-
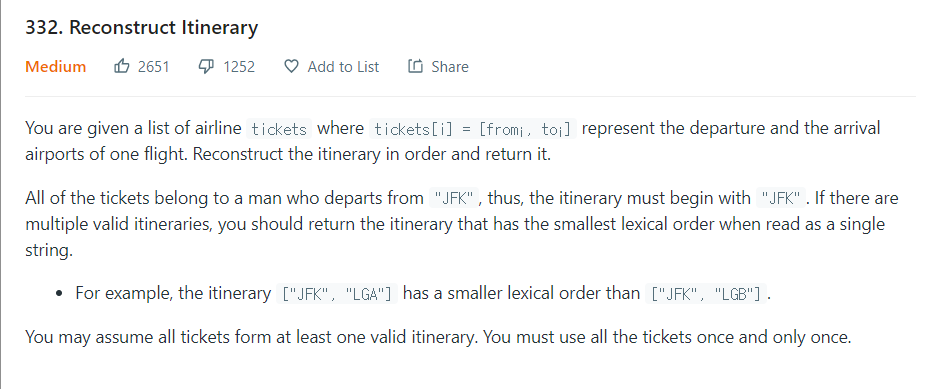
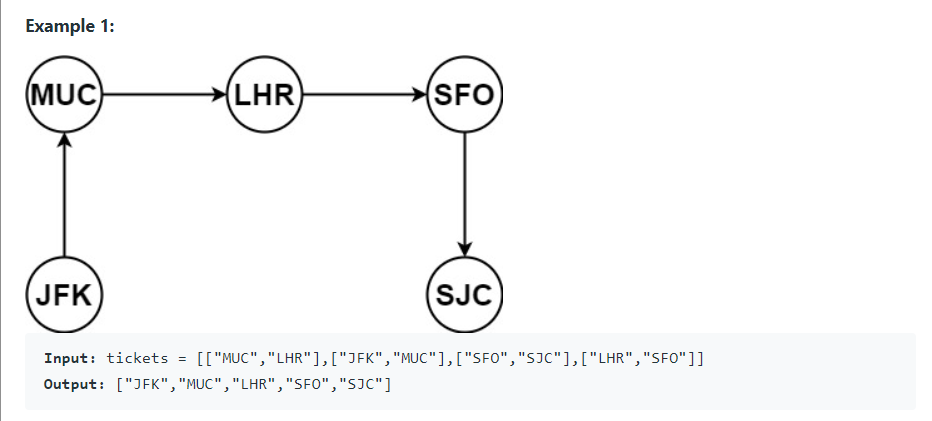
[from, to] 로 구성된 항공원 목록을 이용해 JFK에서 출발하는 여행 일정을 구성하라.
-
여러 일정이 있는 경우 사전 어휘 순(Lexical Order)으로 방문한다.
1. DFS로 일정 그래프 구성 (80ms)
class Solution:
def findItinerary(self, tickets: List[List[str]]) -> List[str]:
graph = collections.defaultdict(list)
#그래프 순서대로 구성
for a, b in sorted(tickets):
graph[a].append(b)
route = []
def dfs(a):
#첫번째 값을 읽어 어휘 순 방문
while graph[a]:
dfs(graph[a].pop(0))
route.append(a)
dfs('JFK')
#다시 뒤집어서 어휘 순 결과로
return route[::-1]
-
여행 일정을 그래프로 구성하면 DFS로 문제를 풀이할 수 있다.
-
여기서 한 가지 주의할 점은, 중복된 일정인 경우 어휘 순으로 방문한다는 점이다.
- 예를 들어, ["ATL", "JFK"], ["ATL", "SFO"]인 경우 J보다 S가 빠르므로 JFK를 먼저 방문한다.
- 예를 들어, ["ATL", "JFK"], ["ATL", "SFO"]인 경우 J보다 S가 빠르므로 JFK를 먼저 방문한다.
-
먼저, 그래프를 구성하는 작업이 필요하다.
- 어휘 순으로 방문해야 하기 때문에 일단 그래프를 구성한 후에 다시 꺼내 정렬하는 방식을 택했다.
graph = collections.defaultdict(list)
for a, b in tickets:
graph[a].append(b)
for a in graph:
graph[a].sort()
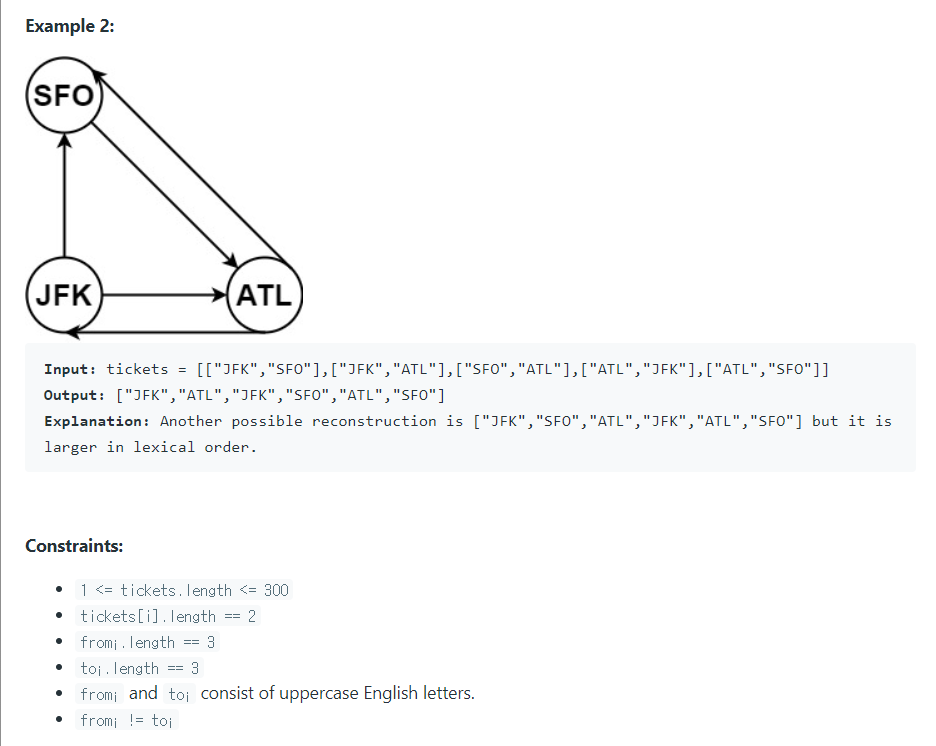
- 이 경우 두 번째 예제 입력값 [["JFK", "SFO"], ["JFK", "ATL"], ["SFO","ATL"], ["ATL", "JFK"], ["ATL", "SFO"]] 일 때 그래프 형태는 다음과 같다.
defaultdict(list,
{'ATL': ['JFK', 'SFO'], 'JFK': ['ATL', 'SFO'], 'SFO': ['ATL']}
-
이처럼 그래프를 순서대로 구성하기 위해 매번
sort()를 호출했다.-
그러나, 이렇게 매번하지 않고 애초에 tickets를 한 번만 정렬해도 결과는 동일하다.
-
파이썬의
sorted()함수로 딱 한 번만 정렬하는 형태로 다음과 같이 개선해보자.
-
graph = collections.defaultdict(list)
for a, b in sorted(tickets):
graph[a].append(b)
-
이제 그래프에서 하나씩 꺼낼 차례다.
pop( )으로 재귀 호출하면서 모두 꺼내 결과에 추가한다.- 결과 리스트에는 역순으로 담기게 될 것이며,
pop( )으로 처리했기 때문에 그래프에서는 해당 경로는 사라지게 되어 재방문하게 되지는 않을 것이다.
- 결과 리스트에는 역순으로 담기게 될 것이며,
-
어휘 순으로 그래프를 생성했기 때문에
pop(0)으로 첫 번째 값을 읽어야 한다. 굳이 따지자면 큐의 연산을 수행한다. -
마지막에는 다시 뒤집어서 어휘 순으로 맨 처음 읽어들였던 값이 처음이 되게 한다.
2. 스택 연산으로 큐 연산 최적화 시도 (76ms)
class Solution:
def findItinerary(self, tickets: List[List[str]]) -> List[str]:
graph = collections.defaultdict(list)
#그래프를 뒤집어서 구성
for a, b in sorted(tickets, reverse=True):
graph[a].append(b)
route = []
def dfs(a):
#마지막 값을 읽어 어휘 순 방문
while graph[a]:
dfs(graph[a].pop())
route.append(a)
dfs('JFK')
#다시 뒤집어서 어휘 순 결과로
return route[::-1]
-
파이썬 리스트의 경우 파라미터를 지정하지 않은 값, 즉 마지막 값을 꺼내는
pop( )은 O(1) 이지만, 첫 번째 값을 꺼내는pop(0)은 O(n) 이다.- 따라서, 좀 더 효율적인 구현을 위해서는
pop( )으로, 즉 스택의 연산으로 처리될 수 있도록 개선이 필요하다.
- 따라서, 좀 더 효율적인 구현을 위해서는
-
애당초 그래프를 역순으로 구성하면 추출 시에는
pop( )으로 처리가 가능하다.- 이렇게 하면 추출 시 시간 복잡도를 O(1)으로 개선할 수 있다.
- 리트코드의 결과에서는 큰 차이가 없지만, 리스트가 매우 클 경우
pop()과pop(0)의 성능 차이는 O(1)과 O(n)으로 클 수 있기 때문에 주의가 필요하다.
3. 일정 그래프 반복 (84ms)
class Solution:
def findItinerary(self, tickets: List[List[str]]) -> List[str]:
graph = collections.defaultdict(list)
#그래프를 순서대로 구성
for a, b in sorted(tickets):
graph[a].append(b)
route, stack = [], ['JFK']
while stack:
#반복으로 스택을 구성하되 막히는 부분에서 풀어내는 처리
while graph[stack[-1]]:
stack.append(graph[stack[-1]].pop(0))
route.append(stack.pop())
#다시 뒤집어서 어휘 순 결과로
return route[::-1]
-
재귀가 아닌 동일한 구조를 반복으로 풀이 해본다.
- 대부분의 재귀 문제는 반복으로 치환할 수 있으며, 스택으로 풀이가 가능하다.
-
그래프 구성은 동일하되, 끄집어낼 때 재귀가 아닌 스택을 이용한 반복으로 처리한다.
-
이제 하나씩 추출하는 형태를 도식화해보면 다음 순서로 진행된다.
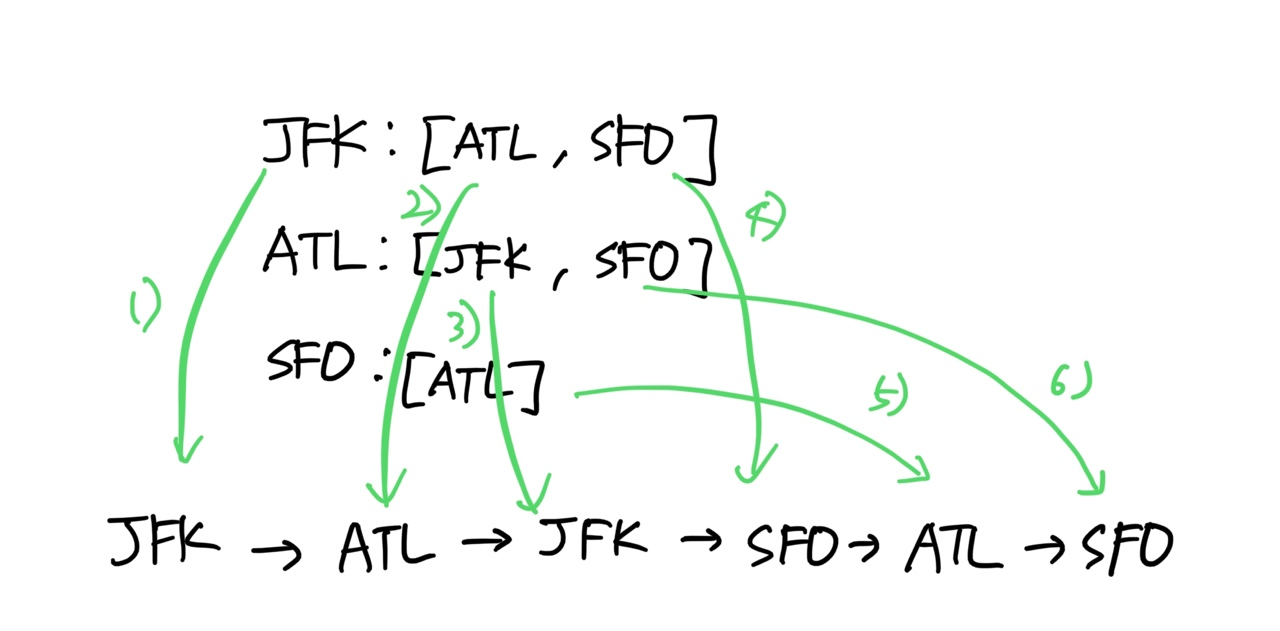
- 출발지는 항상 JFK이므로, 가장 먼저 1) JFK가 오게 되며,
다음은 2) ATL이 어휘순으로 먼저 방문한다.
ATL에서 어휘순 첫 번째 위치는 3) JFK 이며,
다시 JFK로 돌아갔을 대 지난번에 이미 ATL을 방문했기 때문에 다음 방문지인 4) SFO를 가게 된다.
- 출발지는 항상 JFK이므로, 가장 먼저 1) JFK가 오게 되며,
- 한 번 방문했던 곳을 다시 방문하지 않으려면 별도로 마킹하여 다음번에 방문하지 않거나 아예 스택의
pop( )으로 값을 제거하는 방법이 있는데,
여기서는 스택을 이용하므로pop( )으로 아예 값을 제거한다.
stack = ['JFK']
while stack:
while graph[stack[-1]]:
stack.append(graph[stack[-1]].pop(0))-
그래프에 값이 있다면 pop(0)으로 맨 처음의 값을 추출하여 스택 변수 stack에 넣게 했다. 큐의 연산이다.
- 이렇게 하면 그래프의 값들은 점점 제거될 것이며 마지막 방문지가 남지 않을 때까지 while문이 계속 돌면서 그림과 같은 순서대로 처리가 된다.
-
이 예제는 경로가 끊어지는 경우가 없기 때문에 스택에 모든 경로가 한 번에 담긴다. 그런데 만약 경로가 끊어지는 경우가 있다면 스택에 모든 경로가 한 번에 담길 수 없다.
- 예를 들어 입력값이 [["JFK", "KUL"], ["JFK", "NRT"], ["NRT", "JFK"]]라면 그래프는 다음과 같다.
defaultdict(list, {'JFK': ['KUL', 'NRT'], 'NRT': ['JFK']})-
이 경우 JFK -> KUL에서 더 이상 진행할 수 없게 된다. 따라서 스택의 값을 다시
pop( )하여 거꾸로 풀어낼 수 있는 또 다른 변수가 필요하다.-
DFS 재귀 풀이와 달리 반복으로 풀이하려면 이 처럼 한 번 더 풀어낼 수 있는 변수가 필요하다.
-
여기서는 최종 결과가 되는 변수이므로 DFS 재귀 풀이와 동일한 route로 변수명을 정했고, 여기에 스택을
pop( )하여 담게 했다.- 즉 경로가 풀리면서 거꾸로 담기게 될 것이다.
-
-
최종 결과는 다시 뒤집어야 한다.
-
앞서 막혔던 부분인 JKF -> KUL에서 결과 변수 route에
pop( )하여 KUL부터 담게 되고, JFK에서 다시 탐색을 시도해 NRT를 탐색하게 된다. -
NRT는 JFK로 이동하므로, 최종 결과는 다시 뒤집어서 JFK -> NRT -> JFK -> KUL이 된다.
-
