- 연결 리스트를 O(nlogn)에 정렬하라
1. 병합 정렬 (320ms)
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
#두 리스트 병합
def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
if l1 and l2:
if l1.val > l2.val:
l1, l2 = l2, l1
l1.next = self.mergeTwoLists(l1.next, l2)
return l1 or l2
def sortList(self, head: ListNode) -> ListNode:
if not(head and head.next):
return head
#런너 기법 활용
half, slow, fast = None, head, head
while fast and fast.next:
half, slow, fast = slow, slow.next, fast.next.next
half.next = None
#분할 재귀 호출
l1 = self.sortList(head)
l2 = self.sortList(slow)
return self.mergeTwoLists(l1, l2)
-
이 문제는 연결 리스트를 입력값으로 주기 때문에 직접 정렬을 구현해야 하는 좋은 문제이다.
- 그러나, 시간 복잡도 O(nlogn)으로 풀어야 하는 제약사항이 있다.
-
연결 리스트 입력에 대해서는 파이썬에서 정렬할 수 있는 별도의 함수를 제공하지 않기 때문에 직접 정렬 알고리즘을 구현해야 한다.
-
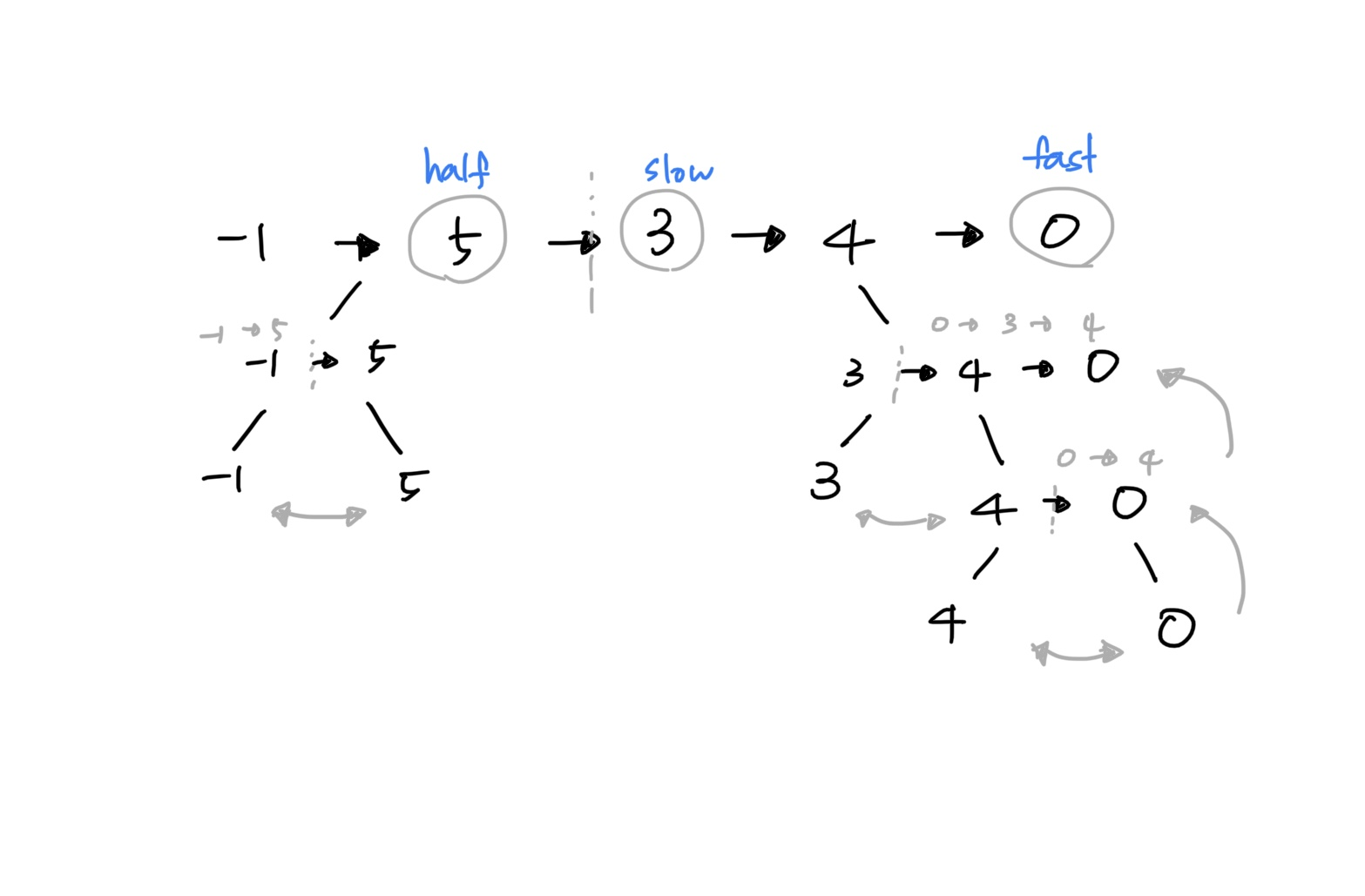
입력값 -1 -> 5 -> 3 -> 4 -> 0 연결 리스트의 병합 정렬 과정의 도식화는 다음과 같다.
-
병합 정렬의 분할 정복(Divide and Conquer)을 위해서는 중앙을 분할(Divide)해야 한다.
- 그림에서도 5를 기준으로 분할하는 과정이 나타나 있다.
-
그러나 연결 리스트는 전체 길이를 알 수 없기 때문에 여기서는 런너 기법을 활용한다.
-
half, slow, fast3개 변수를 만들어 두고slow는 한 칸씩,fast는 두 칸씩 앞으로 이동한다. -
이렇게 하면
fast가 맨 끝에 도달했을 때slow는 중앙에 도착해 있을 것이다. -
half는slow의 바로 이전 값으로 한다. -
마지막에는
half.next = None으로half위치를 기준으로 연결 리스트 관계를 끊어버린다.
-
-
분할해서 재귀 호출을 진행해보자.
-
head는 시작 노드이고,slow는 우리가 탐색을 통해 발견한 중앙 지점이다. -
그림에서는 3이
slow가 된다. -
이 값을 기준으로 계속 재귀 호출을 해나가면 결국 연결 리스트는 -1, 5, 3, 4, 0 단일 아이템으로 모두 쪼개진다.
-
마지막에는 최종적으로 쪼갰던 아이템을 다시 합쳐서 리턴한다.
-
-
그냥 합치는 것이 아닌 크기 비교를 통해 정렬하면서 이어 붙인다.
-
mergeTwoLists()메소드는 연결 리스트를 입력값으로 받아, 길이가 얼마가 되든 재귀 호출을 통해l1의 포인터를 이동하면서 정렬해 리턴한다. -
여기서
return l1 or l2는l1에 값이 있다면 항상l1을 리턴하고,l1이None인 경우l2를 리턴한다.- 즉
l1이 우선이다.
- 즉
-
앞의 두 정렬 리스트 병합 문제는 굳이
l1 or l2를 비교하지 않고l1이None이라면 미리 스왑해버리는 방식인데, 어떤 식으로 풀이하든 결과는 동일하다.
<병합 정렬 구현의 최종 비교 단계>
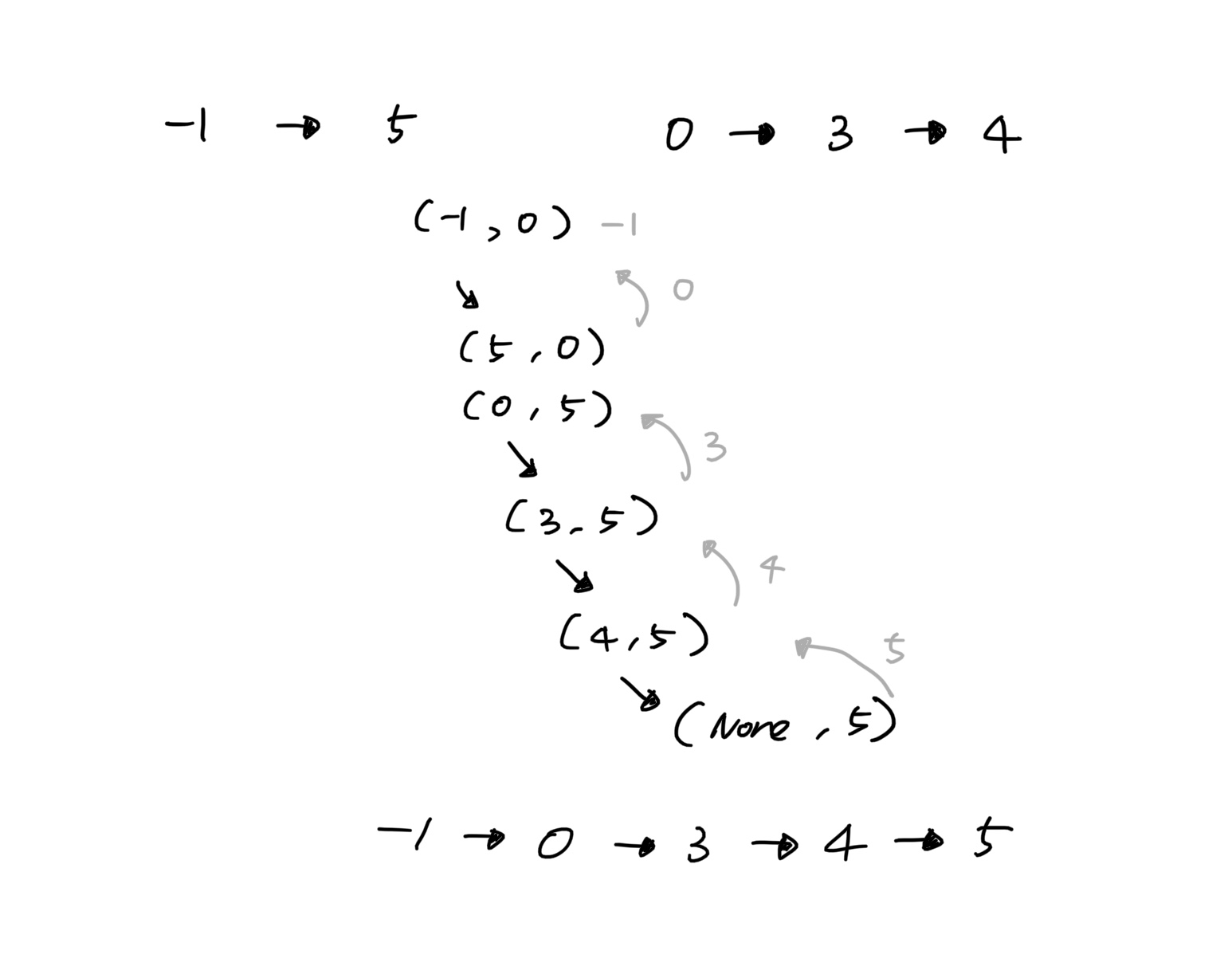
-
-
처음에는
l1에 -1,l2에는 0이 입력값으로 들어오고,l1의next인 5는 0보다 크기 때문에 스왑한다. -
이후에는 스왑없이 계속
next순서로 3, 4로 연결된다. -
마지막에는 4의
next가None이고, 이 경우return l1 or l2부분에서l2값이 리턴되며, 즉 5가 리턴 된다. -
재귀 호출된 부분들을 거슬러서 풀어보면 -1 -> 0 -> 3 -> 4 -> 5로 최종 정렬이 잘 진행됐음을 확인할 수 있다.
2. 퀵 정렬 (타임아웃)
-
이 문제를 로무토 파티션 등의 일반적인 퀵 정렬 알고리즘으로 구현하면, 타임아웃이 발생해 풀이가 불가능하다.
- 퀵 정렬을 변형해 좀 더 최적화를 진행해야 풀이가 가능하다.
-
파이썬에서는 타임아웃이 나며 풀이가 불가능하나 자바와 C++는 풀이가 가능했으나, 병합 정렬보다 한참 더 오래 걸렸다.
-
1,2,3 단 3개의 아이템으로 구성된 1000개 입력값으로 이뤄진 테스트 케이스가 있는데, 이 부분에서 파이썬의 퀵 정렬은 계속 타임아웃을 발생했다.
-
퀵 정렬은 대표적인 불안정 정렬로, 같은 값이 반복될 경우에도 계속해서 스왑을 시도한다.
-
연결리스트는 특성상 피벗을 임의로 지정하기가 어렵기 때문에 여기서는 피벗을 항상 첫 번째 값으로 설정했는데, 이 경우 이미 정렬된 리스트가 입력값으로 들어오게 되면 계속해서 불균형 리스트로 나뉘기 때문에 최악의 결과를 볼 수 있다.
-
-
이처럼 퀵 정렬은 입력값에 따라 성능의 편차가 크고 다루기가 까다롭기 때문에, 성능이 우수함에도 실무에서는 좀처럼 사용하지 않는 이유이기도 하다.
3. 내장 함수를 이용하는 실용적인 방법 (84ms)
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def sortList(self, head: ListNode) -> ListNode:
#연결 리스트 -> 파이썬 리스트
p = head
lst: List = []
while p:
lst.append(p.val)
p = p.next
#정렬
lst.sort()
#파이썬 리스트 -> 연결 리스트
p = head
for i in range(len(lst)):
p.val = lst[i]
p = p.next
return head
-
이 문제는 정렬 알고리즘을 직접 구현할 필요가 없다.
- 요즘 대부분의 프로그래밍 언어들은 표준 라이브러리에서 이미 성능 좋은 정렬 알고리즘을 제공하고 있기 때문이다.
-
실행 시간을 조금이라도 더 줄여야 하는 코딩 테스트에서는 가장 현명한 접근 방식이기도 하며, 실무에서도 당연히 이 같은 방식으로 풀이하는 편이 훨씬 실용적이다.
-
화이트보드에 알고리즘을 작성해야한다면 지양해야한다.
-
대신 언급하는 것이 좋을 것이다.
-
-
코드를 구현해보자
-
연결 리스트를 파이썬의 리스트로 만든다.
-
파이썬의 내장 정렬 함수인
sort()를 다음과 같이 수행한다. -
정렬한 리스트는 다시 연결 리스트로 만든다.
-
여기서
p는 포인터다. -
연결 리스트를 순회하기 위한 포인터 변수를
p로 설정했고, 순회하며 값을 채워넣는 역할을 한다. -
그런 다음 루트 노드
head를 리턴한다.
-
-
-
이 풀이는 84ms에 풀이가 가능하며 무엇보다 단순하면서도, 직관적이고, 쉽다.
- 별도의 제약사항이 없다면 현명하게 활용할 필요가 있다.
