CHAPTER 3 - 데이터 정제하기
3-2. 잘못된 데이터 수정하기
핵심 키워드
NaN 정규 표현식
데이터프레임 정보 요약 확인하기
3-1절에서 만든 ‘ns_book4.csv’ 파일을 임포트하고, info() 메서드로 데이터프레임 요약정보를 확인한다.

위의 RangeIndex 는 전체 행 개수이고, total 13 columns 은 열 개수가 13개 라는 뜻이다.
나머지 아래의 정보들은 각각의 열 이름과 누락된 값(NaN)이 없는 행 개수, 열 데이터 타입을 의미한다.
전체 행 개수는 384591개인데, 각 열의 Non-Null Count 을 보니 전체 행 개수와 차이가 나기 때문에 누락된 값이 있다는 것을 알 수 있다.
누락된 값 처리하기
- 누락된 값의 개수 확인하기 - isna()
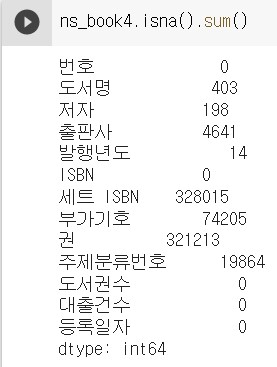
누락된 값의 개수를 확인하기 위해 isna() 메서드를 사용한다.
isna() 메서드는 각 행이 비어있는지 나타내는 불리언 배열을 반환하기 때문에 sum() 메서드를 이어서 호출하면 불리언 배열의 True 개수로 비어있는 행의 개수를 알 수 있다.
참고로 누락되지 않은 값을 확인하기 위해서는 notna().sum() 을 사용한다.
- 임의로 누락된 값 만들기 - None, np.nan
판다스 데이터프레임에서는 정수를 저장하는 열에 None을 입력하면 누락된 값으로 인식한다.

판다스는 NaN을 실수 값으로 저장하기 때문에 정수 타입이던 ‘도서권수’ 열이 자동으로 float64로 형변환 되었다. 원래 데이터타입으로 지정하기 위해서는 astype() 메서드를 사용한다. 매개변수는 딕셔너리 형태로 전달한다.

숫자와 문자열 데이터 타입에 상관 없이 데이터프레임의 값을 NaN으로 만들고 싶다면 np.nan 을 사용한다.

- 누락된 값 바꾸기 - loc, fillna(), replace()
loc 메서드를 사용하면 누락된 값을 원하는 값으로 바꿀 수 있다. 먼저 isna() 메서드를 이용해 누락된 값을 표시한 불리언 배열을 만든 후 loc 에 전달해주면 된다.

'세트 ISBN’ 의 열의 NaN을 모두 빈 문자열로 바꿨기 때문에 누락된 행의 개수는 0이다.
다른 방법으로 fillna() 메서드를 사용한다. 매개변수로 원하는 값을 전달하면 NaN을 간편하게 바꿀 수 있다. 예를 들어 '부가기호' 열에 해당하는 NaN을 모두 '없음' 으로 바꾸려면 아래와 같이 사용한다.

하지만 특정 열을 선택한 후 fillna() 메서드를 적용하면 위의 실행 결과처럼 열 이름 없이 개수만 있는 시리즈 객체로 반환된다.
‘부가기호’ 열의 NaN을 바꾸면서 전체 데이터프레임을 반환하려면 아래처럼 열 이름과 바꾸려는 값으로 이루어진 딕셔너리를 전달한다.

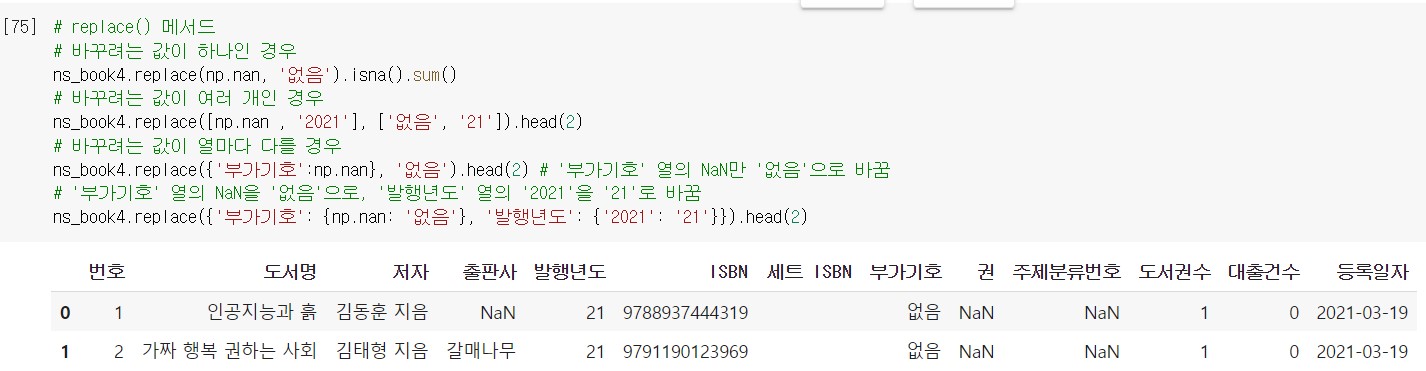
replace()메서드는 NaN을 포함한 모든 값을 바꿀 수 있다. 그만큼 사용법도 다양하다.
- 바꾸려는 값이 하나 → 단일 값을 전달
replace(원래 값, 새로운 값)
- 바꾸려는 값이 여러 개 → 리스트 형식으로 전달
replace([원래 값1, 원래 값2], [새로운 값1, 새로운 값2])
- 바꾸려는 값이 열마다 다를 때 → 딕셔너리 형식으로 전달
replace({열 이름: 원래 값}, 새로운 값)
정규 표현식
정규 표현식(regular expression) 또는 정규식은 문자열 패턴을 찾아서 대체하기 위한 규칙 모음을 뜻한다.
- 숫자 찾기 - \d
Ex. ‘발행년도’의 네자리 연도를 두 자리 연도로 바꾸기
정규식에서 \d 는 숫자를 나타낸다.
남기려는 표현식을 그룹으로 묶을 때는 괄호 ()를 사용한다.
예를 들어 \d\d\d\d 는 네 자리 연도에 해당하는 표현이고, \d\d(\d\d) 는 뒤에 두 자리만 하나의 그룹으로 묶을 때 사용한다. \d\d(\d\d) 에 맞는 문자열로는 ‘2021’, ‘2018’은 가능하지만 ‘A21’, ‘21.9’는 해당되지 않는다.
따라서 패턴에 맞는 문자열을 찾은 후 첫 번째 그룹에 해당하는 뒷자리 연도 두 개를 추출한다. 그리고 패턴 안에 있는 그룹을 나타낼 때는 \1 , \2 처럼 사용한다. 그룹의 번호는 패턴 안에 등장하는 순서대로 매겨진다.
예를 들어 ‘발행년도’의 네자리 연도를 두 자리 연도로 바꾸기 위해서는 정규식을 사용해야 하는데, replace() 의 매개변수인 regex 옵션을 True 로 지정한다.

정규식 앞에 붙은 r 은 파이썬에서 정규식을 다른 문자열과 구분하기 위한 표시이다.
정규식이 반복되는 경우에는 중괄호를 사용해서 개수를 지정할 수 있다. 예를 들어 \d{2} 는 \d\d 와 동일하게 연속된 숫자 두 개를 의미한다.
- 문자 찾기 - 마침표 .
Ex. ‘저자’ 열에서 ‘ (지은이)’, ‘ (옮긴이)’ 문자를 삭제하기
마침표 . 은 어떤 문자에도 대응하는 정규식 문자이다. 해당하는 문자가 0번 이상 반복된다면 ***** 을 사용한다.
매칭시켜야 할 문자열에 괄호가 있는 경우에는 일반 문자라고 인식할 수 있도록 역슬래시()를 각 괄호 앞에 붙인다.
띄어쓰기(공백 문자)가 있다면 \s 를 앞에 붙인다.
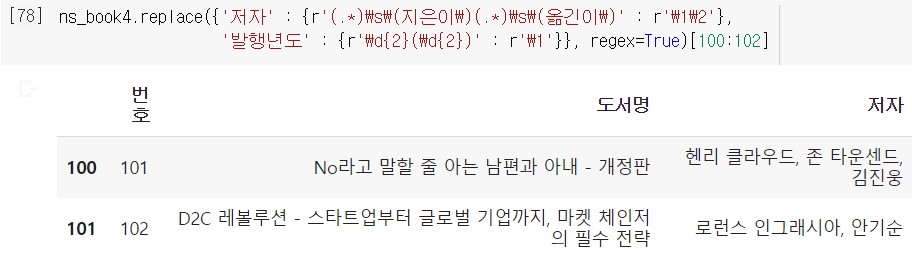
따라서 ‘로런스 인그래시아 (지은이), 안기순 (옮긴이)’ 와 같은 문자열에서 남겨놓아야 할 문자열을 매칭하기 위해서는 (.*)\s\(지은이\)(.*)\s\(옮긴이\) 라고 쓴다.
저자 이름은 삭제하기 않고 남겨놓아야 하기 때문에 괄호를 사용했고, 공백 문자와 괄호가 있는 ‘ (지은이)’ 와 ‘ (옮긴이)’ 문자열을 찾기 위해 \s 와 \ 를 적용했다.
여기서 첫 번째 그룹과 두 번째 그룹만 가져오면 ‘ (지은이)’ 와 ‘ (옮긴이)’ 문자열을 삭제할 수 있다.
잘못된 값 바꾸기
도서의 발행 연도가 잘못 저장된 것이 있는지 확인해보기 위해 ‘발행년도’ 열을 int형으로 바꾸면 아래와 같은 오류가 발생한다.
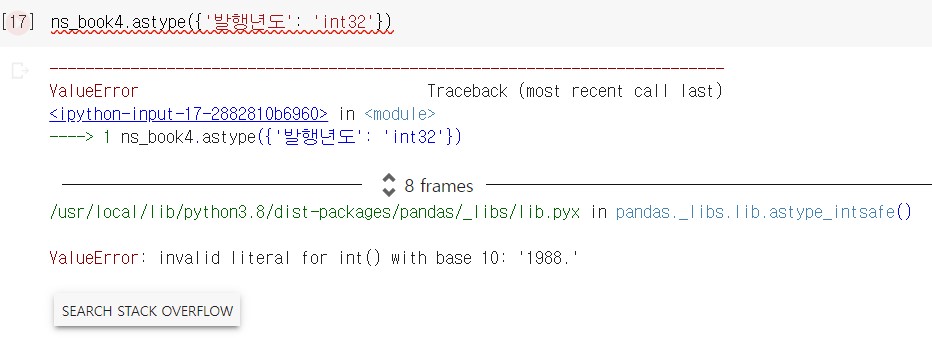
‘1988’ 이라는 연도를 반환할 수 없다. 아무래도 발행년도의 값들 중 숫자가 아닌 다른 문자가 있는 것 같다.
판다스의 str.contains() 메서드를 이용하면 시리즈 또는 인덱스에서 문자열 패턴을 포함하고 있는지 검사할 수 있다. 이 메서드를 이용해서 숫자가 아닌 문자를 포함하는 모든 행을 찾아본다.
str.contains() 는 기본적으로 정규식을 인식한다. 숫자에 대응하는 정규식은 \d 지만, 반대로 숫자가 아닌 다른 모든 문자에 대응하는 정규식은 \D 이다.
개수를 구하기 위해서는 불리언 배열을 구해야 하기 때문에 매개변수 na 를 True로 지정해서 연도가 누락된 행을 True로 표시했다.
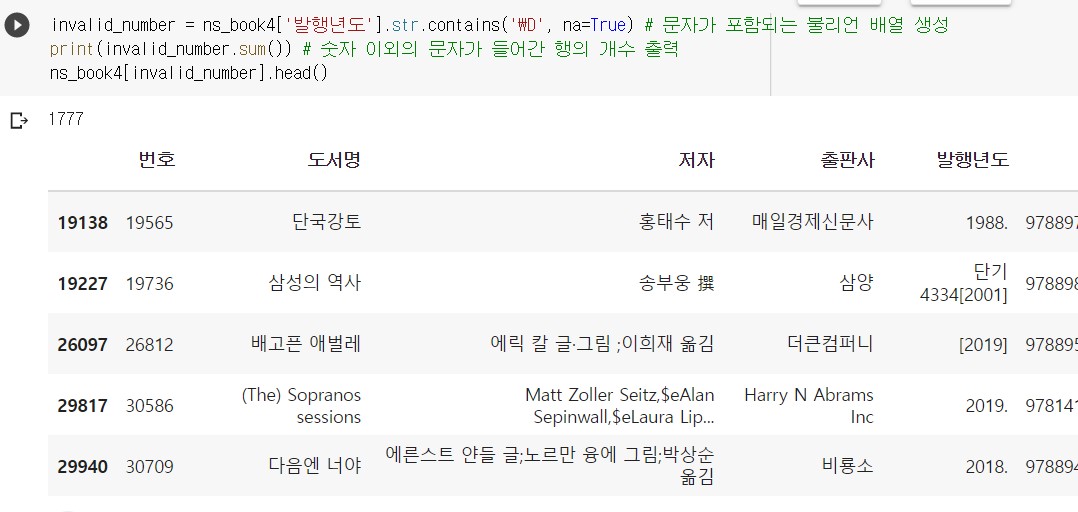
‘발행년도’ 행을 보니 마침표, 대괄호, 한글 등의 숫자를 제외한 문자가 있다는 것을 알 수 있다. 이런 있는 값들의 개수가 1777개가 나왔다.
이제 정규식으로 연도 앞과 뒤에 있는 문자를 제외해보자.
여기서 남겨야 하는 값은 4자릿수 연도에 해당하는 숫자이다. 이 숫자를 정규식 그룹으로 묶으면 (\d{4}) 이다. 그리고 앞뒤로 어떤 문자가 나오더라도 모두 매칭되어야 하기 때문에 앞 뒤에 .* 를 붙여준다.
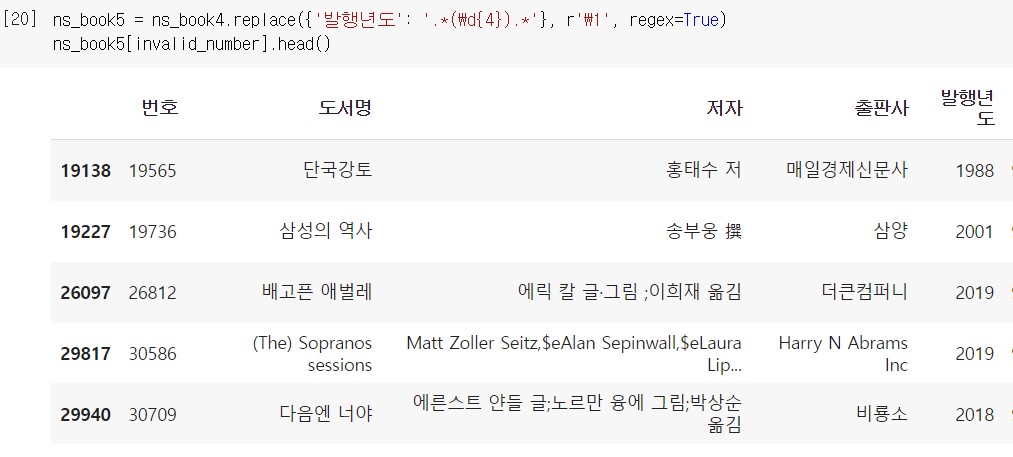
정규식에 맞게 숫자 값이 바뀐 것을 확인할 수 있다. 하지만 모든 값이 제대로 바뀌었는지는 아직 알 수 없기 때문에 숫자 이외의 문자가 들어간 행의 개수와 데이터를 다시 한번 확인해본다.

1777개의 값들 중 바뀌지 않은 값이 67개가 남아 있다.
바뀌지 않은 값들은 NaN이거나 네 자리 숫자가 아닌 값이다. 이런 값은 어떻게 변환할지 알 수 없기 때문에 임의의 값인 -1로 바꾼 다음 데이터 타입을 int32로 변환한다.
그리고 연도 중 이상하게 큰 값이나 작은 값 역시 -1로 바꿔준다. 아래 코드에서 연도가 4000년이 넘거나 1900년보다 작은 도서가 있는지 확인해보았다.

gt() 메서드는 전달된 값보다 큰 값을 찾고, lt() 메서드는 전달된 값보다 작은 값을 찾는다. eq() 메서드는 전달된 값과 같은 값을 찾는다.
총 86권이 연도가 잘못 저장되었거나 알 수 없는 값이라는 것을 확인할 수 있다.
누락된 정보 채우기
이제 ‘발행년도’ 열을 포함한 다른 열의 잘못되거나 누락된 값을 채워보자.
‘도서명’, ‘저자’, ‘출판사’, ‘발행년도’ 열이 분석에 중요하다고 판단했다면 이 4개의 열에는 누락된 값이 있으면 안 된다.
해당 열에 대해서 누락된 값이 있거나 ‘발행년도’ 열이 -1인 행의 개수를 확인해보자.

값이 누락되거나 알 수 없는 행이 5268개이다. 도서에 대한 올바른 발행년도를 확인하기 위해서는 웹스크래핑을 사용해서 도서 사이트의 도서정보에 해당하는 태그를 가져와야 한다.
yes24 검색창에 ISBN을 입력하면
http://www.yes24.com/Product/Search?domain=ALL&query=9791191266054
와 같은 URL 주소가 나오고, 개발자 도구로 태그를 확인하면 클래스 이름이 gd_name 인 <a>태그의 텍스트가 바로 도서명에 해당하는 정보라는 것을 알 수 있다.
먼저 도서명만 가져오는 함수를 작성하면 아래와 같다.
참고로 웹크롤링을 하기 위한(2장 포스팅 참고) 라이브러리인 Requests와 BeautifulSoup의 기능을 간단히 리뷰하자면 아래와 같다.
- Requests: HTTP 요청을 보낼 수 있도록 기능을 제공하는 라이브러리
- BeautifulSoup: 웹 페이지의 정보를 쉽게 스크래핑 할 수 있도록 기능을 제공하는 라이브러리
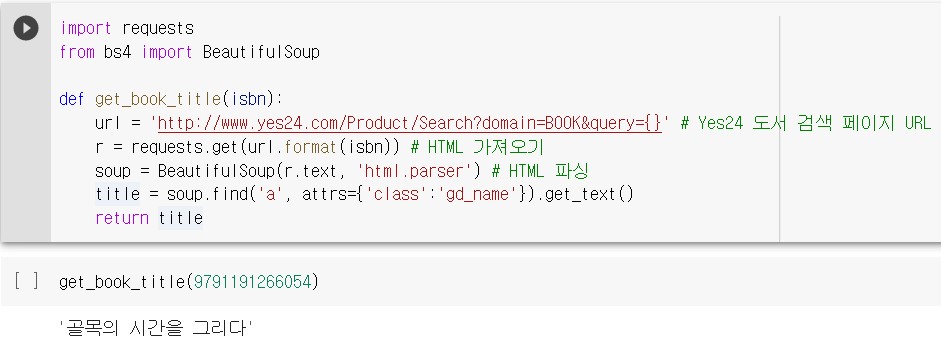
성공적으로 도서명이 추출됐다. 같은 방식으로 저자, 출판사, 발행년도를 추출해서 반환하는 함수를 작성해보자. 이 함수는 길기 때문에 4개 부분으로 나눠 설명한다.
먼저 첫 번째 코드 부분은 위와 동일하게 url을 가져오고 도서명을 가져오는 부분이다.

다음 코드는 저자를 가져오는 부분이다. 도서명과 다르게 저자는 두 명 이상일 수도 있기 때문에 bs4의 find_all() 메서드를 사용해서 태그를 모두 추출하였다.
그리고 <a>태그의 텍스트를 리스트로 만들어 저장하고, 이 결과를 join() 메서드로 하나의 문자열로 합쳤다.

다음으로는 출판사를 가져온다. 간단히 <a>태그에 해당하는 텍스트만 가져오면 된다.

마지막으로 발행년도를 가져온다. 앞에서 잘모된 발행년도는 -1로 지정했기 때문에 여기에 해당하는 데이터만 가져오면 된다.
발행년도는 ‘2020년 12월’ 처럼 쓰여있기 때문에 정규식을 사용해서 연도만 추출해야 한다. re 모듈의 findall(원하는 정규식, 검색 대상 문자열) 함수를 사용하면 원하는 정규식에 매칭되는 모든 문자열을 찾아 리스트로 반환해준다. 이 리스트의 첫 번째 값을 연도로 가져온다.

함수는 누락된 값에만 뷰티플수프로 추출한 값을 저장한다. 만약 yes24에 도서정보가 없거나 HTML을 찾을 수 없는 경우처럼 뷰티플수프로 추출할 수 없다면 오류가 발생한다. 그래서 오류가 발생해도 함수 실행이 종료되지 않고 이어서 다음 요소를 추출할 수 있도록 각 요소를 추출하는 부분에 try ~ except 문을 감싸주었다.
이제 누락된 값이 있었던 처음 두 개의 행에 위의 함수를 적용해보자.
함수가 여러 개의 값을 반환하는 경우 apply() 메서드로 반환된 값을 튜플로 만들 수 있다. 여기에 result_type='expand' 로 지정해서 변환된 값을 각각 다른 열로 만들었다.
apply() 메서드에 대한 자세한 설명은 pandas 공식문서를 확인해보자.

0(도서명), 1(저자), 2(출판사), 3(발행년도)를 잘 가져온 것을 확인할 수 있다.
이 함수를 5268개 행에 대해 적용한 ‘ns_book5_update.csv’ 파일을 코랩에 다운로드해서 업데이트하고, 누락된 행이 몇 개인지 다시 한번 확인한다.
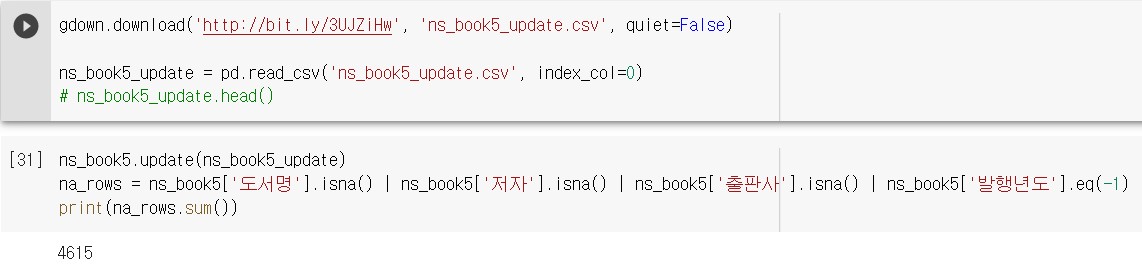
누락된 값이 있는 행의 개수가 뷰티플수프로 데이터를 채우기 전보다 653개가 줄었다.
마지막으로 이 행을 삭제해서 분석 대상에서 제외하자. dropna() 메서드에 ‘도서명’, ‘저자’, ‘출판사’ 열을 리스트로 지정한 후 누락된 값이 있는 행을 삭제하고, ‘발행년도’ 가 -1이 아닌 행만 선택해서 만든 새로운 데이터프레임을 저장한다.

