Intro
MobileNet은 딥러닝의 경량화를 위해 구글에서 2017년에 발표되었다.
Structure
핵심은 Depthwise Separable Convolution이다.
비교해볼 수 있는 것이 'Xception'인데, shortcut이 있고, 1x1->3x3 conv를 사용하는 것에 비해 'MobileNet'은 3x3 => 1x1 순서로 conv block을 구성하고 non-linearity를 추가하고 있다.
구조를 보자.

다시 표로 살펴보면
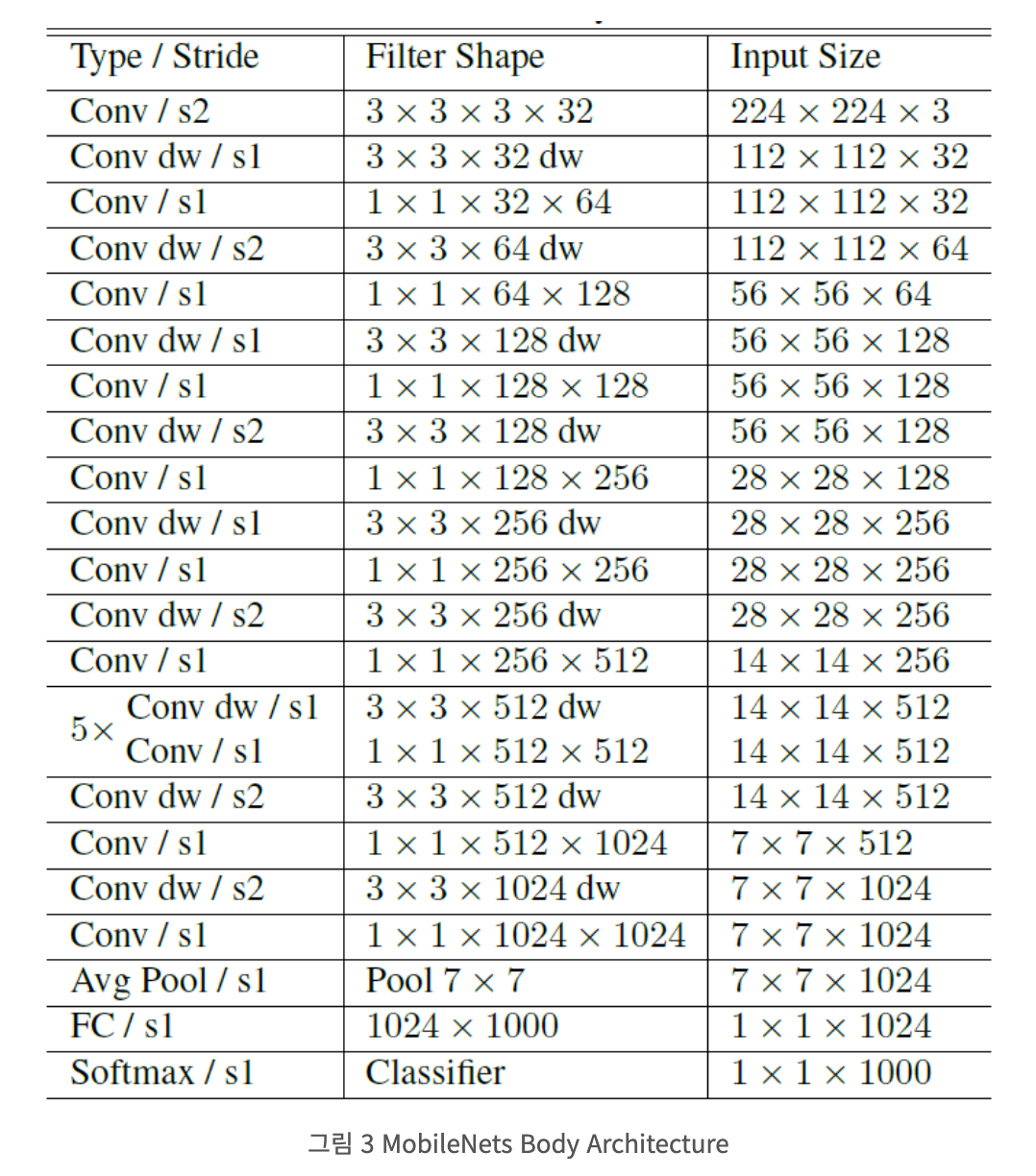
첫 레이어에는 Standard Convoultion이고, 처음에는 Depthwise Separable Convolution이 아닌 일반적으로 사용하는 Convolution을 사용한다.
(Conv dw- Depthwise Convolution)
이렇게 Depthwise Separable Convolution을 쌓은 모델이 MobileNet이다.
Concept
- Width Multiplier
input channel M과 output channel(filter개수와 동일)N에 a를 곱해서 채널을 줄이는 역할을 한다.
Widht Multiplier 알파를 곱한 depthwise separable convolution의 연산량은 다음과 같다. (a알파는 0~1)

- Resolution Multiplier
Resolution Multiplier는 input의 가로 세로 크기를 줄여서 연산량을 줄이는 역할을 한다.
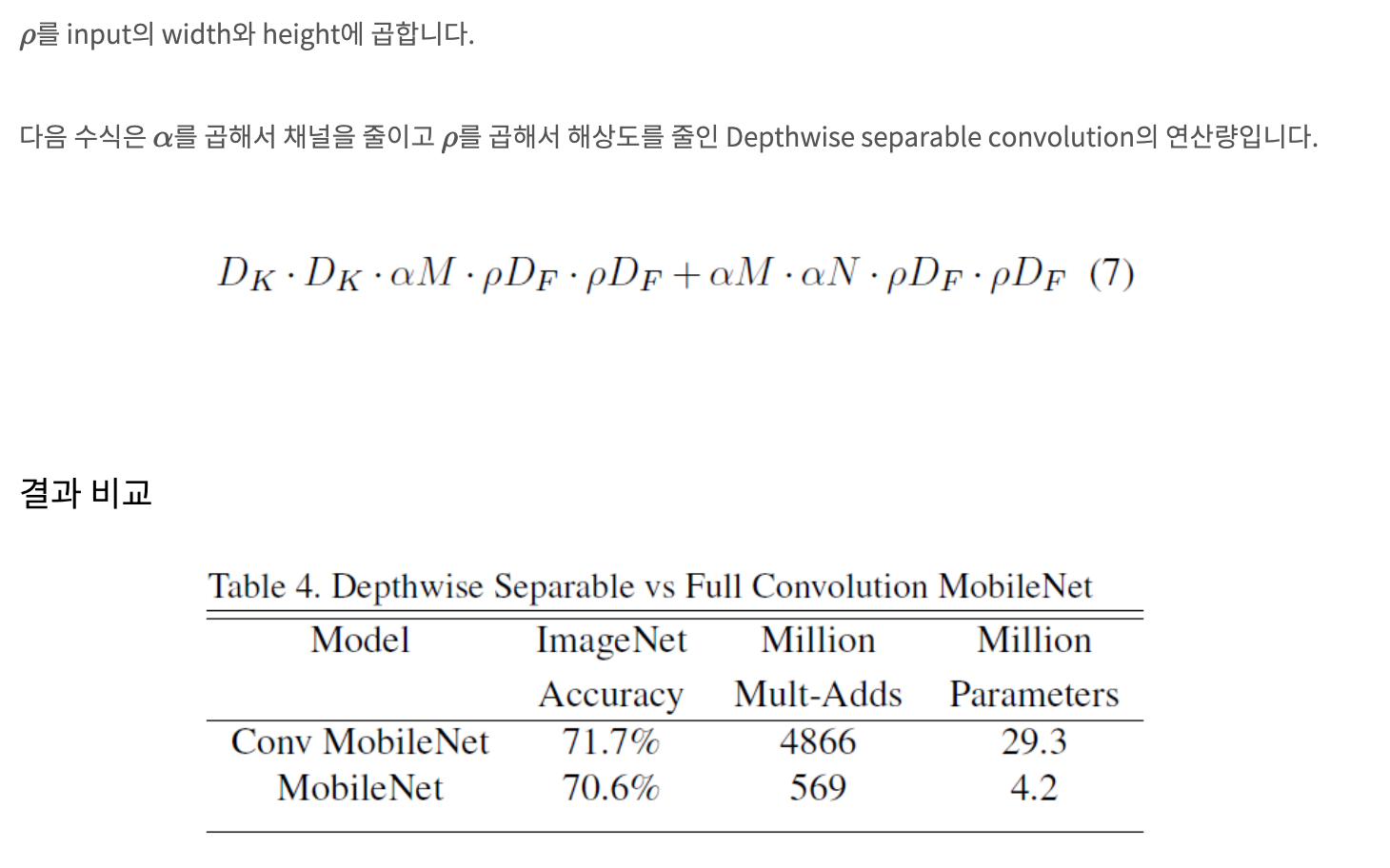
ref)MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
PR-044 MobileNet
https://sotudy.tistory.com/15
