클라우드를 가능하게 하는 기술
1. 광대역 네트워크 및 인터넷 아키텍처(BROADBAND NETWORKS AND INTERNET ARCHITECTURE) (p.119)
-
모든 클라우드는 네트워크에 연결되어야 합니다.
- 인터넷 또는 인터넷은 IT 자원의 원격 프로비저닝을 허용하고 유비쿼터스 네트워크 액세스를 직접 지원합니다.
-
인터넷 서비스 제공업체(ISPs)
-
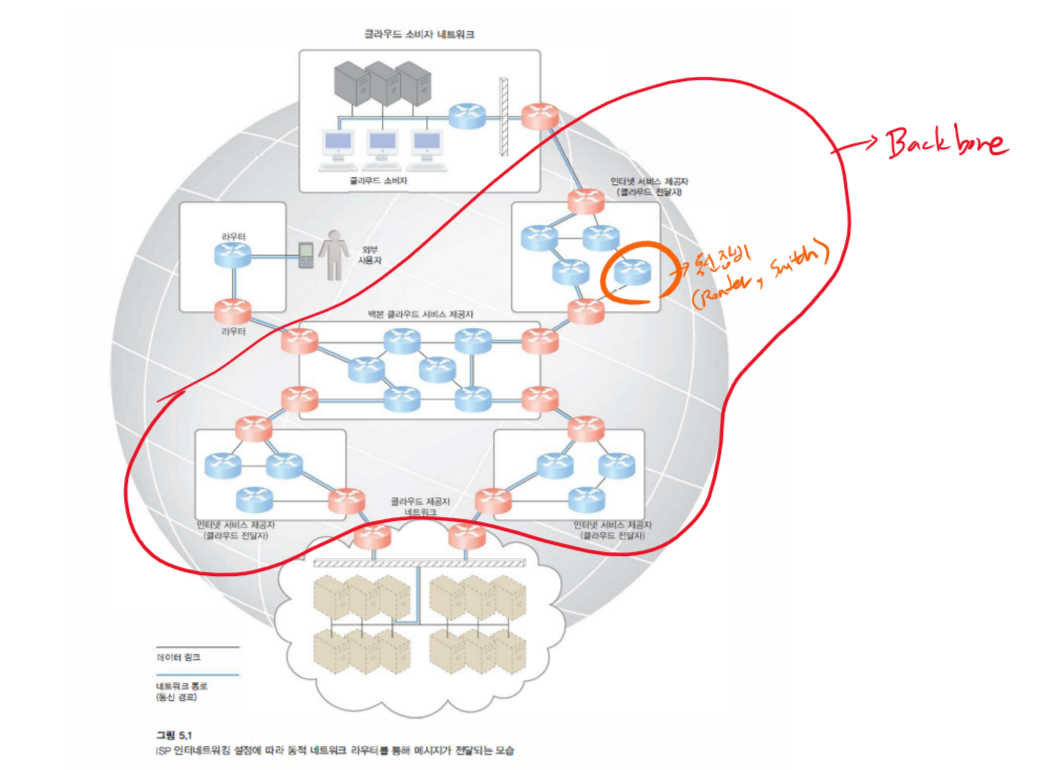
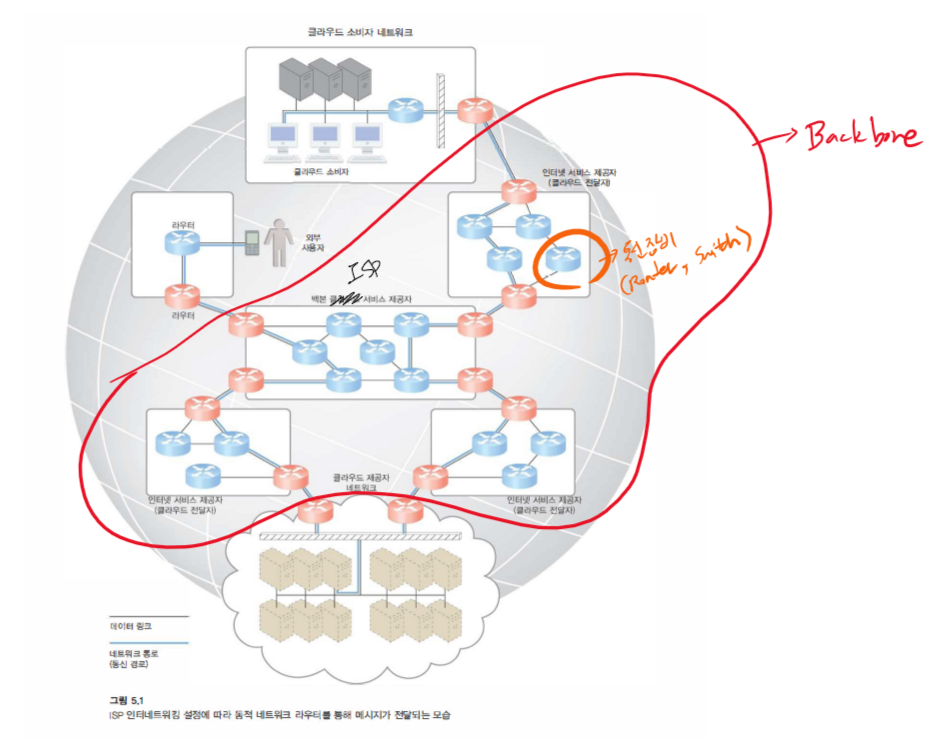
ISP에 의해 구축 및 배포되는 인터넷 최대 백본 네트워크 (backbone network, network core)는 전 세계 다국적 네트워크를 연결하는 핵심 라우터에 의해 전략적으로 상호 연결됩니다.
-
ISP 네트워크는 다른 ISP 네트워크 및 다양한 조직과 상호 연결
-
-
인터네트워킹 아키텍처를 구성하는 데 사용되는 두 가지 기본 구성 요소는 다음과 같습니다.
1) 비연결 패킷 교환(데이터그램 네트워크) (connectionless packet switching (datagram networks))
2) 라우터 기반 상호 연결 (router-based interconnectivity))
1) Connectionless Packet Switching (Datagram Networks)
-
종단간 (End-to-End,송신 - 수신 쌍) 데이터 흐름은 네트워크 스위치와 라우터를 통해 수신 및 처리되는 제한된 크기의 패킷으로 분할된 다음 패킷은 큐에 대기한 후 중간 노드에서 다음 노드로 전달됩니다.
-
각 패킷은 인터넷 프로토콜(IP) 또는 미디어 액세스 제어(MAC, Media Access Control) 주소와 같은 필요한 위치 정보를 전송하며 모든 소스, 중개 및 대상 노드에서 처리 및 전송됩니다.
2) Router-Based Interconnectivity
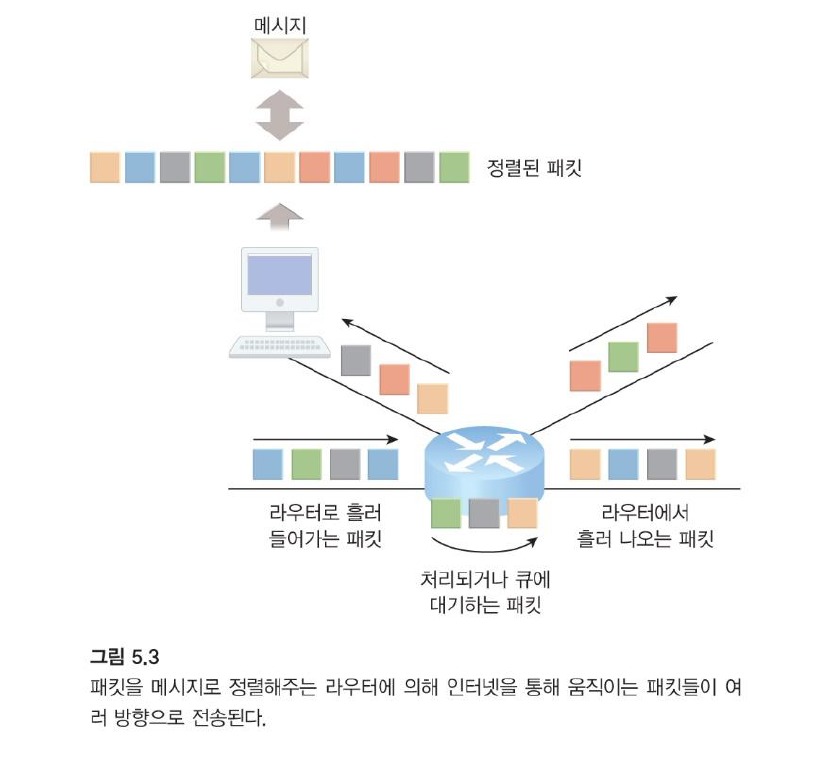
그림에 뒤죽박죽 패킷 그룹이 들어오면서 메시지가 합쳐지는 인터네트워킹의 기본적인 메커니즘이 나타나 있다.
-
라우터는 여러 네트워크에 연결되어 패킷을 전달하는 장치입니다.
-
연속된 패킷이 한 데이터 플로우의 일부일 때 라우터는 소스 노드와 대상 노드 간의 통신 경로상에 있는 다음 노드의 위치를 알려주는 네트워크 토폴로지 정보를 유지하면서 개별적으로 각 패킷을 처리하고 전송합니다.
-
라우터는 패킷 근원지와 패킷 목적지 모두에 대해 접근할 수 있으므로 패킷 전달을 위한 가장 효율적인 홉으로 네트워크 트래픽 및 게이지(궤관?)를 관리합니다.
-
클라우드 제공자와 클라우드 소비자를 연결하는 통신 경로는 여러 ISP 네트워크를 포함할 수 있습니다. 인터넷의 그물망(매쉬) 구조는 런타임에 결정되는 여러 네트워크 경로를 사용하여 인터넷 호스트를 연결합니다.
-
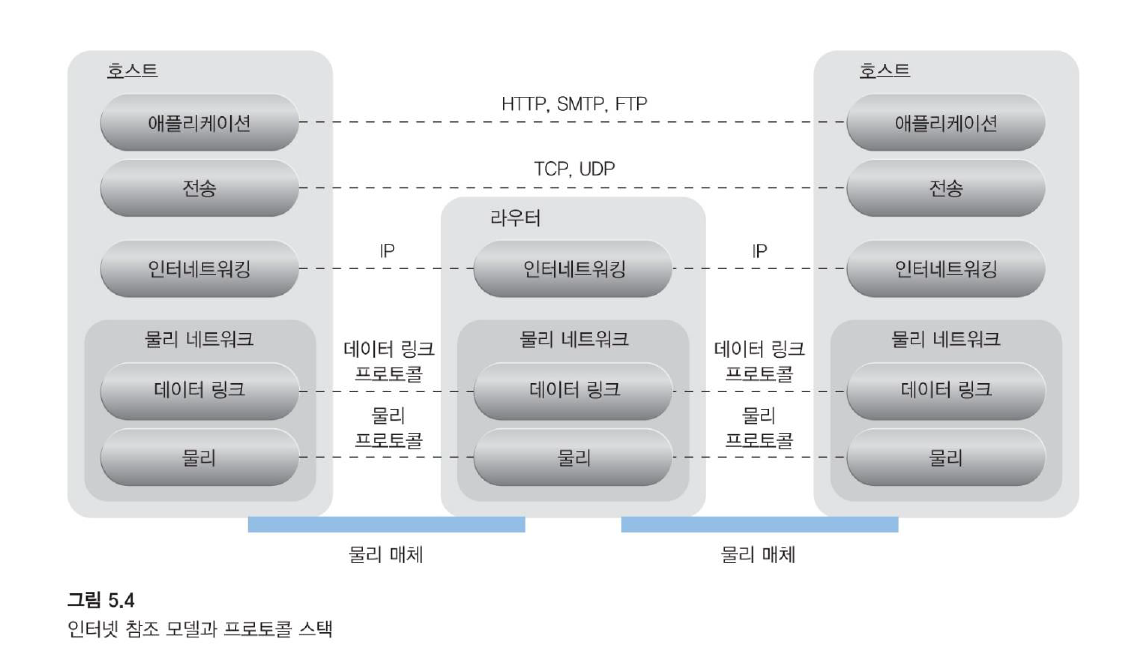
이것은 다음과 같이 인터넷의 인터네트워킹 레이어를 구현하고 다른 네트워크 기술과 상호 작용하는 ISP에 적용됩니다.
-
물리적 네트워크 (Physical Network)
-
IP 패킷은 인접 노드를 연결하는 기본 물리적 네트워크를 통해 전송됩니다.
-
물리적 네트워크는 인접 노드 간의 데이터 전송을 제어하는 바다 데이터 링크 계층과 유무선 매체를 통해 데이터 비트를 전송하는 물리적 계층으로 구성됩니다.
-
-
전송 계층 프로토콜 (Transport Layer Protocol)
- 전송 제어 프로토콜(TCP) 및 사용자 데이터그램 프로토콜(UDP)과 같은 전송 계층 프로토콜은 인터넷을 통한 데이터 패킷 탐색을 용이하게 하는 표준화된 종단 간 통신 지원을 제공하기 위해 IP를 사용합니다.
-
응용 계층 프로토콜 (Application Layer Protocol)
- HTTP, SMTPfore-mail 및 IP 전화용 SIP와 같은 프로토콜은 인터넷을 통한 특정 데이터 패킷 전송 방법을 표준화하고 활성화하기 위한 전송 계층 프로토콜을 사용합니다.
-
기술과 사업적 고려 사항 (Technical and Business Considerations)
접속 문제(Connectivity Issues)
-
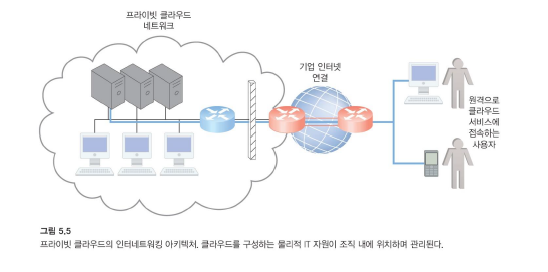
기존의 온프레미스 배포 모델에서 엔터프라이즈 애플리케이션 및 다양한 IT 솔루션은 일반적으로 조직의 자체 데이터 센터에 있는 중앙 집중식 서버 및 스토리지 장치에서 호스팅됩니다.
-
스마트폰 및 노트북과 같은 최종 사용자 장치는 중단 없는 인터넷 연결을 제공하는 기업 네트워크를 통해 데이터 센터에 액세스합니다.
-
-
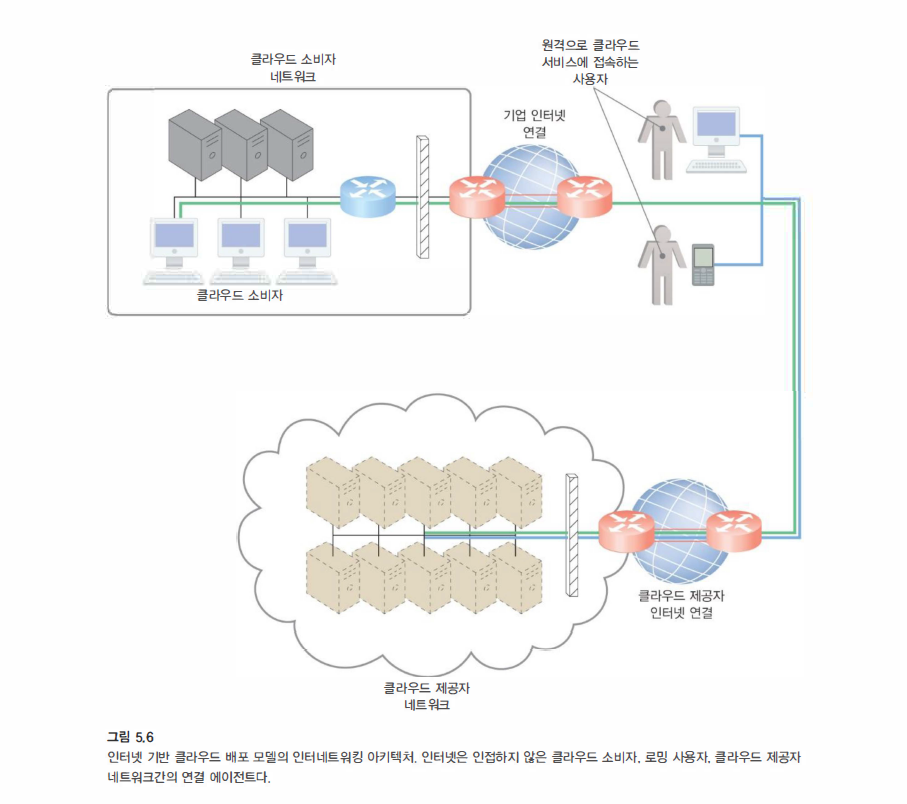
인터넷을 통해 네트워크에 연결된 종단 사용자 장치는 클라우드에 있는 중앙 서버와 애플리케이션에 지속적인 접근이 가능하다.
-
퍼블리 클라우드라고 생각하자
-
조직이 사용하는 곳은 초록 라인을 사용한다.
- 조직 외부에서도 직원이 인터넷을 통하여 클라우드를 접속한다.
-
-
사용자 기능에 적용되는 클라우드의 가장 중요한 특성은 사용자가 기업 네트워크 내부 또는 외부에 있는지 여부에 관계없이 동일한 네트워크 프로토콜을 사용하여 중앙 IT 자원에 접근할 수 있어야 한다.

네트워크 대역폭과 대기 시간 문제(Network Bandwidth and Latency Issues)
대역폭(bandwidth): 초당 몇 비트씩 보낼 수 있는가 (bps)
- 빨강이 공유 데이터 링크
- 파랑이 데이터 링크
- 가장 짧은 시간이 end-to-end 대역폭
- 회색부분의 shared link부분이 관리 불가
- cloud carrier들의 협조가 필요하다.


- 네트워크를 ISP에 연결하는 데이터 링크의 대역폭에 영향을 받는 것 외에도 종단 간 대역폭은 중간 노드를 연결하는 공유 데이터 링크의 전송 용량에 의해 결정됩니다.
-
시간 지연(Latency)이라고 하는 대기 시간(time delay)은 패킷이 한 데이터 노드에서 다른 데이터 노드로 이동하는 데 걸리는 시간입니다.
-
대기 시간은 데이터 패킷 경로의 각 중간 노드를 지날 때마다 증가합니다.
-
네트워크 인프라의 전송 큐는 네트워크 대기 시간을 증가시키는 중부하 조건을 초래할 수 있습니다.
-
네트워크는 공유 노드의 트래픽 조건에 따라 달라지므로 인터넷 대기 시간이 매우 가변적이며 예측할 수 없는 경우가 많습니다.
-
-
"최선의 노력" 서비스 품질(QoS, quality-of-service)의 패킷 네트워크는 일반적으로 선착순 방식으로 패킷을 전송합니다.
-
최석의 노력은 하지만 보장하지는 못한다.
-
혼잡한 네트워크 경로를 사용하는 데이터 흐름은 트래픽에 우선 순위가 지정되지 않은 경우 대역폭 감소, 대기 시간 증가 또는 패킷 손실의 형태로 서비스 수준 저하를 겪는다.
- 따라서 조금 융통성이 있는 시스템만 클라우드를 사용하는 것이 좋다.
-
- 대역폭(Bandwidth)은 클라우드로 전송하고 클라우드에서 전송해야 하는 상당한 양의 데이터가 필요한 애플리케이션에 중요하지만, 지연 시간(latency)은 신속한 응답 시간의 비즈니스 요구 사항이 있는 애플리케이션에 중요합니다.
클라우드 전달자와 클라우드 제공자 선택 (Cloud Carrier and Cloud Provider Selection)
-
클라우드 소비자와 클라우드 제공자 간의 인터넷 연결 서비스 수준은 일반적으로 다른 ISP에 의해 결정되며 따라서 경로에 여러 ISP 네트워크가 포함됩니다.
-
여러 ISP에 걸친 QoS 관리는 실행이 어려우며 종단 간 서비스 수준이 비즈니스 요구 사항에 충분한지 확인하기 위해 클라우드 캐리어 양측의 협력이 필요합니다.
-
따라서 클라우드를 채택하면 지연 시간(latency) 및 대역폭(bandwidth) 요구 사항이 더 완화된 애플리케이션에 더 쉽게 사용할 수 있습니다.
2. 데이터 센터 기술 (Data Center Technology)

<AWS>

- IT 자원을 서로 근접하게(in close proximity) 그룹화하여 권한 공유, 공유 IT 자원 사용의 효율성(power sharing, higher efficiency) 및 IT 인력의 접근성 향상(improved accessibility)
IDC (Internet Data Center)
-
데이터 센터는 일반적으로 다음 기술 및 구성 요소로 구성됩니다.
-
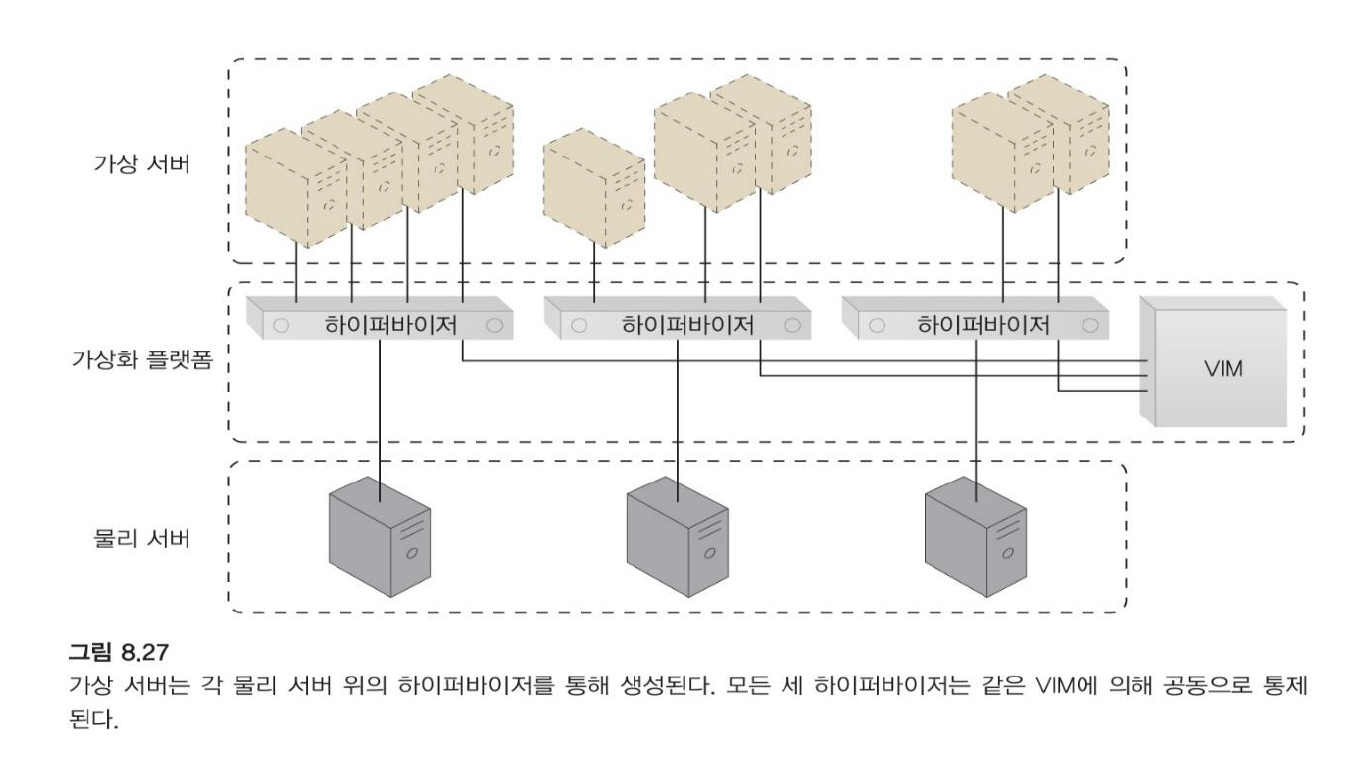
가상화 (Virtualization)
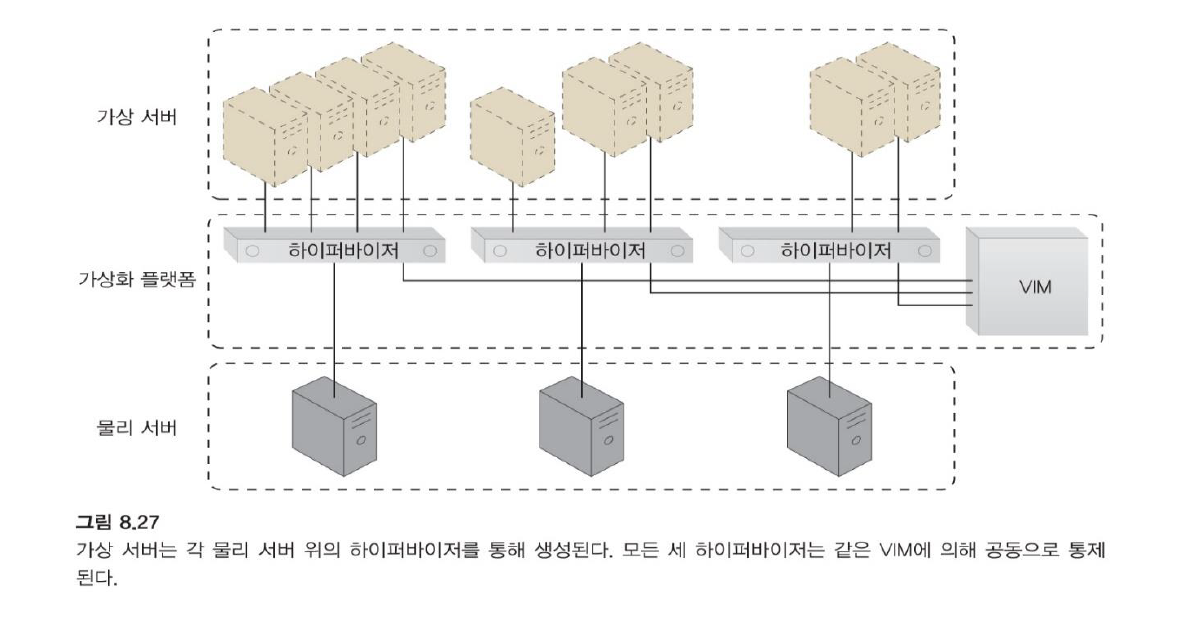
물리적 서버 하나당 하이퍼바이저 한 개!
VIM은 하이퍼바이저들을 관리한다.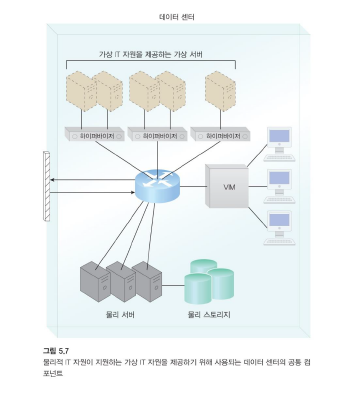
-
데이터 센터는 물리적 및 가상화된 IT 자원으로 구성됩니다.
-
물리적 IT 자원 계층(IT resource layer)은 하드웨어 시스템 및 운영 시스템과 함께 컴퓨팅/네트워킹 시스템 및 장비를 저장하는 인프라 구조를 말합니다.
-
물리적 컴퓨팅 및 네트워킹 자원을 가상화된 컴포넌트로 추상화하여 자원을 보다 쉽게 할당, 작동, 해제, 모니터링 및 제어(allocate, operate, release, monitor, and control)할 수 있는 가상화 플랫폼에 기반을 둔 웅영 및 관리 도구가 가상화 계층의 통제와 자원 추상화를 담당한다.
-
-
표준화 및 모듈화 (Standardization and Modularity)
-
데이터 센터는 표준화된 하드웨어상에 구축되고, 확장성, 성장 및 빠른 하드웨어 교체(scalability, growth, and speedy hardware replacements)를 지원하는 장비와 시설 인프라의 여러 독립적인 구성 요소를 모은 모듈화된 아키텍처를 이용해 설계된다.
-
모듈화와 표준화는 조달, 획득, 배포, 운영 및 유지 보수에 대한 규모의 경제를 가능하게 하기 때문에 투자 및 운영 비용을 절약하는 핵심적인 요건이다.
-
-
자동화 (Automation)
- 데이터 센터에는 감독 없이 프로비저닝, 구성, 패치 및 모니터링(provisioning, configuration, patching, and monitoring)과 같은 작업을 자동화하는 특수 플랫폼이 있습니다.
-
원격 운용과 관리 (Remote Operation and Management)
-
데이터 센터에 있는 IT 리소스의 대부분의 운영 및 관리 작업은 네트워크의 원격 콘솔 및 관리 시스템을 통해 명령됩니다.
-
장비 관리 및 케이블링 또는 하드웨어 수준의 설치 및 유지 보수와 같은 매우 구체적인 작업을 수행하는 경우를 제외하고 서버가 있는 전용실을 방문하기 위해 기술 인력이 필요하지 않습니다.
-
-
높은 가용성 (High Availability)
-
모든 형태의 데이터 센터의 정전은 서비스를 사용하는 조직의 비즈니스 연속성에 상당한 영향을 미치므로 데이터 센터는 가용성을 유지하기 위해 점점 더 높은 수준의 중복성(redundancy to sustain availability)으로 작동하도록 설계되었습니다.
-
데이터 센터는 시스템 실패에 대비해 통신 링크와 클러스터링된 하드웨어의 로드 밸런싱과 함께 중복되고 방해 받지 않는 전원 공급, 배선, 환경적 제어 서브 시스템을 갖추고 있다.
-
-
보안 인식 설계, 운영 및 관리 (Security-Aware Design, Operation, and Management)
- 물리적 및 논리적 접근 제어 및 데이터 복구 전략과 같은 보안 요구 사항은 비즈니스 데이터를 저장 및 처리하는 중앙 집중식 구조 (centralized structures) 때문에 데이터 센터에 대해 엄격하고 포괄적으로 적용되어야 한다.
-
시설 (Facilities)
-
데이터 센터 시설은 특수 컴퓨팅, 스토리지 및 네트워크 장비가 장착된(outfitted with specialized computing, storage, and network equipment) 맞춤형 설계 장소(custom-designed locations)입니다.
-
-
컴퓨팅 하드웨어 (Storage Hardware)
-
데이터 센터에는 많은 양의 디지털 정보를 유지하기 위해 상당한 저장 용량이 필요한 특수 저장 시스템이 있습니다.
-
스토리지 시스템에는 일반적으로 다음 기술이 포함됩니다.
-
하드디스크 배열 (Hard Disk Arrays)

-
배열은 태생적으로 여러 물리적 드라이버 사이에 데이터를 나누고 복제하며 여분의 디스크를 포함해 성능과 중복성을 향상시킨다.
-
하드디스크 배열 컨트롤러를 통해 실행되는 레이드 (RAID) 스키마를 사용해 구현된다.
-
-
입출력 캐싱 (I/O Caching)
- 데이터 캐싱을 이용해 디스크 접근 시간과 성능을 향상시키는 하드디스크 배열 컨트롤러를 이용해 수행
-
전원 차단 없이 교체 가능한 하드디스크 (Hot-Swappable Hard Disks)
- 전원 차단 없이 배열에서 안전하게 제거될 수 있다.
-
스토리지 가상화 (Storage Virtualization)
- 가상 하드디스크와 스토리지 공유로 이루어진다.
-
빠른 데이터 복제 메커니즘 (Fast Data Replication Mechanisms)
- 용량 복제를 위해 가상 머신의 메모리에서 하이퍼바이저가 읽을 수 있는 파일 형태로 저장하는 스냅샷 기능 포함
-
-
일반적으로 삭제 가능한 미디어에 의존해 백업 및 복구 시스템으로 사용되는 자동화된 테이프 라이브러리와 같이 제3의 중복을 포함한다.
-
네트워크로 연결된 스토리지 장치는 일반적으로 다음 범주 중 하나에 속합니다.
-
스토리지 에어리어 네트워크(SAN, Storage Area Network)
- 물리적 데이터 저장 매체는 전용 네트워크를 통해 연결되고 산업 표준 프로토콜을 사용하여 블록 수준의 데이터 저장 액세스 제공
-
네트워크 결합 스토리지(NAS, Network-Attached Storage)
- 하드 드라이브 배열(Hard drive arrays)는 네트워크를 통해 연결하고 네트워크 파일 시스템(NFS, Network File System)이나 서버 메시지 블록(SMB, Server Message Block)과 같은 파일 중심 데이터 접근 프로토콜을 사용하여 데이터 액세스를 용이하게 하는 이 전용 장치에 의해 포함 및 관리된다.
-
-
-
3. ⭐가상화 기술 (Virtualization Technology)
-
가상화는 물리적 IT 자원을 가상 IT 자원으로 변환하는 과정입니다.
-
가상화된 IT자원은 마치 독립적인 물리 서버에서 구동되는 것처럼 설치되고 실행된다.
-
다음을 포함하여 대부분의 IT 자원은 가상화될 수 있습니다.
-
Servers
가상 머신(Virtual Machine) = 가상 서버
- 물리 서버는 가상 서버로 추상화될 수 있다.
-
Storage
- 물리 스토리지 장치는 가상 스토리지 장치나 가상 디스크로 추상화될 수 있다.
-
Network
-
물리 라우터와 스위치는 VLAN과 같은 논리적인 네트워크 섬유로 추상화할 수 있다.
-
LAN -> VLAN
-
-
Power
-
물리적 UPS와 전원 분배 장치는 가상 UPS라 일컬어지는 장비로 추상화될 수 있다.
-
UPS (Uninterruptible power supply)
-
-
1. 하드웨어 독립성 (Hardware Independence)
-
IT 하드웨어 플랫폼에서 운영 체제의 설정과 애플리케이션 소프트웨어의 설치는 많은 소프트웨어 하드웨어 간 의존성을 낳는다.
-
가상화는 고유한 IT 하드웨어를 에뮬레이트되고 표준화된 소프트웨어 기반 복제품으로 옯기는 과정이다.
-
하드웨어와 소프트웨어의 의존성이 발생하지 않게 실행할 수 있다.
-
예를 들어, 안드로이드 OS를 컴퓨터에서 에뮬레이터를 통해서 실행시킬 수 있다.
-
- 하드웨어 독립성을 통해 가상 서버를 다른 가상화 호스트로 쉽게 이동할 수 있으며 여러 하드웨어-소프트웨어 비호환성 문제를 해결할 수 있다.
2. 서버 통합 (Server Consolidation)
-
가상화 기술을 통해 서로 다른 가상 서버가 하나의 물리적 서버를 공유할 수 있습니다.
-
이 프로세스를 서버 통합이라고 하며 하드웨어 활용성, 로드 밸런싱, 이용 가능한 IT 자원의 최적화를 증가시키기 위해 사용된다.
- 그 결과로 나타나는 유연성은 여러 가상 서버가 여러 게스트 운영체제에서 구동될 수 있음을 의미한다.
3. 자원 복제
4. 운영체제 기반 가상화 (Operating System-Based Virtualization)
- 가상머신은 하드웨어 위의 호스트 운영체제와 가상 머신 관리를 통해 관리된다.
- 호스트 운영체제는 CentOS, Window와 같이 우리가 아는 운영체제
- 게스트 운영체제는 가상 머신 안에서만 작동하는 운영체제
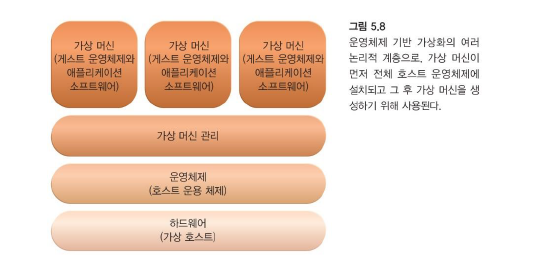
-
운영 체제 기반 가상화는 호스트 운영 체제라고 하는 기존 운영 체제에 가상화 소프트웨어를 설치하는 것입니다.
-
호스트 운영 체제는 그 자체로 완전한 운영체제이기 때문에 관리 도구로 이용 가능한 여러 운영체제 기반 서비스를 물리 호스트를 관리하는 데 사용할 수 있다.
- 하드웨어와 가상 머신 관리 소프트웨어 간의 호환성 문제를 해결해준다.
-
운영 체제 기반 가상화에 대한 고려 사항은 가상화 소프트웨어 및 호스트 운영 체제를 실행하는 데 필요한 처리 오버헤드입니다.
-
호스트 운영체제는 CPU, 메모리, 다른 하드웨어 IT자원을 소비한다.
-
게스트 운영체제로부터의 하드웨어 관련 호출은 하드웨어로 들고나는 여러 계층을 거치게 되어 전체적인 성능을 저하시킨다.
-
각 게스트 운영체제에 대한 개별적인 라이선스와 더불어 대개 호스트 운영체제를 위해 라이선스가 필요하다.
-
5. 하드웨어 기반 가상화 (Hardware-Based Virtualization)
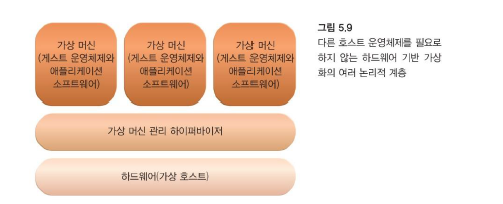
-
이 옵션은 호스트 운영 체제를 우회하기 위해 물리적 호스트 하드웨어에 직접 가상화 소프트웨어를 설치함(온프레미스)을 나타냅니다.
- 가상 서버가 호스트 운영체제의 중재 작업 없이 하드웨어와 통신하게 만들어 하드웨어 기반 가상화는 더욱 효율적이게 된다.
-
가상화 소프트웨어는 일반적으로 하이퍼바이저(hypervisor)라고 합니다.
-
하이퍼바이저는 가상화 관리 레이어를 설정하기 위해 하드웨어 관리 기능을 처리하는 소프트웨어의 얇은 계층으로 존재합니다.
-
이 유형의 가상화 시스템은 여러 가상 서버가 동일한 하드웨어 플랫폼과 상호 작용할 수 있도록 하는 조정 고 유의 성능 최적화에 필수적으로 사용됩니다.
-
-
하드웨어 기반 가상화의 주요 문제 중 하나는 하드웨어 장치와의 호환성 문제
- 가상화 계층은 호스트 하드웨어와 직접 통신하도록 설계되었으며, 이는 모든 관련 장치 드라이버 및 지원 소프트웨어가 하이퍼바이저와 호환되어야 함을 의미합니다.
4. 웹 기술 (Web Technology)
[참고]
- 웹에서의 자원은 WWW을 통해 접근 가능산 부산물들을 자원이나 웹 자원을 일컫는다.
- 이는 IT 자원보다 포괄적인 용어이다.
- 예를 들어 JPG 이미지 파일
- 클라우드 컴퓨팅에서의 맥락에서 IT 자원은 소프트웨어나 하드웨어 기반의 물리적 또는 가상의 IT 관련 부산물을 말한다.
- 클라우드 컴퓨팅의 인터네트워킹과 웹 브라우저 일반성, 웹 기반 서비스 배포의 용이성에 대한 근본적인 의존성 때문에 일반적으로 웹 기술은 클라우드 서비스를 위한 구현의 수단 및 관리 인터페이스로 사용된다.
-
기본 웹 기술
-
WWW은 인터넷을 통해 접근되는 상호 연결된 IT 자원 시스템이다.
-
웹의 기본 요소
-
웹 브라우저 클라이언트
-
웹 서버
-
-
Uniform Resource Locator (URL)
- 웹 기반 자원을 가리키는 식별자를 생성하는 표준 문법으로 논리적 네트워크 위치를 사용해 구성된다.
-
HypertextTransferProtocol(HTTP)
-
World Wide Web을 통해 콘텐츠와 데이터를 교환하는 데 사용되는 기본 통신 프로토콜입니다.
-
URL은 HTTP를 통해 전송된다.
-
-
마크업 언어 (HTML,XML)
- 마크업 언어는 웹 중심 데이터와 메타데이터를 표현하는 수단을 제공합니다.
-
-
웹 애플리케이션 (Web Applications)
-
웹 기반 기술(그리고 일반적으로 사용자 인터페이스 표시를 위해 웹 브라우저에 의존)을 사용하는 분산 응용 프로그램은 일반적으로 웹 응용 프로그램으로 간주됩니다.
-
높은 접근성 때문에 모든 종류의 클라우드 기반 환경에서 찾아볼 수 있다.
-
-
웹 애플리케이션에 대한 일반적인 아키텍처 추상화
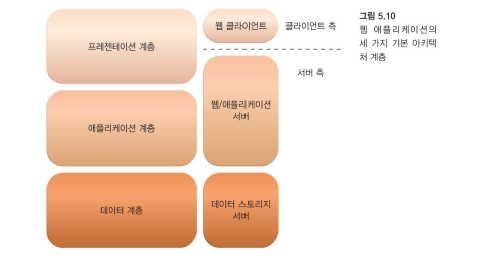
-
프레젠테이션 계층은 사용자 인터페이스를 나타냅니다.
-
애플리케이션 계층은 애플리케이션 로직을 구현합니다.
-
데이터 계층은 지속적인 데이터 저장소를 구성하는 계층입니다.
-
5. 멀티테넌트 기술 (Multitenant Technology)
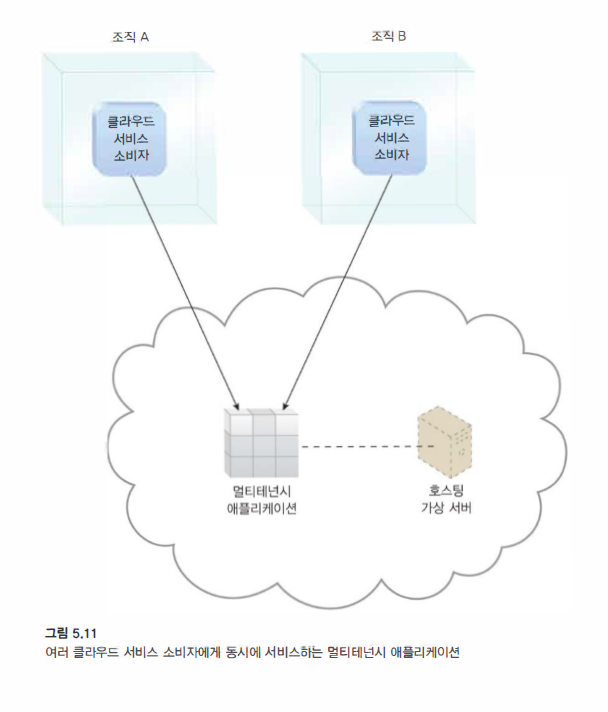
-
여러 사용자(테넌트)가 동일한 애플리케이션 로직에 동시에 접근할 수 있도록 다중 테넌트 애플리케이션이 생겨났다.
-
각 테넌트는 다른 테넌트가 같은 애플리케이션을 사용하고 있다는 것을 인식하지 못한 채 사용하고 관리하며 전용 소프트웨어 인스턴스를 통해 원하는 대로 만드는 애플리케이션의 뷰를 갖는다.
-
멀티테넌시 애플리케이션은 테넌트가 자신의 것이 아닌 데이터 및 구성 정보에 접근할 수 없도록 합니다.
-
임차인은 다음과 같이 애플리케이션의 기능을 개별적으로 사용자화할 수 있습니다.
-
사용자 인터페이스 (User Interface)
-
테넌트는 애플리케이션 인터페이스를 특화된 룩 앤드 필로 정의할 수 있다.
-
버튼의 위치라던가 색상이라던가..
-
-
비즈니스 프로세스 (Business Process)
- 테넌트는 애플리케이션에 구현된 비즈니스 프로세스의 규칙, 로직, 워크플로우를 원하는 대로 만들 수 있다.
-
데이터 모델 (Data Model)
-
테넌트는 애플리케이션 데이터 구조에 있는 필드를 포함하거나 제외, 재명명하기 위해 애플리케이션의 데이터 스키마를 확장할 수 있다.
-
DB의 스키마 등
-
-
접근 제어 (Access Control)
-
테넌트는 사용자와 그룹에 대한 접근 권한을 독립적으로 통제할 수 있다.
-
어디까지 접근할 수 있는가
-
-
-
-
멀티테넌시 애플리케이션은 개별 테넌트 운영 환경을 분리하는 보안 수준을 유지하면서 여러 사용자에 의한(포털, 데이터 스키마, 미들웨어 및 데이터베이스 포함) 다양한 아티팩트(부산물) 공유를 지원해야 합니다.
-
즉, 각각의 사용자별 고유한 데이터 설정 정보는 독립적으로 관리를 하면서도 프로그램 인스턴스는 공유하는 것
-
사용자 입장에서는 공유되는 것을 모름, 자신만 자원을 사용하는 듯한 감각
-
-
다중 테넌트 애플리케이션의 일반적인 특성
-
사용 분리 (Usage Isolation)
-
한 테넌트의 사용 행위가 다른 테넌트의 애플리케이션 가용성 및 성능에 영향을 미치지 않습니다.
- 즉 독립적으로 관리된다.
-
-
데이터 보안 (Data Security)
-
테넌트는 다른 테넌트에 속한 데이터에 접근할 수 없습니다.
- 즉 위의 사용자화 된 정보에 다른 테넌트가 접근할 수 없다.
-
-
복구 (Recovery)
- 각 테넌트의 데이터에 대해 독립적으로 백업 및 복원 수행
-
애플리케이션 업그레이드 (Application Upgrades)
- 테넌트는 공유 소프트웨어 아티팩트의 동기식 업그레이드로 인해 부정적인 영향을 받지 않습니다.
-
확장성 (Scalability)
- 애플리케이션은 기존 테넌트의 사용량 증가나 테넌트 수의 증가를 수용하도록 확장할 수 있습니다.
-
사용량 측정 (Metered Usage)
- 테넌트는 실제 소비된 애플리케이션 프로세싱과 특징에 대해서만 요금이 부과됩니다.
-
데이터 계층 격리 (Data Tier Isolation)
-
테넌트는 다른 테넌트와 독립적인 데이터베이스, 테이블, 스키마를 갖는다.
- 그렇지 않으면 데이터베이스, 테이블, 스키마는 의도적으로 테넌트들 간에 공유되도록 설계될 수 있다.
-
-
6. 서비스 기술 (Service Technology)
