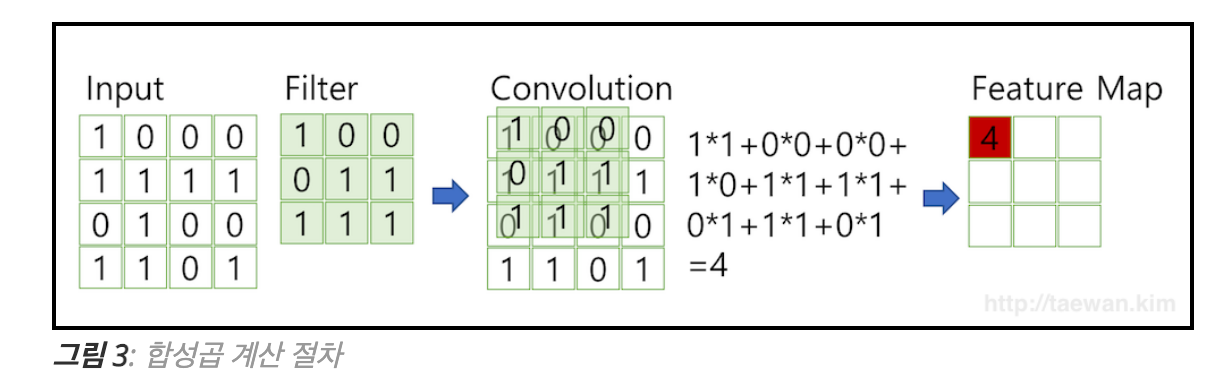
- 초반부 정리
Intro
History
Review: LeNet-5
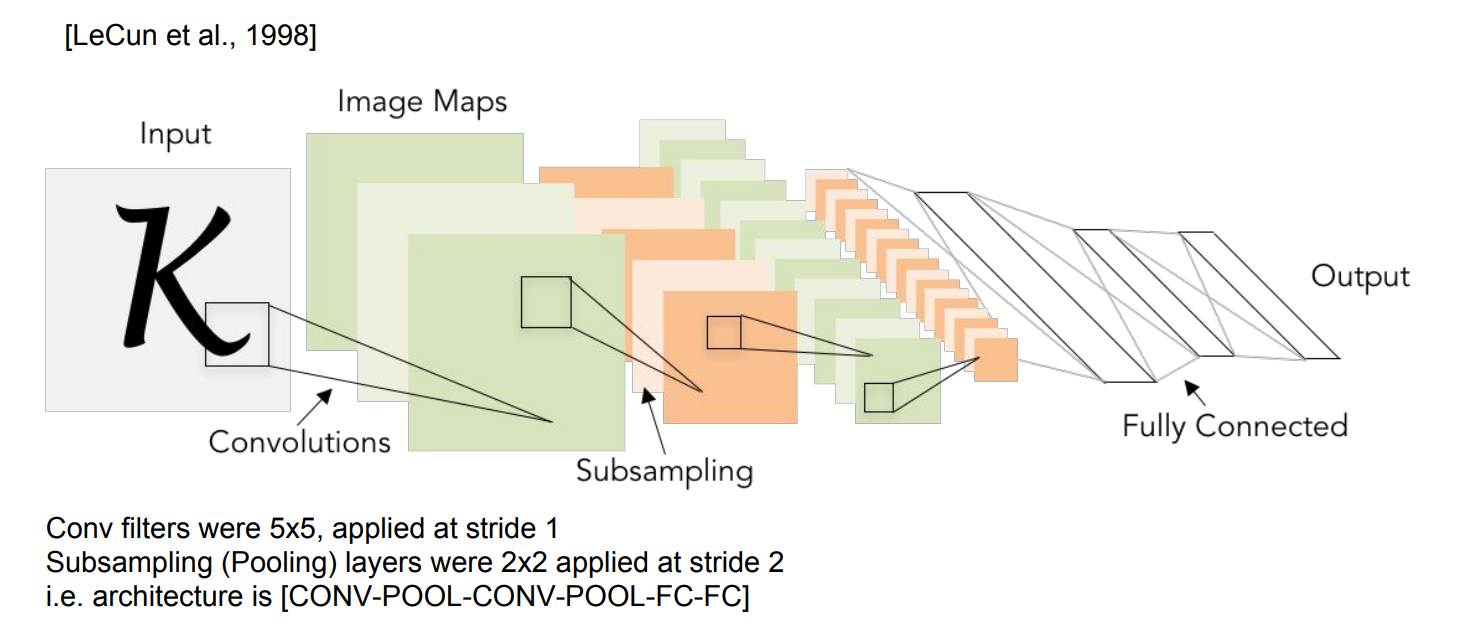
산업에서 잘 적용된 최초의 ConvNet
Case Study: AlexNet
논문 참조) ImageNet Classification with Deep ConvolutionalNeural Networks
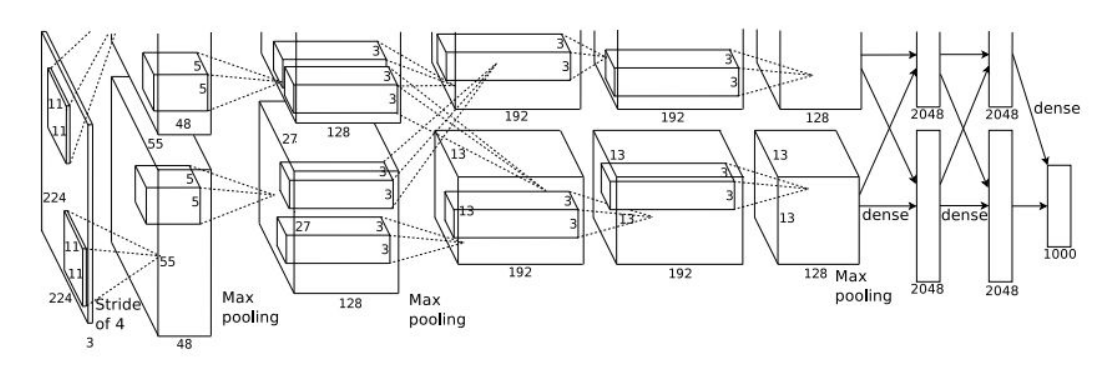
(그림에 224x224로 표현되어있는데 227x227이 맞다.)
최초의 Large scale CNN-
- ImageNet Classification Task를 잘 수행함.
- ConvNet 연구의 인기를 불러 일으킴.
- Conv-Pool-normalization 구조가 두 번 반복한다.(그리고 마지막엔 FC-layer가 몇개 붙는다.
Q) First layer(CONV1): 96 11x11 filters applied at stride 4,
-
What is the output volume size?
(hint: (227-11)/4+1 = 55)
볼륨사이즈: (Width-Filter)/Stride+1A: 55x55x96(depth) -
What is the total number of parameters in this layer?
A: 전체 필터의 크기 x 96 -> (11x11x3)x96 =35K
Q) Second layer(POOL1): 3x3 filters applied at stride 2,
-
What is the output volume size?
A: (55-3)/2+1 = 27 -> 27x27x96 -
What is the number of parameters in this layer?
27x27x....(x) Pooling layer에은 파라미터가 없다. Conv layer에는 가중치가 있지만 pooling에서는 no weight
Just a second, Say for known concept 'pooling layer'
Pooling 레이어는 Convolution 레이어와 비교하여 다음과 같은 특징이 있다.
-
pooling layer에는 파라미터가 없다.
ref) http://taewan.kim/post/cnn/ -
학습대상 파라미터가 없음
-
Pooling 레이어를 통과하면 행렬의 크기 감소
-
Pooling 레이어를 통해서 채널 수 변경 없음
*Say more about this
conv layer에는 학습할 수 있는 가중치가 있다.
but, pooling은 no weight, 단지 특정 area에서 high value를 추출할 뿐이다.
(학습시킬 파라미터가 없다는 얘기!)
Details/Retrospectives:
- first use of ReLU
- used Norm layes(not common anymore)
- heavy data augmentation
- dropout 0.5
- batch size 128
- SGD Monentum 0.9
- Learning rate 1e-2, reduced by 10 manually when val accuracy plateaus
- L2 weight decay 5e-4
- 7 CNN ensemble: 18.2% -> 15.4%
- Historical note:
AlexNet을 학습할 당시에 GTX850으로 학습시켰다. 이 GPU는 메모리가 3GB뿐이였는데,
전체 레이어를 GPU에 다 넣을 수 없어서 네크워크를 분산시켰던 것이다.
각 GPU가 모델의 뉴런과 Feature Map을 반반씩 가진다.
ZFNet
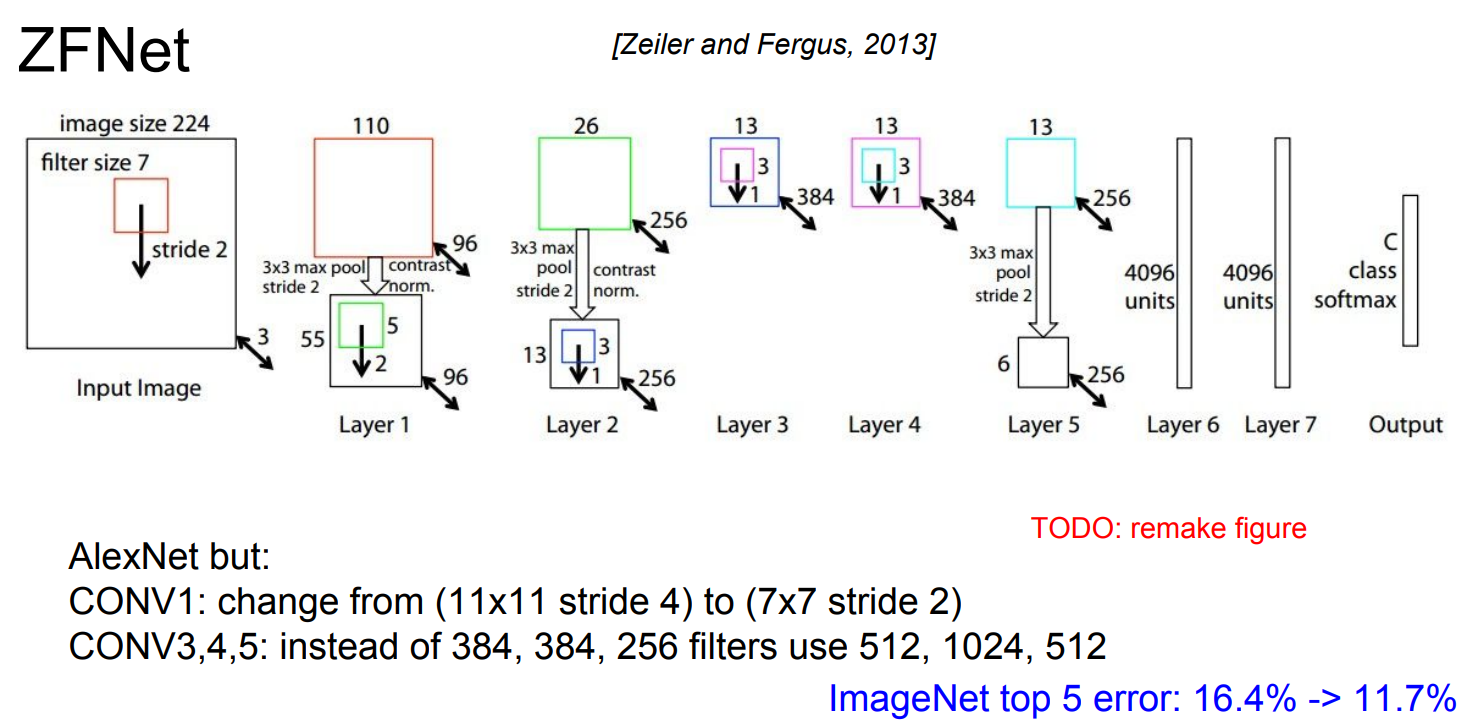
AlexNet의 하이퍼파라미터를 개선한 모델이다.
AlexNet과 같은 레이어 수이고 기본적인 구조도 같지만, stride size, 필터 수 같은 하이퍼파라미터를 조절해서 기존 AlexNet을 개선시켰다.
VGGNet
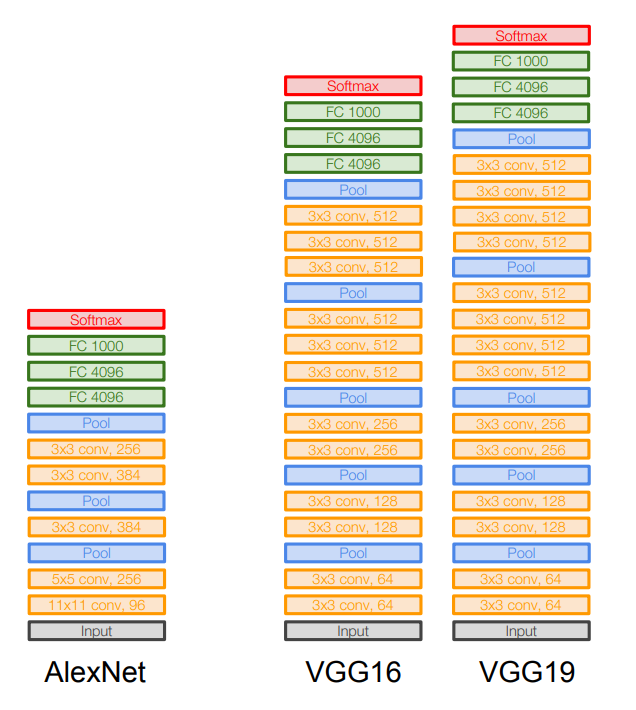
AlexNet - 8개의 레이어
VGGNet - 16 ~ 19개 레이어
VGGNet은 훨씬 깊이가 깊어졌고, 더 작은 필터를 사용함으로써 비선형성을 추가하고 high level의 feature를 추출할 수 있게 되었다.
작은 필터인 3x3 필터만 사용하는데, 이는 이웃픽셀을 포함할 수 있는 가장 작은 필터
이 크기를 유지하면서 주기적으로 Pooling을 수행하는 전체 네트워크를 구성함.
VGGNet은 아주 심플하면서도 고급진 아키텍쳐, ImageNet에서 7.3%의 Top 5 Error 기록
Q1) Why use smaller filters?
A: 크기가 작은 필터이기때문에 파라미터의 수가 더 적다. 그래서 큰 필터에 비해 레이어를 조금 더 많이 쌓을 수 있다.(망이 깊어진다.)
*사실 이론적으로 7x7나 3x3을 2개 사용하는 것이 성능적으로 동일할 수 있으나 VGGNet팀이 테스트한 결과 3x3 커널을 중첩해서 사용하는 것이 더 좋다고 말함. 그 이유는 non-linear 함수 ReLU가 더 많이 들어가서 decision functino이 더 잘 학습이 된다. 그리고 학습할 파라미터 수가 줄어 들어 속도가 더 빨라진다.(3x3필터에는 9개의 파라미터)
Q2) What is the effective receptive field of three 3x3 conv(stride1)layers? (stride가 1인 필터 세 개를 쌓는다면 실제로 Receptive field는 어떻게 되는가?)
A: Receptive Field는 filter가 한번에 볼 수 있는 수용 영역이다. 필터들이 서로 겹치게 되고, 첫 번째 레이어의 Receptive field는 3x3인데, 두 번째 레이어의 경우 각 뉴런이 첫 번째 레이어 출력의 3x3만큼 보게 될 것이다. 그리고 3x3에서 각 사이드는 한 픽셀씩 더 볼 수 있어 두 번째 레이어의 경우 실제로는 5x5의 receptive field를 가지게 된다.
세 번째 레이어의 경우 마찬가지로 두 번째 레이어를 바라보게 되고, 앞선 논리와 마찬가지로 한 픽셀씩 더 보게 됨으로써 Recptive Field는 7x7이 된다.(하나의 7x7필터를 사용하는 것과 같은 셈)
네트워크 살펴보기

VGG16의 모든 레이어의 수는 16개이다.
VGG16은 메모리 사용량이 많은 편이다.
FC Layer는 너무 많은 파라미터를 갖는데 최근 일부네트워크들은 너무 많은 파라미터를 줄이기 위해 이를 없애버리기도 한다.
Details/Retrospectives
보통 16을 많이 사용한다.
베스트 리절트를 위해 앙상블 기법을 사용했다.
특징이 추출이 잘되며 다른 Task에서도 일반화 능력이 뛰어난 것으로 알려져 있다.
Appendix
Feature Map