장에서는 자동차의 종류가 어떤 것인지는 운전하는데 크게 중요하지 않다.
- 새로운 자동차들이 추가된다고 해도, 사람 클래스는 영향을 받지 않는 것이 중요하다. 그러므로 캡슐화를 통해 사람 클래스 입장에서는 확인할 수 없도록 구현하는 것이다.
-
상속 관계에서는 단순히 하나의 클래스 안에서 속성 및 연산들의 캡슐화에 한정되지 않는다. 즉, 자식 클래스 자체를 캡슐화하여 '사람 클래스'와 같은 외부에 은닉하는 것으로 확장되는 것이다.
-
이처럼 자식 클래스를 캡슐화해두면, 외부에선 이러한 클래스들에 영향을 받지 않고 개발을 이어갈 수 있는 장점이 있다.
-
- 상속 재사용의 단점
-
상위 클래스(부모 클래스)의 변경이 어려워진다.
-
부모 클래스에 의존하는 자식 클래스가 많을 때, 부모 클래스의 변경이 필요하다면?
- 이를 의존하는 자식 클래스들이 영향을 받게 된다.
-
-
불필요한 클래스가 증가할 수 있다.
- 유사기능 확장시, 필요 이상의 불필요한 클래스를 만들어야 하는 상황이 발생할 수 있다.
- 유사기능 확장시, 필요 이상의 불필요한 클래스를 만들어야 하는 상황이 발생할 수 있다.
-
상속이 잘못 사용될 수 있다.
-
같은 종류가 아닌 클래스의 구현을 재사용하기 위해 상속을 받게 되면, 문제가 발생할 수 있다. 상속 받는 클래스가 부모 클래스와 IS-A 관계가 아닐 때 이에 해당한다.
-
ex) BMW is a Car → IS-A 관계 / 오토바이와 차 → IS-A 관계 아님 (근데 시동 이런거 재사용하고싶음)
-
-
해결책은?
-
객체 조립(Composition), 컴포지션이라고 부르기도 한다.
-
객체 조립은, 필드에서 다른 객체를 참조하는 방식으로 구현된다.
-
상속에 비해 비교적 런타임 구조가 복잡해지고, 구현이 어려운 단점이 존재하지만 변경 시 유연함을 확보하는데 장점이 매우 크다.
- 따라서 같은 종류가 아닌 클래스를 상속하고 싶을 때는 객체 조립을 우선적으로 적용하는 것이 좋다.
-
-
-
그럼 상속은 언제 사용?
-
IS-A 관계가 성립할 때
-
재사용 관점이 아닌, 기능의 확장 관점일 때
-
-
- 다형성(Polymorphism)
-
서로 다른 클래스의 객체가 같은 메시지를 받았을 때 각자의 방식으로 동작하는 능력
- 객체 지향의 핵심과도 같은 부분이다.
-
다형성은, 상속과 함께 활용할 때 큰 힘을 발휘한다.
-
이와 같은 구현은 코드를 간결하게 해주고, 유연함을 갖추게 해준다.
-
즉, 부모 클래스의 메소드를 자식 클래스가 오버라이딩해서 자신의 역할에 맞게 활용하는 것이 다형성이다.
-
-
이처럼 다형성을 사용하면, 구체적으로 현재 어떤 클래스 객체가 참조되는 지는 무관하게 프로그래밍하는 것이 가능하다.
- 상속 관계에 있으면, 새로운 자식 클래스가 추가되어도 부모 클래스의 함수를 참조해오면 되기 때문에 다른 클래스는 영향을 받지 않게 된다.
시동 이라는 행위를 어떤 것은 키로하고, 어떤 것은 버튼으로 하고 이렇게 자기한테 맞게 다형성 할 수있다.
-
5. 함수형 프로그래밍(Fuctional Programming)
프로그래밍 패러다임(Programming Paradigm)
-
프로그래머에게 프로그래밍의 관점을 갖게 하고 코드를 어떻게 작성할 지 결정하는 역할을 한다.
-
새로운 프로그래밍 패러다임을 통해서는 새로운 방식으로 생각하는 법을 배우게 되고, 이를 바탕으로 코드를 작성하게 된다.
-
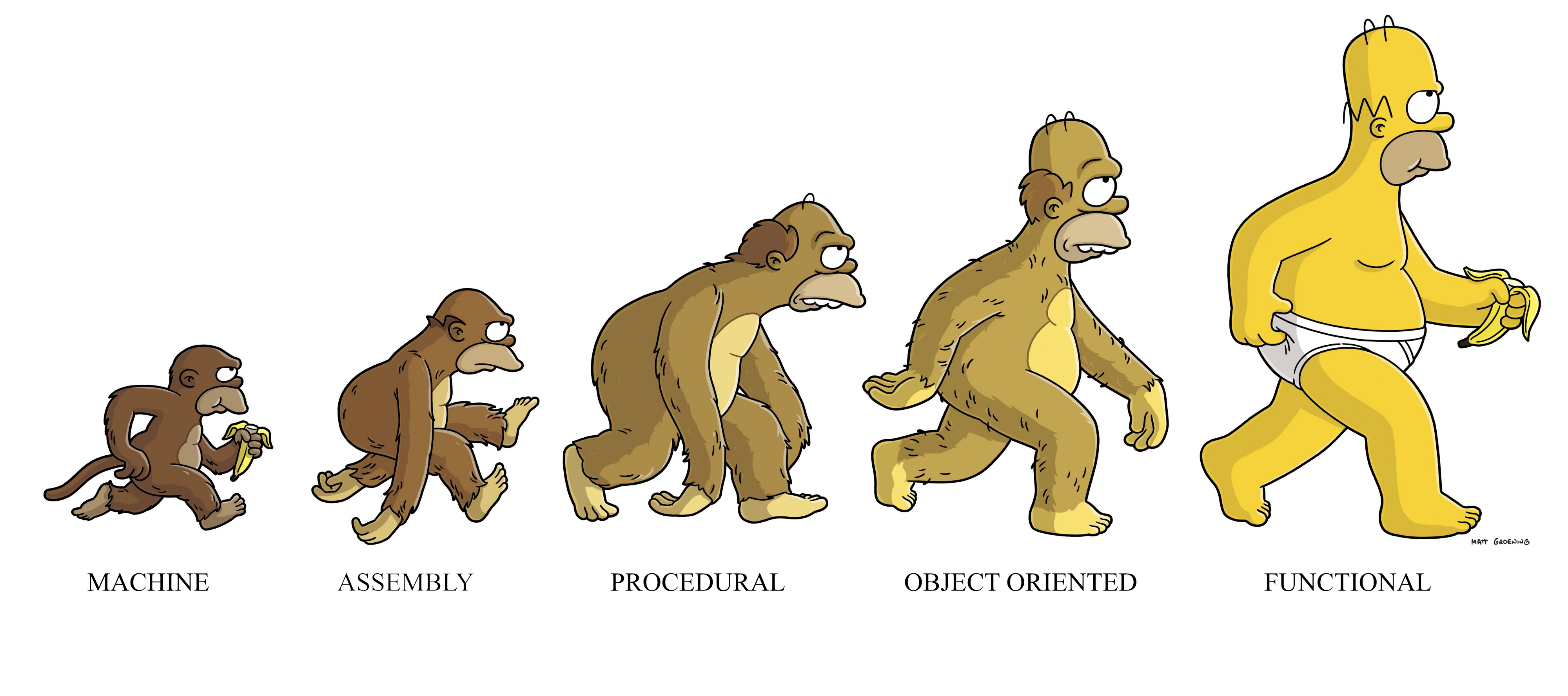
최근의 프로그래밍 패러다임은 크게 아래와 같이 구분할 수 있다.
-
명령형 프로그래밍: 무엇(What)을 할 것인지 나타내기보다 어떻게(How) 할 건지를 설명하는 방식
-
절차지향 프로그래밍: 수행되어야 할 순차적인 처리 과정을 포함하는 방식 (C, C++)
-
객체지향 프로그래밍: 객체들의 집합으로 프로그램의 상호작용을 표현 (C++, Java, C#)
-
-
선언형 프로그래밍: 어떻게 할건지(How)를 나타내기보다 무엇(What)을 할 건지를 설명하는 방식
- 함수형 프로그래밍: 순수 함수를 조합하고 소프트웨어를 만드는 방식 (클로저, 하스켈, 리스프)
-
-
명령형 프로그래밍을 기반으로 개발했던 개발자들은 개발하는 소프트웨어의 크기가 커짐에 따라, 복잡하게 엉켜있는 스파게티 코드를 유지보수하는 것이 매우 힘들다는 것을 깨닫게 되었다.
-
이를 해결하기 위해 함수형 프로그래밍이라는 프로그래밍 패러다임에 관심을 갖게 되었다.
-
함수형 프로그래밍은 거의 모든 것을 순수 함수로 나누어 문제를 해결하는 기법으로, 작은 문제를 해결하기 위한 함수를 작성하여 가독성을 높이고 유지보수를 용이하게 해준다.
-
유명한 책인 클린 코드(Clean Code)의 저자 Robert C.Martin은 함수형 프로그래밍을 대입문이 없는 프로그래밍이라고 정의하였다.
"Functional Programming is programming without assignment satements"
- 명령형 프로그래밍은 다음과 같이 간단한 코드에서도 변수가 할당되고, 값이 대입된다.
// 1 ~ 10까지의 값이 i에 할당된다
for(int i = 1 ; i < 10; i++){
System.out.println(i);
}
함수형 프로그래밍
-
함수형 프로그래밍은 대입문을 사용하지 않는 프로그래밍이며, 작은 문제를 해결하기 위한 함수를 작성한다고 설명하였다.
- 함수형 프로그래밍에서는 위와 같은 코드를 다음과 같이 해결할 수 있다.
process(10, print(num));
process함수는 첫 번째 인자로 몇까지 iteration을 돌 것인가를 매개변수로 받고 있고, 두 번째 인자로 전달받은 값을 출력하라는 함수를 매개변수로 받고 있다.
-
함수형 프로그래밍에서는 '출력을' 하는 함수를 파라미터로 넘길 수 있다.
- 이는 함수형 프로그래밍의 기본 원리 중 함수를 1급 시민(First-Class Citizen) 또는 1급 객체(First-Class Object)로 관리하는 특징 때문
-
명령형 프로그래밍에서는 메소드를 호출하면 상황에 따라 내부의 값이 바뀔 수 있다.
-
즉, 우리가 개발한 함수 내에서 선언된 변수의 메모리에 할당된 값이 바뀌는 등의 변화가 발생할 수 있다.
-
하지만 함수형 프로그래밍에서는 대입문이 없기 때문에 메모리에 한 번 할당된 값은 새로운 값으로 변할 수 없다.
-
함수형 프로그래밍(Functional Programming)의 특징
부수 효과가 없는 순수 함수를 1급 객체로 간주하여 파라미터로 넘기거나 반환값으로 사용할 수 있으며, 참조 투명성을 지킬 수 있다.
-
여기서 부수효과(Side Effect)란 다음과 같은 변화 또는 변화가 발생하는 작업을 의미한다.
-
변수의 값이 변경됨
-
자료 구조를 제자리에서 수정함
-
객체의 필드값을 설정함
-
예외나 오류가 발생하며 실행이 중단됨
-
콘솔 또는 파일 I/O가 발생함
-
-
부수 효과(Side Effect)들을 제거한 함수들을 순수 함수(Pure Function)이라고 부르며, 함수형 프로그래밍에서 사용하는 함수는 이러한 순수 함수들이다.
-
Memory or I/O의 관점에서 Side Effect가 없는 함수
-
함수의 실행이 외부에 영향을 끼치지 않는 함수
-
-
순수 함수(Pure Function)를 통해 얻을 수 있는 효과
-
함수 자체가 독립적이며 Side-Effect가 없기 때문에 Thread에 안전성을 보장받을 수 있다.
-
Thread에 안정성을 보장받아 병렬 처리를 동기화 없이 진행할 수 있다.
-
-
1급 객체란 다음과 같은 것들이 가능한 객체를 의미한다.
-
변수나 데이터 구조 안에 담을 수 있다.
-
파라미터로 전달 할 수 있다.
-
반환값으로 사용할 수 있다.
-
할당에 사용된 이름과 무관하게 고유한 구별이 가능하다.
-
함수형 프로그래밍에서 함수는 1급 객체로 취급받기 때문에 위의 예제에서 본 것 처럼 함수를 파라미터로 넘기는 등의 작업이 가능한 것이다.
우리가 일반적으로 알고 개발했던 함수들은 함수형 프로그래밍에서 정의하는 순수 함수들과는 다르다는 것을 인지해야 한다.
-
참조 투명성(Referential Transparency)이란 다음과 같다.
-
동일한 인자에 대해 항상 동일한 결과를 반환해야 한다.
- 참조 투명성을 통해 기존의 값은 변경되지 않고 유지된다.(Immutable Data)
-
-
명령형 프로그래밍과 함수형 프로그래밍에서 사용하는 함수는 부수효과의 유/무에 따라 차이가 있다.
-
함수가 참조에 투명한지 안한지 나뉘어 지는데, 참조에 투명하다는 것은 말 그대로 함수를 실행하여도 어떠한 상태의 변화 없이 항상 동일한 결과를 반환하여 항상 동일하게(투명하게) 실행 결과를 참조(예측)할 수 있다는 것을 의미한다.
-
즉, 어떤 함수 f에 어떠한 인자 x를 넣고 f를 실행하게 되면, f는 입력된 인자에만 의존하므로 항상 f(x)라는 동일한 결과를 얻는다는 것을 의미한다.
-
부작용을 제거하여 프로그램의 동작을 이해하고 예측을 용이하게 하는 것은 함수형 프로그래밍으로 개발하려는 핵심 동기 중 하나이다.
-
병렬 처리 환경에서 개발할 때 Race Condition에 대한 비용을 줄여준다.
- 함수형 프로그래밍에서는 값의 대입이 없이 항상 동일한 실행에 대해 동일한 결과를 반환하기 때문이다.
-
-
Java를 이용한 함수형 프로그래밍(Functional Programming) 예시
- 어떤 List에 저장된 단어들의 접두사가 각각 몇개씩 있는지를 Map으로 저장하는 코드를 작성해보도록 하자.
< 함수형을 적용하지 않은 코드 >
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class WordCount {
private static List<String> WORDS = Arrays.asList("TONY", "a", "hULK", "B", "america", "X", "nebula", "Korea");
private static Map<String, Integer> wordPrefixFreq() {
Map<String, Integer> wordCountMap = new HashMap<>();
String prefix;
Integer count;
for (String word : WORDS) {
prefix = word.substring(0, 1);
count = wordCountMap.get(prefix);
if (count == null) {
wordCountMap.put(prefix, 1);
} else {
wordCountMap.put(prefix, count + 1);
}
}
return wordCountMap;
}
public static void main(String[] args) {
final Map<String, Integer> map = wordPrefixFreq();
map.keySet().forEach(k -> System.out.println(k + ": " + map.get(k)));
}
}
-
함수형 프로그래밍을 적용하지 않은 코드에서는 List를 루프를 돌면서 접두사를 잘라내고 그 갯수를 Map에 저장하고 있다.
- 위의 코드는 최선일 것 같아 보이지만 함수형 프로그래밍 기법을 적용하면 더욱 간결하고 가독성있게 코드를 변경할 수 있다.
< 함수형을 적용한 코드 >
-
Java는 대표적인 객체지향 프로그래밍 언어이다.
-
그렇기 때문에 함수형으로 개발을 하기 위해서는 별도의 도구가 필요한데, Java 같은 경우에는 함수형 프로그래밍을 위해 JDK8부터 Stream API와 함수형 인터페이스(Functional Interface) 등을 제공하고 있다.
- Java 8 이상의 버전을 사용해야 아래와 같은 코드 리팩토링이 가능하다.
-
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class WordCount {
private static List<String> WORDS = Arrays.asList("TONY", "a", "hULK", "B", "america", "X", "nebula", "Korea");
private static Map<String, Integer> wordPrefixFreq() {
Map<String, Integer> wordCountMap = new HashMap<>();
WORDS.stream().map(w -> w.substring(0, 1)).forEach(prefix -> wordCountMap.merge(prefix, 1, (oldValue, newValue) -> (newValue += oldValue)));
return wordCountMap;
}
public static void main(String[] args) {
final Map<String, Integer> map = wordPrefixFreq();
map.keySet().forEach(k -> System.out.println(k + ": " + map.get(k)));
}
}
-
stream()을 통해 함수형 프로그래밍을 위한 Stream 객체를 생성하고 -
map()을 통해 Stream 객체의 단어들을 prefix로 변형시키고 있다. -
forEach를 통해서 prefix를 보고 map에 값을 추가하고 있다.
이제 만약 기존의 문제에 다음과 같은 추가 요구 사항이 생겼다고 가정하여 보자.
-
단어의 크기가 2 이상인 경우에만 처리를 할 것
-
모든 단어를 대문자로 변환하여 처리를 할 것
-
스페이스로 구분한 하나의 문자열로 변환 할 것
이러한 요구 사항을 기존의 함수형 적용 이전의 코드에 반영한다고 하면 코드가 상당히 길어지고, 복잡해질 것이다.
하지만 함수형 프로그래밍을 적용한다면 해당 요구사항들 역시 비교적 간단하게 처리할 수 있다.
import java.io.IOException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class Main {
private static List<String> WORDS = Arrays.asList("TONY", "a", "hULK", "B", "america", "X", "nebula", "Korea");
public static String wordPrefixFreq() {
return WORDS.stream().filter(w -> w.length() > 1).map(String::toUpperCase).map(w -> w.substring(0, 1)).collect(Collectors.joining(" "));
}
public static void main(String[] args) throws IOException {
final String result = wordPrefixFreq();
System.out.println(result);
}
}Java는 객체지향의 언어이기 때문에 Java에서 함수형 프로그래밍을 하기 위해서는 관련 자바의 API를 알아야 한다. 추가적으로 관련 내용을 학습하기 원한다면 StreamAPI 포스팅을 참고하기 바란다.
6. 데브옵스(DevOps)
-
Development + Operation
-
개발담당자와 운영담당자가 연계하여 협력하는 개발 방법론
-
데브옵스 DevOps는 개발(development)과 운영(operation)을 결합해 탄생한 개발 방법론 입니다.
- 시스템 개발자와 운영을 담당하는 정보기술 전문가 사이의 소통, 협업, 통합 및 자동화를 강조하는 소프트웨어 개발 방법론
이러한 데브옵스의 개념은 애자일 소프트웨어(Agile software) 개발과 지속적인 통합(Continuous integration) 등의 개념과도 관련이 있습니다.
-
애자일 소프트웨어 개발 (Agile software development)
-
애자일 개발 프로세스
- 익스트림 프로그래밍, 스크럼, 크리스털 패밀리, 익스트림 모델링
-
계획과 문서를 기반으로 개발 모형이나 모델에 따라 앞을 예측하며 개발하는 것이 아니라, 실질적인 코딩을 기반으로 일정한 주기에 따라 계속적으로 프로토타입을 형성하고 필요한 요구사항을 파악하며 이에 따라 즉시 수정사항을 적용하여 결과적으로 하나의 큰 소프트웨어를 개발하는 적응형 개발 방법
-
지속적인 통합 (Continuous integration)
-
개발 초기부터 실행이 가능한 상태로 코드를 유지하는 것
-
퀄리티 컨트롤을 적용하는 프로세스
-
소프트웨어의 질적 향상과 소프트웨어를 배포하는데 걸리는 시간을 줄인다
-
데브옵스 DevOps는 쉽게 말해 개발부서와 운영부서 간의 원활한 소통을 기반으로 합니다.
-
개발 부서에서 웹사이트 개발, 앱 개발, 그리고 알고리즘 개발을 한다면 운영 부서에서는 개발된 아이템이 고객에게 잘 전달되도록 하는 부서입니다.
- 운영팀에서 고객의 수요에 맞춰 서버와 데이터베이스를 관리하는 일을 통해 서비스가 제대로 돌아갈 수 있는 환경을 개발팀에게 제공할 수 있는 것입니다.
-
데브옵스 DevOps의 이점
-
속도
- 작업 속도가 빨라지면서 시장 변화에 더 잘 적응하고 효율적으로 비즈니스 성과를 창출할 수 있음
-
신속한 제공
- 새로운 기능의 릴리스와 버그 수정 속도가 빨라질수록 경쟁 우위를 차지할 수 있음
-
안정성
- 애플리케이션 업데이트와 인프라 변경의 품질 보장, 지속적 통합 및 지속적 전달과 같은 방식을 통해 변경 사항이 제대로 안전하게 작동하는지 테스트 가능
-
확장 가능
- 규모에 따라 인프라와 개발 프로세스 운영, 관리 가능
-
협업 강화
- 개발자와 운영 부서 간의 협력을 통해 효과적인 팀 구축 가능
-
보안
- 자동화된 규정 준수 정책, 세분화된 제어 및 구성 관리 기술 사용 가능
데브옵스는 현재 우아한 형제들, 스마트 스터디와 같은 알려진 기업이나 대기업에서 많은 채용이 일어나고 있습니다.
- 데브옵스엔지니어는 개발도 가능하고 운영도 가능해야 한다.
- DevOps에 도전하기 위해서는 개발 능력 뿐만 아니라 네트워크, 시스템엔지니어의 기초를 알아야 합니다.
- 따라서 개발 + 인프라 공부를 하면 됩니다.
- 개발자로 직무를 선택하더라도 인프라에 대한 지식을 가지고 있다면 데브옵스엔지니어가 되지 않더라도 다양한 분야에 활용이 가능하기 때문에 공부를 해두면 좋습니다.
7. 서드 파티(3rd party)란?
-
경제 용어가 IT에서 쓰이는 부분이다.
-
하드웨어 생산자와 소프트웨어 개발자의 관계를 나타낼 때 사용한다.
-
그 중에서 서드파티는, 프로그래밍을 도와주는 라이브러리를 만드는 외부 생산자를 뜻한다.
ex) 게임제조사와 소비자를 연결해주는 게임회사(퍼플리싱) 스마일게이트와 같은 회사
-
- 즉 서드파티는 다른 회사 제품에 이용되는 소프트웨어나 하드웨어를 개발하는 회사를 말한다.
-
개발자 측면
-
하드웨어 생산자가 '직접' 소프트웨어를 개발하는 경우 : 퍼스트 파티 개발자
-
하드웨어 생산자인 기업과 자사간의 관계(또는 하청업체)에 속한 소프트웨어 개발자 : 세컨드 파티 개발자
-
아무 관련없는 제3자 소프트웨어 개발자 : 서드 파티 개발자
-
- 주로 편한 개발을 위해 플러그인이나 라이브러리 혹은 프레임워크를 사용하는데, 이처럼 제 3자로 중간다리 역할로 도움을 주는 것이 서드 파티로 볼 수 있고, 이런 것을 만드는 개발자가 서드 파티 개발자다.
8. 마이크로서비스 아키텍처(MSA)
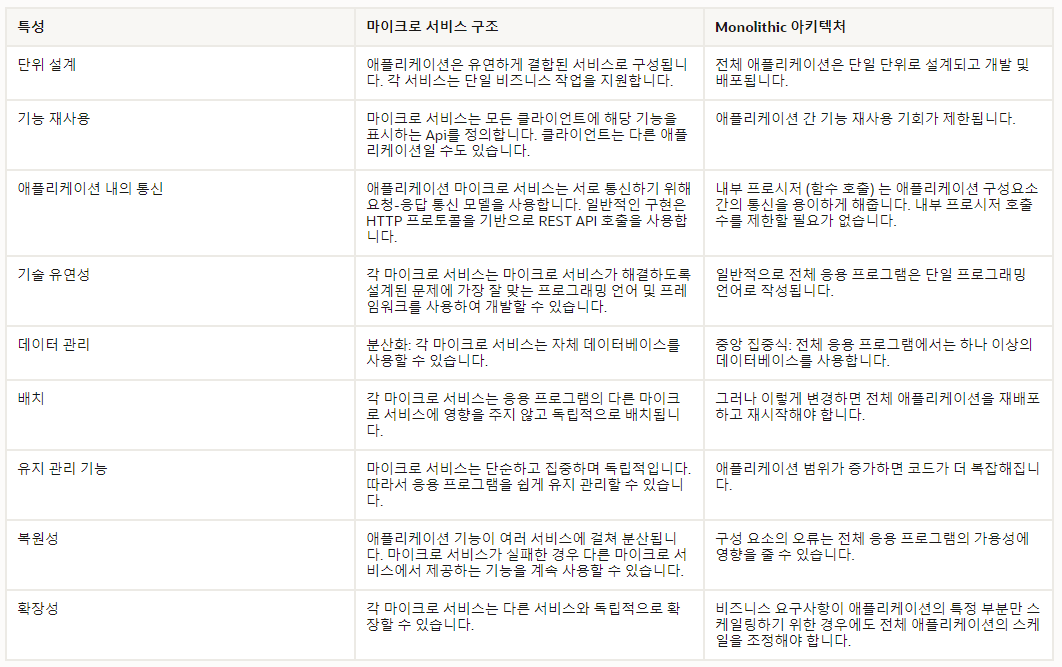
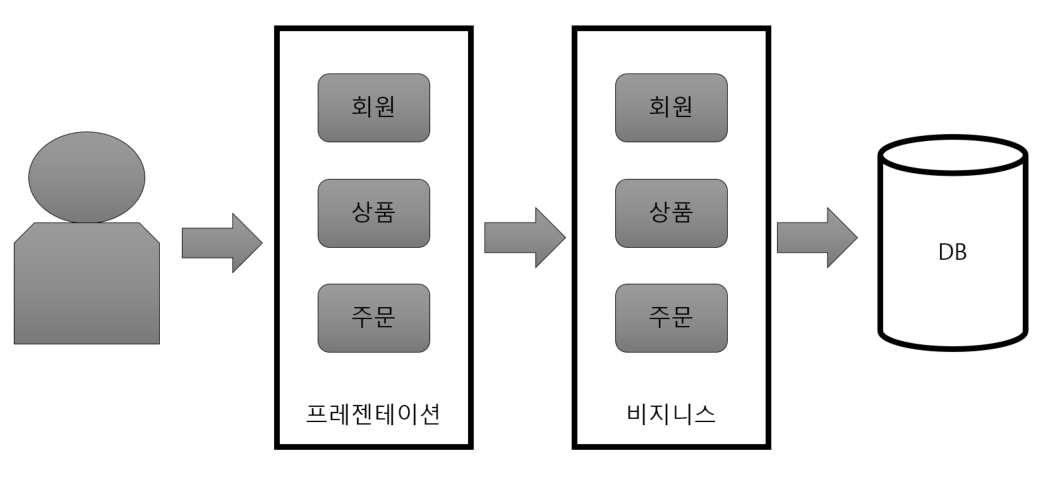
모노리틱 아키텍처
-
기존에 우리가 사용하던 전통적인 방식의 개발 방법을 모노리틱 아키텍처 스타일이라고 합니다.
- 한 덩어리의 구조라고 볼 수 있습니다.
-
전체 애플리케이션이 하나로 되어있어서 보통 동일한 개발 툴을 사용해 개발되며, 배포 및 테스트도 하나의 애플리케이션만 수행하면 되기 때문에 개발 및 환경설정이 간단합니다.
-
각 컴포넌트들이 함수로 호출 되기 때문에 성능에 제약이 덜하고, 운영 관리가 용이합니다.
-
이런 장점 때문에 작은 볼륨의 시스템을 개발할 때는 매우 유용하지만 시스템이 커지기 시작하고 여러 컴포넌트들이 더해지면 문제가 발생하기 시작합니다.
-
빌드/테스트 시간이 길어집니다.
-
작은 수정에도 시스템 전체를 빌드해야 하며, 테스트 시간도 길어집니다.
-
요즘처럼 CI/CD((Continuous Integration / (Continuous Delivery)가 강조되는 시점에서는 큰 문제가 될 수 있습니다.
-
-
선택적 확장이 불가능합니다.
- 이벤트로 인해 서비스 접속량이 폭증할 경우 프로젝트 전체를 확장해야만 합니다.
-
하나의 서비스가 모든 서비스에 영향을 줍니다.
- 이벤트 서비스에 트래픽이 몰려 해당 서버가 죽게 된다면 다른 모든 서비스 역시 마비 되는 상황이 오게 됩니다.
-
MSA (Micro Service Architecture)
-
MSA란 마이크로 서비스 아키텍처(Micro Service Architecture)의 약자로 단일 프로그램을 각 컴포넌트 별로 나누어 작은 서비스의 조합으로 구축하는 방법입니다.
- 즉 MSA는 소프트웨어 개발 기법 중 하나로, 애플리케이션 단위를 '목적'으로 나누는 것입니다.
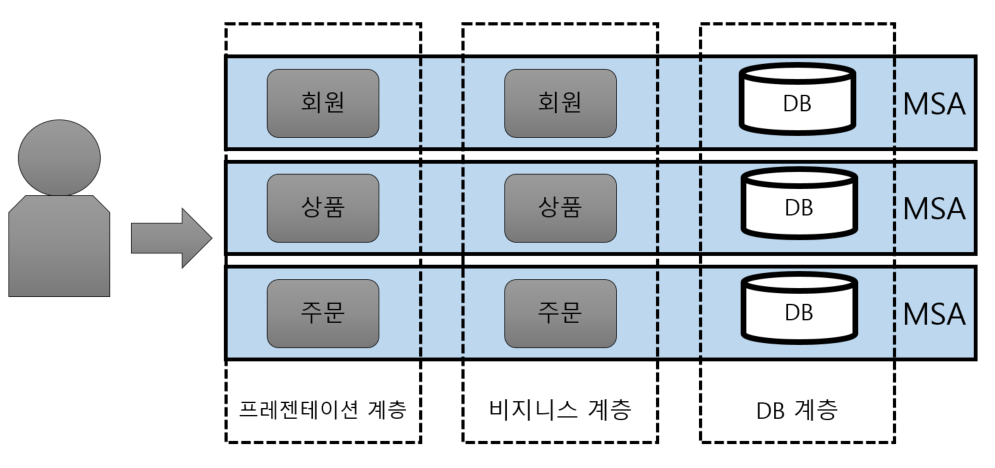
-
각 컴포넌트는 서비스 형태로 구현되고 API를 이용하여 타 서비스와 통신하게 됩니다.
-
각 서비스는 독립된 서버로 타 컴포넌트와 의존성이 없기 때문에 독립된 배포를 하게 됩니다.
-
각 컴포넌트가 독립된 서비스로 개발되어있기 때문에 부분적인 확장이 가능합니다.
- 온라인 쇼핑몰에서 주문 서비스에 트래픽이 증가한다면 해당 서버만 확장을 해주면 됩니다.
-
단점
-
MSA의 경우 서비스간 호출을 API통신을 이용하기 때문에 속도가 느리다.
- 모노리틱 아키텍처는 서비스간의 호출이 하나의 프로세스 내에서 이루어지기 때문에 속도가 빠르다.
-
통신에 사용하기 위해 값을 데이터 모델로 변환시켜주는 오버헤드가 발생하기도 한다.
-
MSA의 특징
1. 데이터 분리
-
데이터 저장 시 하나의 DB에 중앙 집중화를 하지 않고 서비스 별 별도의 데이터 베이스를 사용합니다.
-
DB의 종류를 별도로 가져갈 수도 있고, 같은 DB를 사용하더라도 나누어서 사용하게 됩니다.
-
데이터가 분산되어있기 때문에 다른 서비스 컴포넌트에 대한 의존성이 없이 서비스를 독립적으로 개발 및 배포/운영 할 수 있다.
- 다른 컴포넌트의 데이터를 API통신을 통해 가져와야 하기 때문에 성능상의 문제가 발생 할 수 있고, 트렌젝션으로 묶을 수 없는 문제가 발생하기도 합니다.
2. API Gateway
-
MSA의 문제점 중 하나는 각 서비스가 다른 서버에 분리 배포되어있기 때문에 서버 URL이 각기 다를 수 밖에 없습니다.
- 이때 API Gateway는 API 서버 앞 단에서 모든 API 서버들의 End-Point를 단일화하여 묶어주는 역할을 합니다.
-
또한 거미줄처럼 복잡한 서비스간의 API호출 구조도 단순화 시켜줍니다.
-
그 외에 라우팅, 로드밸런싱, 인증 역할 등등 여러 역할을 수행합니다.
3. 팀의 변화
-
기존의 팀 모델은 역할별로 나누어진 모델로 팀을 구분했습니다.
-
모노리틱 아키텍처에서의 팀 모델
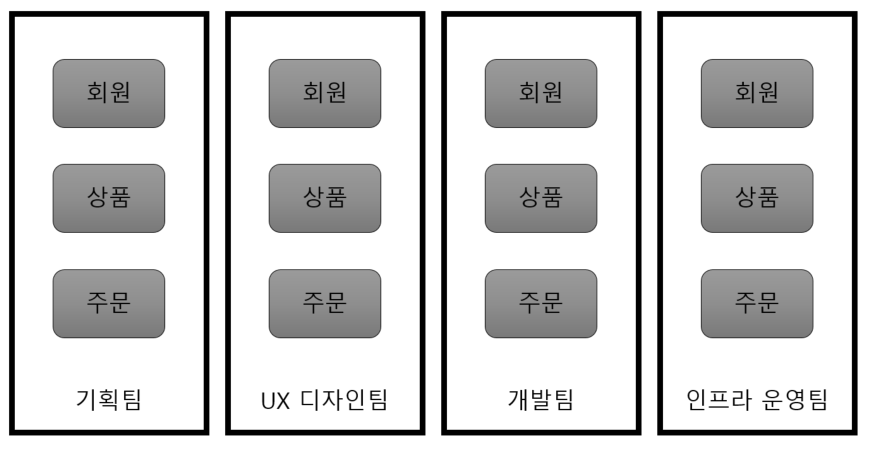
- 이러한 팀 모델은 인력 관리와 운영에 유연성을 부여하지만 팀간의 커뮤니케이션이 원활하지 않고 협업에 걸리는 시간이 지연되는 경우가 많았습니다.
-
-
MSA에서는 서비스 별로 팀을 나누고 서비스 기획에서부터 설계 개발 운영이 팀 내에서 이루어지기 때문에 다른 팀에 대한 의존성이 사라지게 됩니다.
-
MSA에서의 팀 모델
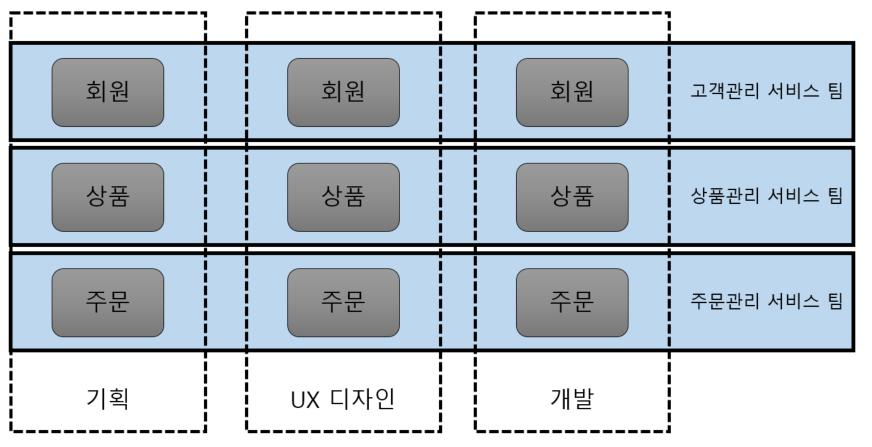
-
역할별 요청과 피드백이 빨라지고, 때문에 유연하고 지속적인 운영과 개발이 함께하게 됩니다.
-
인력 리소스 관리에 어려움이 생기게 됩니다.
-
각 팀의 역할 담당자들은 기본적인 업무 성숙도를 가지고 있어야 하고, 특히 개발자들은 운영 팀의 고유 영역이었던 인프라 핸들링이 가능해야 합니다.
-
이러한 일이 가능하게 된 것은 AWS같은 클라우드 서비스 발달입니다. 직접적인 인프라 운영 없이 클라우드 서비스를 이용하여 개발자가 운영 환경을 설정할 수 있게 되었습니다.
-
-
-
정리
-
MSA는 복잡한 웹 시스템에 맞춰 개발된 API기반의 서비스 지향적 아키텍처 스타일입니다.
-
근래의 아키텍처 모델은 시스템에 대한 설계뿐만 아니라 팀의 구조나 프로젝트 관리 방법까지 달라지기 때문에 프로젝트에 미치는 영향이 매우 크며, 때문에 거시적인 관점에서 고려할 필요가 있습니다.
-
MSA가 필요하다고 해도 꼭 시작을 MSA로 해야 하는 것은 아닙니다.
-
MSA가 서비스의 재사용 성, 유연한 아키텍처구조, 대용량 웹 서비스에 적합한 구조 등 많은 장점을 가지고 있지만 개개인의 높은 숙련도가 필요한 편입니다.
-
MSA를 구축한 많은 기업들이 시작은 모노리틱 시스템으로 시작하여 팀원들의 숙련도를 높이고 피드백을 통해 시스템을 발전 시키는 과정에서 MSA로 전환한 사례들도 있습니다.
- 프로젝트의 목적이나 팀의 상황에 맞는 유연한 선택이 필요합니다.
-
