ResNet특징
딥러닝에서 네트워크가 깊어질수록 성능이 올라가지만 학습이 어려워지는데, 이에 해결 방안으로 네트워크의 깊이를 늘리면서 안정적인 학습을 위해 ResNet이 탄생함.
- Residual learning
: 기존 신경망은 k번째 층과 (i+1)번째 층의 연결로 이루어져 있는데, ResNet은 (i+r)층의 연결을 허용했다. 'shortcut connection'이라 생각하면 간단하다.
지름길로 두 층의 연결함으로써 역전파 작동 시 이전 층으로 기울기가 쉽게 전파되는 이점이 있다.
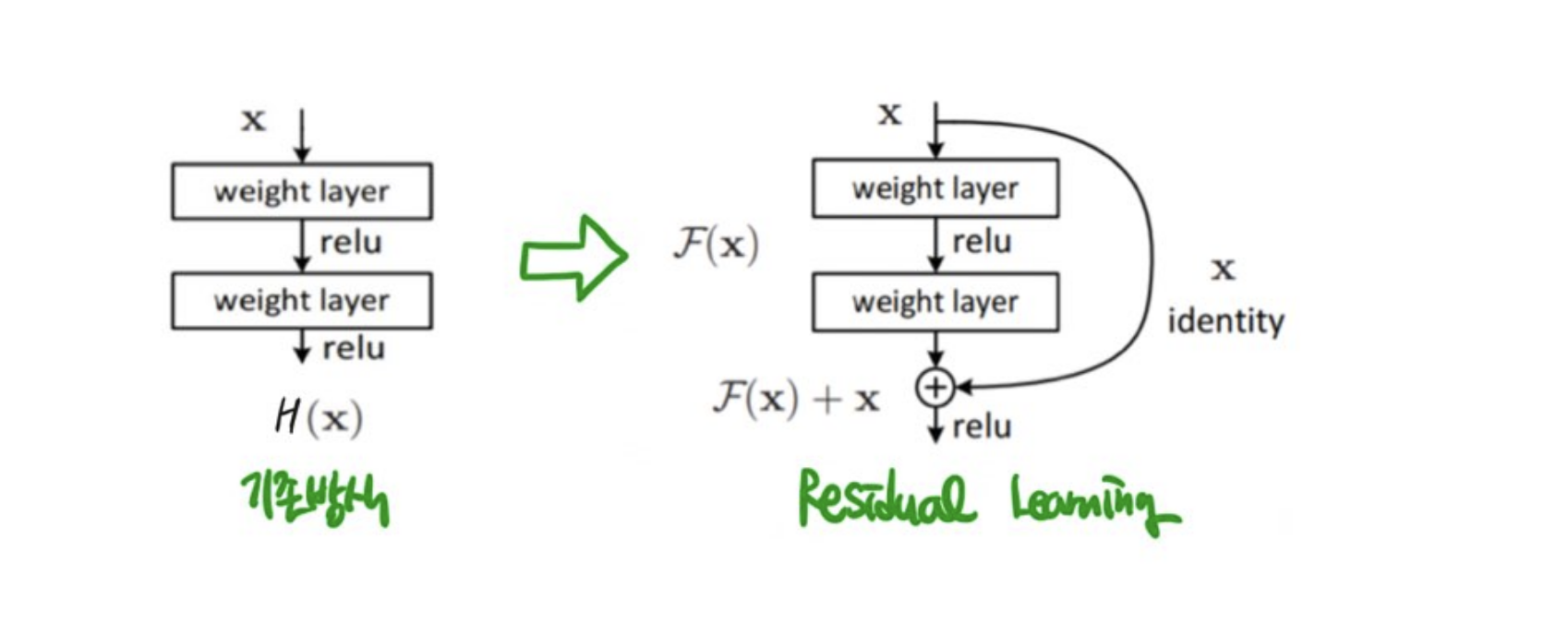
기존 방식은 이웃한 층끼리 연결되어 있고 X를 입력으로 받아 H(x)를 출력한다.
또한 학습을 통해 적절한 가중치 값을 찾아 최적의 H(x)를 찾는 것을 목표로 하는 것이 일반적.
이때 목표를 조금 수정해 출력과 입력간의 차인 H(x) - x를 얻는 것이라고 했을 때,
H(x)-x를 F(x)라고 하면 결과적으로 출력 H(x)는 H(x) = F(x)+x가 된다.
이 방식이 Residual Learning의 기본 방식이다.
참고)https://ardino.tistory.com/45
- Residual Block
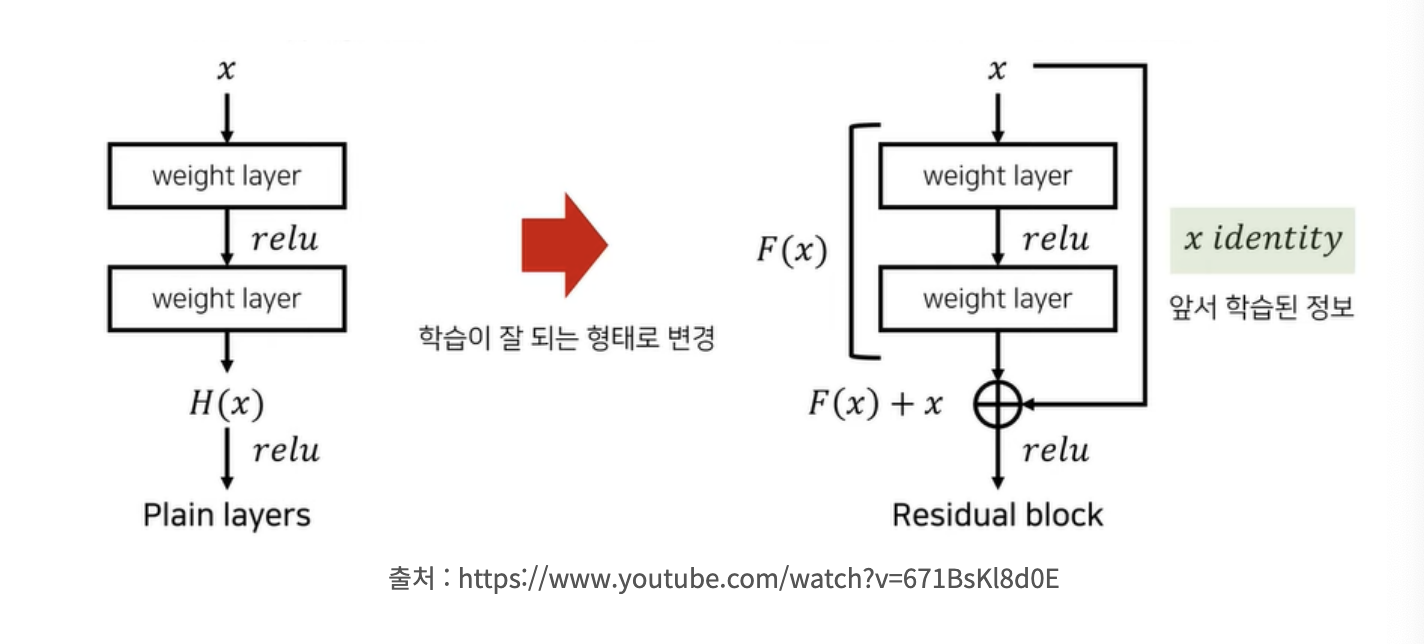
input 값은 그대로 가져오고, 나머지 잔여 정보인 F(x)만을 추가적으로 더해주는 단순한 형태로 만들어 준다.
즉, 잔여효과(추가적인 정보)인 F(x)만 학습을 하면 되는 상황이다. 따라서 전체를 학습하는 것보다 학습이 오히려 쉬워지고, 수렴을 더 잘 할 수 있게 된다. 전체를 학습할 때는 각 weight layers가 모두 분리되어 있기 때문에 각 layer마다 학습을 진행해줘야하는데, 수렴 난이도가 높아진다.
appendix(RNN이 학습이 잘 안되는 이유)
일반적인 RNN의 경우 짧은 시퀀스를 처리할 경우엔 유리하지만 관련 정보와 그 정보를 사용하는 지점이 멀어지면 학습 능력이 떨어진다. 데이터의 시퀀스가 길어지만 장기 의존성 학습에 어려움을 겪는데 가중치를 업데이트를 하는 과정에서 1보다 작은 값들이 계속 곱해지면서 기울기 소실 문제(Vanishing Gradient Problem)가 발생한다.
기울기가 사라지게 되면 과저 정보가 현재의 학습에 영향을 미치지 못하게 되면서 RNN의 퍼포먼스가 떨어진다. 이를 위해 나온 것이 LSTM, GRU이다.
