전문화된 클라우드 메커니즘
1. 자동 확장 리스너

-
동적 확장을 위해 클라우드 서비스 소비자와 클라우드 서비스 간의 통신을 모니터링하고 추적하는 서비스 에이전트입니다.
- 모니터링 에이전트
- 자원 에이전트
- 폴링 에이전트
-
일반적으로 방화벽 근처의 클라우드 내에 배포됩니다.
-
워크로드는 클라우드 소비자 생성 요청의 양 또는 특정 유형의 요청에 의해 트리거된 백엔드 처리 요구를 통해 결정될 수 있습니다.
-
작업 부하 변동 조건에 대한 다양한 유형의 응답을 제공할 수 있습니다.
-
클라우드 소비자가 이전에 정의한 매개변수를 기반으로 IT 자원을 자동으로 확장 또는 축소
-
워크로드가 현재 임계값을 초과하거나 할당된 자원 아래로 떨어질 때 클라우드 소비자에게 자동 알림
- 자원 관리자에게 알려서 조치를 취하게 할 수도 있다.
-
AWS Cloud Watch
- 모니터링 하다가 cpu utilization >= 90 for 10 min일 때 알림하거나 auto scailing 처리를 하도록 설정할 수 있다.
- 어디까지 늘리거나 줄일지 설정이 있다. (min, max)
- cool down time도 설정 가능
2. 부하 분산
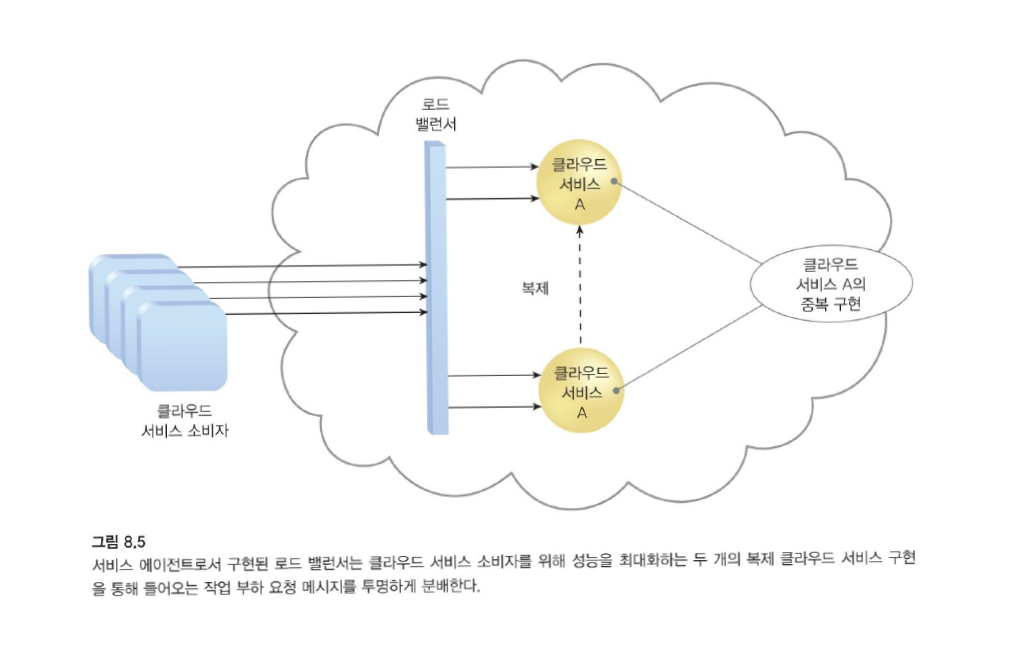
-
수평적 확장에 대한 일반적인 접근 방식은 단일 IT 자원이 제공할 수 있는 것 이상으로 성능과 용량을 증가시키기 위해 둘 이상의 IT 자원에 걸쳐 워크로드의 균형을 맞추는 것입니다.
-
로드 밸런서는 단순한 작업 분할 알고리즘을 넘어 다음을 포함하는 다양한 특수 런타임 워크로드 분산 기능을 수행할 수 있습니다.
-
비대칭 분포
-
워크로드 우선 순위 지정
-
콘텐츠 인식 배포
-
-
로드 밸런서는 IT 자원 사용 최적화, 과부하 방지, 처리량 최대화라는 일반적인 목표로 일련의 성능 및 QoS 규칙 및 매개변수로 프로그래밍되거나 구성됩니다.
3. SLA 모니터
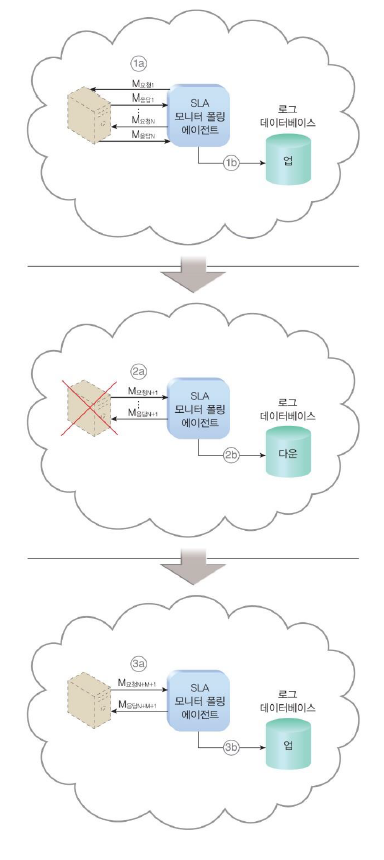

그림 요청과 응답 화살표 방향 반대!
-
SLA 모니터 메커니즘은 클라우드 서비스의 런타임 성능을 구체적으로 관찰하여 SLA에 게시된 계약 QoS 요구 사항을 충족하는지 확인하는 데 사용됩니다.
- 폴링 에이전트
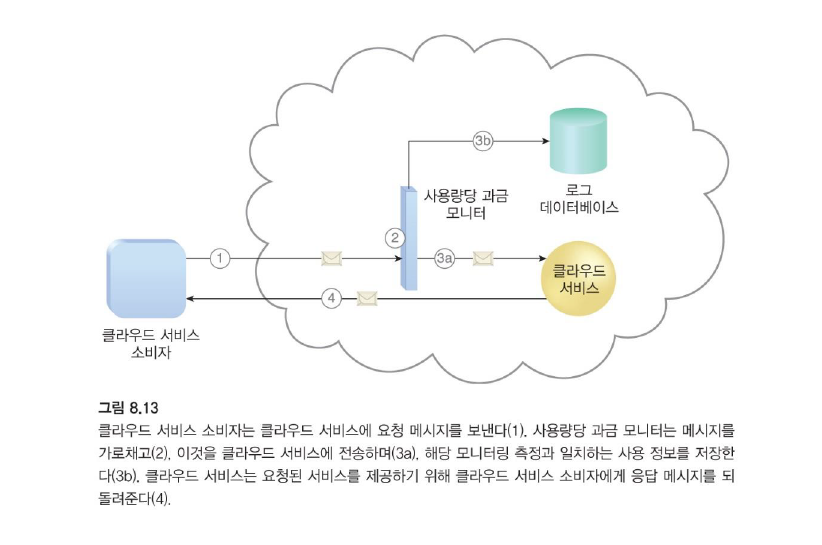
4. 사용량당 과금 모니터
-
사용량당 과금 모니터 메커니즘은 미리 정의된 가격 매개 변수에 따라 클라우드 기반 IT 자원 사용을 측정하고, 요금 계산 및 과금 목적으로 사용 로그를 생성한다.
-
일반적인 모니터링 변수
-
요청/응답 메시지 양
-
전송된 데이터 볼륨
-
대역폭 소비
-
-
사용량당 과금 모니터로 수집된 데이터는 지불 요금을 계한하는 과금 관리 시스템에 의해 처리된다.
- 자원 에이전트


- 모니터 에이전트
5. 감사 모니터
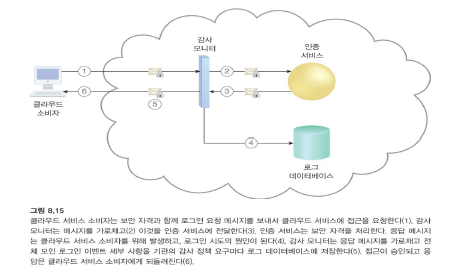
-
감사 모니터 메커니즘은 규제 및 계약 의무를 지원(또는 지시)하기 위해 네트워크 및 IT 자원에 대한 감사 추적 데이터를 수집하는 데 사용됩니다.
-
클라우드 감사관이 사용할 정보를 수집하는 데 사용된다.
-
모니터링 에이전트
-
6. 장애 조치(failover) 시스템
-
기존 클러스터링 기술을 사용하여 중복 구현을 제공하여 IT 자원의 신뢰성과 가용성을 높이는 데 사용됩니다.
-
현재 활성 IT 자원을 사용할 수 없게 될 때마다 이중화 또는 대기 IT 자원 인스턴스로 자동 전환하도록 장애 조치 시스템이 구성됩니다.
-
장애 조치 시스템은 두 가지 기본 구성으로 제공됩니다.
-
액티브 - 액티브
-
액티브 - 패시브
-
액티브 - 액티브
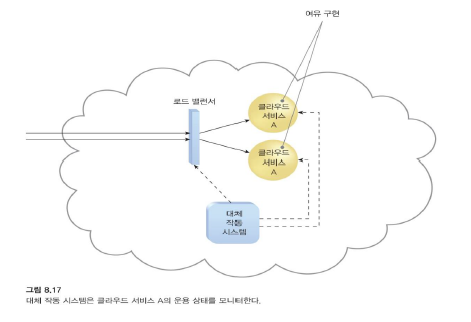
둘 다 항상 돌아간다
-
IT 자원의 중복 구현은 워크로드를 동기식으로 능동적으로 처리합니다.
-
활성 인스턴스 간의 로드 밸런싱이 필요합니다. 장애가 감지되면 로드 밸런싱 스케줄러에서 장애가 발생한 인스턴스를 제거합니다.
-
장애가 감지될 때 계속 운영되는 IT 자원이 처리를 인계받습니다.
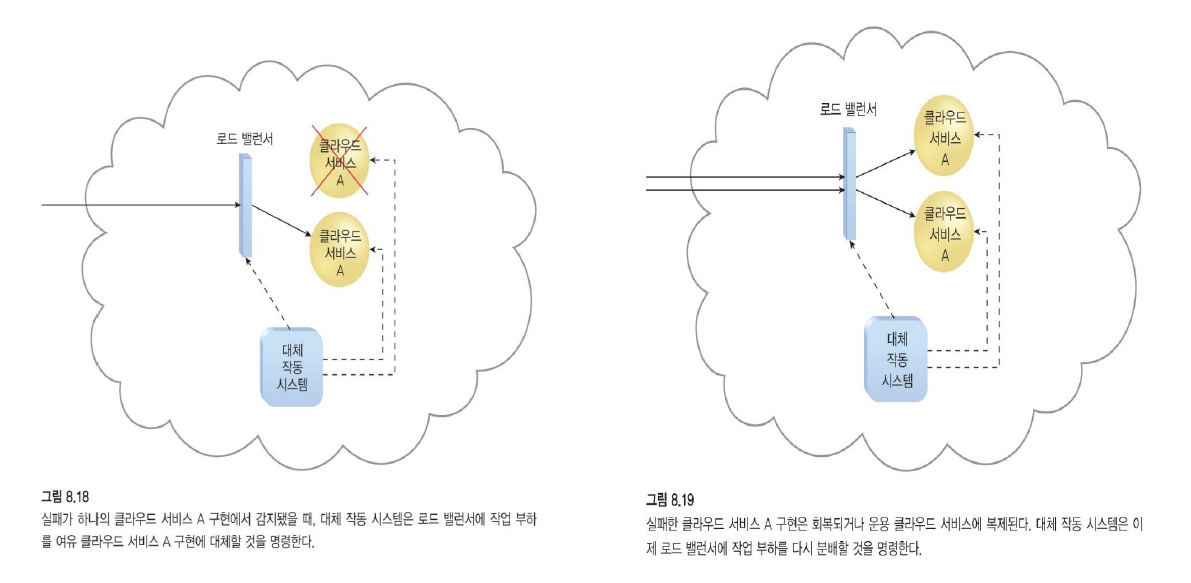
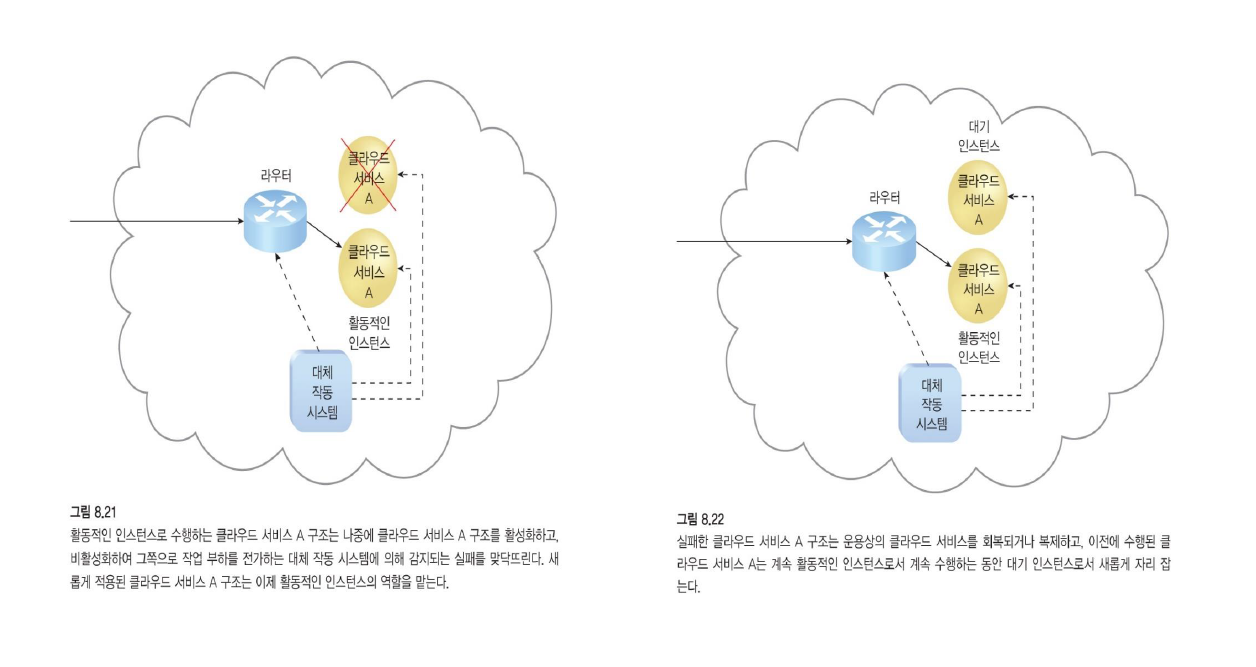
액티브 - 패시브
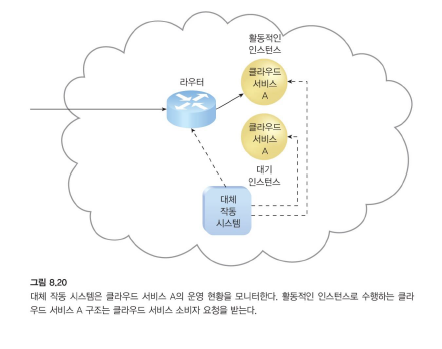
두 개가 있지만 평상시에는 한 개만 돌아가고 문제가 생겼을 때 나머지 하나를 돌린다.
- 대기 또는 비활성 구현이 활성화되어 사용할 수 없게 된 IT 자원의 처리를 인계하고 해당 워크로드가 작업을 인계받는 인스턴스로 리디렉션됩니다.
7. 하이퍼바이저
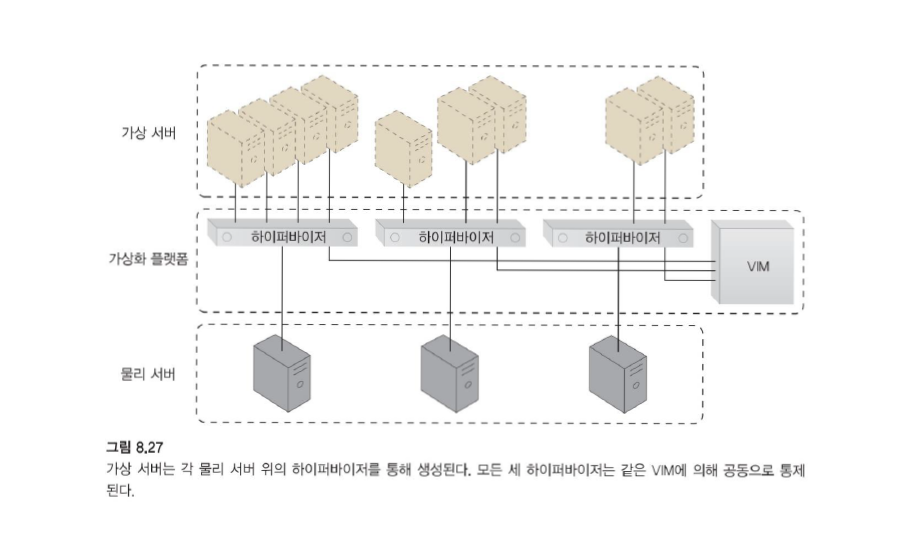
-
주로 물리적 서버의 가상 서버 인스턴스를 생성하는 데 사용되는 가상화 인프라의 기본 부분입니다.
-
하이퍼바이저는 일반적으로 하나의 물리적 서버로 제한되므로 해당 서버의 가상 이미지만 생성할 수 있습니다.
- 즉 하나의 물리 서버 당 하나의 하이퍼바이저
-
VIM은 물리적 서버에서 여러 하이퍼바이저를 관리하기 위한 다양한 기능을 제공합니다.
bare-metal server
- 운영체제나 다른 소프트웨어가 설치되어 있지 않는 서버
8. 자원 클러스터
-
지리적으로 다양한 클라우드 기반 IT 자원을 그룹으로 논리적으로 결합하여 할당 및 사용을 개선할 수 있습니다.
- 논리적인 클러스터로 위치가 동일하지 않아도 된다.
-
자원 클러스터 메커니즘을 사용하여 여러 IT 자원 인스턴스를 그룹화하여 단일 IT 자원으로 운영할 수 있습니다.
-
이렇게 하면 클러스터된 IT 자원의 결합된 컴퓨팅 용량, 로드 밸런싱 및 가용성이 향상됩니다.
-
많은 자원 클러스터는 자원 클러스터 아키텍처 내에서 일관성을 유지하고 설계를 단순화하기 위해 클러스터 노드가 거의 동일한 컴퓨팅 용량과 특성을 가져야 합니다.
-
공통 자원 클러스터 유형은 다음과 같습니다.
-
서버 클러스터
- 물리적 또는 가상 서버가 클러스터링되어 성능 및 가용성 향상
-
데이터베이스 클러스터
- 데이터 가용성을 향상시키도록 설계된 이 고가용성 자원 클러스터에는 클러스터에서 사용되는 다양한 저장 장치에 저장되는 데이터의 일관성을 유지하는 동기화 기능이 있습니다.
-
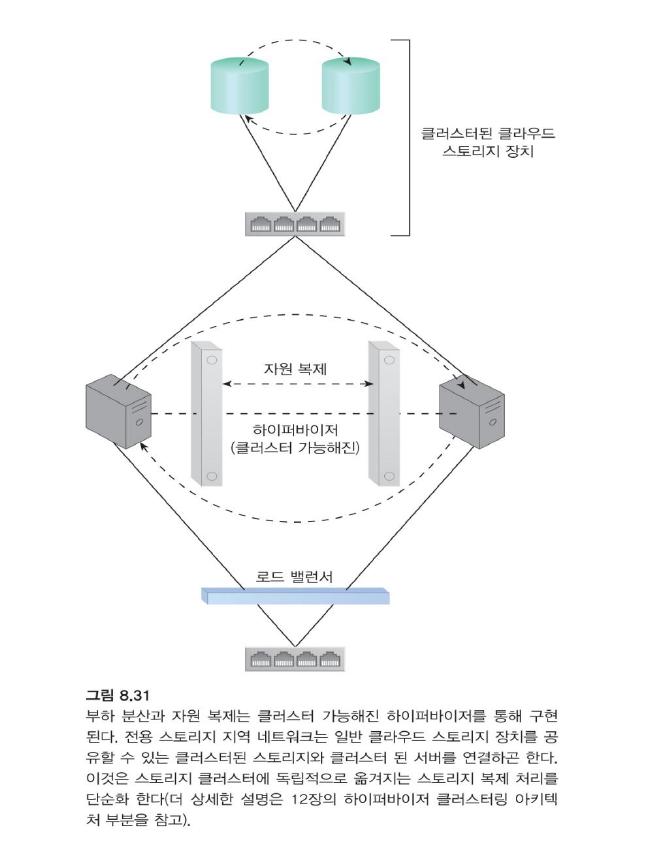
-
자원 클러스터에는 두 가지 기본 유형이 있습니다.
-
로드 밸런싱 클러스터
- 이 자원 클러스터는 IT 자원 관리의 중앙 집중화를 유지하면서 IT 자원 용량을 늘리기 위해 클러스터 노드 간에 워크로드를 분산하는 데 특화되어 있습니다.
-
HA 클러스터
-
고가용성 클러스터는 다중 노드 장애 발생 시 시스템 가용성을 유지하고 클러스터된 IT 자원의 대부분 또는 전체를 중복 구현합니다.
-
장애 조건을 모니터링하고 장애가 발생한 노드에서 작업 부하를 자동으로 리디렉션하는 장애 조치 시스템 메커니즘을 구현합니다.
-
-
9. 다중 장치 브로커
10. 상태 관리 데이터베이스
