cs231_5
Chapter.5
Convolutional Neural Networks
활성화 함수를 쓰는 이유
-
zero-pad
의도대로 출력 사이즈를 만들어 주기 위함.
이미지 가장자리에 0을 넣어준다.Q)만약 7x7 입력에 3x3 필터 연산을 수행할 때 zero-padding을 하면 어떻게 출력이 될까?
A)- padding을 넣는 이유?
주로 출력 크기를 조정할 목적으로 쓴다. 출력의 크기가 1이 되는 것을 막기 위해 미리 임의의 공간을 넣는 것이다.
- padding을 넣는 이유?
발표파트
56p)예제 문제
32x32x3의 input에 5x5필터 10개와 stride1, pad가 2이면 outpuat volume size는?
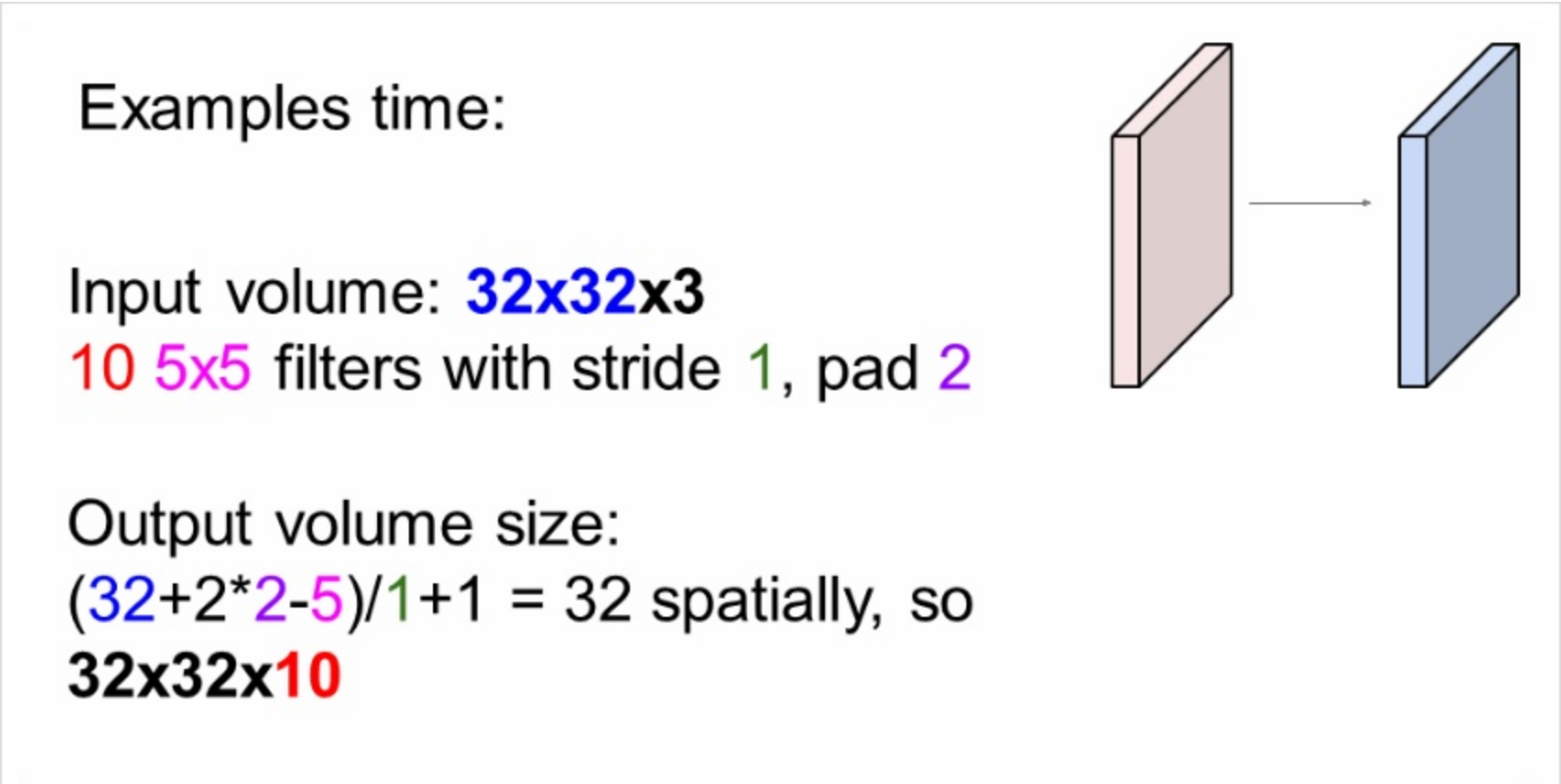
입력 사이즈 F=32, 2x패딩2 추가 시키면 32 +4, 필터 사이즈5를 빼주면 각 필터는 32x32가 된다. 전체 필터 수는 10개니깐 32x32x10
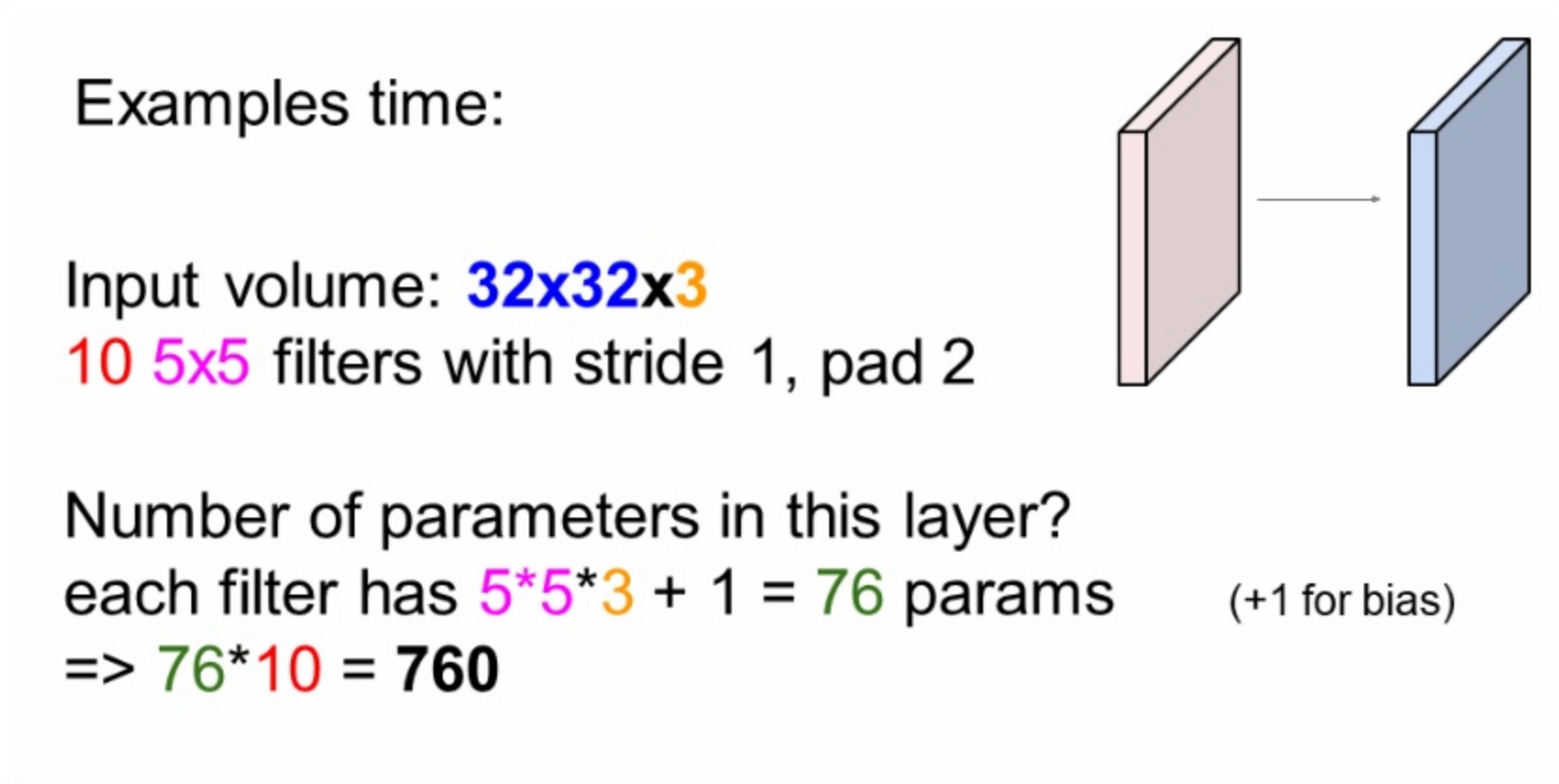
이 레이어의 파라미터 수는 몇개인가?
760개
5x5x3 = 75, 여기에 bias+1값 = 76 그리고 10개의 activation map을 곱하면
76x10 = 760

ConvNet에 필요한 하이퍼파라미터는 필터의 수인 K, 필터의 크기인 F, 보폭인 S, zero padding의 수인 P이다.
필터 갯수 K는 2^꼴로 가게 되고, 필터는 보통3x3, 5x5를 쓴다.
stride는 1, 2가 흔함.
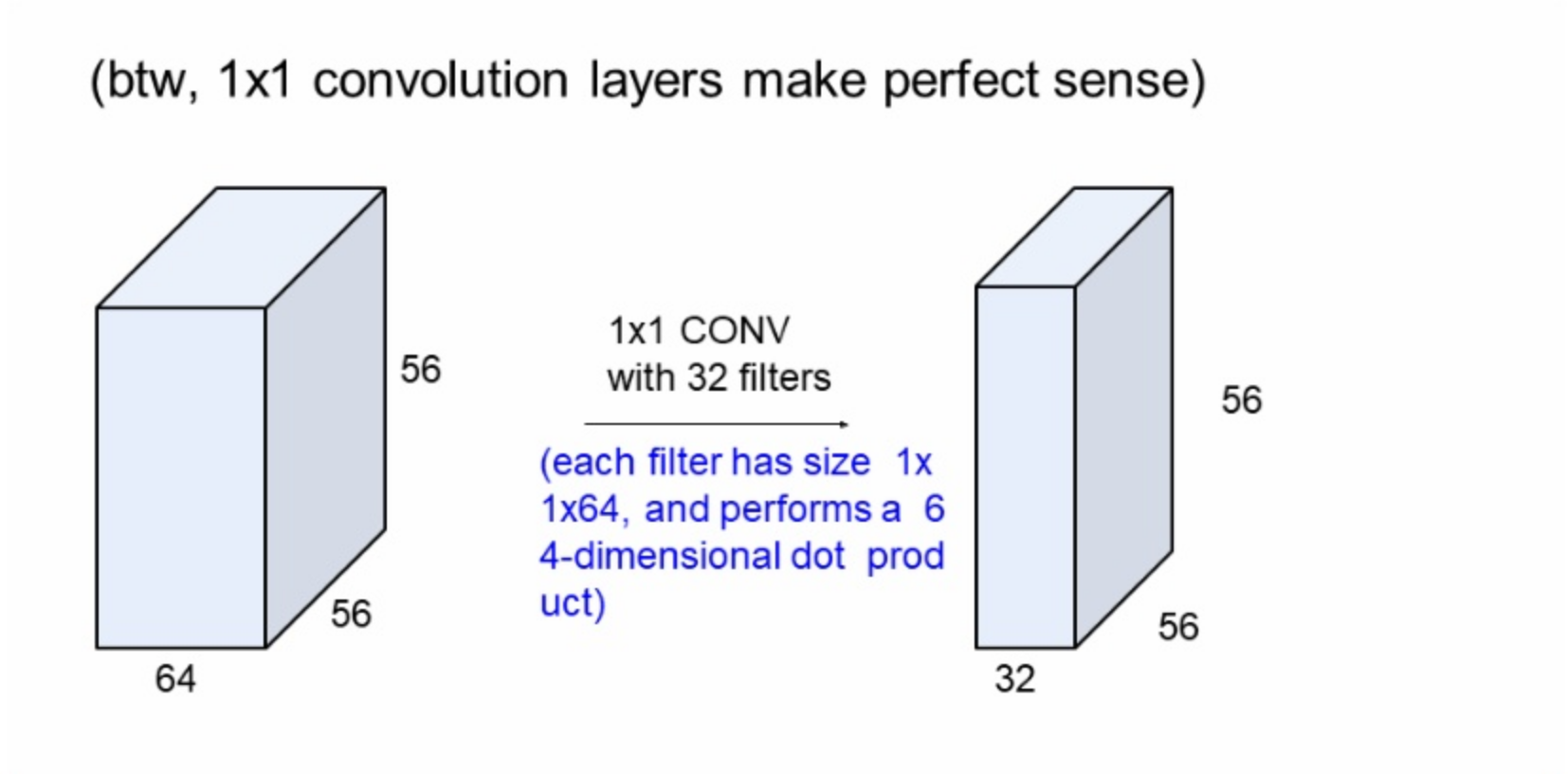
1x1 conv layer? 똑같이 슬라이딩하면서 값을 구함. 1x1xD의 convolution은 차원을 줄여주는 역할을 한다.
56x56x64의 입력이미지에 32개의 필터를 1x1 CONV한다는 것은 크기가 1x1x64인 64개의 필터가 있고 64차원 내적을 한다는 뜻이고, 그 결과로 56x56x32의 activation map이 나온다. 참고로 1x1의 convolution layer는 pooling과 비슷하다.
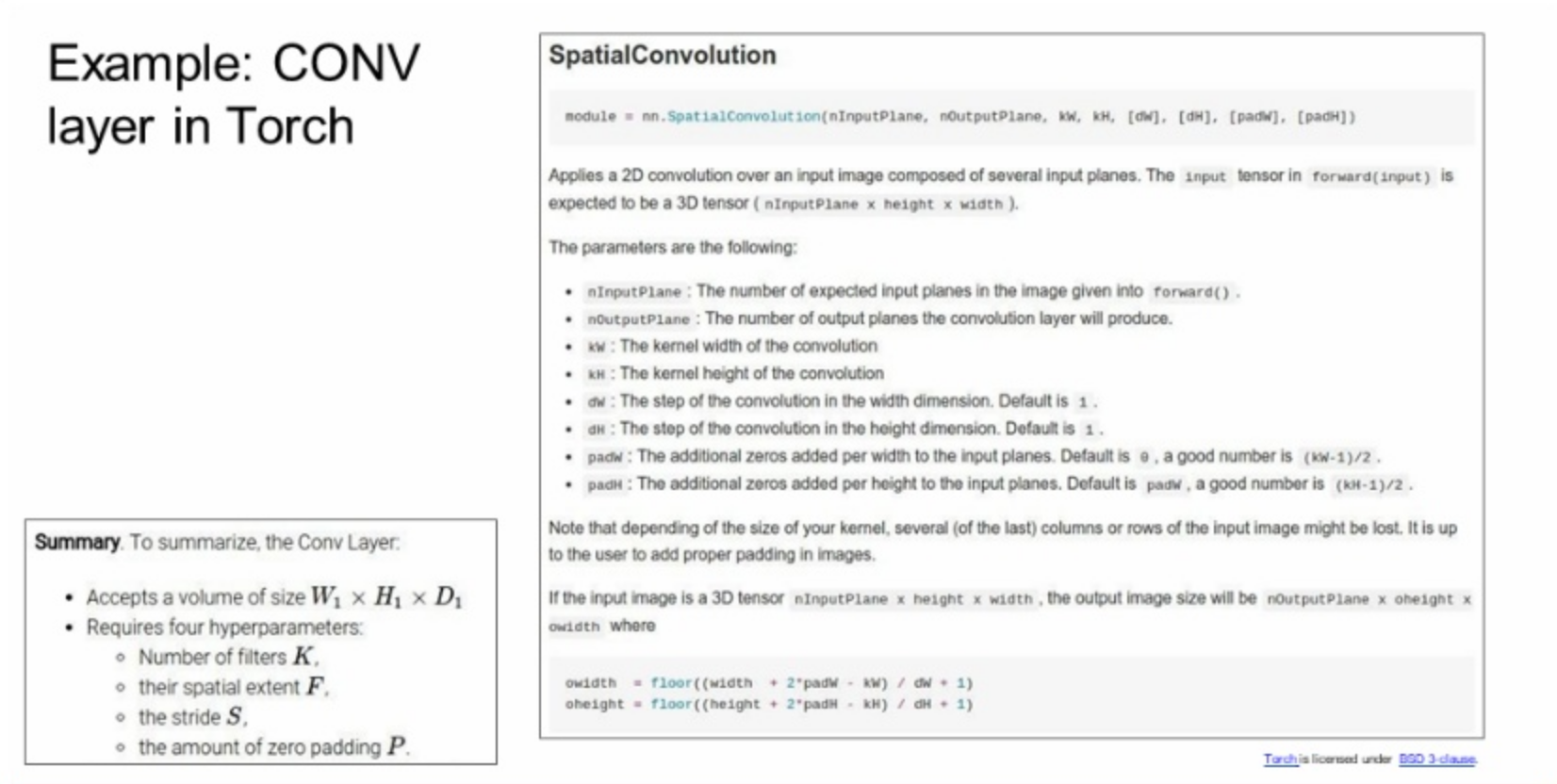
Torch
여러 arguments를 가지고 디자인할 수 있음.

caffe

뉴런의 관점으로 보면 Convolution Layer는 local connectivity(1구역은 1노드가 담당)를 가진 뉴런과 같다.
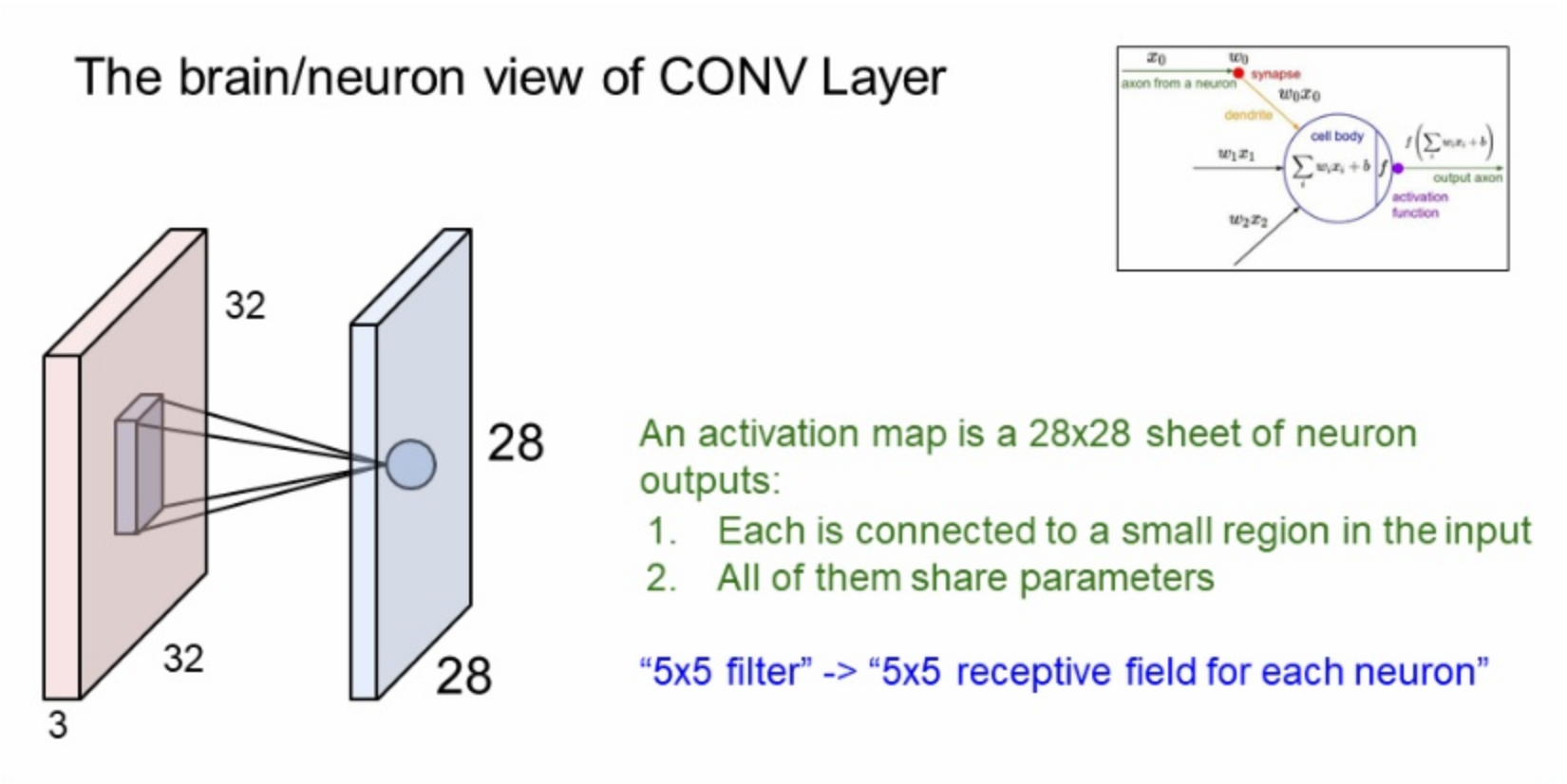
activation map은 28x28개의 뉴런 출력이고, 각각은 입력 이미지의 국소적인 부분과 연결된다.
5x5 필터는 각 뉴런의 5x5 수용체(receptive field)와 같다.
즉, 필터가 5개이면 같은 영역에 대해 5개의 값이 나오게 된다.
*receptive field = 한 뉴런이 한 번에 수용할 수 있는 영역
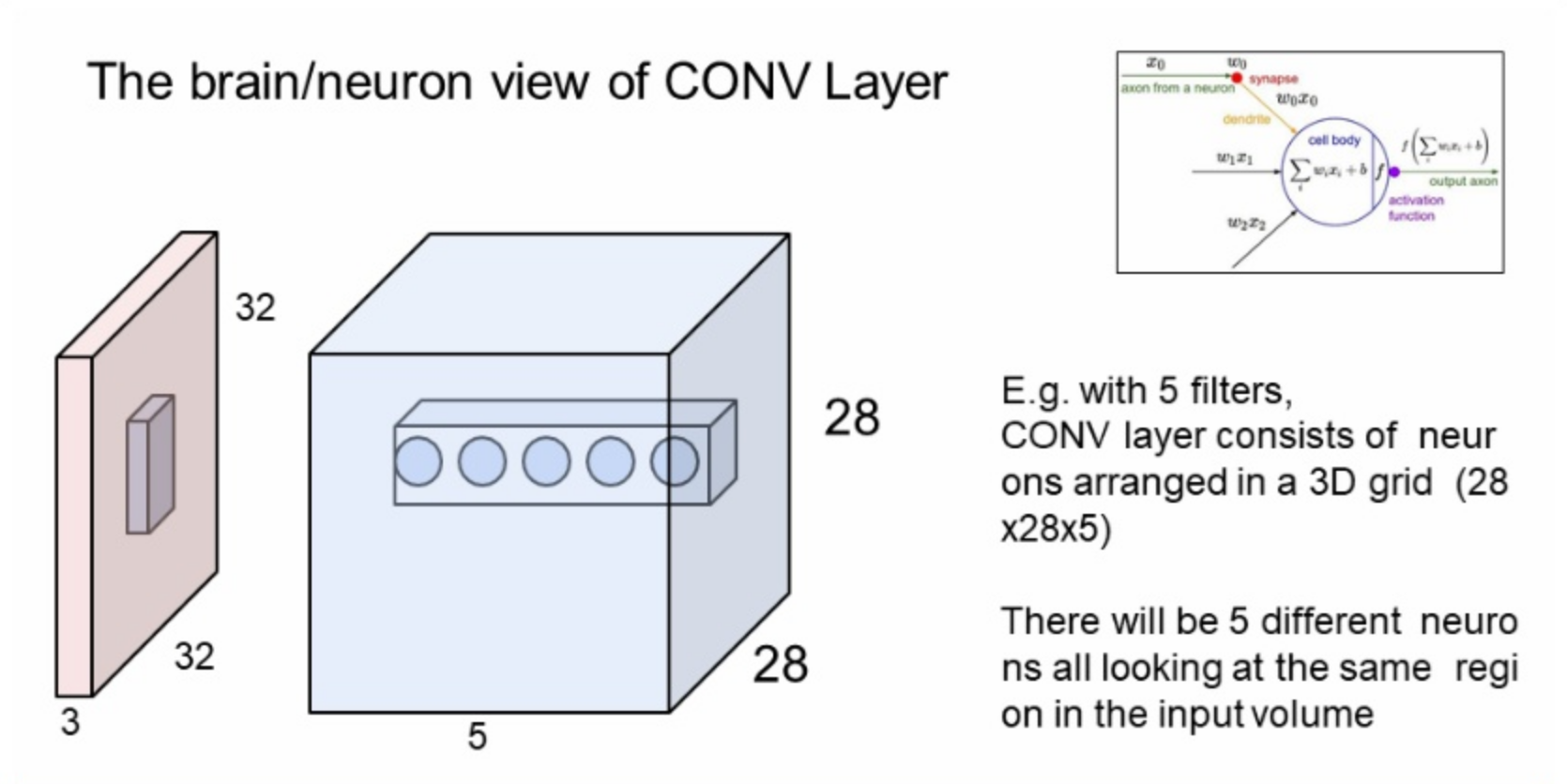
5개의 필터를 가진 CONV layer 는 28x28x5 안에 존재하는 뉴런으로 구성되어 있다. 5개의 뉴런들이 입력 이미지의 같은 부분을 모두 본다. 즉 동일한 파라미터를 가진 5개의 필터는 입력 이미지의 같은 부분에 연산을 각각 1번씩, 총 5번을 하게 된다.
그림과 같이 그 5개의 다른 필터는 각각 다른 특징을 가지고있어 서로 다른 값을 뽑아내는 것이다.
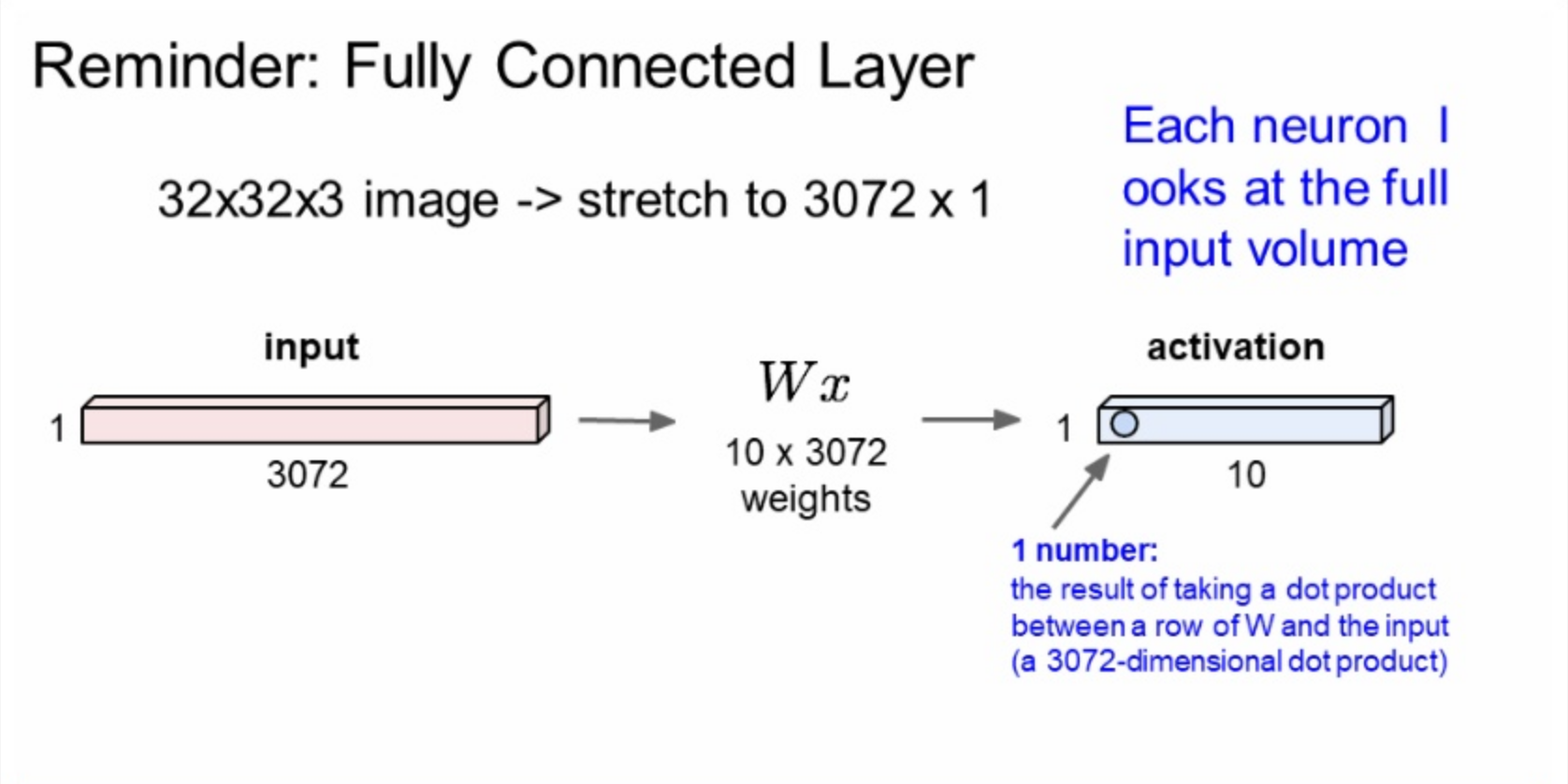
FC layer는 32x32x3의 이미지를 쭉 늘려 3072x1의 벡터로 만든 후, 가중치 W와 내적해 1개의 숫자(점수)를 추출한다. 뉴런의 관점에서 보면 각 뉴런이 전체 입력 이미지를 한 번에 보는 것과 같다.
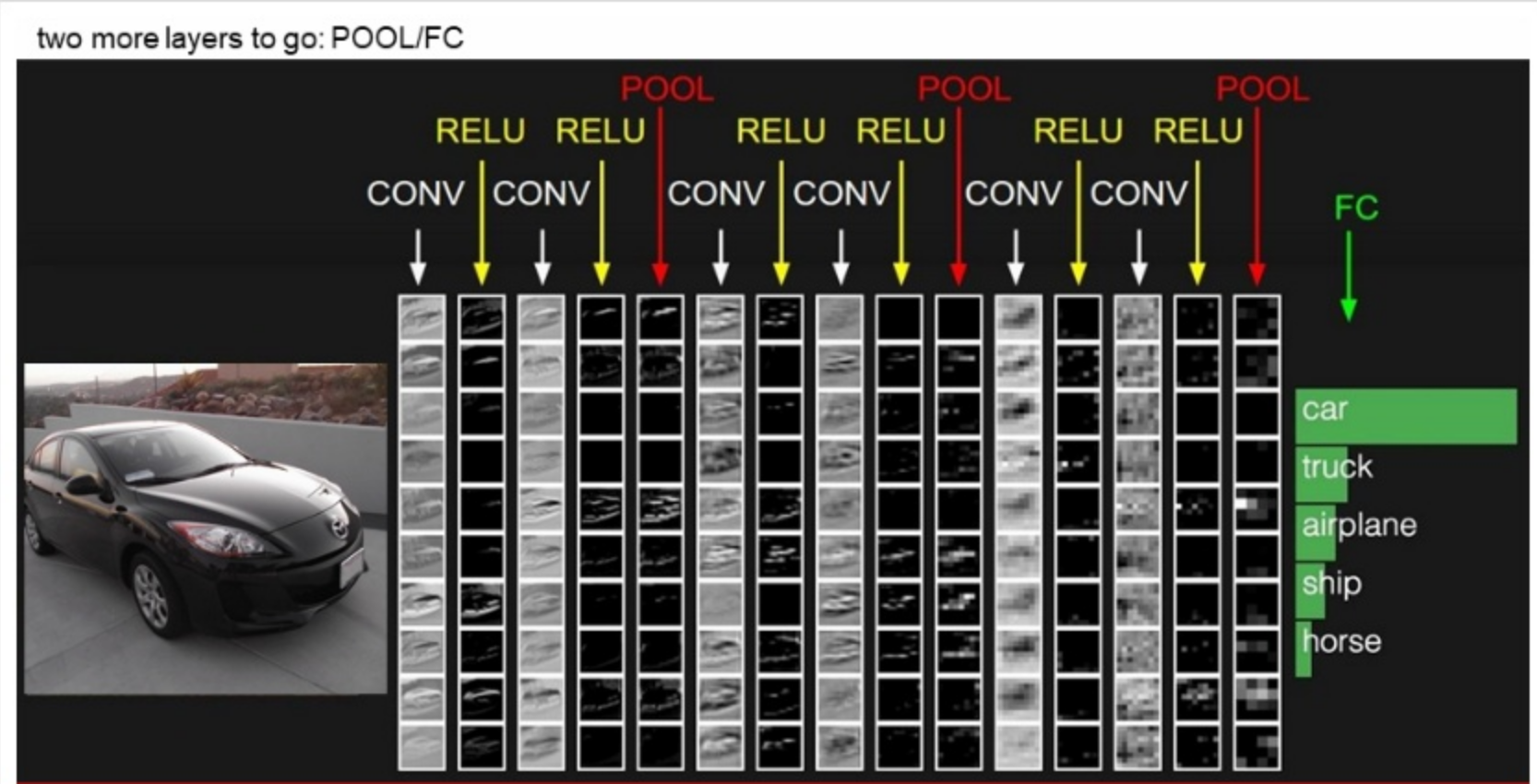
자동차를 어떻게 분류하는지를 보여준다.
convolutino layer와 relu조합을 2번 반복하고, pooling하여 차원을 줄여주고 있다.
그리고 마지막 Fully Connected Layer를 통과하여 이미지가 어떤 것인지 1개의 숫자로 분류해 준다.
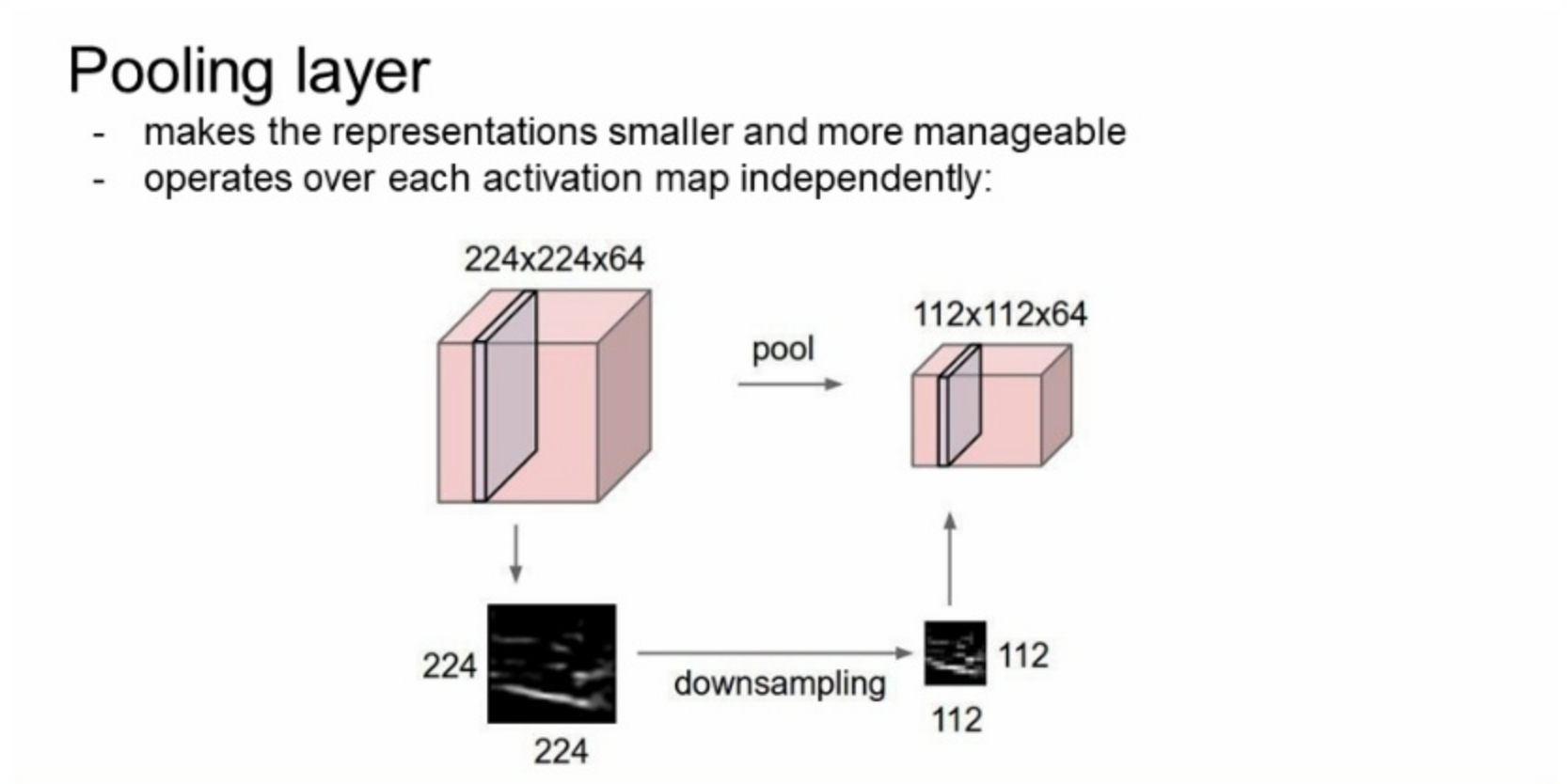
pooling layer는 representation을 'downsampling'을 한다.(이미지 사이즈를 줄여 줌)
큰 특징값을 유지하면서 줄여준다.
그럼 왜 작게 만드는가?
작아지면 파라미터의 수가 줄어 든다. 그러면 관리가 쉽다.
depth는 줄이지 못한다.
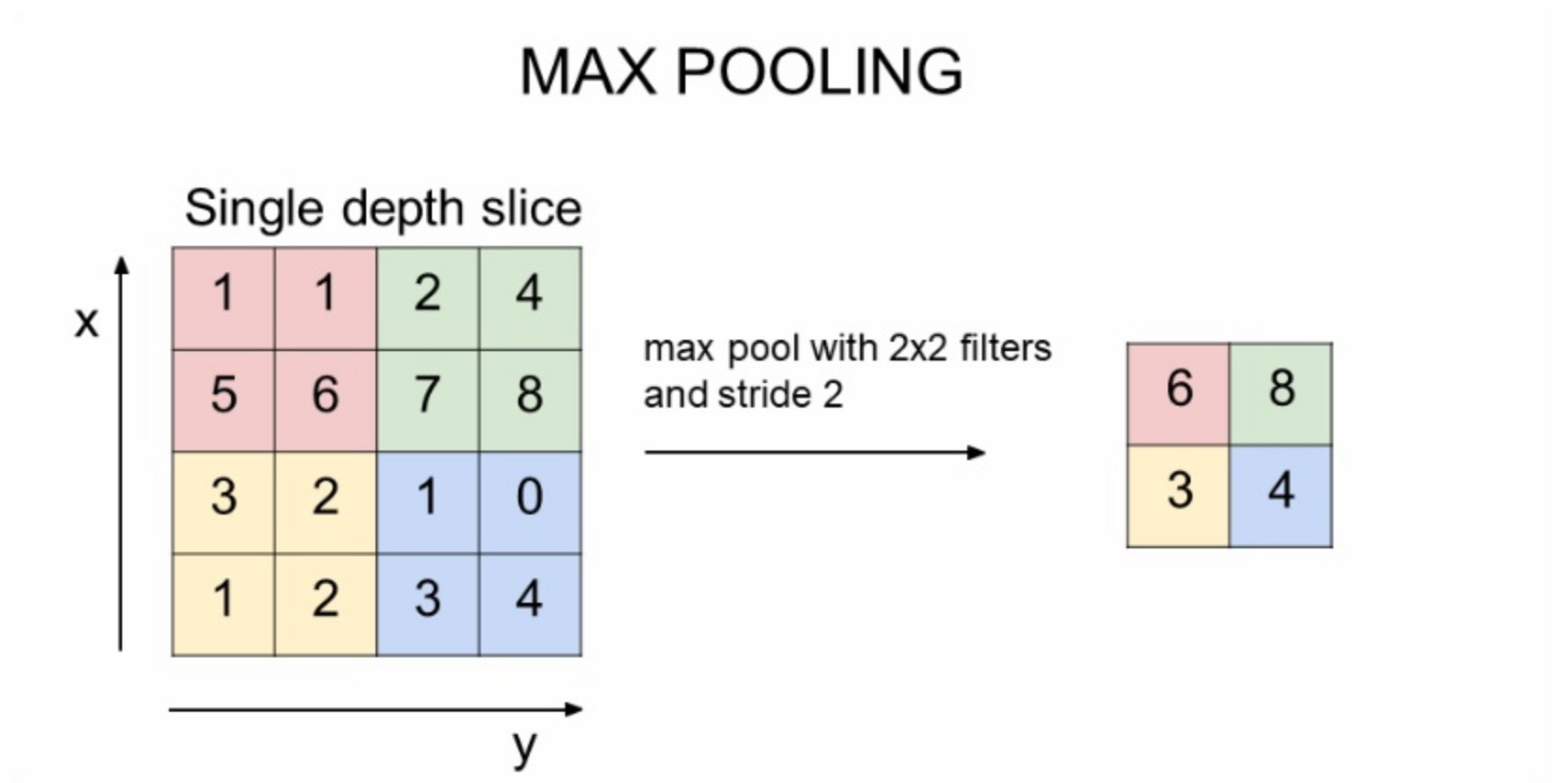
max pooling은 필터 안에서 가장 큰 값을 고르는 것
max pool이 2x2면 크기가 절반으로 준다. 이런 식으로 이미지의 사이즈를 줄여나간다.
그럼 왜 pooling하는가?
피쳐가 많아지면서 발생할 수 있는 오버피팅을 방지하기 위함이다.
stride나 pooling으로 Downsampling하게 되는데 요즘 추세는 stride

ConvNets은 CONV, POOL, FC layer가 모여 만들어진다. convolution layer는 파라미터를 많이 사용한다.
