Intro
BBox를 먼저 찾는게 아니라 center Point를 먼저 찾는다.
앵커박스를 만들어 bbox를 만드는 것이 아니라 center point에서부터 bbox를 만든다.
Real-time Task를 요구하는 Object Detection문제를 요구하는 프로젝트를 진행할 때는 주로 YOLO를 사용했다. 하지만 해커톤 프로젝트를 진행하면서 좀 더 재밌고 좋은 Detector를 찾다가 CenterNet을 발견했다.
CenterNet은 단 하나의 anchor를 keypoint estimation을 통해 얻어내고, 이러한 개념은 CornerNet에서 처음 소개됨

하지만 CenterNet은..
물체의 중심 포인트를 찾음.
객체의 중심점 하나를 찾고 이를 바탕으로 bbox를 그림
하나의 점만 찾기 때문에 grouping이 필요없고, 하나의 앵커박스를 사용하므로 NMS(non-maximum-suppression)과정이 필요 없다.

- Keypoint estimation?
주로 pose estimation분야에서 많이 쓰인다.
CenterNet에선 keypoint가 객체의 중심이 됨
CenterNet은 network를 이용해 keypoint의 heatmap을 찾는데 주 목적이 있음
CenterNet은 1-stage detector
기존 CornerNet은 쌍을 이루는 key point로 bbox를 예측하기 때문에, anchor box 설계가 필요없었다. 또한 성능도 뛰어나 1-stage detector 중에서 SOTA를 달성했다.
하지만 단점도 존재했다.
CenterNet은 anchorless object detection architecture이다.
이 구조는 후 처리 과정에서 전통적인 NMS를 대체하는 주요한 장점을 가지고 있다.
이 메커니즘은 더 빠른 추론을 가능하게 한다.
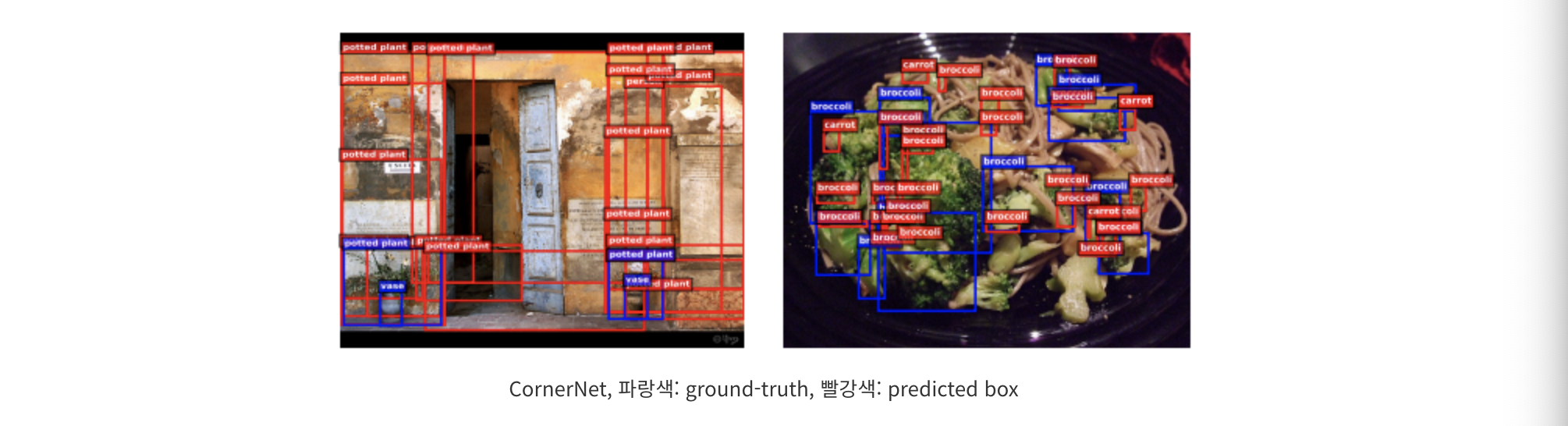
CornerNet의 단점
1) 두 쌍의 특징점의 활용은 장점도 있지만, object의 whole information을 다 쓰지는 못 한다.
2) Bounding Box 경계도 예측하는데에만 초점이 맞춰져있다. 그래서 정보의 맹점이 있을 수 있다.

포인트가 2n개이고 어떤 점과 어떤 점들이 현재의 오브젝트와 연결이 되는지 그룹핑되어야 하는데 많은 연산이 필요하다.
CenterNet의 등장
위의 CornerNet의 문제를 해결하기 위해 CenterNet은 두 쌍의 특징점이 생성한 region에서 중심점 정보를 활용한다.
예측된 bbox가 ground-truth box와 높은 IoU를 가진다면, predicted box의 center point는 ground-truth와 같은 class를 가질 확률이 높을 것이다.
기존 1-stage detector와 비슷한 접근방식을 보이지만 차이점이 있다.
1) CenterNet은 box overlap이 아닌 오직 위치만 가지고 "Anchor"를 할당한다.
2) CenterNet은 오직 하나의 "Anchor"만을 사용한다.
3) CenterNet은 더 큰 output resolution (output stride of 4) 을 가진다.
(CenterNet은 더 큰 output resolution을 갖음)
특징으론..
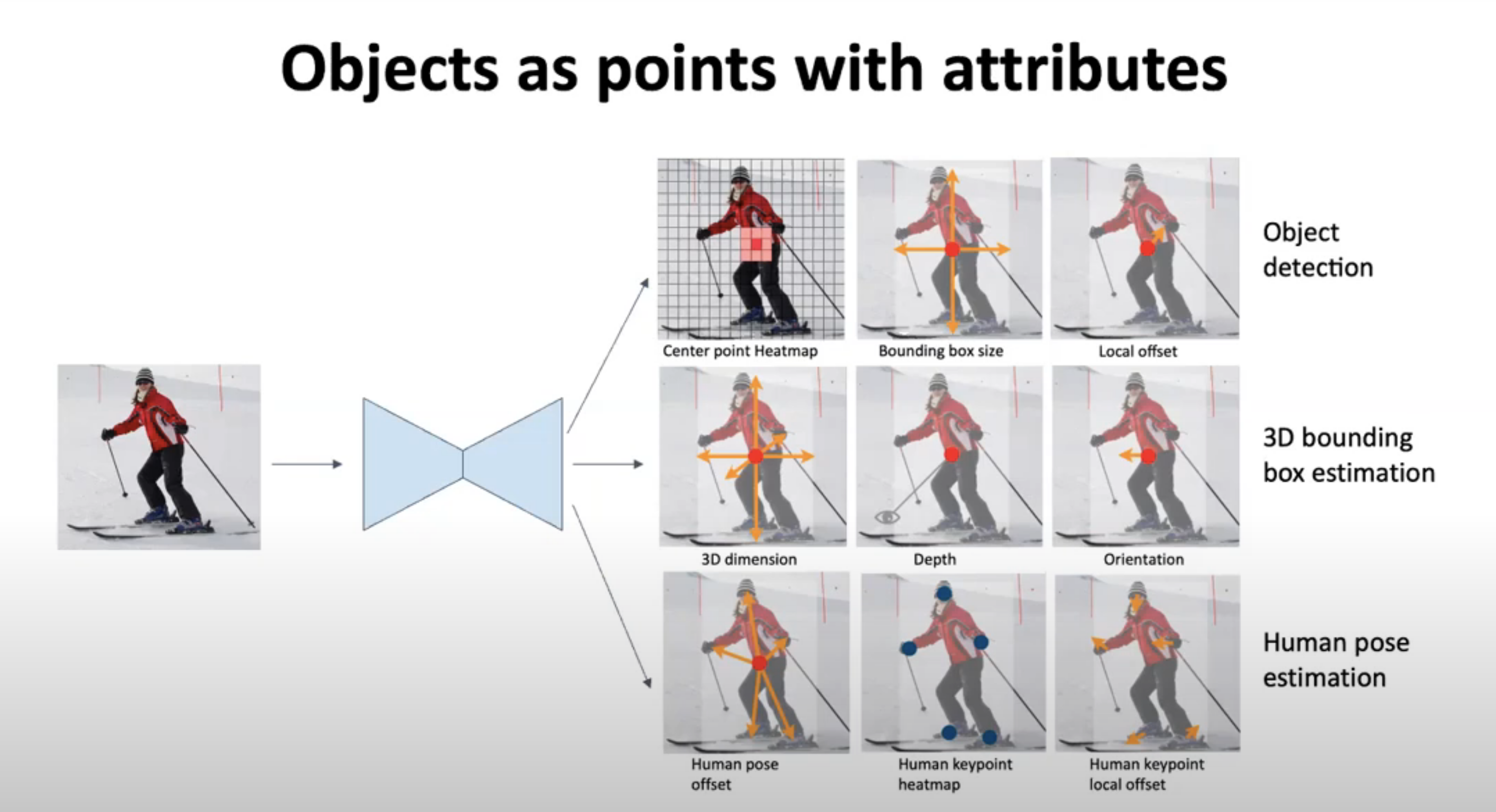
1) 별도의 anchorbox없이 object detection을 object의 중앙에 놓인 point의 heatmap으로 결정한다는 점
2) 중앙 point의 feature값으로 detection뿐 아니라 object size, dimension, 3D extent, orientation, pose등도 regression할 수 있다는 점

What is so special about it?
1) Anchor box의 제거
앵커베이스드 모델은 많은 가비지 예측을 생산한다. 예를 들어 YOLOv3가 그렇다.
서로 다른 7천개의 박스보다 많은 많이 이미지를 예측한다.
2) Pooling lyaer (corner pooling)의 새로운 타입 - 더 좋은 코너 localize를 돕는다.
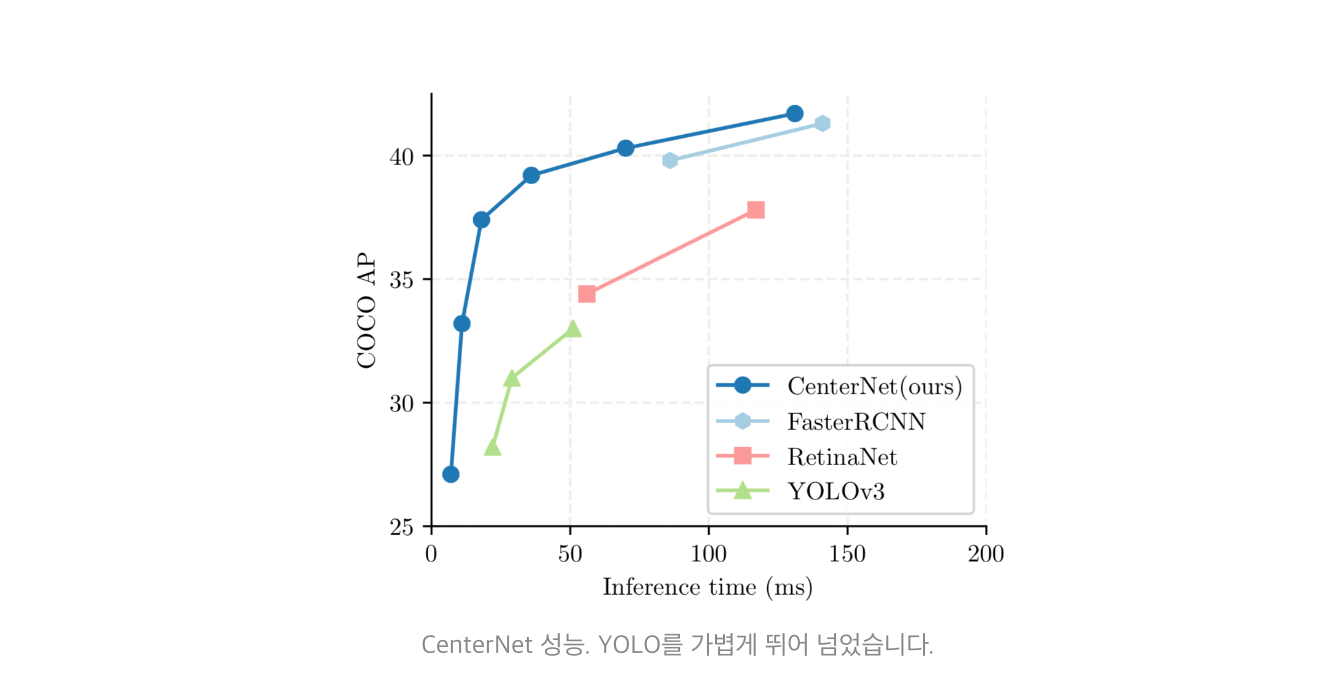
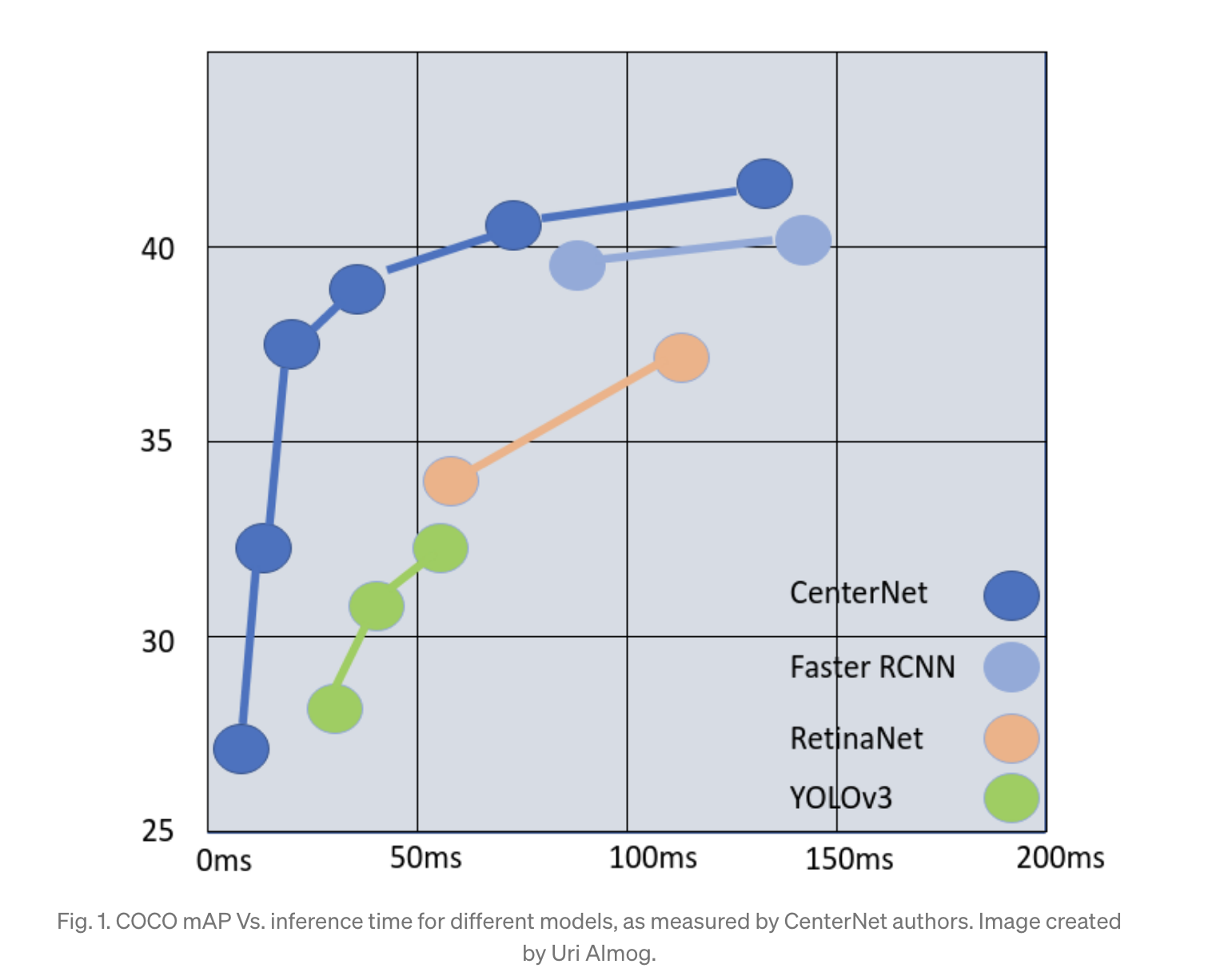
3) Performance! CornerNet보다 42.2% mAP UP!
4) 다른 keypoint기반 object detector(CornerNet 2개, ExtremeNet 5개) 보다 적은수인 1개의 keypoint를 요구한다는 점
오브젝트 디텍션을 위해 센터포인트가 어딘지 보여주는 힛맴을 만들고, 바운딩 박스를 기준점으로 만들고,
스트라이드가 4니까 오프셋을 얻어낸다?
2) Relate work
키포인트 에스티메이션은 conernet과 extremeNet이 있었다.(둘이 같은 저자)
코너넷은 비박스를 찾을 때 두 포인트를 찾게 된다. (오브젝트마다) 2n
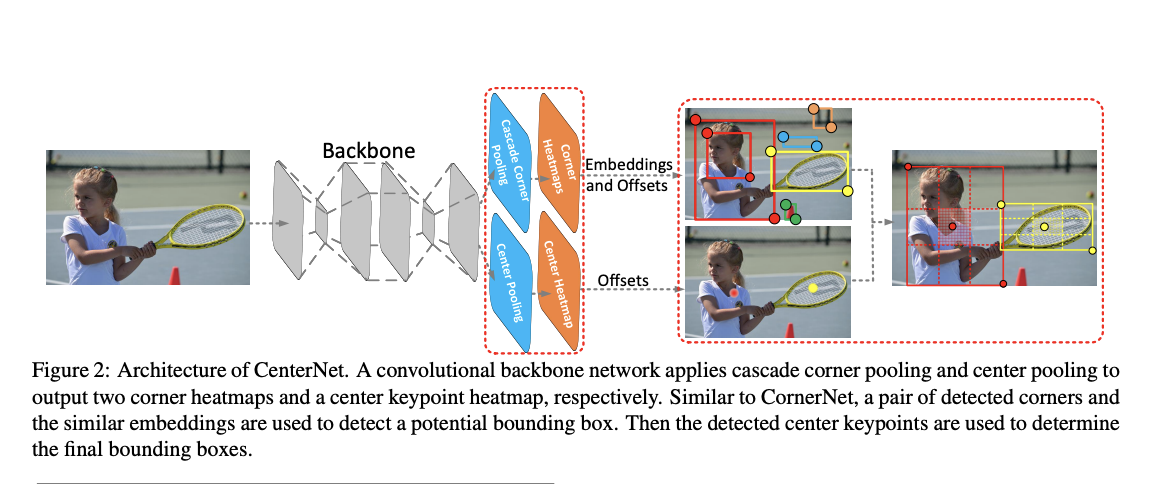
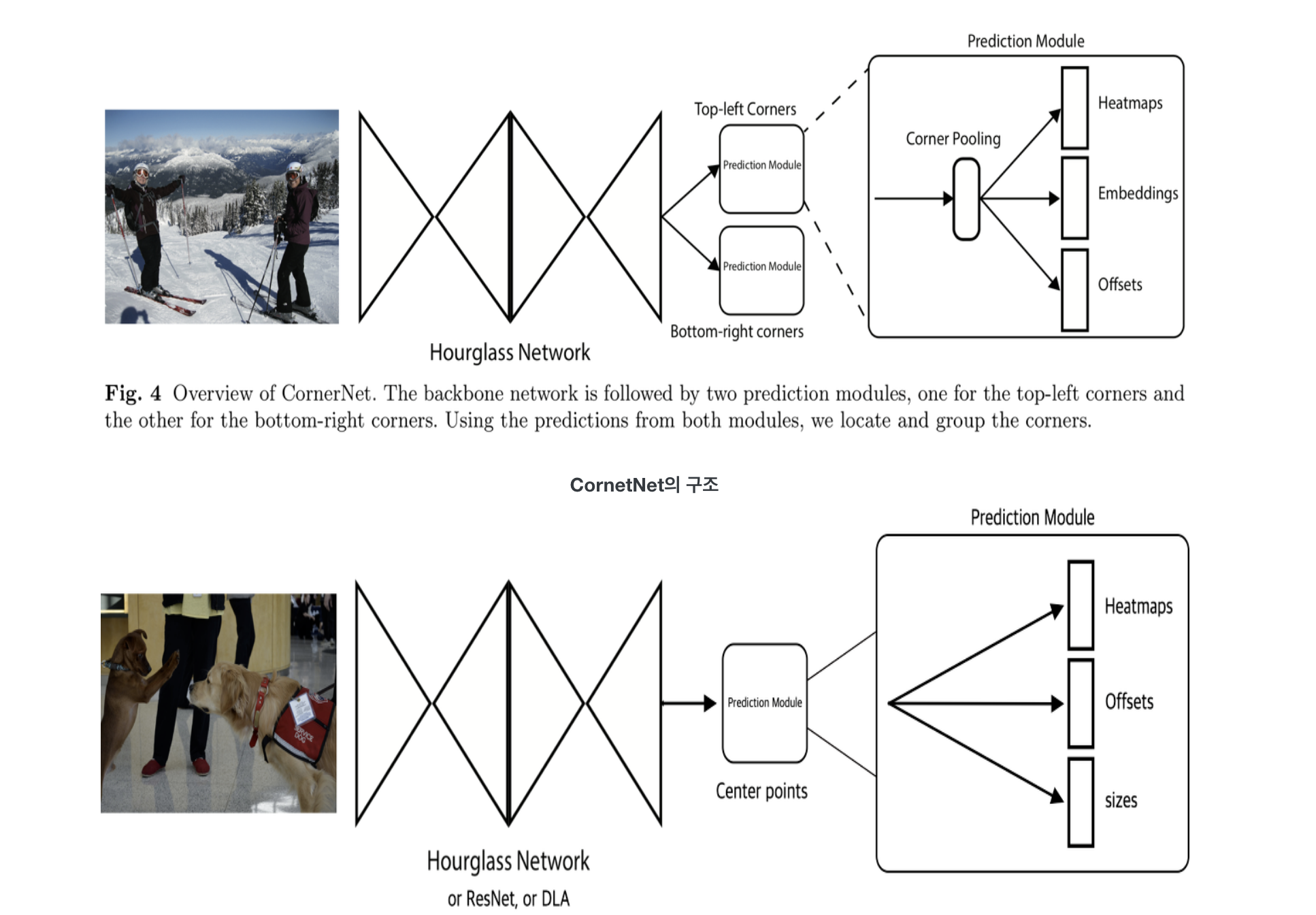
CneterNet의 구조
- CenterNet은 ConerNet과 비슷한 네트워크 구조를 사용해 keypoint를 찾음
keypoints, offset, object size를 찾기 위해 하나의 네트워크를 사용
-
Keypoints

-
Offsets
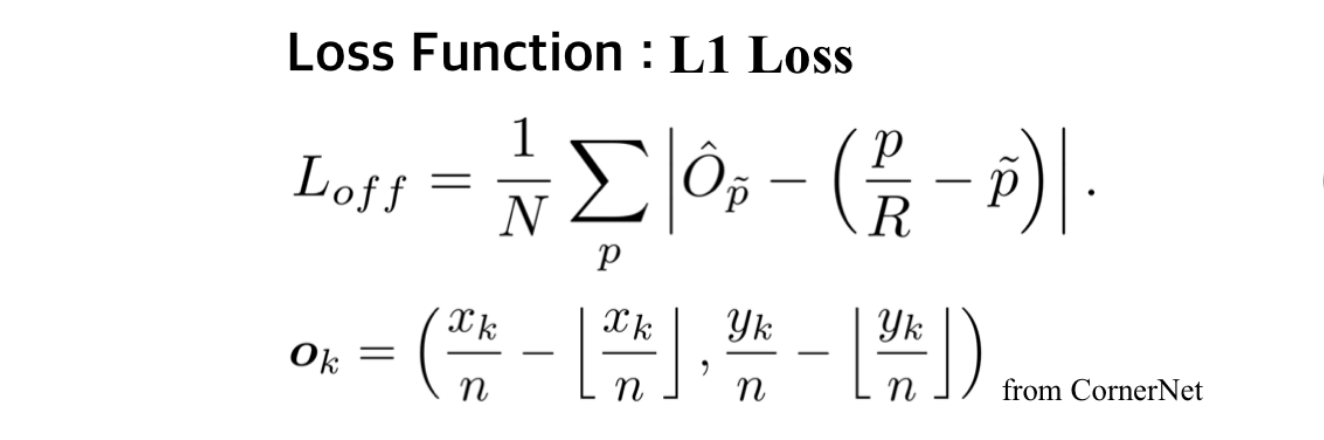
-
Object sizes

-
Overall training objective
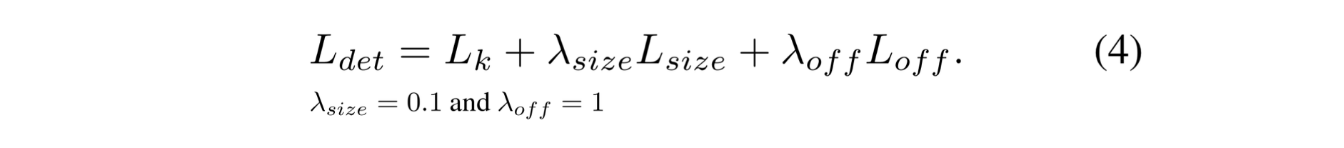
From points to bounding boxes
- 앞에서 얻어진 keypoint들로부터 객체탐지를 위한 bounding box를 얻는 과정
- CenterNet은 우선 heatmap으로부터 각 category별로 peaks들을 뽑아냄

- Heatmap에서 주변 8개 픽셀보다 값이 크거나 같은 중간값들은 모두 저장하고, 값이 큰 100개의 peak 값들을 남겨놓음
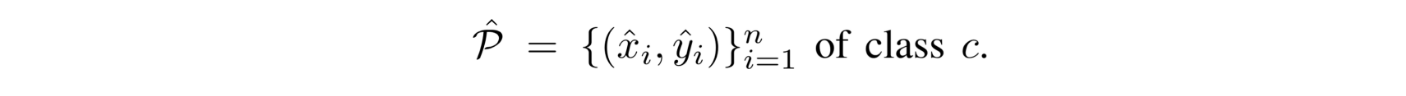
- 뽑아낸 peaks(keypoints)의 위치는 정수 좌표 형태로 표현됨(x,y)
- 이를 통해 bounding box의 좌표를 아래와 같이 나타냄
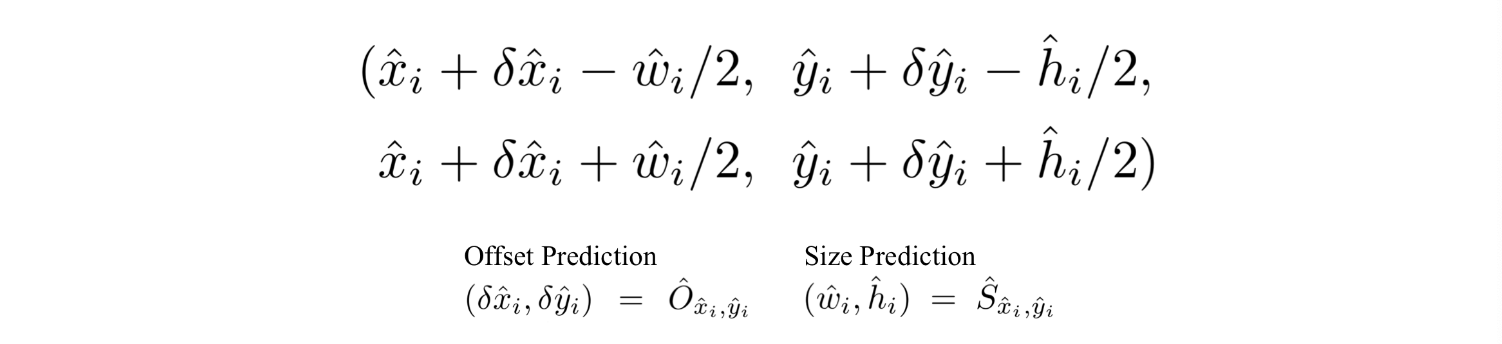
- CenterNet에서는 이런 모든 output들이 Single Keypoint Estimation으로부터 나왔다는 것을 강조함
CenterNet 성능
- ResNet-18, ResNet-101, DLA-34, Hourglass-104 총 4개의 네트워크 모델을 사용해 학습을 진행
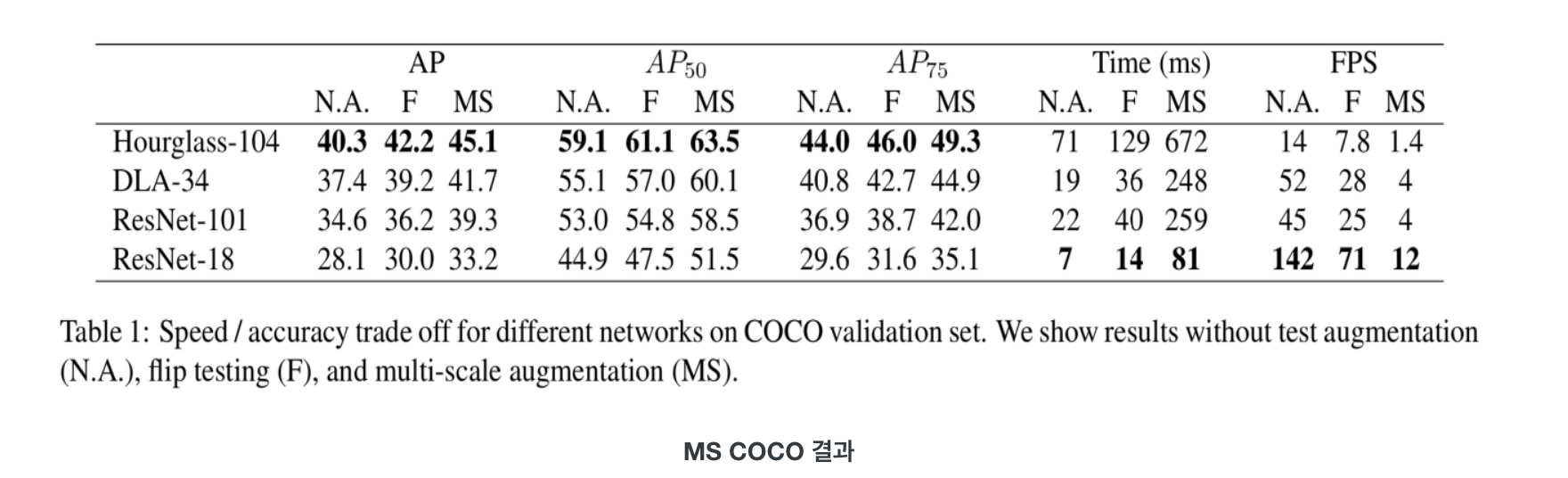
- MS COCO 기준 ResNet-18 backbone에 대해 142FPS가 나왔으며, 그때의 정확도는 28.1mAP로 매우 높음
- 간단한 구조임에도 Hourglass-104 backbone 사용시 45.1mAP가 나옴
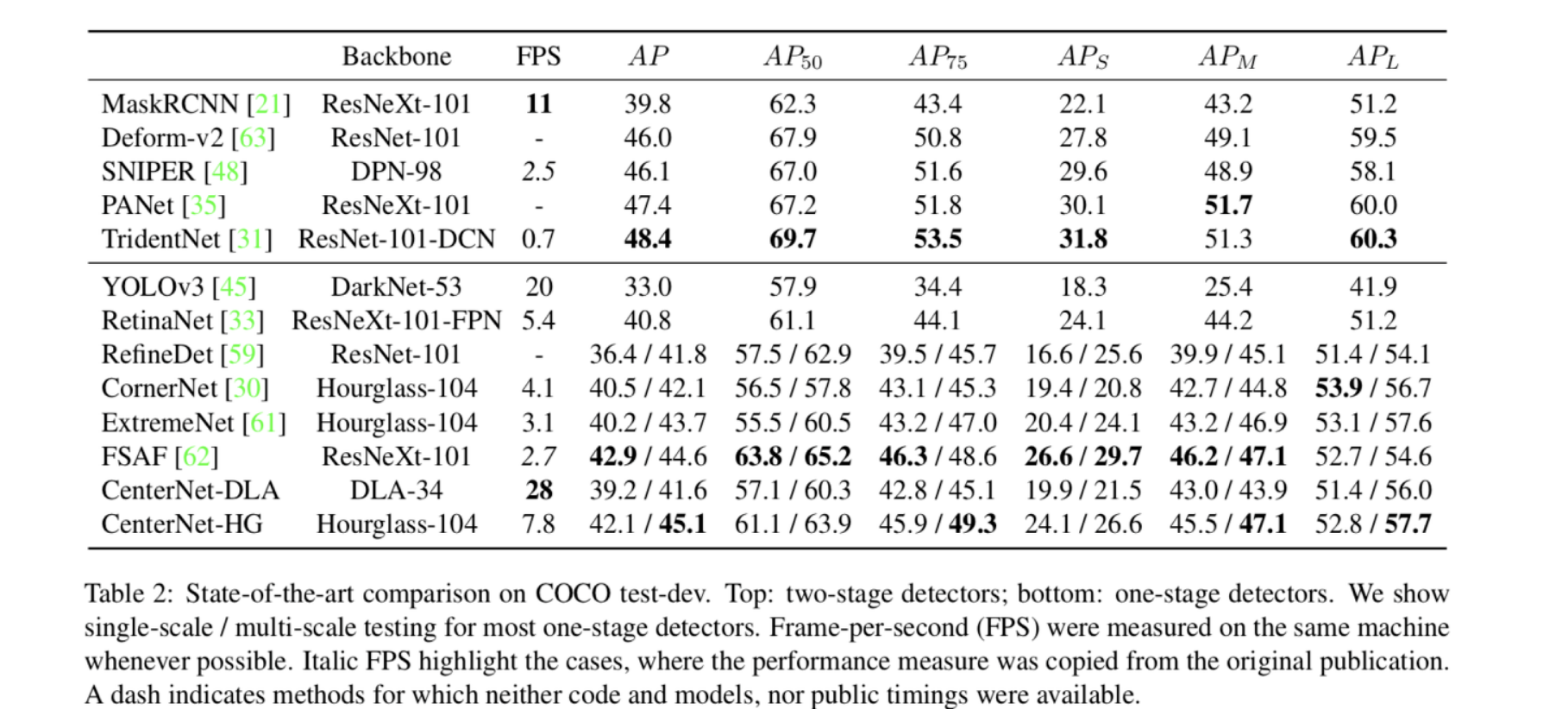
일단 결론
One Staged Detector이지만, ROI를 찾고, classify를 하는 행위는 two staged detector와 비슷한 성격을 가지고 있는 모델이라고 할 수 있다. 저자는 center keypoint를 다른 one-staged detector에도 쓸 수 있을거라고 생각하고, 좀 더 좋은 training 기법으로 CenterNet의 성능을 끌어 올릴 수 있다고 말한다.
OverView of CornerNet
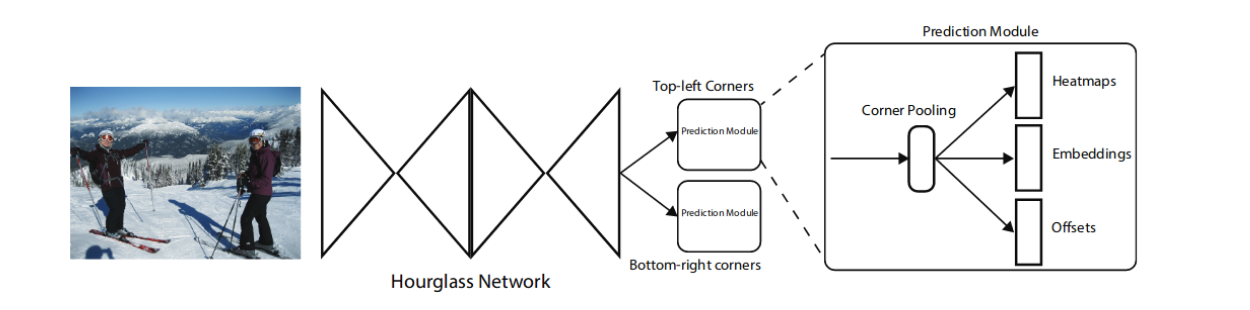
CornerNet은 hourglass를 back bone으로 쓰고 있다.
ref) https://seongkyun.github.io/papers/2019/10/28/centernet
