CHAPTER 3 - 데이터 정제하기
3-1. 불필요한 데이터 삭제하기
핵심 키워드
데이터 정제 데이터 랭글링 데이터 먼징 원소별 비교 불리언 배열 넘파이
데이터 정제(data cleaning)
불필요하거나 불완전한 데이터를 교체하는 작업이다.
데이터 정제는 데이터를 분석 목적에 맞게 변환하는 데이터 랭글링(data wrangling) 또는 데이터 먼징(data munging)의 일부로 수행될 수 있다.
열 삭제(선택)하기
오늘 사용할 남산도서관 데이터를 다운로드해서 확인해보자.
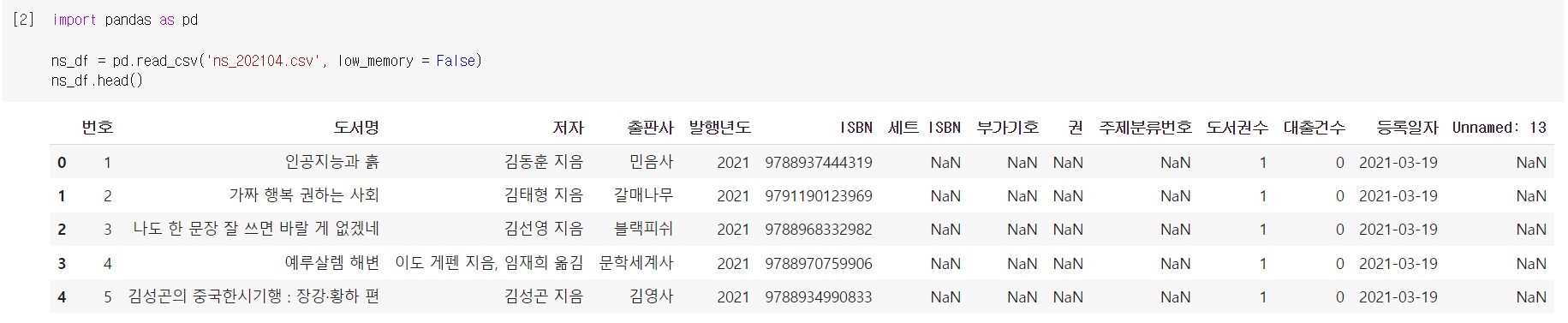
마지막 Unnamed: 13 열은 CSV 각 라인의 끝에 콤마(,)가 있어서 판다스에서 자동으로 추가되었다.
NaN은 누락된 값, 비어있는 값을 의미한다.
불필요한 열이기 때문에 전체 열 중에서 해당 열만 삭제하면 된다. 이럴 경우 loc() 을 이용하는 것 보다는 불리언 배열 또는 drop() 또는 dropna() 메서드를 사용해서 원하는 열만 삭제한다.
- 불리언 배열 사용
columns 속성은 판다스의 Index 클래스 객체이다. 이 안에 들어있는 원소들은 리스트처럼 인덱스를 이용해 해당하는 값을 찾을 수 있다. 또한 원소별 비교를 통해 열을 불리언 배열로 나타낼 수 있다.
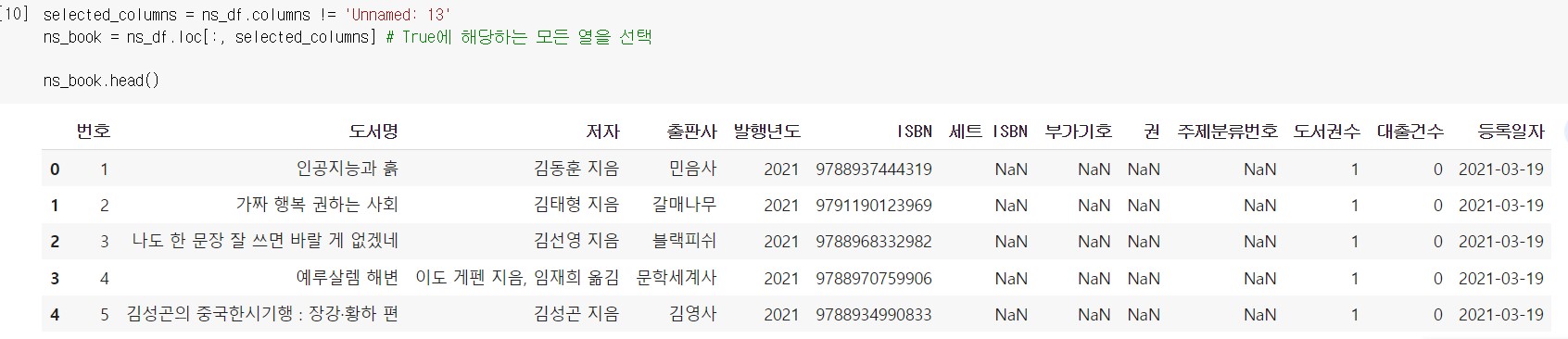
예를 들어 ns_df.columns 에서 Unnamed: 13 열이 아닌 것들을 표시하는 불리언 배열은 아래와 같다.

이렇게 반환된 결과는 numpy.ndarray 타입이다.
이제 원소별 비교 연산으로 얻은 불리언 배열을 이용해서 Unnamed: 13 열을 삭제해보자.
- drop() 사용
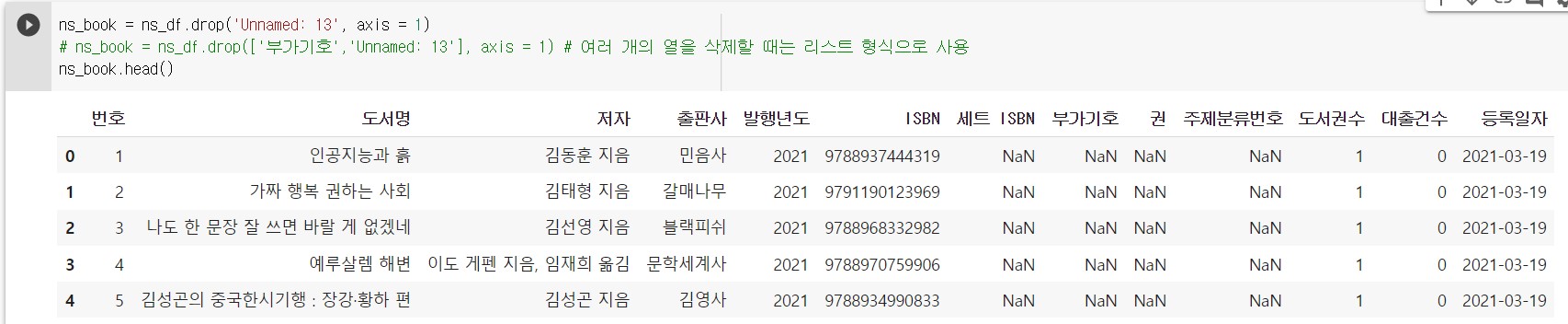
판다스의 drop() 메서드는 데이터프레임의 행이나 열을 삭제한다.
첫 번째 배개변수에는 삭제하려는 열을, axis 매개변수는 1로 지정해서 열을 삭제한다. (기본값인 0으로 지정하면 행을 삭제한다.)
drop()을 이용해서 Unnamed: 13 열을 삭제해보자.
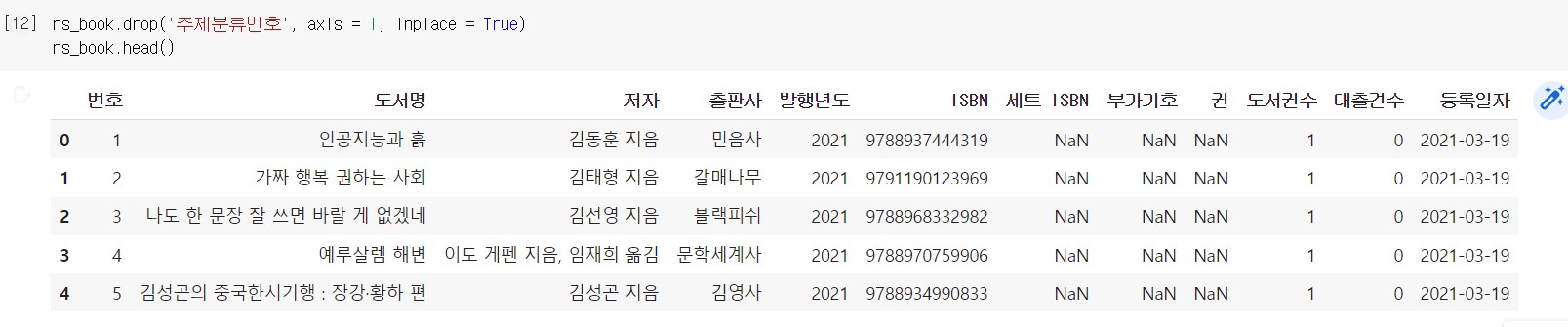
또한 drop() 메서드에 inplace 매개변수를 True로 지정하면 현재 선택한 데이터프레임을 바로 수정할 수 있다.
- dropna() 사용
dropna() 메서드를 사용하면 NaN 값이 한 개 이상 들어간 행 또는 열을 삭제한다.
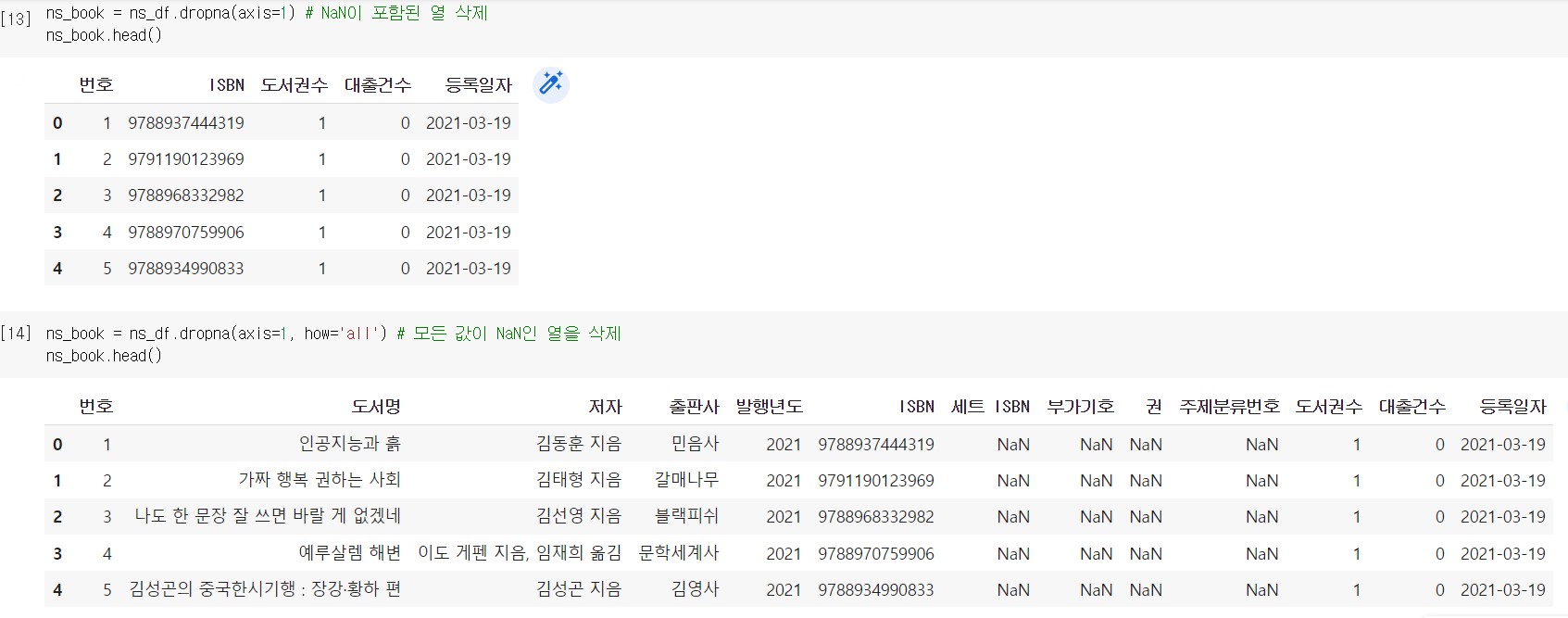
모든 값이 NaN인 열을 삭제하려면 dropna() 메서드에 how 매개변수는 ‘all’ 로 지정한다.
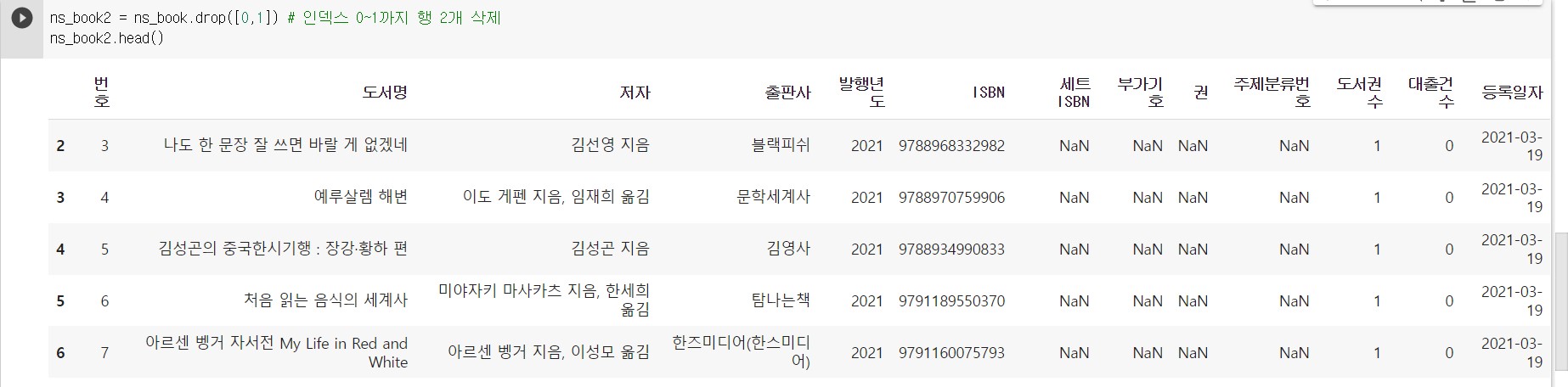
행 삭제하기
- drop() 사용
drop() 메서드를 사용해서 행을 삭제하려면 숫자로 된 인덱스에 직접 접근해야 한다.
- [] 연산자와 슬라이싱
선택한 행만 남기려면 [] 연산자에 인덱스를 전달한다.
[] 연산자에 슬라이싱을 사용하면 loc()메서드와는 달리 마지막 인덱스를 포함하지 않는다. (파이썬의 리스트 슬라이싱과 같다.)

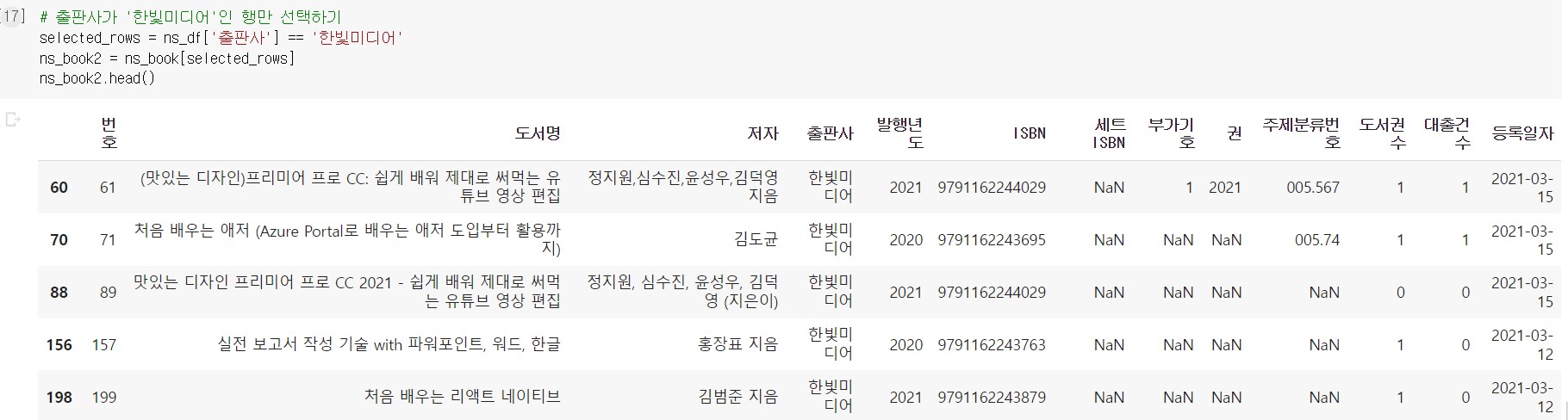
- [] 연산자와 불리언 배열
남길 행은 True, 삭제할 행은 False로 표시한 불리언 배열을 만들고, 이 배열을 []연산자에 전달한다.
원하는 행만 삭제하거나 남길 때 가장 많이 사용하는 방식으로는 아래처럼 []연산자 안에 불리언 배열을 만드는 조건을 바로 만들어 넘긴다.

중복된 행 찾기
판다스 데이터프레임의 중복된 행은 duplicated() 메서드를 사용해서 검사한다.
중복된 행 중에서 처음 행을 제외한 나머지 행은 True, 그 외의 중복되지 않은 나머지 모든 행은 False로 표시한 불리언 배열을 반환한다.
예를 들어서 첫 번째 행과 두 번째 행에 있는 데이터가 중복되었다면, 처음으로 중복된 데이터가 있는 첫 번째 행은 False로, 두 번째 행은 True이다.
또한 파이썬의 sum() 함수는 True를 1로 인식하기 때문에 duplicated() 로 만든 불리언 배열에서 중복된 행의 개수를 셀 수 있다.
일부 열을 기준으로 중복된 행을 찾으려면 duplicated() 의 subset 매개변수에 기준 열을 나열한다.

도서명, 저자, ISBN을 기준으로 어떤 데이터가 중복되었는지 확인하기 위해서는 duplicated() 의 keep 매개변수로 불리언 배열을 만들어 확인해보면 된다.
keep 매개변수를 False로 지정하면 중복된 모든 행이 True로 표시된다.

중복된 도서를 확인해보니 시리즈물인 ‘파친코’, 인기대출도서인 ‘보건교사 안은영’ 등이 등록되어 있다.
그룹 별로 모으기
앞으로 어떤 도서가 인기있을지 예상하려고 한다면, 이 데이터프레임에서 가장 중요한 열은 ‘대출건수’ 이다. 따라서 같은 도서의 대출 건수를 하나로 합쳐보자. 이럴 때는 groupby() 메서드를 사용한다.
groupby() 메서드의 by 매개변수에는 행을 합칠 때 기준이 되는 열을 지정한다.
열에 대한 값이 정수 타입이라면 일반적으로 더하거나 평균을 낸다. 여기에서는 같은 책의 대출건수는 sum() 메서드를 사용해서 서로 더한다.
groupby() 메서드는 기본적으로 by 매개변수에 지정된 열에 NaN이 포함되어 있으면 해당 행을 자동으로 삭제한다. NaN이 포함되어 있는 행이 삭제되면 대출건수 합계에도 빠지기 때문에 이를 막기 위해 dropna 매개변수를 False로 지정한다.

그룹으로 묶어 기준이 된 인덱스 열은 위처럼 굵게 표시된다.
원본 데이터 업데이트하기
- 원본 데이터프레임에서 중복되지 않는 열만 선택하기
이제 대출건수를 원본 데이터프레임에 업데이트해보자. 원본에는 중복된 데이터가 있기 때문에 가장 먼저 중복되는 부분을 제거한다.
이때 판다스의 ~연산자를 이용하면 중복된 열을 True로 표시한 불리언 배열을 반전시킬 수 있다.

판다스에서 ns_book3 데이터프레임이 별도의 메모리 공간에 저장되는지 알 수 없기 때문에 이를 명시적으로 복사하는 copy() 메서드를 사용한다. 판다스에서 일부 행이나 열을 선택해서 데이터를 업데이트해야 할 때는 항상 복사하는 것이 좋다.
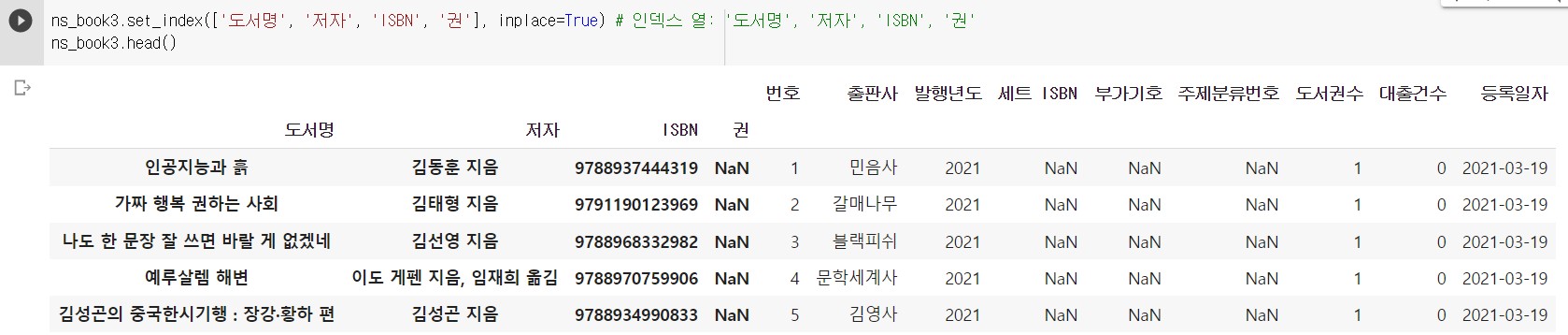
- 원본 데이터프레임 인덱스를 설정하기
다음으로 원본 데이터프레임 인덱스를 설정한다. 지정한 열을 인덱스로 설정할 때는 set_index() 메서드를 사용한다. 이때 inplace 매개변수를 True로 지정해서 새로운 데이터프레임을 반환하지 않고 ns_book3 데이터프레임을 수정한다.
- 업데이트하기 - update() 메서드
다른 데이터프레임을 사용해 원본 데이터프레임의 값을 업데이트 할 때는 update() 메서드를 사용한다.
제대로 업데이트가 되었다면 reset_index() 메서드로 지정했던 인덱스 열을 해제한다.
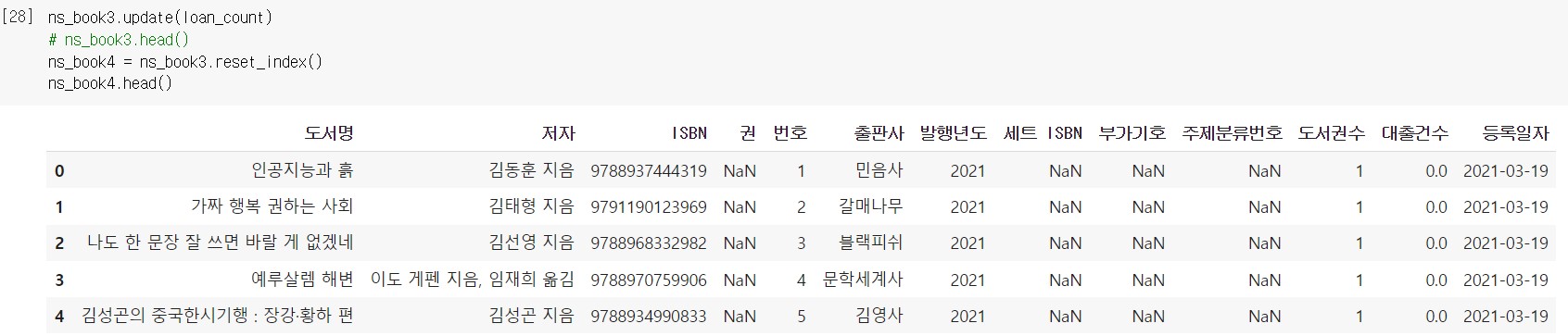
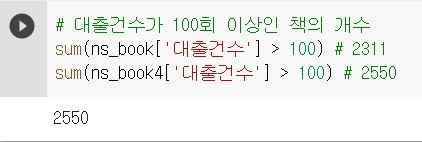
대출건수가 잘 합쳐졌는지 확인해본다. 중복된 대출건수를 합친 ns_book4 에서 대출건수가 100회 이상인 책이 늘어났다.
여러 개의 열로 인덱스를 재설정하고, 다시 해제했기 때문에 원본 데이터프레임의 열과 ns_book4 데이터프레임의 열 순서가 달라졌다. 이를 맞추기 위해 []연산자에 원하는 열 이름을 순서대로 전달한다.

- 변환한 데이터프레임 저장하기
데이터프레임을 csv 파일로 저장하려면 to_csv() 메서드를 사용한다.

