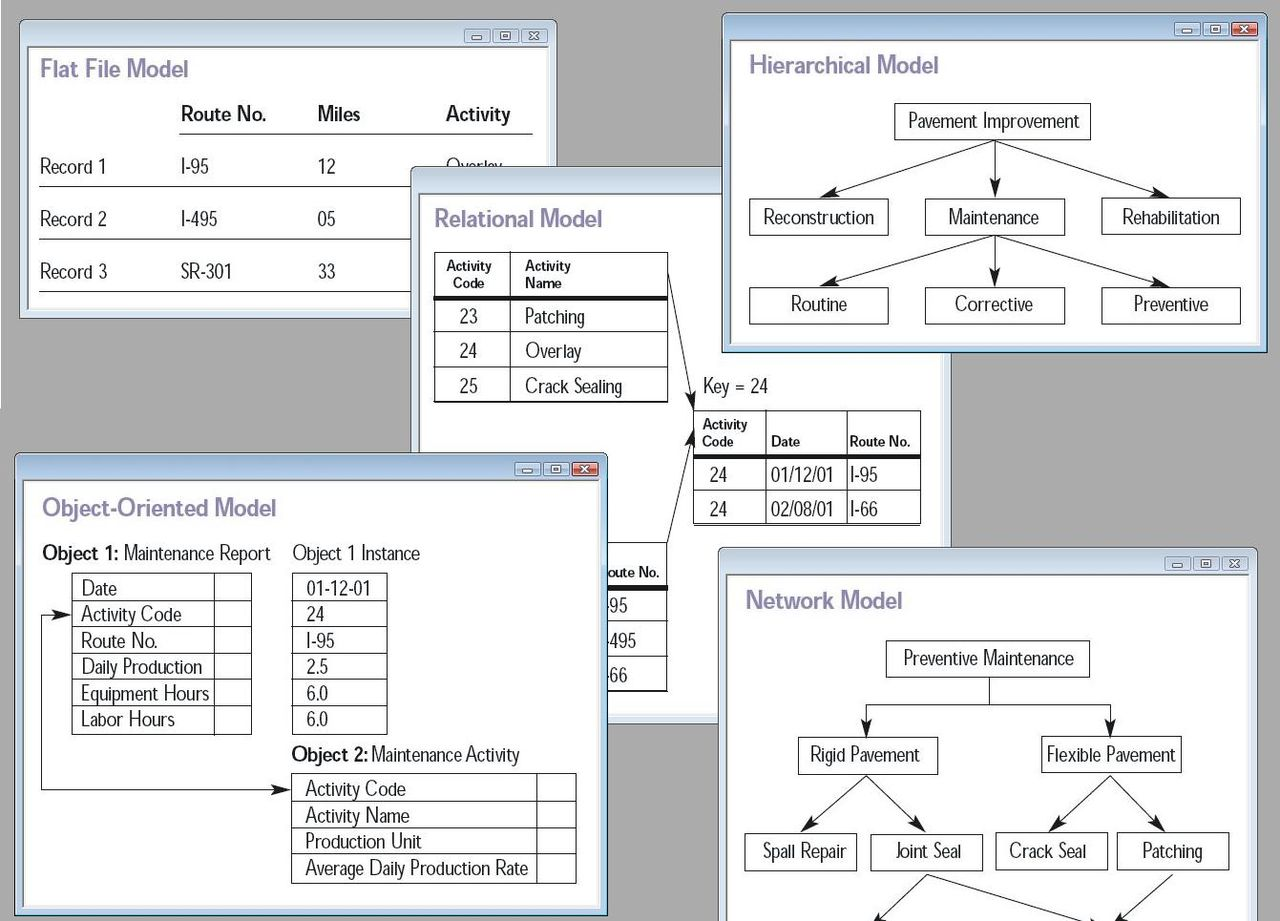
데이터베이스
- 데이터베이스는 데이터를 바라보는 관점에 따라 관계형 데이터베이스, 계층형 데이터베이스, 그래프 데이터베이스 등으로 나눌 수 있다.
-
관계형 데이터베이스(Relational Database)
-
관계형 데이터베이스는 여러 개의 테이블에 걸쳐있는 데이터 사이의 관계에 주목한다. 여러 개의 행(row)이 모여 테이블을 이루며, 행에는 여러 개의 열(column)이 있다. 엑셀의 표와 행, 열을 떠올리면 된다.
-
일반적으로 DBMS라고 하면 RDBMS(Relational DBMS)를 가리킨다. 오라클 데이터베이스 서버, 마이크로소프트 SQL 서버, MySQL과 MariaDB, PostgreSQL 등이 이에 해당한다. 이 책에서 다루는 SQLite도 RDBMS이다.
-
SQLite: SQLite는 가장 널리 사용되는 데이터베이스 엔진으로2, 임베디드 디바이스, 사물 인터넷, 데이터 분석, 작은 규모의 웹사이트에 사용하기 적합하다.
SQLite의 특징은 다음과 같다.
-
SQLite는 임베디드 SQL 데이터베이스 엔진으로, 독립적인 서버 프로세스를 갖지 않는다.
-
설치 과정이 없고, 설정 파일도 존재하지 않는다.
-
테이블, 인덱스, 트리거, 뷰 등을 포함한 완전한 데이터베이스가 디스크 상에 단 하나의 파일로 존재한다.
-
퍼블릭 도메인5으로서 개인적 또는 상업적 목적으로 사용할 수 있다.
-
SQLite 환경 설정
DB Browser for SQLite(DB4S) 다운로드 페이지 (https://sqlitebrowser.org/dl/)에서 자신의 환경에 맞는 최신 버전의 프로그램을 다운로드한다. DB Browser for SQLite는 윈도우, 맥, 리눅스 등 다양한 환경을 지원한다.
-
설치가 완료된 후 DB Browser for SQLite를 실행하면 아래와 같은 화면을 볼 수 있을 것이다.
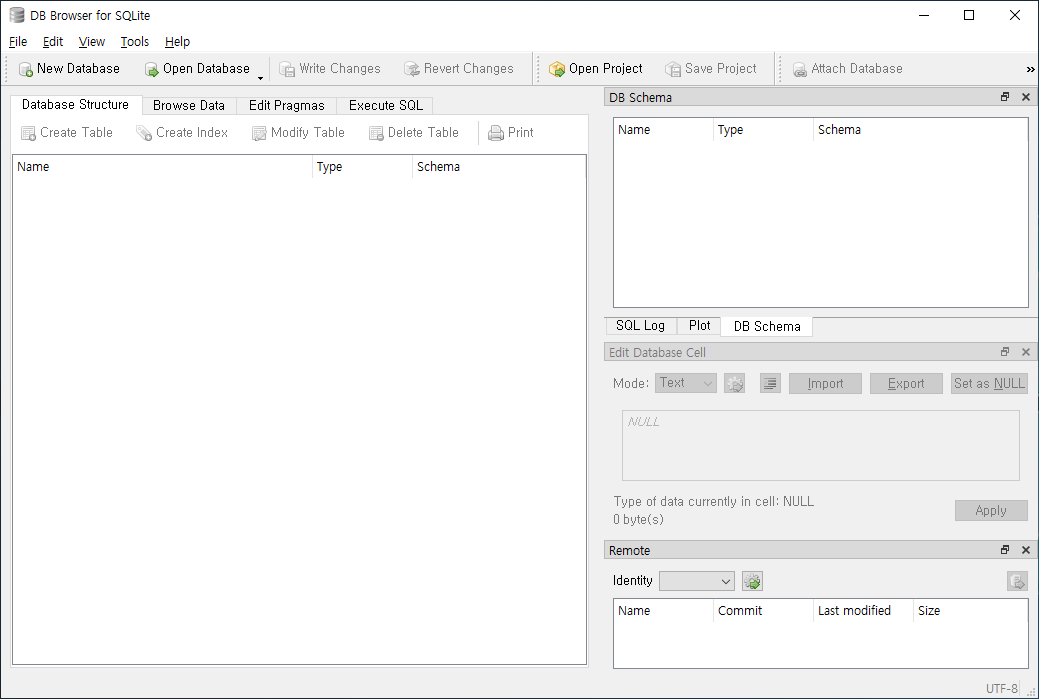
- 메뉴가 한글로 보인다면 편집(Edit) - 환경설정(Preferences) 메뉴를 선택하고, 환경설정(Prefernces) 창의 일반(General) 탭에서 언어(Language)를 English (United States)로 설정하자.
- SQLite용 서드파티 바이너리 확장으로 더 많은 기능을 추가할 수 있다. SQLCipher는 SQLite 데이터베이스 파일에 256비트 AES 암호화를 추가한다. SQLite-Bloomfilter는 특정 필드의 데이터에서 블룸 필터를 생성할 수 있게 해준다.
데이터베이스 생성
-
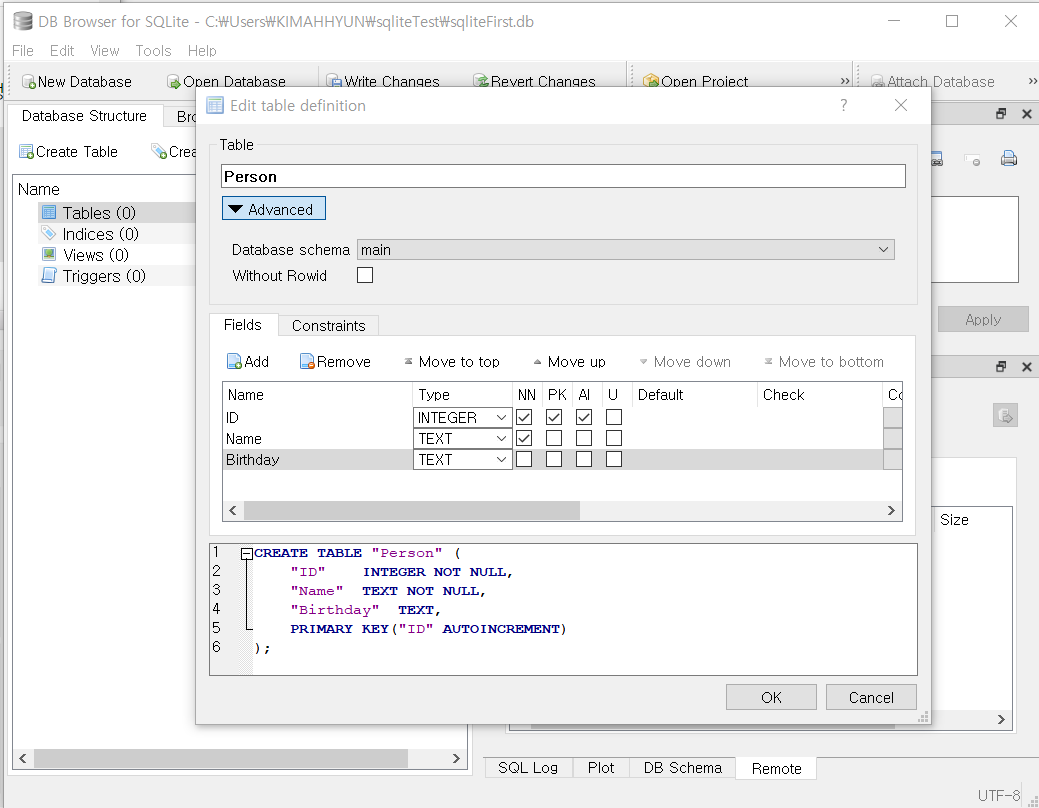
DB Browser for SQLite의 File — New database 메뉴를 선택하거나, DB toolbar에 있는 New Database 버튼을 클릭한다. 단축키는
Ctrl + N이다.- Choose a filename to save under 창이 열리면 파일 이름을 입력하고 저장 버튼을 클릭한다.
파일 형식은 SQLite database files (.db .sqlite .sqlite3 .db3)로 선택되어 있으므로 그대로 두면 된다.
- Choose a filename to save under 창이 열리면 파일 이름을 입력하고 저장 버튼을 클릭한다.
1. 추가, 삭제, 갱신, 조회
- DB Browser for SQLite의 Execute SQL 탭을 열고 실습한다.
추가
-
행을 추가할 때는 INSERT 문을 사용한다.
-
다음의 SQL 문을 입력해보라.
- DB Browser for SQLite에서 자동완성을 지원하므로, 입력하는 도중에 툴팁이 뜨면 원하는 항목을 선택하고 Tab 또는 Enter 키를 눌러서 진행할 수도 있다.
-
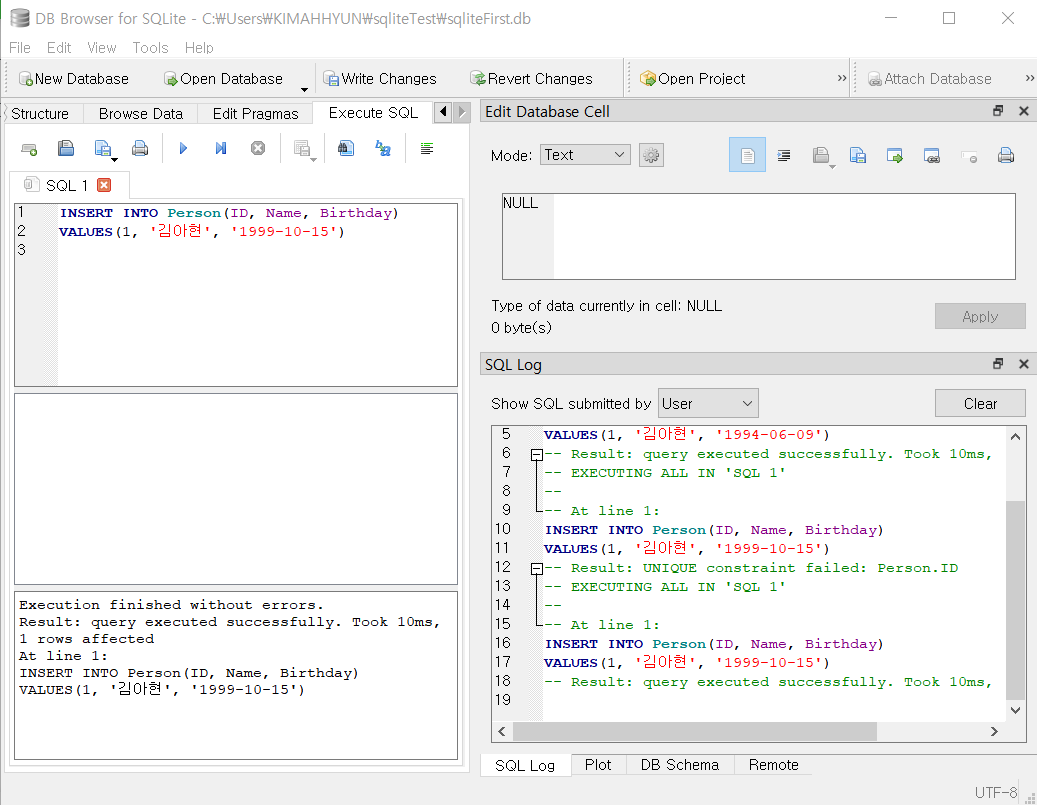
INSERT INTO Person (ID, Name, Birthday)
VALUES (1, '이혜리', '1994-06-09');
- 모든 컬럼에 순서대로 값을 넣을 때는 컬럼명을 생략하고, 아래와 같이 쓸 수 있다.
INSERT INTO Person
VALUES (1, '이혜리', '1994-06-09');
-
SQL 문의 키워드는 대문자와 소문자를 가리지 않으며, 줄바꿈을 하지 않아도 된다.
- SQL 문장을 하나만 입력하였을 때는 행의 끝에 세미콜론을 넣지 않아도 된다. 따라서, 아래와 같은 문장도 유효하다.
insert into Person values (1, '이혜리', '1994-06-09')
-
Execute SQL 버튼또는F5키를 눌러 실행한다. (ctrl + Enter도 가능)정상적으로 INSERT되면 다음과 같은 메시지가 표시된다.
- 여러 번 클릭하더라도 여러 행이 들어가지는 않는다. 앞 장에서 테이블을 생성할 때 ID 필드에 대해 PRIMARY KEY(줄여서 PK) 제약 조건을 설정했기 때문이다.
-
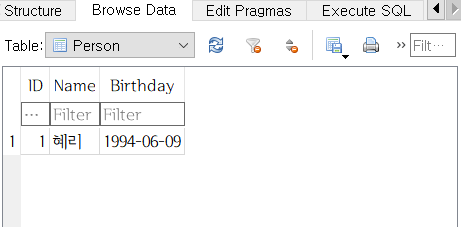
Browse Data 탭으로 가보면 행이 추가된 것을 볼 수 있을 것이다.
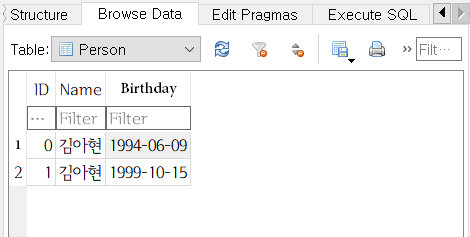
여러 행을 INSERT하기
- Person 테이블에 행을 추가하자. VALUES 절에 여러 행의 값을 적어서 한 번에 삽입할 수 있다.
INSERT INTO Person (Name, Birthday)
VALUES ('박소진', '1986-05-21'), ('김아영', '1992-11-06');열(column) 값의 자동 증가(AUTOINCREMENT)
- 테이블을 생성할 때 ID 컬럼에 대하여 AUTOINCREMENT 속성을 설정했으므로, 위와 같이 ID 열을 생략하고 INSERT하면 자동으로 값이 채워진다.
널(NULL)
- Person 테이블을 정의할 때 Birthday 컬럼은 널 값을 허용하도록 했으므로, 다음과 같이 실행하더라도 문제가 없다.
INSERT INTO Person (Name) VALUES ('민아');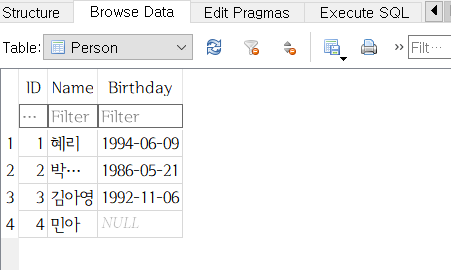
삭제
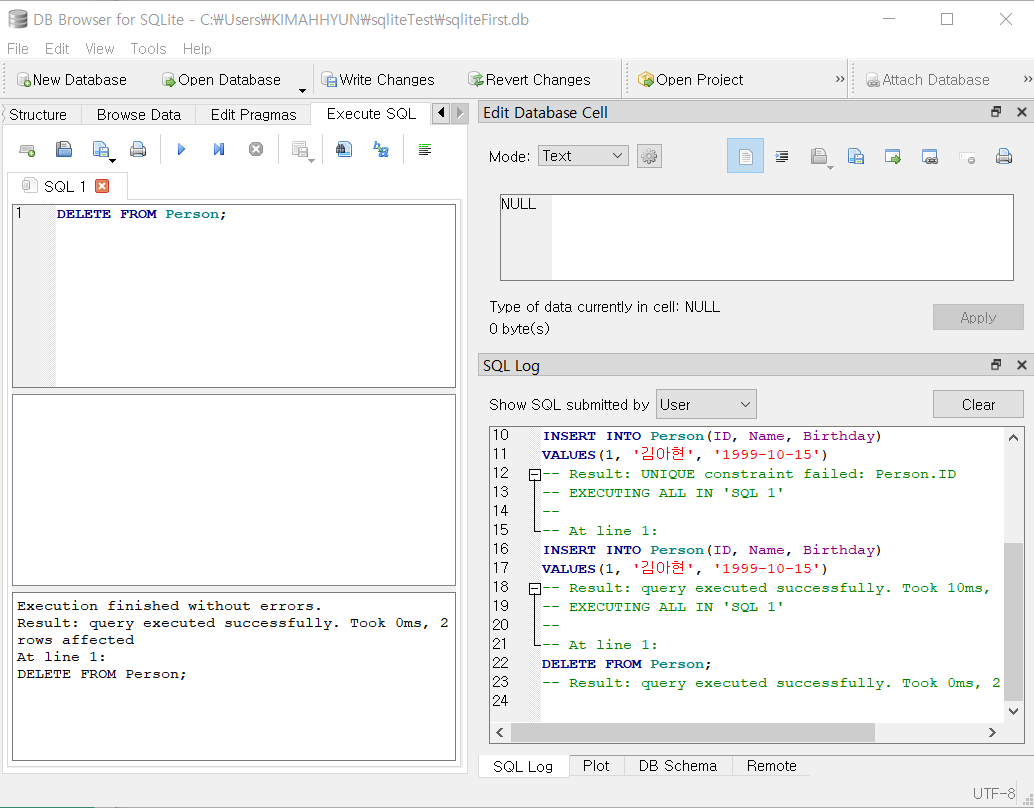
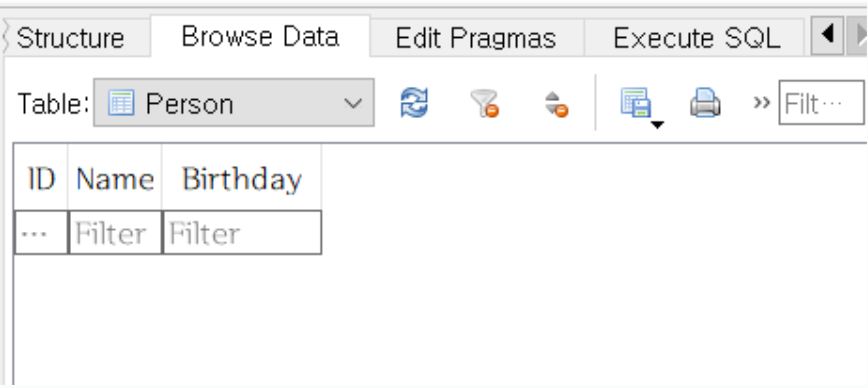
- 행을 삭제할 때는 DELETE 문을 사용한다.
DELETE FROM Person;
-
위와 같이 실행하고 테이블을 조회해보라. 몇 건이 있었든 간에, 들어있던 행이 모두 지워졌을 것이다. 행은 지워졌지만 테이블의 구조는 변함이 없다.
갱신
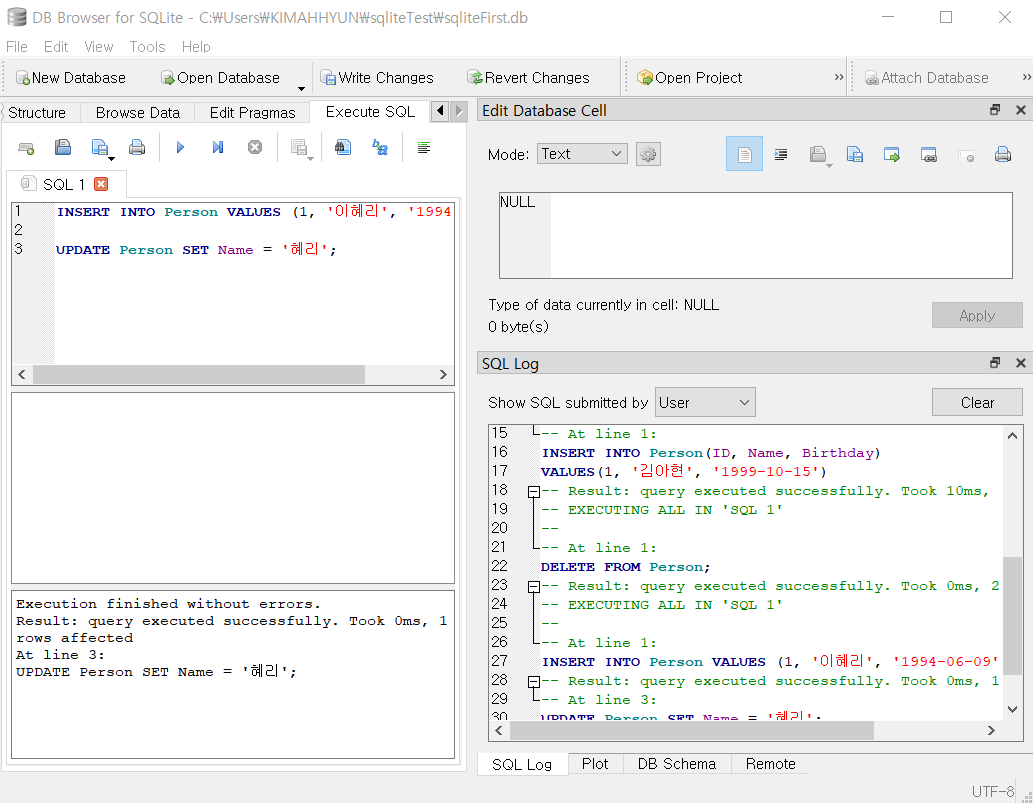
- 갱신할 때는 UPDATE 문을 사용한다. 행을 다시 INSERT한 다음, UPDATE 문을 실행해보자.
INSERT INTO Person VALUES (1, '이혜리', '1994-06-09');
UPDATE Person SET Name = '혜리';
조회
-
조회할 때는 SELECT 문을 사용한다.
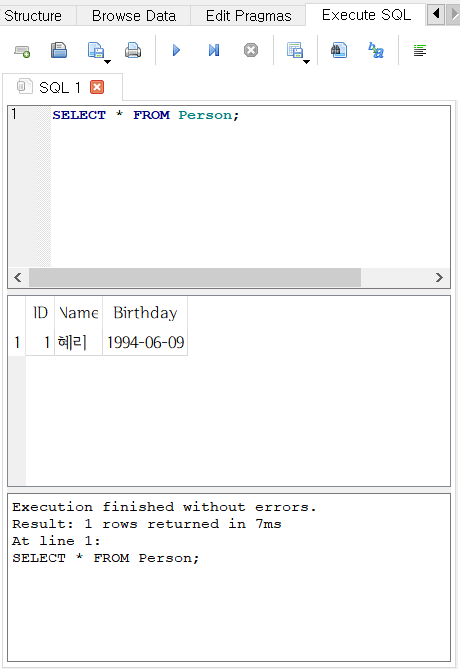
- 다음의 문장은 Person 테이블의 모든 행과 열을 조회한다.
SELECT * FROM Person;
원하는 열만 조회하기
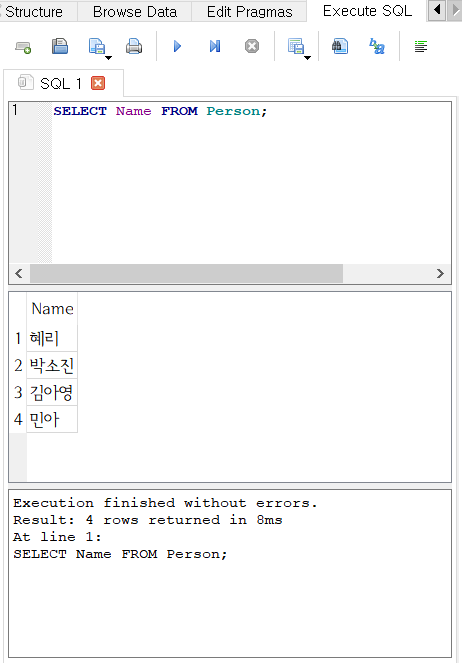
- SELECT 절에 컬럼명을 지정하여 조회할 수 있다.
SELECT Name FROM Person;
원하는 순서로 조회하기
-
특정 컬럼을 기준으로 행을 정렬하여 조회할 수 있다.
- 다음 문장은 Person 테이블의 Name 컬럼을 나열하되, Name을 기준으로 오름차순으로 정렬한다.
SELECT Name FROM Person ORDER BY Name;- DESC 키워드를 추가하여 역순으로 조회할 수 있다.
SELECT Name FROM Person ORDER BY Name DESC;
SELECT ... WHERE
- Name이 '박소진'인 행을 찾아보자.
SELECT * FROM Person WHERE Name = '박소진';
UPDATE ... WHERE
- UPDATE 또는 DELETE 문에도 WHERE 절을 사용할 수 있다. Name이 '박소진'인 행에 대하여, Name을 '소진'으로 바꾸어보자.
UPDATE Person SET Name = '소진' WHERE Name = '박소진';
LIKE
- WHERE 절에
=대신 LIKE를 사용하여, 패턴과 일치하는 문자열을 찾을 수 있다.
SELECT * FROM Person WHERE Birthday LIKE '1986%';2. 변경사항 저장과 취소
변경사항 저장하기
-
File --> Write Changes 메뉴를 선택하거나 DB Toolbar의
Write Changes 버튼을 클릭하여, 지금까지 작업한 내용을 데이터베이스 파일에 기록하자.DB Browser for SQLite를 종료하였다가 다시 실행하더라도 데이터가 보존되어 있을 것이다.
변경사항 되돌리기
- File --> Revert Changes 메뉴를 선택하거나 DB Toolbar의
Revert Changes 버튼을 클릭하고, Person 테이블을 다시 조회해보라. 마지막으로 저장한 상태로 되돌아간 것을 볼 수 있을 것이다.
3. 테이블 변경
- ALTER TABLE 구문을 사용하여 테이블 구조를 변경할 수 있다.
컬럼 추가
- Person 테이블에 Height 컬럼을 추가해보자.
ALTER TABLE Person ADD COLUMN Height INTEGER;
-
DB Browser for SQLite의 Database Structure 탭에서 Person 테이블을 선택하고 Modify Table 메뉴를 실행하여 필드를 추가해도 된다.
- 새 컬럼에 값을 넣어보자.
UPDATE Person SET Height = 164 WHERE NAME = '민아';
UPDATE Person SET Height = 167 WHERE Name = '소진';
UPDATE Person SET Height = 170.3 WHERE Name = '유라';
테이블 삭제
- DROP TABLE 문으로 테이블을 삭제할 수 있다.
DROP TABLE Person;
-
DROP TABLE을 실행하면 데이터베이스 스키마와 디스크 파일에서 테이블이 삭제되며, 되돌릴 수 없다.
-
삭제된 테이블을 처음부터 다시 만들고, 데이터를 채워넣도록 하자.
CREATE TABLE Person (
ID INTEGER NOT NULL PRIMARY KEY,
Name TEXT NOT NULL,
Birthday TEXT,
Height INTEGER,
Weight INTEGER
);
INSERT INTO Person VALUES
(1, '혜리', '1994-06-09', NULL, 50),
(2, '소진', '1986-05-21', 167, NULL),
(3, '유라', '1992-11-06', 170.3, 54),
(4, '민아', NULL, 164, 46);
4. 컬럼 별명, 뷰
컬럼 별명
-
조회 결과에서 컬럼명이 다른 이름으로 보이게 할 수 있다.
예를 들어, 8장에서 생성한 Person 테이블에는 Name과 Birthday라는 컬럼이 있는데, 이것을 조회할 때 이름과 생일이라는 컬럼명으로 나타낼 수 있다.
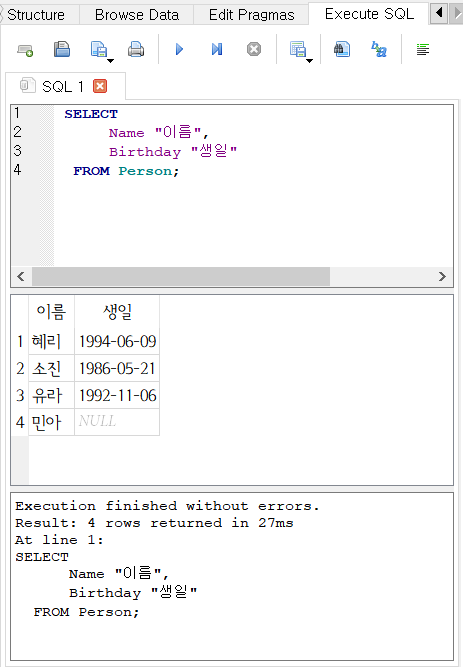
SELECT
Name AS "이름",
Birthday AS "생일"
FROM Person;
- 다음과 같이 AS 키워드를 생략해도 된다.
SELECT
Name "이름",
Birthday "생일"
FROM Person;
-
이번에는 Person 테이블에서 체중(kg)을 키(m)의 제곱으로 나눈 값인 체질량지수(Body Mass Index, BMI)를 계산해보자.
-
round()
-
round() 함수는 소수점 이하에 대하여 반올림을 수행한다. 다음은 123.4567을 소수점 둘째 자리로 반올림한다.
SELECT round(123.4567, 2);
-
-
SELECT
Name,
Height,
Weight,
round(weight / (height * height * 0.0001), 1) BMI
FROM Person;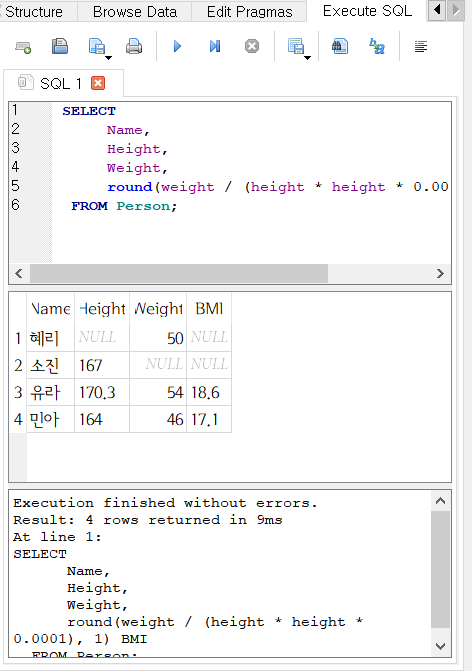
뷰(View) 생성
-
뷰는 SELECT 문을 미리 만들어서 이름을 붙여둔 것이라 할 수 있다.
-
다음 문장은 Person 테이블에서 Birthday와 Birthday의 년, 월, 일에 해당하는 값을 조회하는 뷰를 생성한다.
-
substr()
-
substr() 함수는 문자열의 일부를 반환한다.
SELECT substr('abcdefg', 3), -- 셋째 자리부터 끝까지 substr('abcdefg', 3, 2); -- 셋째 자리부터 두 글자
-
-
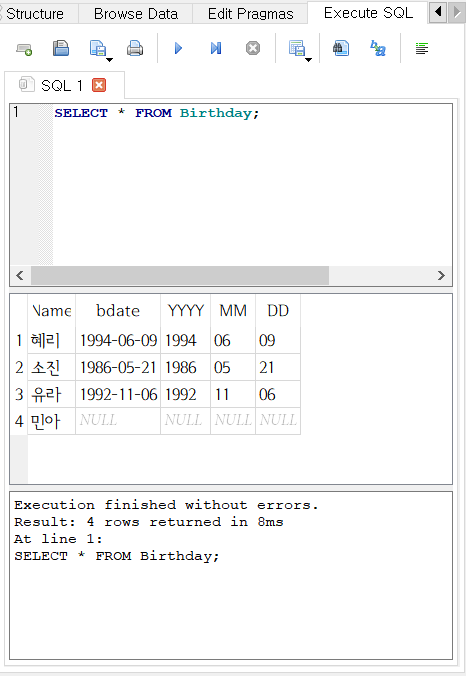
CREATE VIEW Birthday
AS
SELECT
Name,
Birthday bdate,
substr(Birthday, 1, 4) YYYY,
substr(Birthday, 6, 2) MM,
substr(Birthday, 9, 2) DD
FROM Person;
- 이제, Birthday 뷰를 일반 테이블과 똑같은 방법으로 조회할 수 있다.
SELECT * FROM Birthday;
뷰 삭제
- 뷰를 삭제하려면 DROP VIEW 문을 사용한다.
DROP VIEW Birthday;
5. 조건절
Java나 Python 같은 프로그래밍 언어를 접해봤다면 if-then-else의 조건분기에 익숙할 것이다. SQL 문에서도 그와 비슷한 것을 사용할 수 있다. (단, SQL은 절차형 프로그래밍 언어와 작동 방식이 다르므로 SQL의 CASE가 절차형 프로그래밍 언어의 조건분기와 똑같지는 않다. 오히려 함수형 언어 또는 용법에서 분기문을 사용하는 것과 유사하다고 할 수 있다.)
CASE
- CASE를 사용한 조건절의 형식은 다음과 같다.
CASE
WHEN 조건 THEN 값
WHEN 조건 THEN 값
...
[ELSE 값]
END
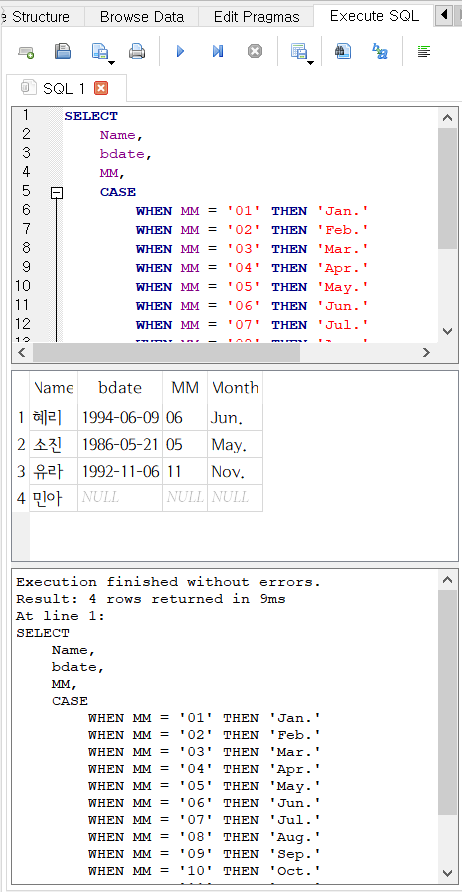
- Birthday 뷰의 MM 컬럼에는 생월을 나타내는 두 자리 숫자가 0으로 빈 자리를 채운(zero-padded) 형식으로 들어 있는데, 다음 예에서는 그 값을 가지고 영어의 달 이름 약어를 나타내게 했다.
SELECT
Name,
bdate,
MM,
CASE
WHEN MM = '01' THEN 'Jan.'
WHEN MM = '02' THEN 'Feb.'
WHEN MM = '03' THEN 'Mar.'
WHEN MM = '04' THEN 'Apr.'
WHEN MM = '05' THEN 'May.'
WHEN MM = '06' THEN 'Jun.'
WHEN MM = '07' THEN 'Jul.'
WHEN MM = '08' THEN 'Aug.'
WHEN MM = '09' THEN 'Sep.'
WHEN MM = '10' THEN 'Oct.'
WHEN MM = '11' THEN 'Nov.'
WHEN MM = '12' THEN 'Dec.'
END Month
FROM Birthday;
6. 날짜와 시간
- SQLite에는 날짜와 시간을 위한 자료형이 없지만, 관련 함수를 사용할 수 있다.
현재 시간
-
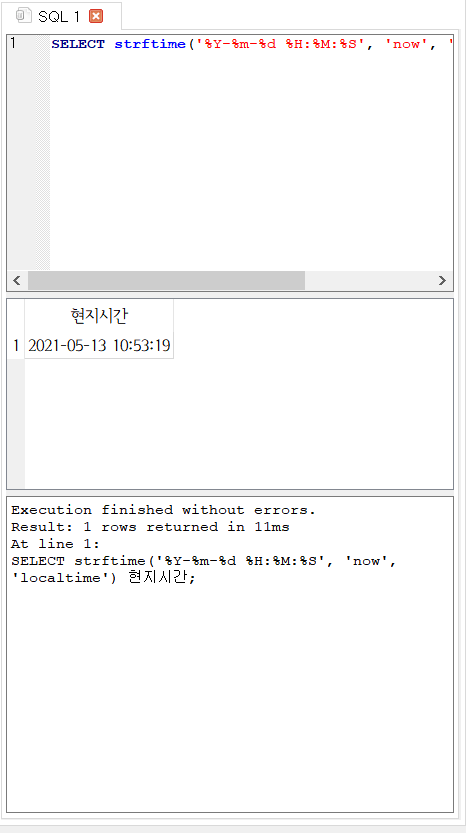
strftime()은 date 값을 포맷에 맞추어 반환한다.다음은 현재 시간을 조회하는 문장이다. '시간'보다는 '시각'이 엄밀한 표현일 수도 있겠지만, 여기서는 편하게 '시간'이라는 단어를 사용했다.
SELECT strftime('%Y-%m-%d %H:%M:%S', 'now') 현재시간;
-
직접 실행해보았다면 시간이 맞지 않다는 것을 알아챘을 것이다. 위와 같이 조회하면 세계표준시가 반환되기 때문이다.
이번에는 세 번째 인자에 'localtime'을 넣어 다시 조회해 보자.
SELECT strftime('%Y-%m-%d %H:%M:%S', 'now', 'localtime') 현지시간;
나이 구하기
- 다음은 혜리의 만 나이를 구하는 질의문이다.
SELECT
Birthday "생일",
strftime('%Y', 'now') - substr(Birthday, 1, 4) - (strftime('%m-%d', 'now') < substr(Birthday, 6)) "나이"
FROM Person
WHERE Name = '혜리';

-
위의 질의에는 트릭이 숨어 있다.
-
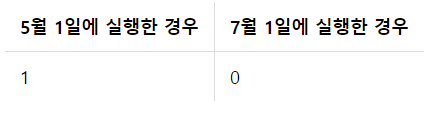
혜리는 6월 9일생이므로,
strftime('%m-%d', 'now') < substr(Birthday, 6)부분은 5월에 실행하는지 7월에 실행하는지에 따라 결과가 달라진다.그뿐 아니라, 같은 6월에 실행하더라도 생일이 지났는지에 따라 결과가 달라진다.
-
SELECT
'05-01' < '06-09' AS "5월 1일에 실행한 경우",
'07-01' < '06-09' AS "7월 1일에 실행한 경우"
FROM Birthday
WHERE NAME = '혜리';
-
결괏값은 참과 거짓을 나타내는 1과 0으로 반환되는데, 이 값이 숫자라는 것에 착안해 나이 계산 질의문에 바로 활용했다.
-
또한, 비교 연산(<)이 사칙연산보다 먼저 실행되었음에도 유의하자.
리터럴 값
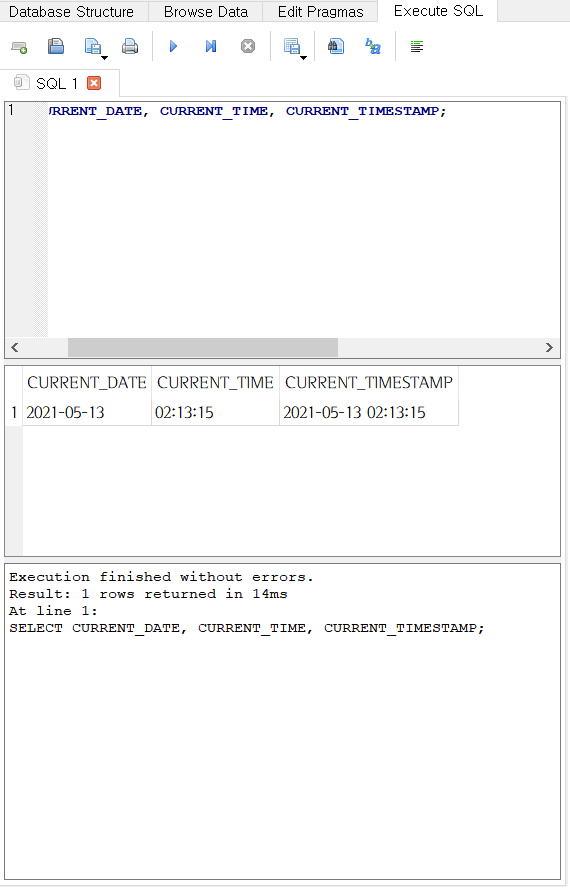
- SQLite에서는 날짜 관련 리터럴 값을 제공한다.
SELECT CURRENT_DATE, CURRENT_TIME, CURRENT_TIMESTAMP;
7. 집계 함수
count()
-
count() 함수는 행 수를 센다.
- 다음 문장은 Person 테이블의 모든 행의 개수를 센다.
SELECT count(*) FROM Person;
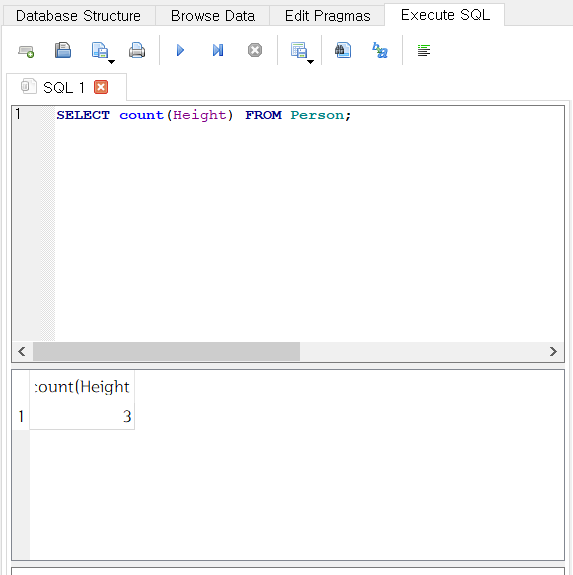
- 특정 컬럼에 데이터가 있는 행을 세려면 괄호 안에 컬럼명을 쓴다.
SELECT count(Height) FROM Person;
max()
- max()는 최댓값을 구한다.
SELECT max(Height) FROM Person;min()
- min()은 최솟값을 구한다.
SELECT min(Height) FROM Person;
sum()
- 숫자 컬럼에 대해 sum()을 사용하여 합계를 낼 수 있다.
SELECT sum(Height) FROM Person;
avg()
- avg()는 평균값을 구한다.
SELECT avg(Height) FROM Person;
8. 그룹화
GROUP BY
- 키를 반올림한 값이 같은 사람 수를 세어보자.
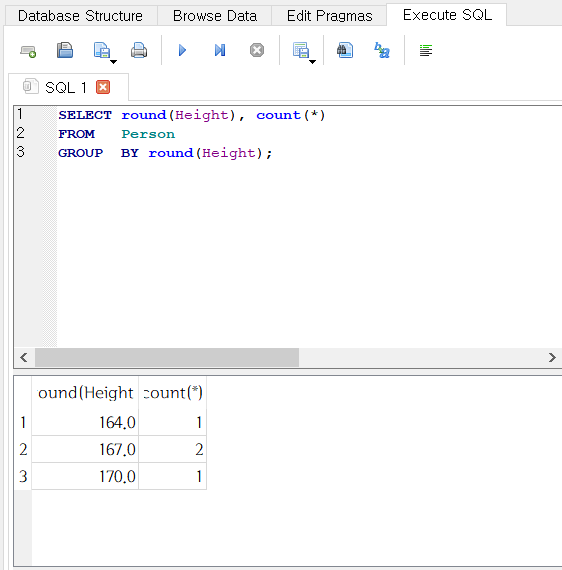
SELECT round(Height), count(*)
FROM Person
GROUP BY 1;
-
GROUP BY 절에 사용한 1은 첫 번째 컬럼, 즉
round(Height)을 가리킨다.- 따라서 아래의 질의로도 같은 결과를 얻는다.
SELECT round(Height), count(*)
FROM Person
GROUP BY round(Height);
HAVING
-
두 명 이상인 경우, 즉
count(*)가 2 이상인 경우만 조회해보자.- HAVING 절에 사용한 숫자 1은 리터럴 값임에 유의하라
SELECT round(Height), count(*)
FROM Person
GROUP BY round(Height)
HAVING count(*) > 1;
9. 평균, 편차, 분산, 표준 편차
- SQLite에서 자체적으로 지원하지 않는 함수를 설명
편차(deviation)는 관측값에서 평균 또는 중앙값을 뺀 것이다.
분산(variance)은 관측값에서 평균을 뺀 값을 제곱하고, 그것을 모두 더한 후 전체 개수로 나눠서 구한다. 즉, 차이값의 제곱의 평균이다. 관측값에서 평균을 뺀 값인 편차를 모두 더하면 0이 나오므로 제곱해서 더한다.
표준 편차(standard deviation)는 분산을 제곱근한 것이다. 제곱해서 값이 부풀려진 분산을 제곱근해서 다시 원래 크기로 만들어준다.
평균
-
평균의 대상이 되는 개별 값과 평균을 표에 나란히 나타내려면 어떻게 해야 할까?
-
집계 함수로 계산한 결과를 행에 나타내려고
over ()구문을 사용했다. -
over ()는 SQLite 3.25 버전 이후에서 작동한다.-
현재 사용하는 SQLite 버전을 확인하는 방법은 다음과 같다.
select sqlite_version();
-
-
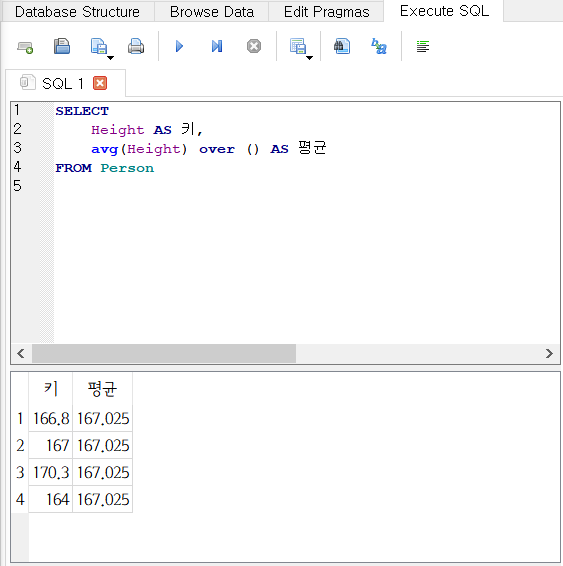
SELECT
Height AS 키,
avg(Height) over () AS 평균
FROM Person
편차
-
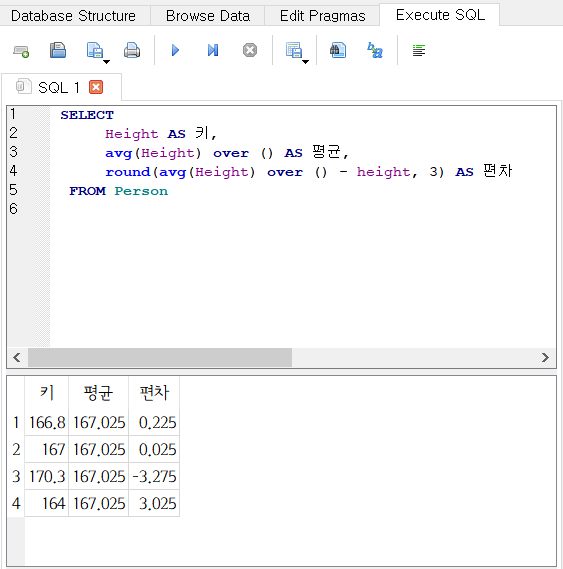
Person 테이블에서 Height의 평균값과의 편차를 구해보자.
- 앞에서와 마찬가지로
over ()를 사용한다.
- 앞에서와 마찬가지로
SELECT
Height AS 키,
avg(Height) over () AS 평균,
round(avg(Height) over () - height, 3) AS 편차
FROM Person
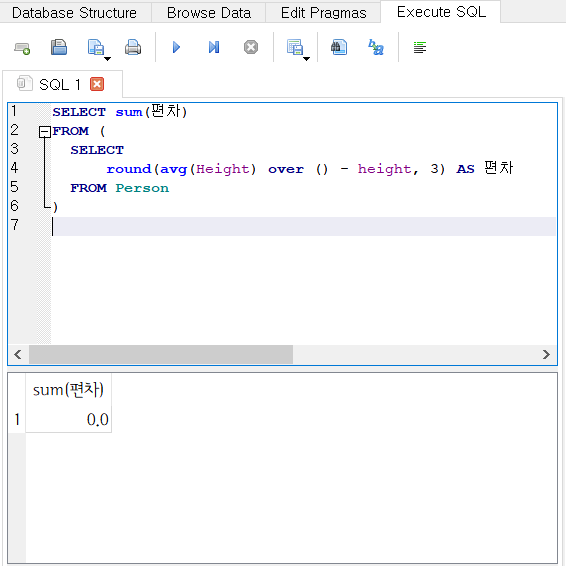
- 분산에 대한 설명에서 '편차를 모두 더하면 0이 나오므로 제곱해서 더한다'고 했는데, 그렇다면 편차를 제곱하지 않은 채로 그대로 더하면 정말로 0이 나오는지 확인해보자.
SELECT sum(편차)
FROM (
SELECT
round(avg(Height) over () - height, 3) AS 편차
FROM Person
)
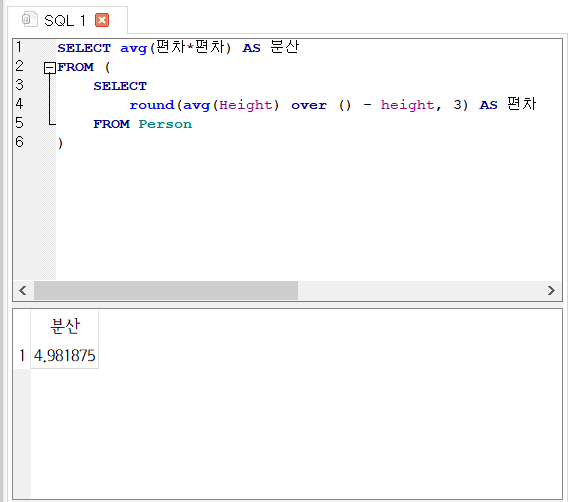
분산
SELECT avg(편차*편차) AS 분산
FROM (
SELECT
round(avg(Height) over () - height, 3) AS 편차
FROM Person
)
-
표준 편차
-
이제 분산의 제곱근을 계산하면 표준편차도 구할 수 있다.
-
그런데 이것은 생각보다 복잡한 문제다. SQLite는 제곱근을 구하는 함수를 자체적으로 제공하지 않는다!
-
- SQLite는 자체적으로 제공하는 함수가 많지 않은 대신, 사용자가 함수를 직접 만들어 쓸 수 있게 되어 있다. 함수를 만드는 방법이 궁금하면 이 글을 읽어 보라.
10. 조인
-
이번 장에서는 새로운 테이블을 만들어 실습한다.
-
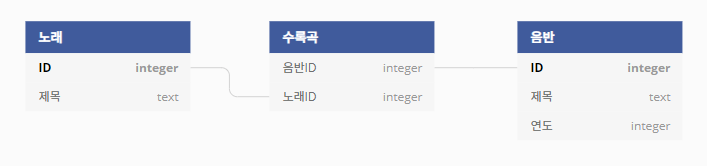
먼저 노래 테이블을 만들어보자.
CREATE TABLE 노래 (
ID INTEGER NOT NULL PRIMARY KEY,
제목 TEXT NOT NULL
);- 다음으로 음반 테이블을 만들고
CREATE TABLE 음반 (
ID INTEGER NOT NULL PRIMARY KEY,
제목 TEXT NOT NULL,
연도 INTEGER
);- 음반과 노래의 관계를 표현하는 수록곡 테이블도 만들자.
CREATE TABLE 수록곡 (
음반ID INTEGER NOT NULL,
노래ID INTEGER NOT NULL
);
- 이제 노래 테이블에 데이터를 넣어보자.
INSERT INTO 노래 VALUES
(1, '갸우뚱'),
(2, 'Shuppy Shuppy'),
(3, 'Control'),
(4, '영러브'),
(5, '한번만 안아줘'),
(6, '반짝반짝'),
(7, '기대해'),
(8, 'I Don''t Mind'),
(9, 'Easy go'),
(10, '여자대통령');
- 음반 테이블에도 데이터를 넣어보자.
INSERT INTO 음반 VALUES
(1, 'Girl''s Day Party #1', 2010),
(2, 'Everyday', 2011),
(3, 'Expectation', 2013),
(4, '여자대통령', 2013);
-
음반과 노래의 관계를 표현하는 수록곡 테이블에 데이터를 넣어보자.
- Everyday 앨범의 반짝반짝이라는 곡은 Expectation 앨범에도 수록됐다.
INSERT INTO 수록곡 VALUES
(1, 1),
(1, 2),
(1, 3),
(2, 4),
(2, 5),
(2, 6), -- Everyday - 반짝반짝
(3, 7),
(3, 8),
(3, 9),
(3, 6), -- Expectation - 반짝반짝
(3, 5),
(4, 10);
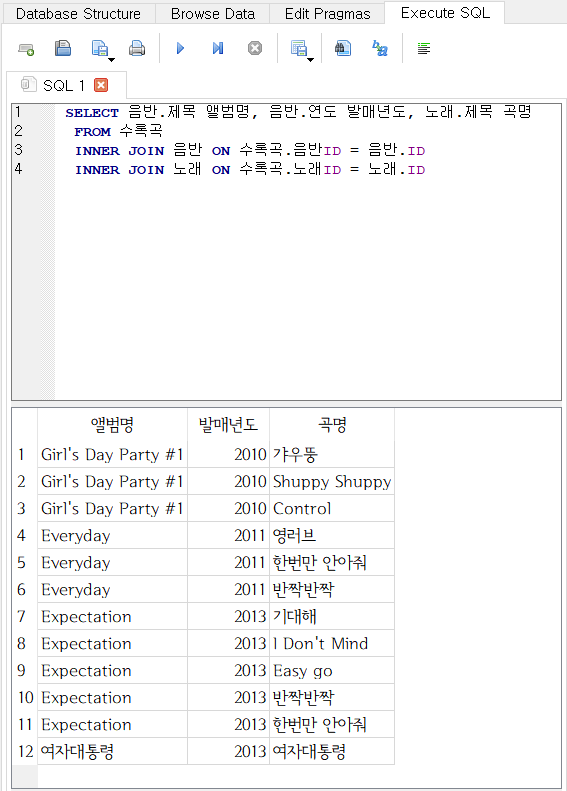
- 데이터를 조회해보자.
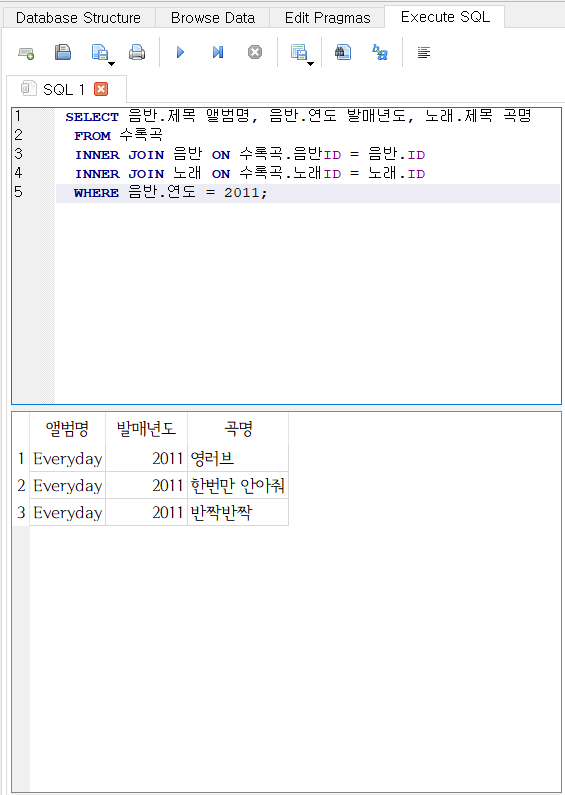
SELECT 음반.제목 앨범명, 음반.연도 발매년도, 노래.제목 곡명
FROM 수록곡
INNER JOIN 음반 ON 수록곡.음반ID = 음반.ID
INNER JOIN 노래 ON 수록곡.노래ID = 노래.ID
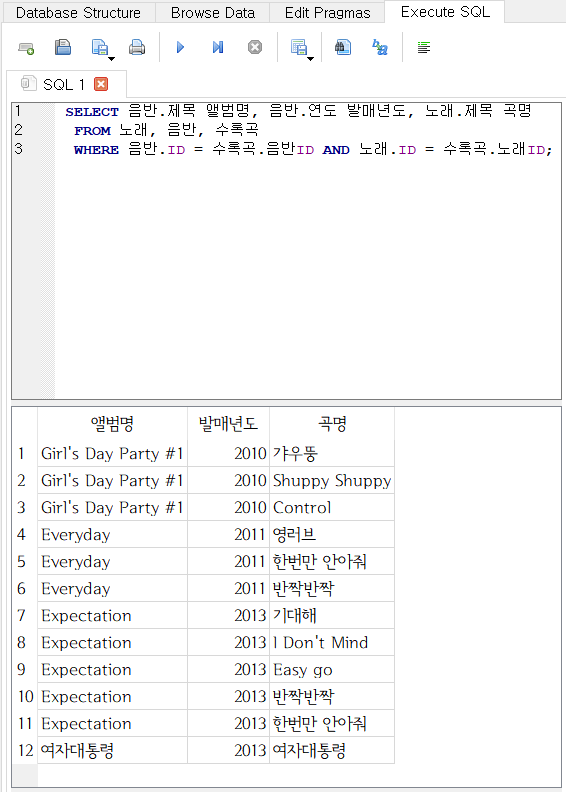
- 위의 SQL 문은
INNER JOIN구문을 명시적으로 사용했다. 다음 문장은 조인 구문을 명시하지 않았지만 위의 것과 같은 결과를 얻을 수 있다.
SELECT 음반.제목 앨범명, 음반.연도 발매년도, 노래.제목 곡명
FROM 노래, 음반, 수록곡
WHERE 음반.ID = 수록곡.음반ID AND 노래.ID = 수록곡.노래ID;
- 2011년에 발매된 앨범만 조회하려면 WHERE 절을 추가하면 된다.
SELECT 음반.제목 앨범명, 음반.연도 발매년도, 노래.제목 곡명
FROM 수록곡
INNER JOIN 음반 ON 수록곡.음반ID = 음반.ID
INNER JOIN 노래 ON 수록곡.노래ID = 노래.ID
WHERE 음반.연도 = 2011;
11. UNION ALL과 UNION
-
UNION ALL 또는 UNION 구문을 사용하면 복수의 질의문을 하나로 합친 결과를 얻을 수 있다.
- 테이블의 내용이나 이름이 똑같지 않더라도 구조가 같다면 합칠 수 있다.
UNION ALL
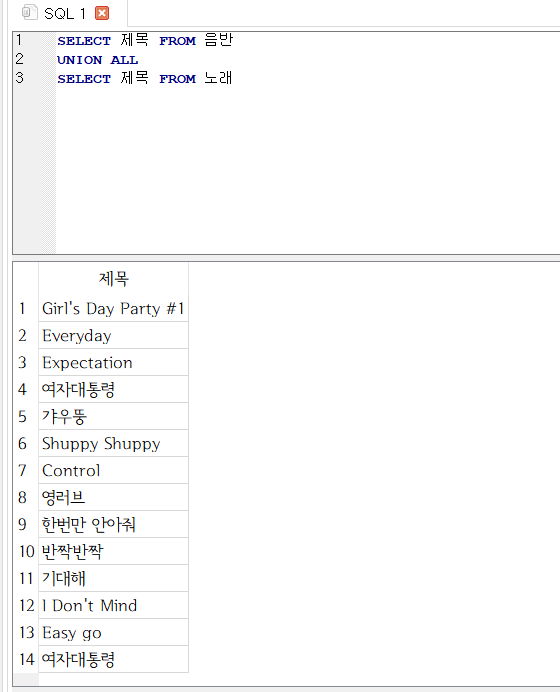
- 음반 테이블과 노래 테이블의 제목을 한 번에 조회해 보자.
SELECT 제목 FROM 음반
UNION ALL
SELECT 제목 FROM 노래
-
컬럼명이 달라도 UNION ALL을 수행하는 데 문제가 없다.
- 따라서 위의 질의문을 다음과 같이 바꿔도 같은 결과를 얻을 수 있다.
SELECT 제목 FROM 음반
UNION ALL
SELECT 제목 AS Title FROM 노래
UNION
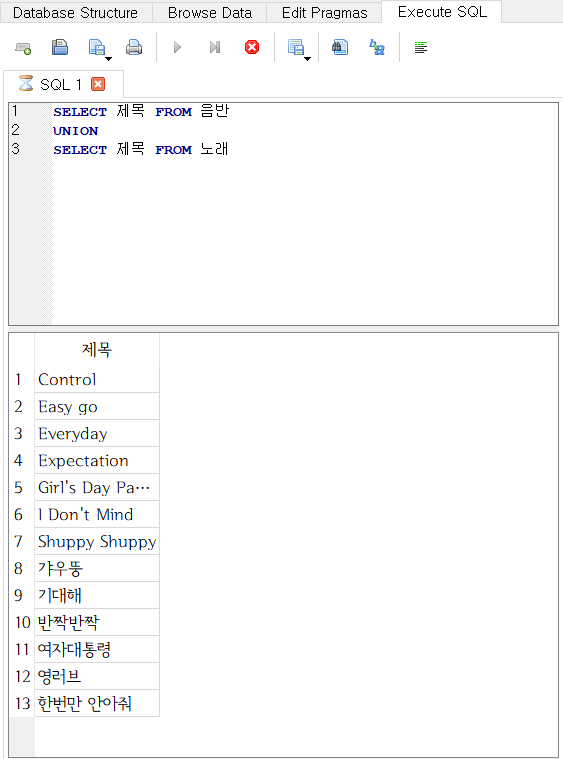
-
UNION구문은UNION ALL과 비슷하지만, 중복되는 데이터를 제외한 결과를 돌려준다는 점에서 차이가 있다. -
UNION ALL과UNION의 또다른 차이점으로,UNION은 질의 결과가 정렬된다는 점을 들 수 있다. 질의 결과에서 중복을 제거하기 위해 먼저 정렬을 수행하기 때문이다. 그래서 제목을 기준으로 오름차순 정렬이 되어, 음반과 노래 제목이 뒤섞인 것을 볼 수 있다.- 정렬과 중복 제거가 굳이 필요하지 않을 때는 UNION ALL을 사용하는 것이 메모리와 속도 측면에서 유리할 것이다.
SELECT 제목 FROM 음반
UNION
SELECT 제목 FROM 노래
UNION ALL과 JOIN을 이용해 조건절을 대체
-
조건절의 예로 들었던 질의를 다음과 같이 바꿀 수 있다.
-
필자가 생각하기에 RDBMS는 테이블 연산에 최적화되어 있고 조건절은 부가적인 기능인 것 같다.
그러므로 이와 같이 테이블 간의 조인으로 계산을 할 수 있는 경우에는 조건절을 사용하는 것보다 조인으로 처리하는 것이 낫다. 실행 시간도 조건절을 사용했을 때보다 이 방식이 더 적게 걸렸다.
- 절차지향적인 프로그래밍 언어에 익숙하면 아무래도 조건절에 먼저 손이 가기 때문에 발상의 전환이 필요하다.
SELECT Name, bdate, Birthday.MM, MonthAbb
FROM Birthday, (
SELECT '01' AS MM, 'Jan.' AS MonthAbb
UNION ALL
SELECT '02' AS MM, 'Feb.' AS MonthAbb
UNION ALL
SELECT '03' AS MM, 'Mar.' AS MonthAbb
UNION ALL
SELECT '04' AS MM, 'Apr.' AS MonthAbb
UNION ALL
SELECT '05' AS MM, 'May.' AS MonthAbb
UNION ALL
SELECT '06' AS MM, 'Jun.' AS MonthAbb
UNION ALL
SELECT '07' AS MM, 'Jul.' AS MonthAbb
UNION ALL
SELECT '08' AS MM, 'Aug.' AS MonthAbb
UNION ALL
SELECT '09' AS MM, 'Sep.' AS MonthAbb
UNION ALL
SELECT '10' AS MM, 'Oct.' AS MonthAbb
UNION ALL
SELECT '11' AS MM, 'Nov.' AS MonthAbb
UNION ALL
SELECT '12' AS MM, 'Dec.' AS MonthAbb
) AS Months
WHERE Birthday.MM = Months.MM
12. 이미지
-
이미지(그림, 사진 등)를 데이터베이스에 저장할 수 있을까?
물론 할 수 있다. 거칠게 말하자면, 컴퓨터에 있어 이미지란 숫자를 나열한 것에 불과하다. 다만, 이미지의 크기나 품질에 따라 그 숫자의 개수가 많을 수 있다.
- 실습을 위해 간단한 테이블을 생성해보자.
CREATE TABLE `Images` (
`name` TEXT,
`image` BLOB
);
-
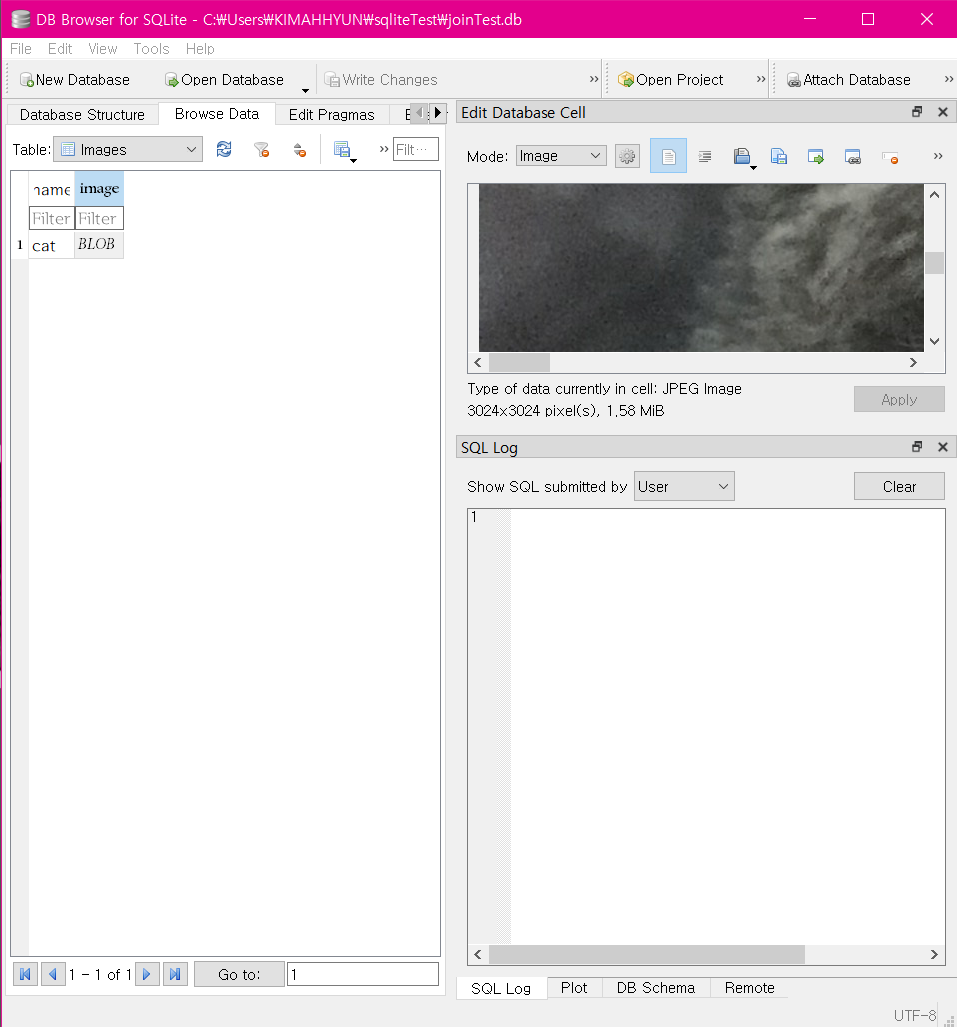
Images 테이블을 생성했으면, Browse Data 탭으로 이동하여 Images 테이블을 선택하고 New Record 버튼을 클릭하자.
- name 필드에 적당한 이름을 입력하자. 필자는 cat을 입력했다.
-
image 필드에는 고양이 사진을 넣을 것이다. DB Browser for SQLite에서는 드래그 앤 드롭으로 이미지를 입력할 수 있다.
탐색기에서 이미지 파일 아이콘을 끌어다가 image 필드에 넣는다. image 필드에 BLOB라는 문구가 표시될 것이다.
- BLOB는 Binary Large Object의 약자로, '큰 이진 파일'이라는 뜻으로 이해하면 된다.
- 오른쪽의 Edit Database Cell 영역에서 Mode를 Image로 바꾸어보면, 방금 넣은 이미지가 보일 것이다.
참고: 위키독스, SQLite를 사용해야하는 이유 ,
