Abstract
R-CNN은
Region with Convolutional Neuron Network의 준말로, 영역을 설정하고 CNNs을 활용하여 Object Detection을 수행하는 신경망이다.
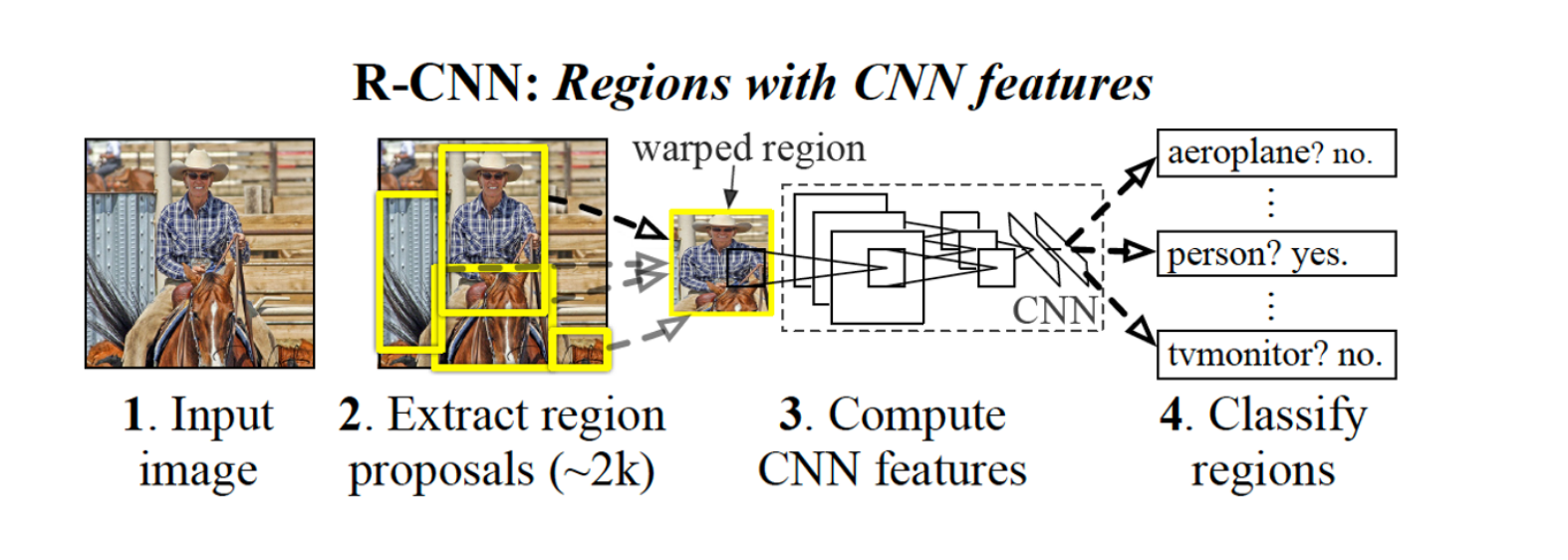
Input 이미지를 통해서 selective search(Region Proposal)를 진행하여 2000개의 후보영역을 추출한다.
생성된 후보 지역을 CNN구조로 넣기 위해 고정된 크기로 만들고(warped region) 그 2000개의 물체를 pre-training된 CNN 네트워크에 넣어서 피쳐 벡터를 추출한다. 피처 벡터들에 대하여 SVM을 이용해서 SVM를 통해 클래스 당 score를 계산하여 classification을 진행, Regressors를 통해 물체의 위치를 바운딩 박스로 예측한다.
Warped region

Selective Search
- 모든 영역에 대해 다양한 scale의 region 후보를 만든다.
- Region들에 대해 color, texture, size, fill의 값을 계산한다.
- 이웃하는 두 region 사이의 유사도를 구한다.
- 유사도가 높은 것부터 차례대로 merge하여 2000개를 구성한다.

Bounding box regression
localization을 통해 좀 더 정확한 개체를 찾아내는 바운딩 박스를 활용하게 되면 더 높은 정확도를 가져온다.
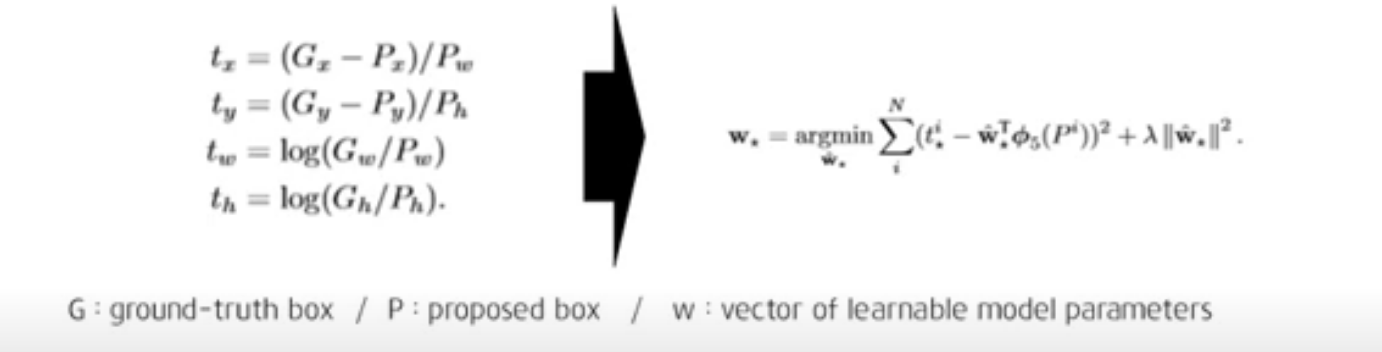
bounding box regression의 목적은 실제 박스와 유사한 proposed box를 만들어내도록 하는 것이다.
Training
-
ILSVRC2012 classification dataset을 pre-training된 CNN 구조 사용
-
Fine-tuning
-
Object category classifiers
- class별로 Linear svm을 구성해서 학습을 진행한다.
Result(VOC 2010-12)
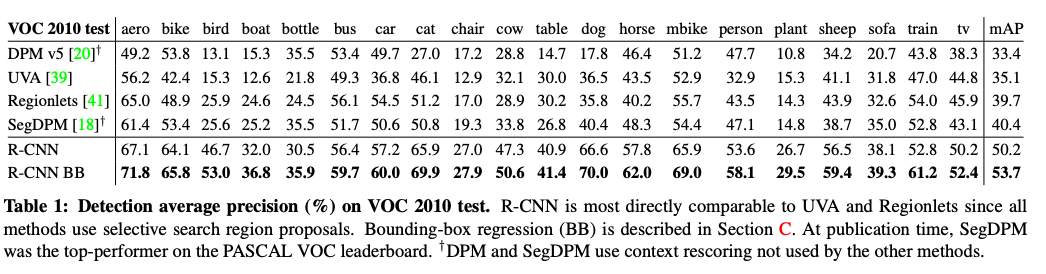
결과
:R-CNN이 selective search를 사용하는 UVA, Regionlets보다 좋은 성능을 보이고 있다. 그리고 bb regression을 사용하면서 학습한 모델의 더 좋은 성능을 보여짐을 알 수 있다.
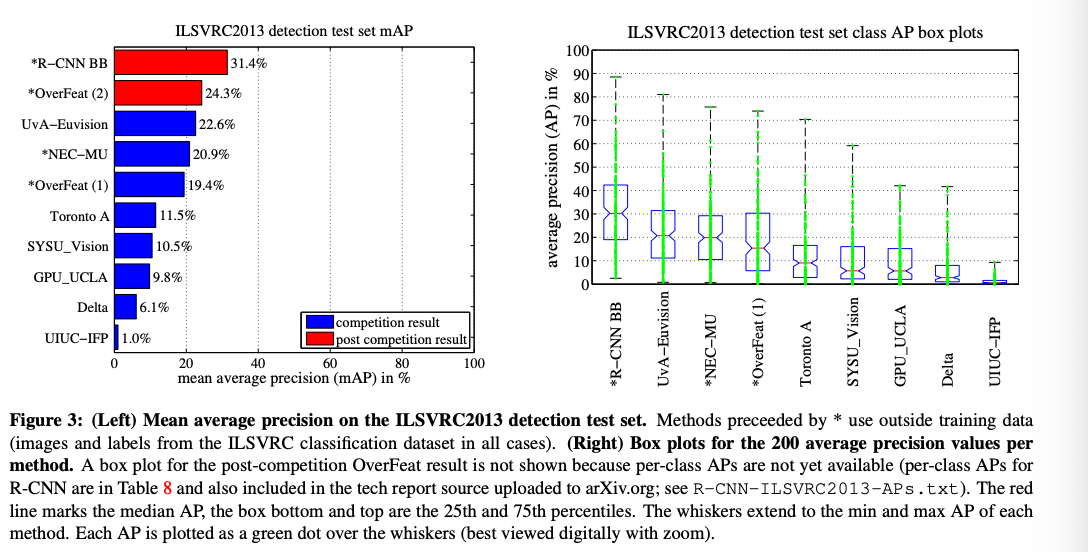
ILSVRC 2013
기존 시스템보다 성능의 우월함을 보고있다.
박스plot을 보면 박스가 위쪽 부분에 위치해 있다.
Visualizaing learned features
CNN이 어떤 것을 학습했는지 시각화

Ablation Studies
VOC 2007 test
- fine-tuning의 여부
- b-box regression 학습 여부
- DPM(base line)과 비교
결과: fine tuning과 b-box regression 학습은 더 좋은 성능을 만들어냈다.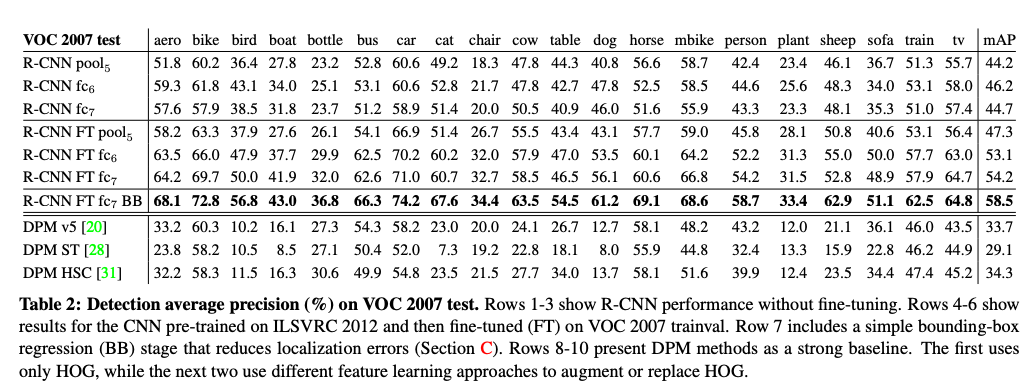
다른 두 CNN 구조의 비교 테스트
결과
: O-Net(VggNet)의 결과가 더 좋다.
복잡도가 더 크기 때문이다. (CNN으로부터 얻은 피쳐의 표현 능력이 좋아짐)
Semantic segmentation

Summary
- Detection task의 성능이 2배 이상 향상 됐다.
1. Region proposal algorithm으로부터 얻은 결과와 CNN을 통해 representational power가 높아졌기 때문이다.
2. 단점으로는 이미지의 고정화로 인해 이미지가 손상된다.
3. 2000개의 지역을 각각 CNN을 수행하기에는 학습 시간이 길어진다는 단점이 있다.
Ref)
https://arxiv.org/pdf/1311.2524.pdf
https://www.youtube.com/watch?v=X4TxIPuYu0E
