개요
언어의 벡터화를 통해 자연어처리 안에서 특징 추출을 통해 수치화 시켜야 한다.(word embedding)
가장 심플한 것은[1,0][0,1]로 만드는 원-핫 인코딩 방법이 있다. 하지만 단어가 많아지면 벡터의 공간이 커져 실제 1인 값은 한개뿐이므로 매우 비효율적이다. 이러한 방식은 단어가 뭔지는 알려주지만 어떤 특징인지는 표현하지 못한다.
so..Dense
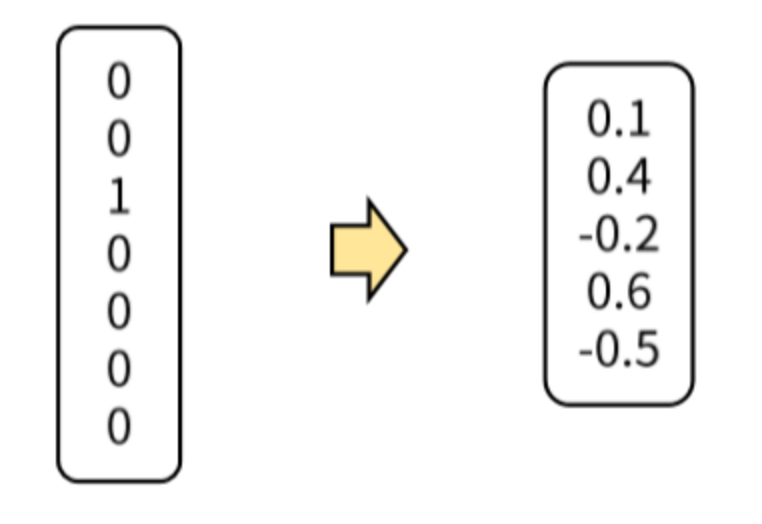
단어의 수에 상관없이 특정 차원의 벡터로 변환시켜 단어의 특성이나 유사성을 나타내 줌.
예를 들어 남자, 여자를 [0.2,0.5][0.1,0.4]의 실수 형태 벡터로 표현해준다.
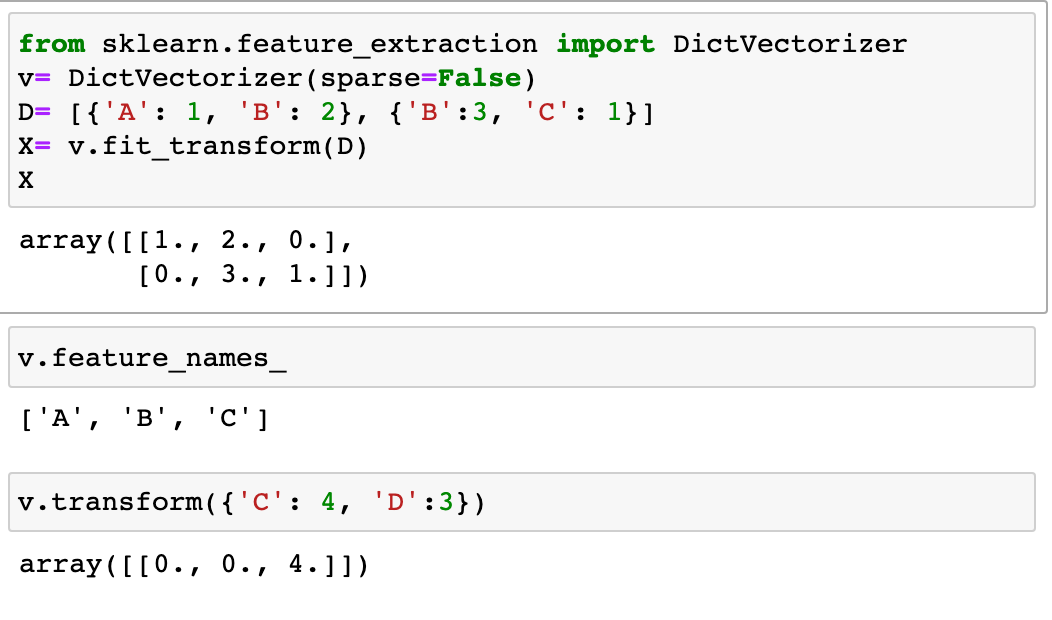
DictVectorizer:
각 단어의 수를 세어놓은 사전에서 BOW 인코딩 벡터를 만든다.
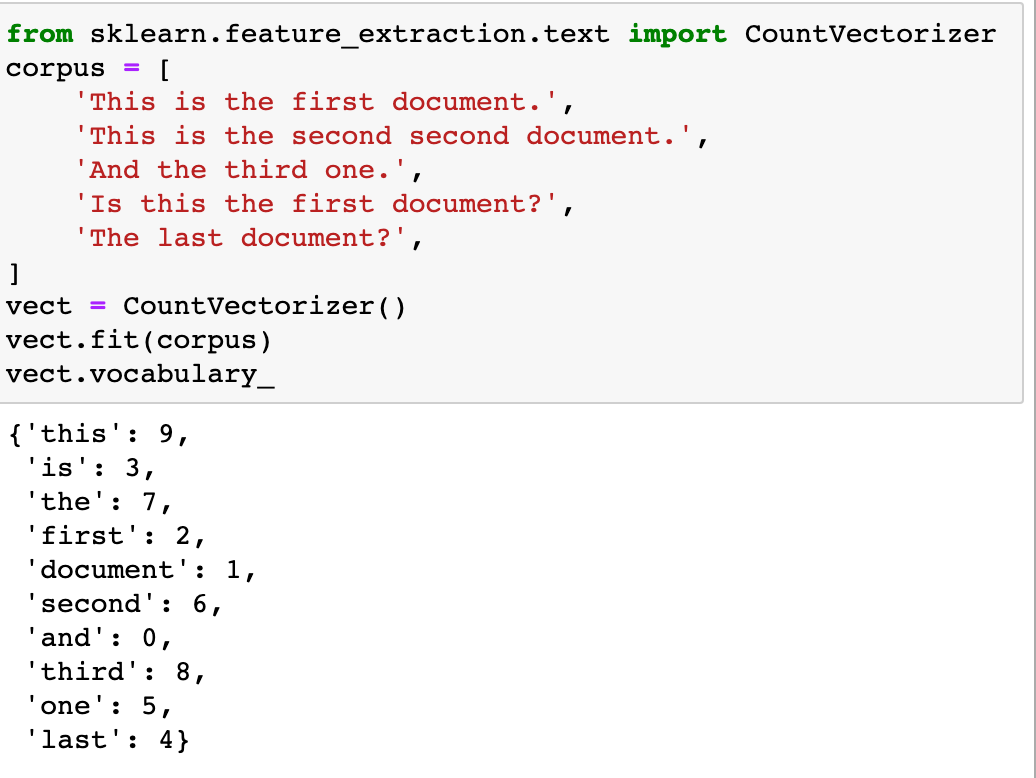
CountVectorizer:
문서 집합에서 단어 토큰을 생성하고 각 단어의 수를 세어 BOW 인코딩 벡터를 만든다.
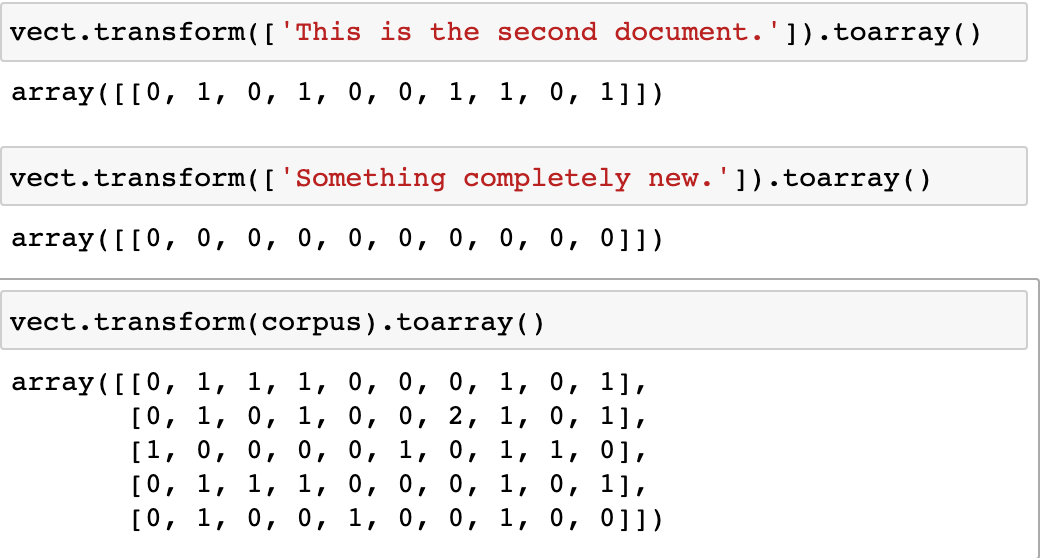
example)
TfidfVectorizer:
CountVectorizer와 비슷하지만 TF-IDF 방식으로 단어의 가중치를 조정한 BOW 인코딩 벡터를 만든다.
HashingVectorizer:
해시 함수(hash function)을 사용하여 적은 메모리와 빠른 속도로 BOW 인코딩 벡터를 만든다.
https://simpling.tistory.com/1 https://datascienceschool.net/03%20machine%20learning/03.01.03%20Scikit-Learn%EC%9D%98%20%EB%AC%B8%EC%84%9C%20%EC%A0%84%EC%B2%98%EB%A6%AC%20%EA%B8%B0%EB%8A%A5.html ## 파이토치에서 ### Embedding 임베딩 층은 룩업 테이블이다.
Innovation is mine