클라우드 인프라 메커니즘
1. 논리 네트워크 경계
-
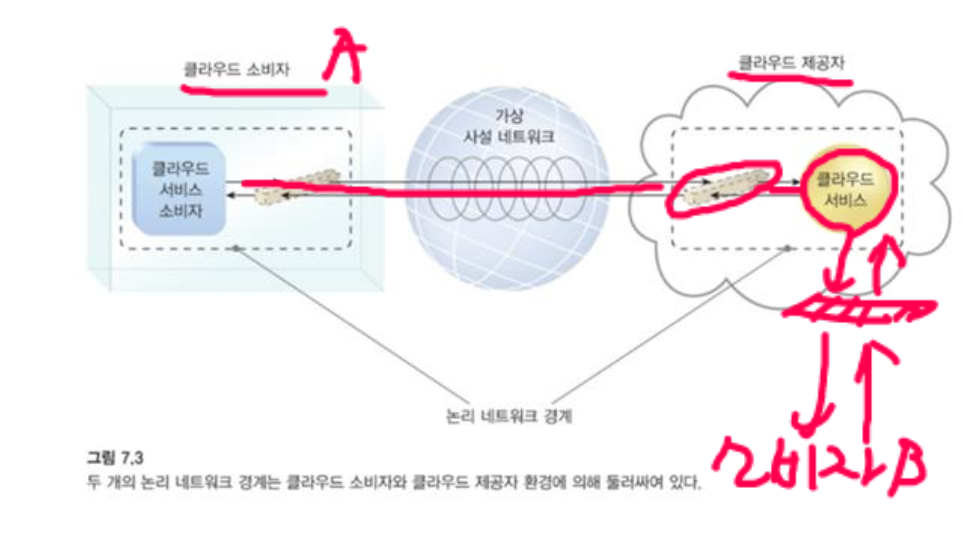
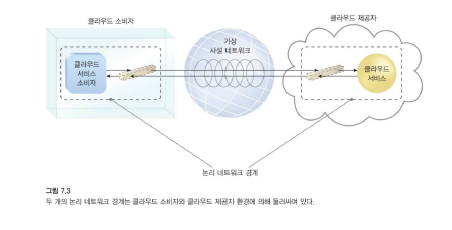
논리 네트워크 경계는 통신 네트워크의 나머지 부분과 특정 네트워크 환경을 분리하는 것으로 정의된다.
-
논리적 네트워크 경계는 관련된 클라우드 기반 IT 자원 그룹을 포함하고 격리할 수 있는 가상 네트워크 경계를 설정합니다.
- 경계를 기반으로 클라우드 공간과 아닌 공간을 구분할 수 있다.

- 경계를 기반으로 클라우드 공간과 아닌 공간을 구분할 수 있다.
-
이 메커니즘은 다음과 같이 구현될 수 있습니다.
-
클라우드의 IT 자원을 승인되지 않은 사용자로부터 격리
-
클라우드의 IT 자원을 비사용자로부터 격리
-
클라우드의 IT 자원을 클라우드 소비자로부터 격리
-
격리된 IT 자원에 사용할 수 있는 대역폭 제어
-
-
논리적 네트워크 경계는 일반적으로 데이터 센터의 연결을 제공하고 제어하는 네트워크 장치를 통해 설정됩니다.
-
가상 방화벽
- 인터넷과의 상호 작용을 제어하면서 격리된 네트워크와의 네트워크 트래픽을 능동적으로 필터링하는 IT 자원
-
가상 네트워크
-
일반적으로 VLAN을 통해 얻는 IT 자원으로 데이터 센터 인프라 내의 네트워크 환경을 격리시킨다.
-
각각 사용자 전용의 네트워크가 있는 것 같은 효과
-
-

-
경계는 통신을 보호하는 VPN(Virtual Private Network)을 통해 연결됩니다.
-
VPN은 일반적으로 통신 엔드포인트 간에 전송되는 데이터 패킷의 지점 간 암호화로 구현되기 때문입니다.
-
허가된 사용자 만 해독이 가능하다.
- 전용망을 쓰는 것과 같은 효과
-
-
2. 가상 서버
-
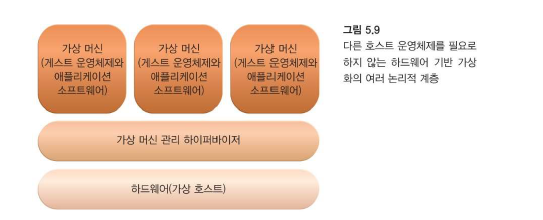
가상 서버는 물리적 서버를 에뮬레이트하는 가상화 소프트웨어의 한 형태입니다.
-
가상 서버는 클라우드 소비자에게 개별 가상 서버 인스턴스를 제공함으로써 여러 클라우드 소비자와 동일한 물리적 서버를 공유하기 위해 클라우드 공급자가 사용합니다.
-
공유할 수 있는 물리적 서버의 수는 용량에 따라 제한됩니다.

Operating System-Based Virtualization
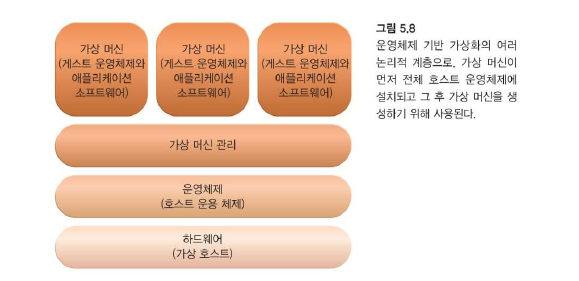
Hardware-Based Virtualization
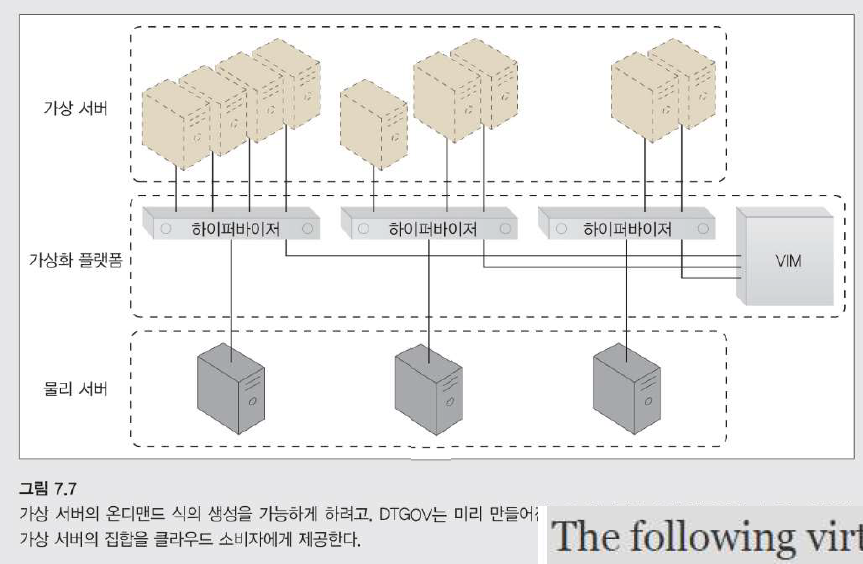
- 가상 서버의 온디맨드식 생성을 가능하게 하기 위해, DTGOV는 미리 만들어진 VM 이미지를 통해 만들어질 수 있는 템플릿 가상 서버의 집합을 클라우드 소비자에게 제공한다.
- 다음 가상 서버 패키지는 DTGOV의 클라우드 소비자에게 제공된다. 각 패키지에는 서로 다른 미리 정의된 성능 구성 및 제한 사항이 있다.
- 작은 가상 서버 인스턴스
- 1개의 가상 프로세서 코어, 4GB 가상 RAM, 루트 파일 시스템 내의 20GB 스토리지 공간
- 중간 가상 서버 인스턴스
- 2개의 가상 프로세서 코어, 8GB 가상 RAM, 루트 파일 시스템 내의 20GB 스토리지 공간
- 큰 가상 서버 인스턴스
- 8개의 가상 프로세서 코어, 16GB 가상 RAM, 루트 파일 시스템 내의 20GB 스토리지 공간
- 메모리가 큰 가상 서버 인스턴스
- 8개의 가상 프로세서 코어, 64GB 가상 RAM, 루트 파일 시스템 내의 20GB 스토리지 공간
- 프로세서가 큰 가상 서버 인스턴스
- 32개의 가상 프로세서 코어, 16GB 가상 RAM, 루트 파일 시스템 내의 20GB 스토리지 공간
- 매우 큰 가상 서버 인스턴스
- 128개의 가상 프로세서 코어, 512GB 가상 RAM, 루트 파일 시스템 내의 40GB 스토리지 공간
3. 클라우드 스토리지 장치
-
클라우드 저장 장치 메커니즘은 클라우드 기반 프로비저닝을 위해 특별히 설계된 저장 장치를 나타냅니다.
-
클라우드 저장 장치는 일반적으로 종량제 메커니즘을 지원하는 고정 증가 용량 할당(fixed-increment capacity allocation)을 제공할 수 있습니다.
-
클라우드 저장 장치는 클라우드 저장 서비스를 통해 원격 접속을 위해 노출될 수 있습니다.
클라우드 프로비저닝
-
클라우드 프로비저닝(provisioning)은 클라우드 공급자의 자원과 서비스를 고객에게 제공하는 것입니다.
-
클라우드 프로비저닝은 고객이 클라우드 공급자로부터 클라우드 서비스 및 리소스를 조달하는 방법과 관련된 클라우드 컴퓨팅 모델의 핵심 기능입니다.
-
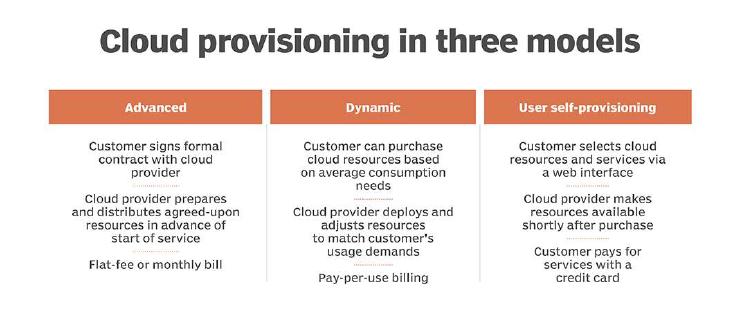
3가지 대표적인 방식
-
Dynamic
- 요청하는 만큼 제공한다.
-
Advanced
- 사전에 계약한 만큼이 제공된다.
-
User self-provisioning
- 사용자가 필요한 만큼 스스로 결제해서 사용한다.
-
클라우드 스토리지 수준
-
클라우드 저장 장치 메커니즘은 데이터 저장의 공통 논리 단위를 제공합니다.
-
파일 – 데이터 컬렉션은 폴더에 있는 파일로 그룹화됩니다.
-
블록 – 가장 낮은 수준의 스토리지이며 하드웨어에 가장 가까운 블록은 개별적으로 접근할 수 있는 가장 작은 데이터 단위입니다.
-
데이터 세트 – 데이터 세트는 테이블 기반, 구분 기호 또는 레코드 형식으로 구성됩니다.
-
오브젝트 – 데이터 및 관련 메타데이터가 웹 기반 리소스로 구성됩니다.
<meta>와<body>, 즉 데이터와 메타가 같이 있다.
-
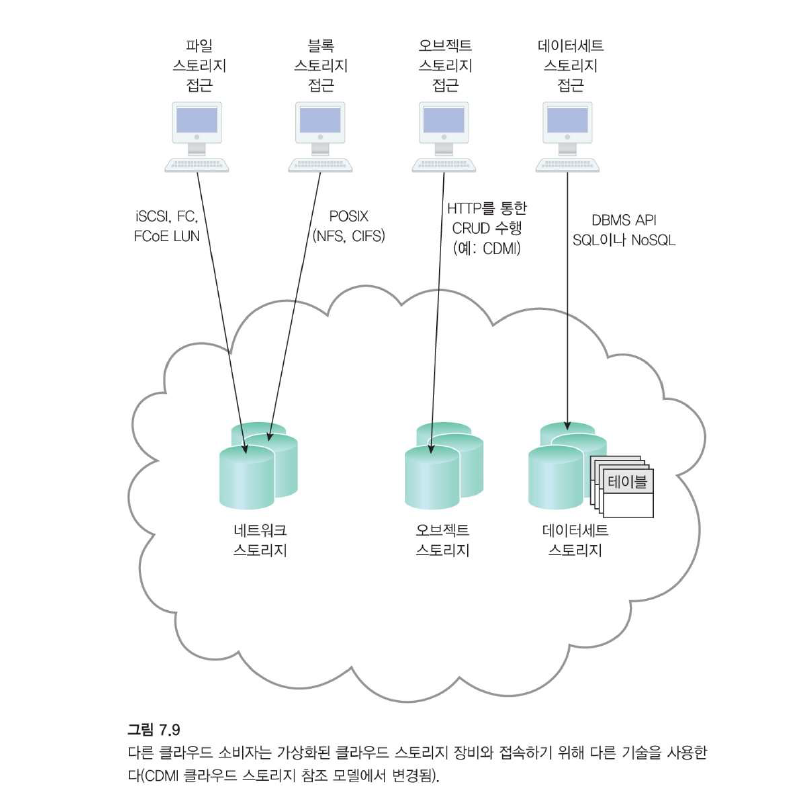
네트워크 스토리지 인터페이스
파일, 블록
-
블록 스토리지는 데이터가 저장 및 접근할 수 있는 가장 작은 단위이며 하드웨어에 가장 가까운 스토리지 형식인 고정 형식(데이터 블록이라고 함)이어야 합니다.
-
일반적으로 파일 수준 스토리지보다 성능이 우수합니다.
- 네트워크로 연결된 스토리지 장치는 일반적으로 다음 범주 중 하나에 속합니다.
- 스토리지 에어리어 네트워크(SAN, Storage Area Network)
- 물리적 데이터 저장 매체는 전용 네트워크를 통해 연결되고 산업 표준 프로토콜을 사용하여 블록 수준의 데이터 저장 액세스 제공
- 네트워크 결합 스토리지(NAS, Network-Attached Storage)
- 하드 드라이브 배열(Hard drive arrays)는 네트워크를 통해 연결하고 네트워크 파일 시스템(NFS, Network File System)이나 서버 메시지 블록(SMB, Server Message Block)과 같은 파일 중심 데이터 접근 프로토콜을 사용하여 데이터 액세스를 용이하게 하는 이 전용 장치에 의해 포함 및 관리된다.
오브젝트 스토리지 인터페이스
오브젝트
-
다양한 유형의 데이터를 웹 리소스로 참조 및 저장할 수 있습니다.
-
이를 오브젝트 스토리지라고 하며, 이는 다양한 데이터 및 미디어 유형을 지원할 수 있는 기술을 기반으로 합니다.
-
이 인터페이스를 구현하는 클라우드 스토리지 장치 메커니즘은 일반적으로 HTTP를 기본 프로토콜로 사용하는 REST 또는 웹 서비스 기반 클라우드 서비스를 통해 액세스할 수 있습니다.
데이터베이스 스토리지 인터페이스
데이터세트
- 데이터베이스 스토리지 인터페이스를 기반으로 하는 클라우드 스토리지 장치 메커니즘은 일반적으로 기본 스토리지 작업 외에 쿼리 언어를 지원합니다.
-
관계형 데이터 스토리지(RDB)
-
전통적으로 많은 사내 IT 환경은 관계형 데이터베이스 또는 관계형 데이터베이스 관리 시스템(RDBMS)을 사용하여 데이터를 저장합니다.
-
관계형 데이터베이스(또는 관계형 저장 장치)는 테이블을 사용하여 유사한 데이터를 행과 열로 구성합니다.
-
관계형 스토리지 작업에는 일반적으로 업계 표준 SQL(Structured Query Language) 사용이 포함됩니다.
-
복잡한 관계가 있거나 많은 양의 데이터를 포함하는 데이터베이스는 특히 클라우드 서비스를 통해 원격으로 액세스할 때 더 높은 처리 오버헤드와 대기 시간으로 영향을 받을 수 있습니다.
-
-
비관계형 데이터 스토리지(NoSQL(Not Only))
-
비관계형 스토리지를 사용하는 주된 동기는 관계형 데이터베이스에 의해 부과될 수 있는 잠재적인 복잡성과 처리 오버헤드를 방지하는 것입니다.
-
그러나 많은 비관계형 스토리지 메커니즘은 독점적이므로 데이터 이식성을 심각하게 제한할 수 있습니다.
-
Dynamo(Key-value), HBase(column), MongoDB(document), Neptune(graph)...
-
Hadoop
-
구글의 맵리듀스와 HDFS를 구현한 Java기반 오픈소스 프레임워크
-
HDFS: 대용량 데이터을 분산시키고 저장하고 관리 (분산저장기술)
-
MapReduce: 대용량 데이터의 분석을 수행 (분산처리기술)
-
-
클라우드 컴퓨팅 분야 대용량 처리분석 오픈소스 프로젝트
-
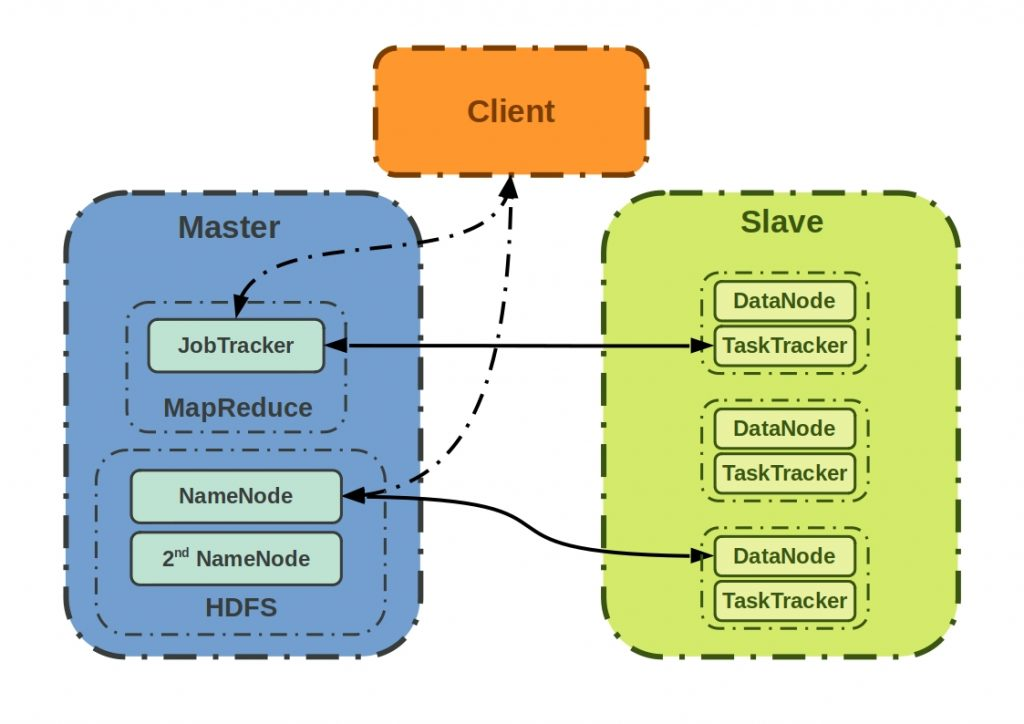
Hadoop의 구성요소
-
Client
- Name Node를 통해 정보를 받고 이후 직접적으로 Data Node와 통신
-
Master Node
작업되는 애들을 관리하거나 할당하고 얘들의 정보를 가지고 있는 애들
-
Job Tracker와 Name Node를 하는 노드로서, slave node에 대한 정보와 실행을 할 Tasks에 대한 관리
- Job Tracker: slave 노드에 Task를 할당하는 역할과 모든 Task를 모니터링
-
-
Slave Node
할당 받는 애들 (실제 작업을 하는 애들)
-
Task Tracker와 Data Node를 하는 노드로서, 실제로 데이터를 분산되어 가지고 있으며 Client에서 요청이 오면 데이터를 전달하는 역할 및 담당 Task를 수행하는 역할
- Task Tracker: Task가 위치한 HDFS의 데이터를 사용하여 MapReduce를 수행
-
-
MapReduce
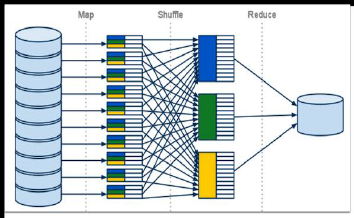
-
구글에서 대용량 데이터 처리를 분산 병렬 컴퓨팅에서 처리하기 위한 목적으로 개발한 소프트웨어 프레임워크
-
대용량 데이터에 대한 병렬 처리는 기존의 단일 머신 상에서는 어려웠던 대용량 데이터 처리를 보다 저비용으로 실현
-
데이터집약적인 분산처리 모델 - 웹인덱스, 데이터마이닝, 과학적 시뮬레이션과같은 대규모 데이터 처리에 많이 사용됨
-
MapReduce = Map + Reduce
-
Map: 흩어져 있는 데이터를 관련있는 데이터끼리 묶는 작업을 통해임시 데이터 집합으로 변형
-
Reduce: Map작업에서 생성된 임시 데이터 집합에서 중복 데이터를 제거하고 원하는 데이터를 추출하는 작업 진행
-
처리 순서

1. Splitting
- 입력한 파일 값을 chunk 단위로 분할
2. Mapping
-
분할된 chunk를 Map 함수로 전달하면, Map 함수를 거치면서 임시 데이터 결과(key-value pair)가 메모리에 저장됨.
- ex) Map 함수는 공백을 기준으로 문자를 분리, 단어의 개수를 확인
3. Shuffling
-
메모리에 저장되어 있는 Map 함수의 출력 데이터를 partitioning과 sorting하여 로컬 디스트에 저장.
- 네트워크를 통해 Reducer의 입력 데이터로 전달
4. Reducing
- 요약된 결과(ex. 합)을 계산하여 표시
HDFS (Hadoop Distributed File System)

-
Cloud File System
-
대규모 데이터를 분산, 저장, 관리하기 위한 분산 파일 시스템
-
저장하고자 하는 파일을 블록 단위(각 블록은 기본적으로 64MB 또는128MB)로 나누어 분산된 서버에 저장
-
이를 통해 효율적인 MapReduce 처리 가능

-

-
하나의 NameNode와 다수의 DataNode로 구성
-
NameNode
- 메타데이터(디렉토리명, 파일명, 파일 블록 등에 대한 트리 형태의 네임 스페이스)를 관리
-
DataNode
- 블록 단위로 나뉜 데이터를 저장하는 데이터 서버로서, NameNode와 클라이언트 어플리케이션의 데이터 입출력 요청을 관리
-
-
각 블록들은 복제되어 여러 데이터노드에 저장됨
- Fault recovery를 위해 기본 3개의 replication (각 블록은 서로다른 3개의 머신의 저장되어 있다는 의미)
-
클라이언트 어플리케이션이 파일에 접근하고자 하는 경우
-
NameNode와 통신하여 file을 구성하고 있는 블록들의 정보와 DataNode의 블록의 위치 정보를 제공받음
-
이후 데이터를 읽기 위해 DataNode와 직접 통신
- 읽기 작업만 일어나는 NameNode는 bottleneck이 되지 않음
-
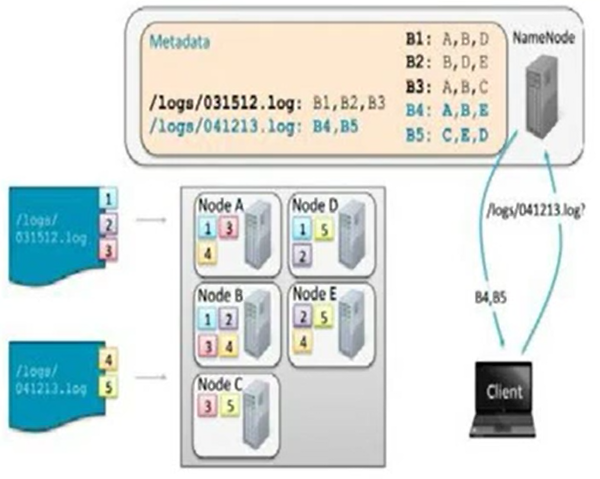
-
NameNode의 메타데이터 정보를 통해
-
/logs/031512.log 파일: B1 + B2 + B3 블록
-
B1은 A, B, D DataNode에 존재 (3 replication)
-
중복 저장되어 있다.
-
A, B, D 중에서 idle한 노드를 선택하여 해당 노드에 데이터 엑세스
-
-
-
/logs/041213.log 파일: B4 + B5 블럭
-
-
NameNode의 가용성
-
NameNode가 중단되면 데이터 접근 불가능
- 고가용성을 위해 2개의 네임노드를 구성(Active와 Standby) 가능
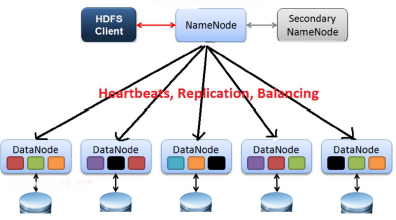
- Heartbeats: 너 잘 동작하고 있니?
- Replication: 중복 저장
- Balancing: 요청이 집중되지 않도록 분산
-
Hadoop Ecosystem
-
Ecosystem
-
중앙화된 시스템의 활용성을 더 높이기 위해 다양한 소프트웨어가 추가된 시스템
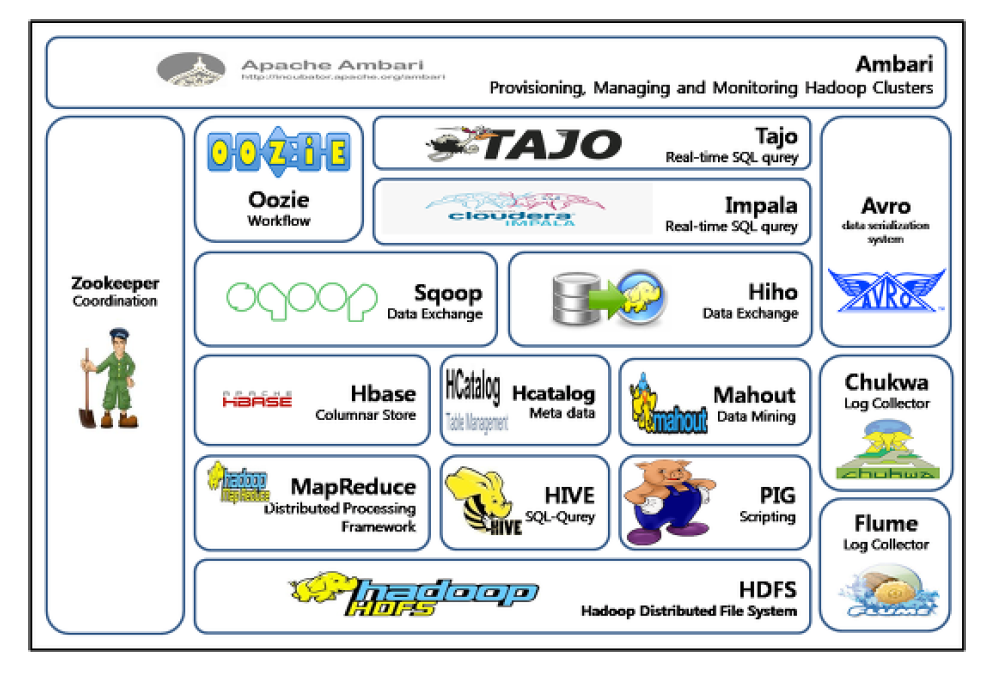
-
Apache Spark
-
빅데이터 워크로드에 주로 사용되는 분산처리 오픈소스 시스템
-
성능비교
-
Batch processing 경우 – MapReduce에 비하여 약 10배 더 빠름
-
In-Memory Analytics 경우 – 약 100배 더 빠름
-
-
비교
-
Hadoop은 HDFS 분산형 파일 시스템과 MapReduce 프로세싱 컴포넌트를 제공함. Spark가 필수적으로 필요하지는 않음
-
Spark도 Hadoop HDFS 외에도 다른 클라우드 기반 데이터 플랫폼과도 융합 될 수 있어 Hadoop이 필수적으로 필요하지는 않음
-
다만 Spark는 원래 Hadoop용으로 설계된 솔루션이기 때문에, Hadoop과 Spark를 함께 사용할 때 최상의 효과를 낼 수 있음
-
-
장점
-
Hadoop: 정적이거나 batch processing 경우
-
Spark: streaming data 처리 또는 machine learning 경우
-
4. 클라우드 사용 모니터
-
클라우드 사용량 모니터링 메커니즘은 IT 자원 사용량 데이터 수집 및 처리를 담당하는 가볍고 자율적인 소프트웨어 프로그램입니다.
-
수집하도록 설계된 사용 메트릭의 유형과 사용 데이터를 수집해야 하는 방식에 따라 클라우드 사용 모니터는 다양한 형식으로 존재할 수 있습니다.
-
모니터링 에이전트
-
자원 에이전트
-
폴링 에이전트
-
모니터링 에이전트
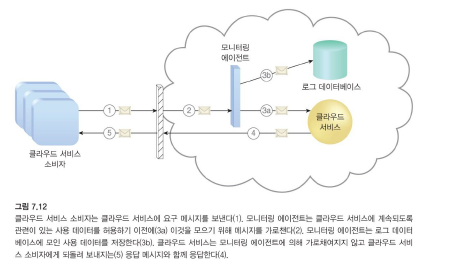
-
모니터링 에이전트는 서비스 에이전트로 존재하고 기존 통신 경로를 따라 상주하여 데이터 흐름을 투명하게 모니터링 및 분석하는 중재자이며, 이벤트 기반 프로그램이다.
-
일반적으로 네트워크 트래픽 및 메시지 메트릭을 측정하는 데 사용됩니다.
-
이벤트 기반 동작이기에 도착해야만 실행된다.
-
대상이 네트워크 트래픽이다.
-
자원 에이전트
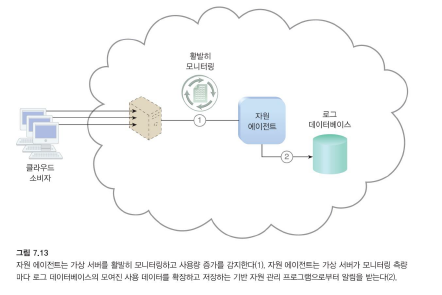
-
자원 에이전트는 특수 자원 소프트웨어와 이벤트 기반 상호 작용을 통해 사용 데이터를 수집하는 처리 모듈입니다.
-
이 모듈은 자원 소프트웨어 수준에서 사전 정의되고 관찰 가능한 이벤트(예: 시작, 일시 중단, 재개 및 수직적 확장)를 기반으로 사용 메트릭을 모니터링하는 데 사용됩니다.
- 이벤트 기반 동작
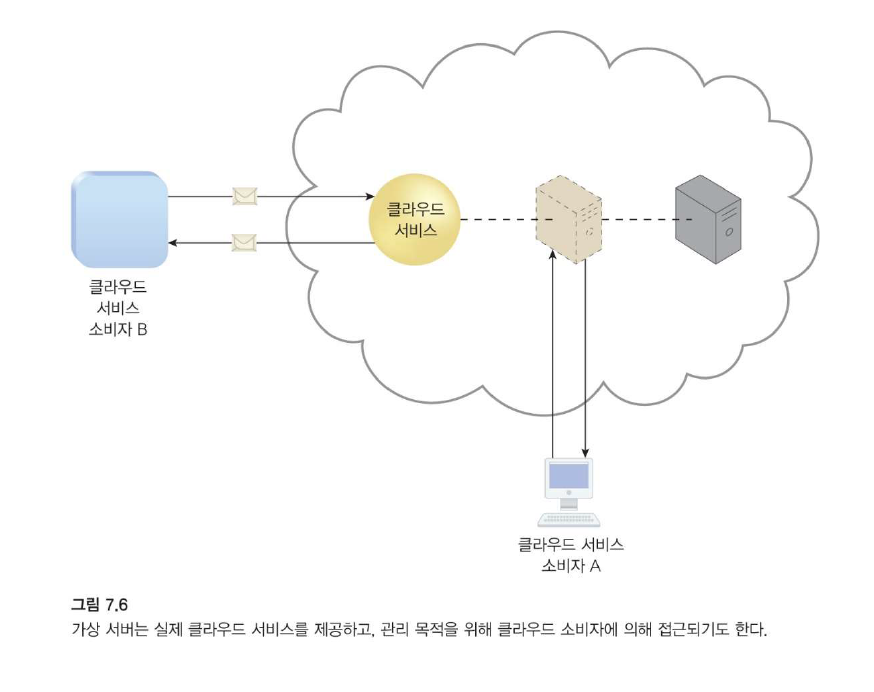
폴링 에이전트
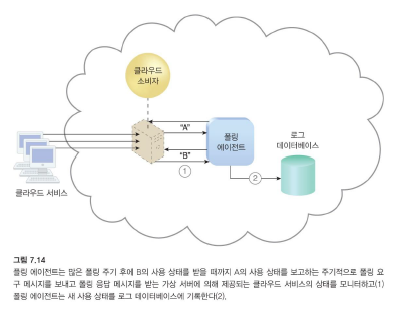
위의 그림에서 클라우스 서비스 <-> 클라우드 소비자
-
폴링 에이전트는 IT 자원을 폴링하여 클라우드 서비스 사용 데이터를 수집하는 처리 모듈입니다.
-
업타임 및 다운타임과 같은 IT 자원 상태를 주기적으로 모니터링하는 데 일반적으로 사용됩니다.
-
정해진 시간마다 정기적으로 모니터링한다.
- 이벤트 기반 X
-
제대로 작동되고 있는지에 대해 상태를 확인한다.
-
5. 자원 복제
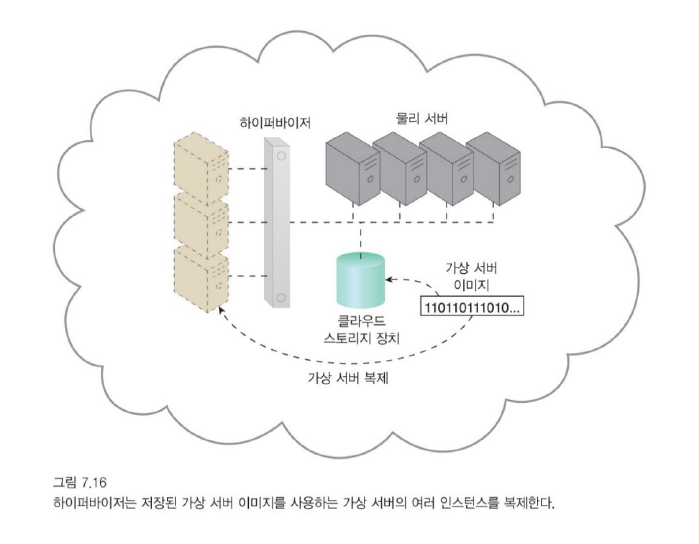
그림과 다르게 하나의 물리서버 하나당 하나의 하이퍼바이저가 존재
-
동일한 IT 자원의 여러 인스턴스 생성으로 정의되는 복제는 일반적으로 IT 자원의 가용성 및 성능 향상이 필요할 때 수행됩니다.
- 동일한 설정을 가상 서버 이미지를 생성하여 복제한다.
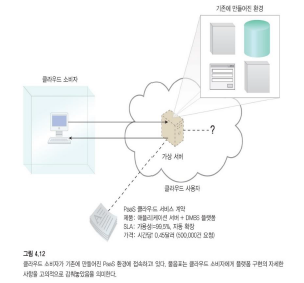
6. 기성 환경
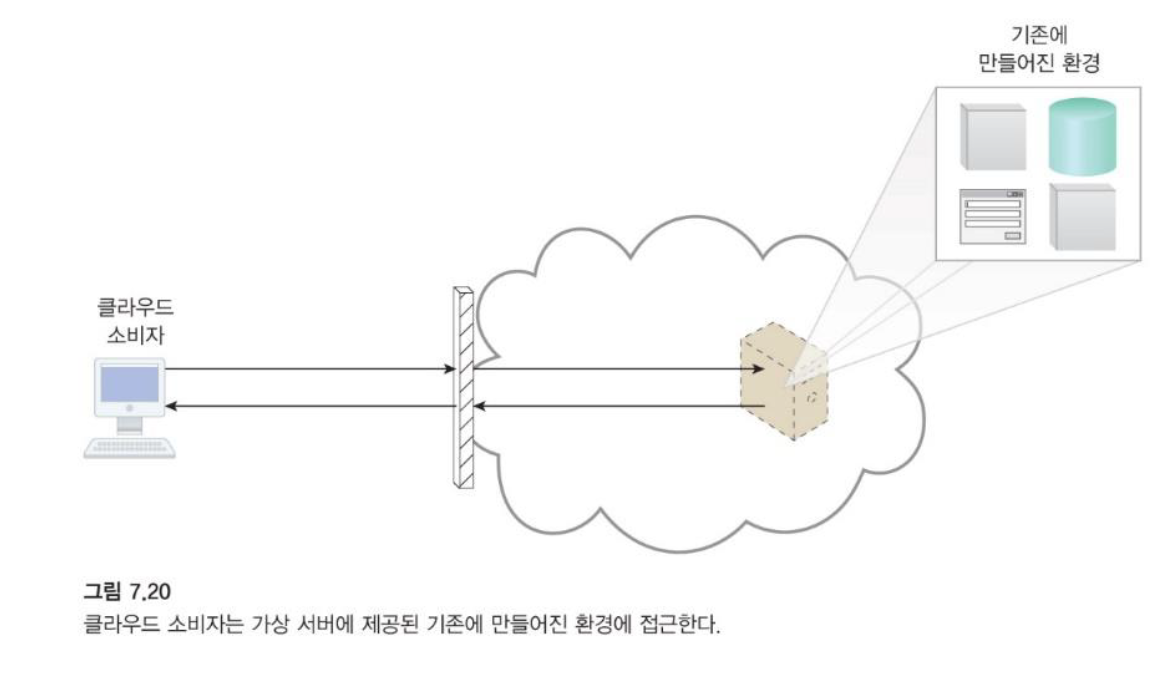
-
기성 환경 메커니즘은 클라우드 소비자가 사용할 준비가 된 이미 설치된 IT 자원 세트로 구성된 사전 정의된 클라우드 기반 플랫폼을 나타내는 PaaS 클라우드 제공 모델의 정의 구성 요소입니다.
-
이러한 환경은 클라우드 소비자가 클라우드 내에서 자체 서비스 및 애플리케이션을 원격으로 개발 및 배포하는 데 활용됩니다.
-
기성환경에는 소프트웨어 개발 키트(SDK, Software Development Kit)가 있다
- 클라우드 소비자가 원하는 프로그래밍 스택을 구성하는 개발 기술에 프로그래밍 방식으로 접근할 수 있게 해주는 것
-
PaaS
- PaaS 제공 모델은 일반적으로 이미 배포 및 구성된 IT 자원으로 구성된 사전 정의된 "즉시 사용 가능한" 환경을 나타냅니다.
- PaaS는 맞춤형 애플리케이션의 전체 제공 수명 주기를 지원하는 데 사용되는 사전 패키지된 제품 및 도구 세트를 설정하는 기성 환경의 사용에 의존합니다(주로 정의됨).