-
다음으 기능을 제공하는 해시맵을 디자인하라.
-
put(key, value): 키, 값을 해시맵에 삽입한다. 만약 이미 존재하는 키라면 업데이트한다.
-
get(key): 키에 해당하는 값을 조회한다. 만약 키가 존재하지 않는다면 -1을 리턴한다.
-
remove(key): 키에 해당하는 키, 값을 해시맵에서 삭제한다.
-
1. 개별 체이닝 방식을 이용한 해시 테이블 구현
import collections
class ListNode(object):
def __init__(self,key = None,value=None):
self.value = value
self.key = key
self.next = None
class MyHashMap:
def __init__(self):
self.size = 1000
self.table = collections.defaultdict(ListNode)
def put(self,key:int,value:int)->None:
index = key % self.size
#인덱스 노드가 없다면 삽입 후 종료
if self.table[index].value is None:
self.table[index] = ListNode(key,value)
return
#인덱스에 노드가 존재하는 경우 연결리스트 처리
p = self.table[index]
while p:
if p.key == key:
p.value = value
return
if p.next is None:
break
p = p.next
p.next = ListNode(key,value)
def get(self,key:int)->int:
index = key % self.size
if self.table[index].value is None:
return -1
#노드가 존재할 때 일치하는 키 탐색
p = self.table[index]
while p:
if p.key == key:
return p.value
p = p.next
return -1
def remove(self,key:int)->None:
index = key%self.size
if self.table[index].value is None:
return
#인덱스의 첫 번째 노드일 때 삭제 처리
p = self.table[index]
if p.key == key:
self.table[index] = ListNode() if p.next is None else p.next
return
#연결 리스트 노드 삭제
prev = p
while p:
if p.key ==key:
prev.next = p.next
return
prev, p = p, p.next
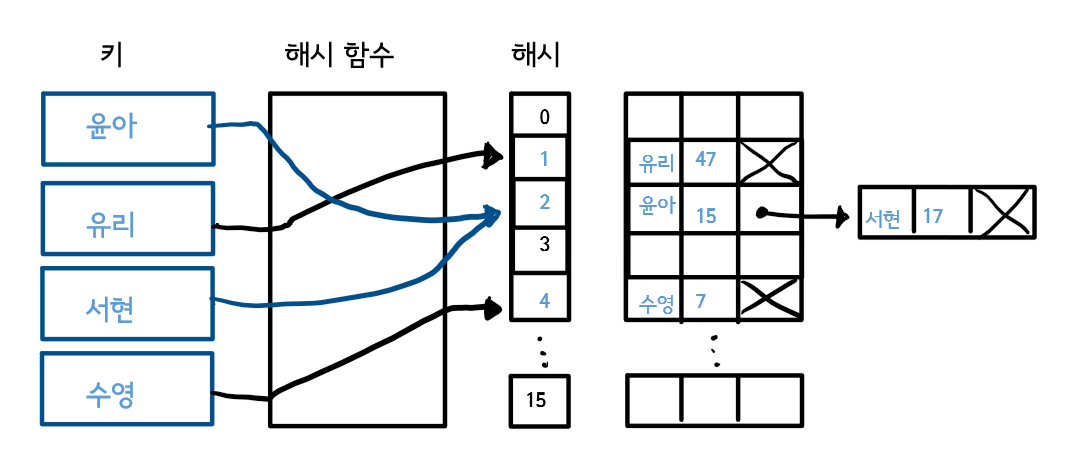
<해시 테이블의 개별 체이닝 방식>
-
여기서는 초기화, 삽입, 조회, 삭제의 총 4가지 기능이 있다.
- 편의상 키와 값은 모두 int로 한다.
-
키, 값을 보관하고 연결 리스트로 처리할 별도의 객체를 ListNode라는 이름의 클래스로 정의한다.
class ListNode(object):
def __init__(self,key = None,value=None):
self.value = value
self.key = key
self.next = None
-
기본 사이즈는 1000개 정도로 적당히 설정하고, 각 ListNode를 담게 될 기본 자료형을 선언한다.
-
편리하게 구현하기 위해 존재하지 않는 키를 조회할 경우 자동으로 디폴트를 생성해주는 collections.defaultdict를 사용한다.
-
모든 키를 정수형으로 지정했으므로, size의 개수만큼 모듈로 연산을 한 나머지를 해시 값으로 정하는 매우 단순한 형태로 처리한다.
-
모듈로 연산을 통한 해싱은 해시 테이블의 가장 기본적인 해싱 방식이기도 하다.
-
해싱한 결과인 index는 해시 테이블의 인덱스가 될 것이다.
-
-
만약, 해당 인덱스에 아무것도 없다면 키, 값을 삽입하고 바로 종료한다.
-
self.table[index] is None이 아닌self.table[index].value is None으로 비교한 이유는 MyHashMap의 초기화 메소드에서 선언한 self.table이 collections.defaultdict(ListNode)이기 때문이다. -
defaultdict는 존재하지 않는 인덱스로 조회를 시도할 경우 에러를 발생하지 않고 그 자리에서 바로 디폴트 객체를 생성하므로, 존재하지 않는 인덱스를 조회할 경우 바로 빈 ListNode를 생성할 것 이다.
- 이 부분은 defaultdict의 특징이며, 매우 편리하게 사용할 수 있는 반면, 이처럼 자동으로 처리해주는 부분들이 있으므로 자칫 잘못하면 버그를 유발할 수 있다.
-
-
해당 인덱스에 노드가 존재하는 경우, 즉 해시 충돌(Hash Collision)이 발생한 경우인데, 이를 개별 체이닝 방식을 충돌을 해결할 것이다.
-
p는 인덱스의 첫 번째 값이며 여기서부터 p.next를 계속 탐색한다.
-
종료 조건은 2가지 이다.
-
이미 키가 존재할 경우 값을 업데이트하고 빠져나간다.
-
p.next is None이라면 아무것도 하지 않고 루프를 빠져나간다.
-
-
-
에러 없이 정상적으로 진행되면 이 코드에서 p.next에 새 노드가 생성되면서 연결된다.
- 기존에 존재하지 않았던 키라면 맨 마지막에 새로운 노드가 연결될 것이다.
-
이제 조회 메소드 get()을 구현하자
-
마찬가지로 모듈로 연산으로 인덱스를 결정하고, 해당 인덱스에 아무것도 없다면 -1을 리턴한다.
- 이 경우는 해당하는 노드는 물론, 아직 어떠한 키도 이 값으로 해싱되지 않은 경우다.
-
노드가 존재할 경우에는 해싱 결과에 하나 이상의 노드가 존재한다는 이야기이므로, p.next로 탐색하면서 일치하는 키를 찾는다.
- 찾게 되면 값을 리턴하고, 찾지 못한다면 루프를 빠져나오면서 마찬가지로 -1을 리턴한다.
-
-
삭제 메소드 remove()를 살펴보자
-
인덱스를 구한 다음에 아무것도 없다면, 잘못된 키를 삭제 시도한 경우이므로 그냥 리턴한다.
-
값이 있는 경우에는 2가지 케이스로 나눠서 처리한다.
-
인덱스 첫 번째 노드일 때,
p.next is None이라면 유일한 노드를 삭제하는 경우이므로 원래는 모두 없애야 한다.그러나 여기서는 ListNode()로 빈 노드를 할당하게 했다.
애당초 self.table은 defaultdict(ListNode)이기 때문에 매번 빈 노드를 생성하기 때문이다.만약, 여기서
self.table[index] = None을 할당한다면 앞서 추가, 조회 함수에서self.table[index].value is None으로 비교를 시도할 때 에러가 발생할 것이다. -
연결 리스트인 노드를 삭제할 때는 prev는 이전, p는 현재 노드로, 계속 p.next로 탐색하다가 일치하는 노드를 찾게 되면, 이전 노드의 다음을 현재 노드의 다음으로 연결한다.
즉, 현재 노드를 아무런 연결 고리가 없도록 끊어 버린다.
-
-
✔ 해시 테이블
-
해시 테이블 (해시 맵)
-
키를 값에 매핑할 수 있는 구조인, 연관 배열 추상 자료형(ADT)을 구현하는 자료구조다.
- 해시 테이블의 가장 큰 특징은 대부분의 연산이 분할 상환 분석에 따른 시간 복잡도가 O(1)이라는 점이다.
- 데이터 양에 관계 없이 빠른 성능을 기대할 수 있다는 장점이 있다.
-
-
해시 함수
-
임의 크기 데이터를 고정 크기 값으로 매핑하는 데 사용할 수 있는 함수
-
해시 테이블의 핵심이라고 할 수 있다.
-
입력 값이 ABC, 1324BC, AF32B로 각각 3글자, 6글자, 5글자이지만, 화살표로 표시한 특정 함수를 통과하면 2바이트의 고정 크기 값으로 매핑된다.
여기서 화살표 역할을 하는 함수가 바로 해시 함수이다.
-
-
해시 테이블을 인덱싱하기 위해 이처럼 해시 함수를 사용하는 것을 해싱(Hashing)이라고 한다.
- 해싱은 정보를 가능한 한 빠르게 저장하고 검색하기 위해 사용하는 중요한 기법 중 하나다.
-
<성능 좋은 해시 함수들의 특징>
-
해시 함수 값 충돌의 최소화
-
쉽고 빠른 연산
-
해시 테이블 전체에 해시 값이 균일하게 분포
-
사용할 키의 모든 정보를 이용하여 해싱
-
해시 테이블 사용 효율이 높을 것
로드 팩터
-
로드 팩터
-
해시 테이블에 저장된 데이터 개수 n을 버킷의 개수 k로 나눈 것
-
load factor = n/k
-
-
로드 팩터 비율에 따라서 해시 함수를 재작성해야 될지 또는 해시 테이블의 크기를 조정해야 할지를 결정한다.
- 또한, 이 값은 해시 함수가 키들을 잘 분산해 주는지를 말하는 효율성 측정에도 사용된다.
- 일반적으로 로드 팩터가 증가할수록 해시 테이블의 성능은 점점 감소하게 되며, 자바 10의 경우 0.75를 넘어설 경우 동적 배열처럼 해시 테이블의 공간을 재할당한다.
충돌(Collision)
- 아무리 좋은 해시 함수라도 충돌은 발생하게 된다.
개별 체이닝
-
충돌 발생 시, 연결 리스트로 처리하는 방식
-
원래 해시 테이블 구조의 원형이기도 하며 가장 전통적인 방식으로, 흔히 해시 테이블이라고 하면 바로 이 방식을 말한다.
-
간단한 원리
1) 키의 해시 값을 계산한다.
2) 해시 값을 이용해 배열의 인덱스를 구한다.
3) 같은 인덱스가 있다면 연결 리스트로 연결한다.
- 잘 구현한 경우 대부분의 탐색은 O(1) 이지만 최악의 경우, 즉 모든 해시 충돌이 발생했다고 가정할 경우에는 O(n) 이 된다.
오픈 어드레싱
-
충돌 발생 시 탐사를 통해 빈 공간을 찾아나서는 방식이다.
-
사실상 무한정 저장할 수 있는 체이닝 방식과 달리, 오픈 어드레싱 방식은 전체 슬롯의 개수 이상은 저장할 수 없다.
-
충돌이 일어나면 테이블 공간 내에서 탐사(Probing)를 통해 빈 공간을 찾아 해결하며, 이 때문에 개별 체이닝 방식과 달리, 모든 원소가 반드시 자신의 해시값과 일치하는 주소에 저장된다는 보장은 없다.
-
선형 탐사(Linear Probing)방식
-
오픈 어드레싱 방식 중에서 가장 간단한 방식
-
충돌이 발생할 경우 해당 위치부터 순차적으로 탐사를 하나씩 진행한다. 이렇게 탐사를 진행하다가 비어 있는 공간을 발견하면 삽입하게 된다.
-
한 가지 문제점은 해시 테이블에 저장되는 데이터들이 고르게 분포되지 않고 뭉치는 경향이 있다는 점이다.
-
클러스터링(Clustering)
: 해시 테이블 여기저기에 연속된 데이터 그룹이 생기는 현상
-
클러스터들이 점점 커지게 되면 전체적으로 해싱 효율을 떨어뜨리는 원인이 된다.
-
-
⭐파이썬의 딕션너리는 해시 테이블로 구현되어 있다.
-
파이썬의 해시 테이블은 충돌 시 오픈 어드레싱 방식으로 구현되어 있다.
- 파이썬이 체이닝을 사용하지 않는 이유를 설명한 바 있는데, 연결 리스트를 만들기 위해서는 추가 메모리 할당이 필요하고, 추가 메모리 할당은 상대적으로 느린 작업이기 때문에 택하지 않았다고 기술했다.
