stanford_cs231_4_summary
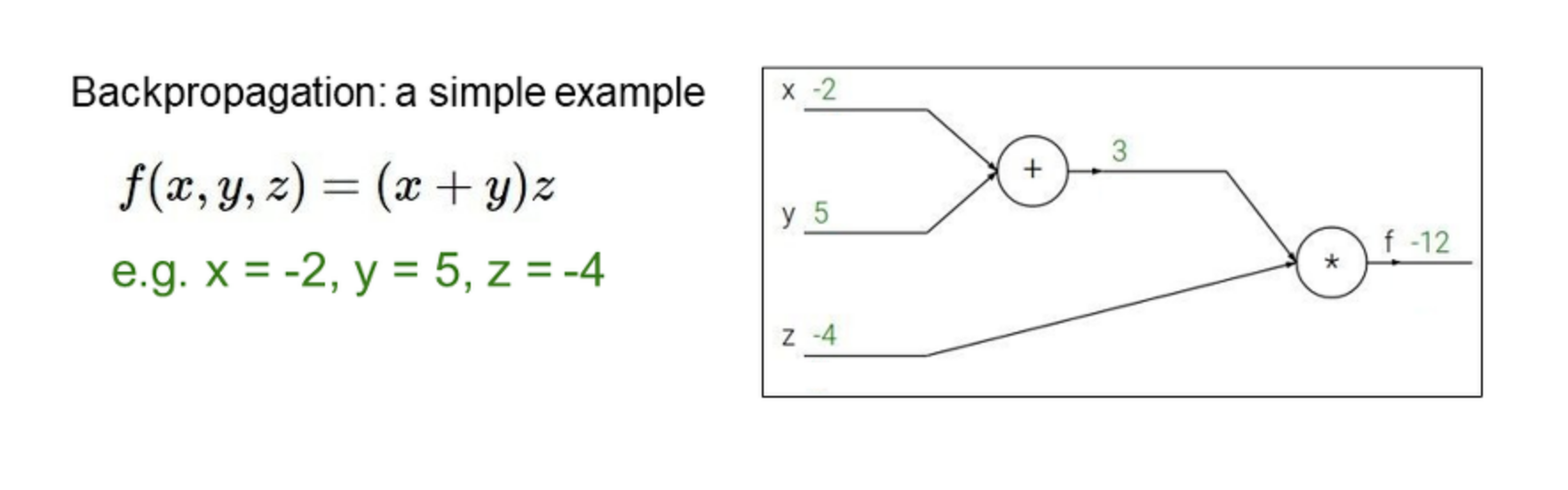
<심플 예제>
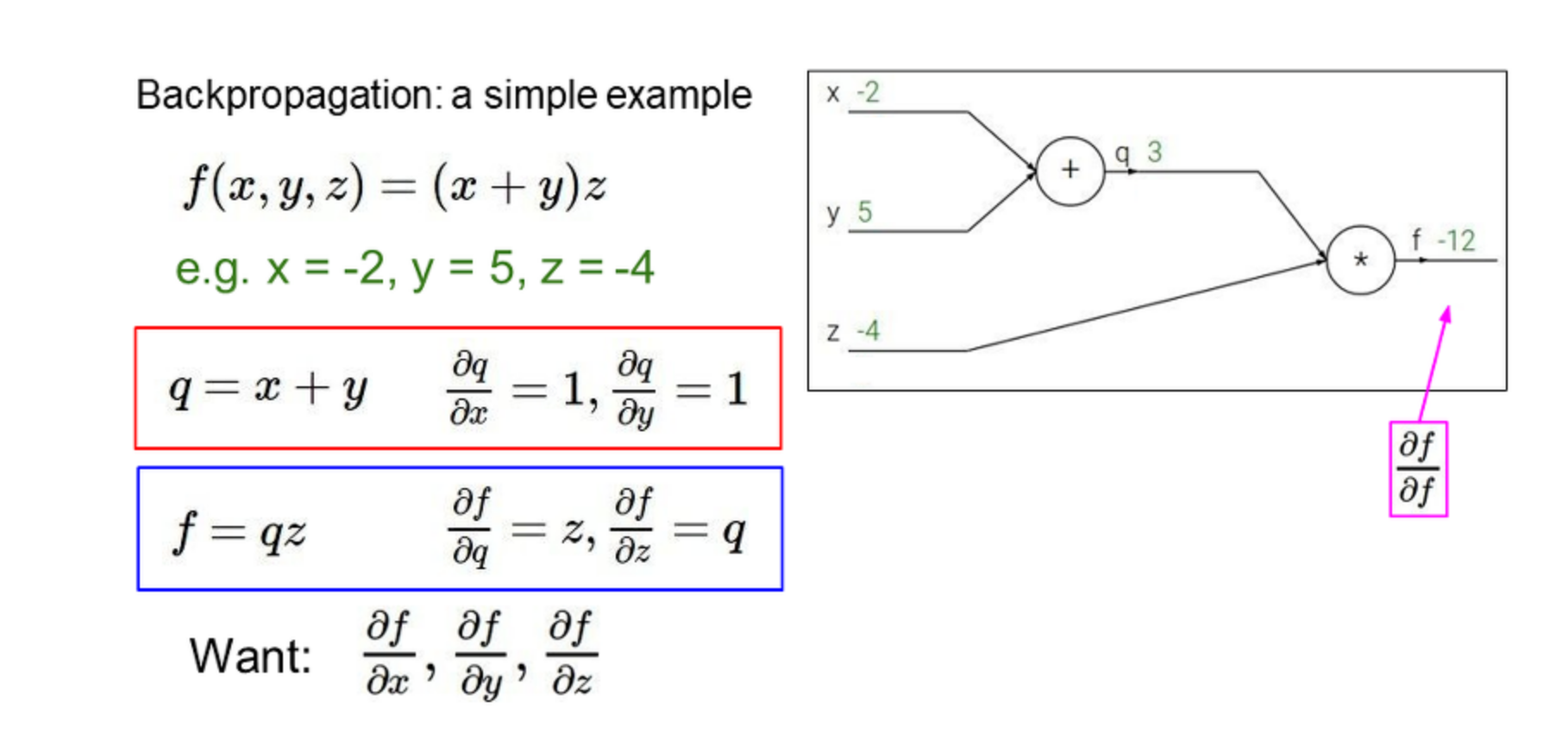
역전파를 통해 각 미분값을 구함.
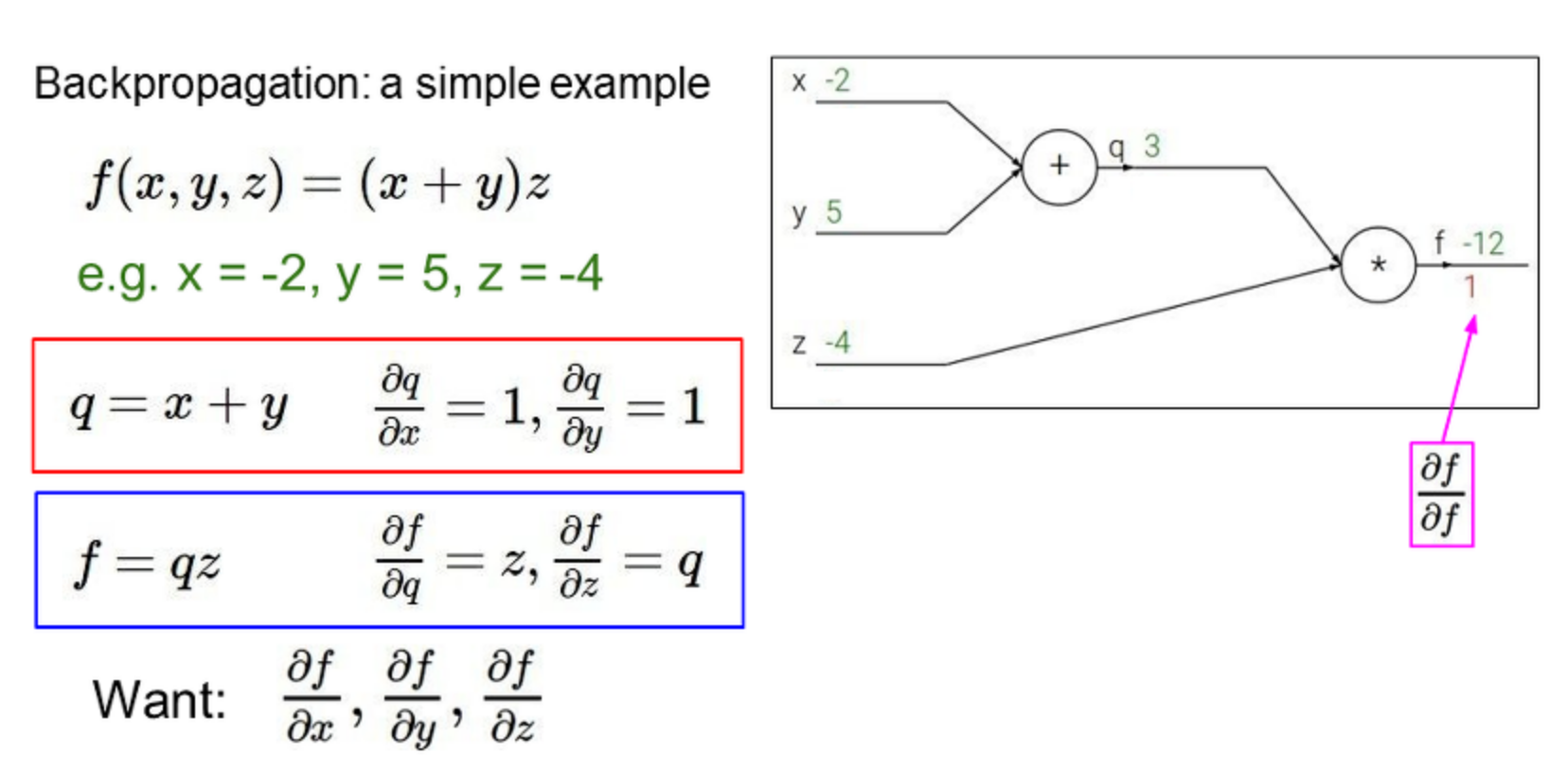
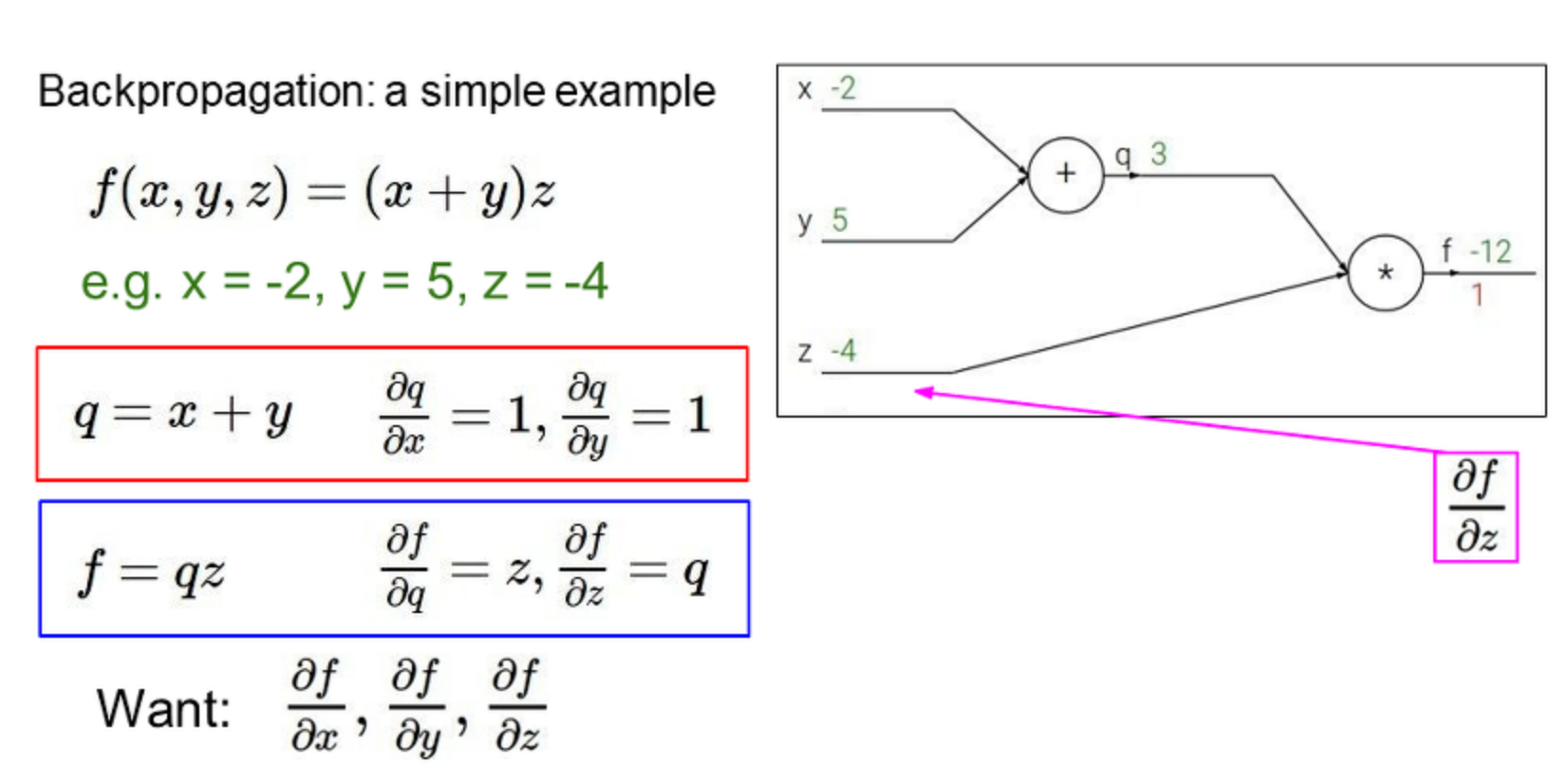
정리하자면..
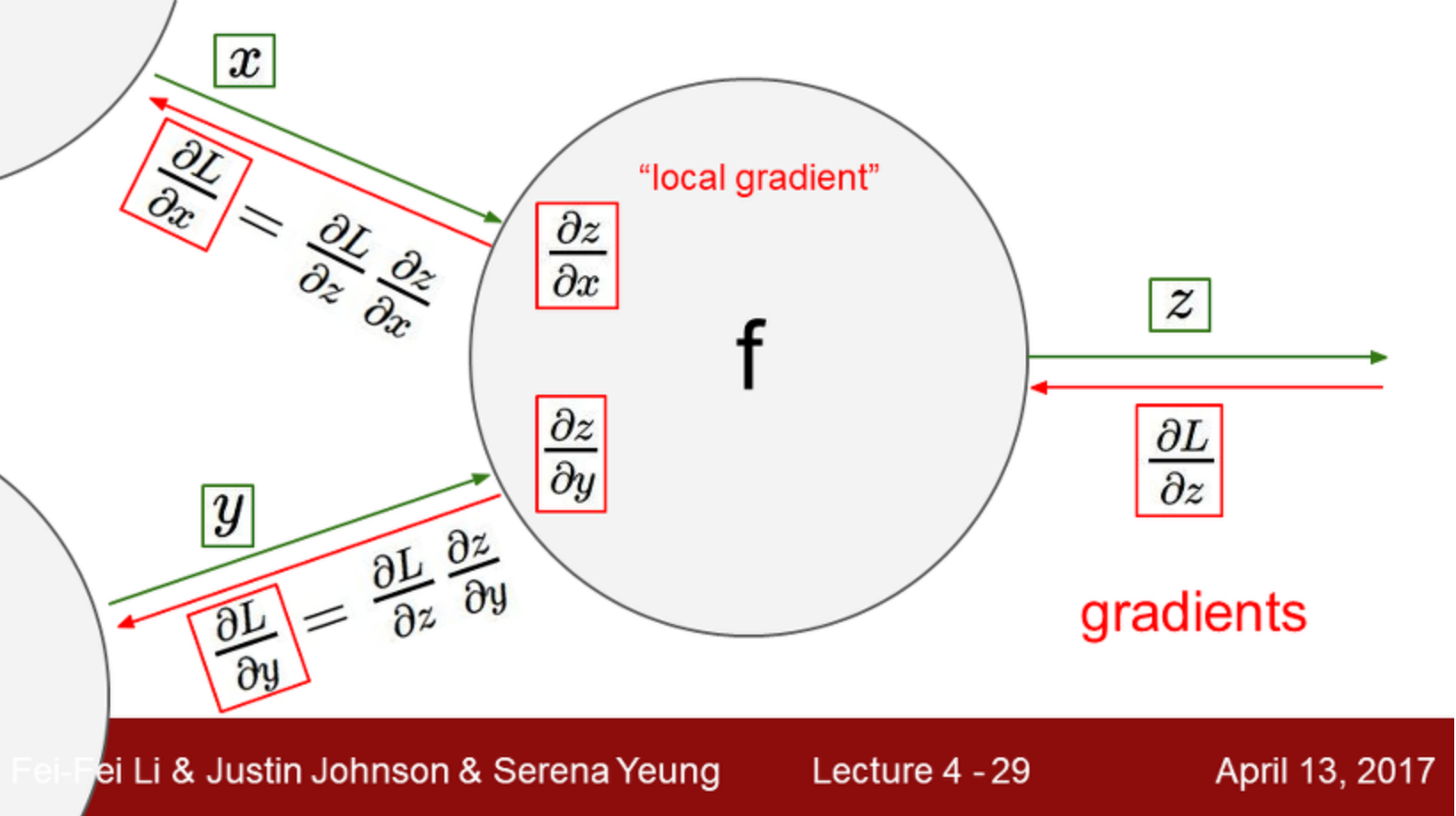
75p ~

- backward로 보면 역순으로 모든 게이트를 통과한 후 각각의 게이트를 거꾸로 호출한다.
- forward pass에서는 노드의 출력을 계산하는 함수를 구현하고, backward시 gradient를 계산한다.

forward pass에서 중요한 것은 forward pass 값을 cache해야 하는 것이다. 물론 x,y 값도 저장
backward pass에서 chain rule을 사용해야 하기 때문에.
프레임워크
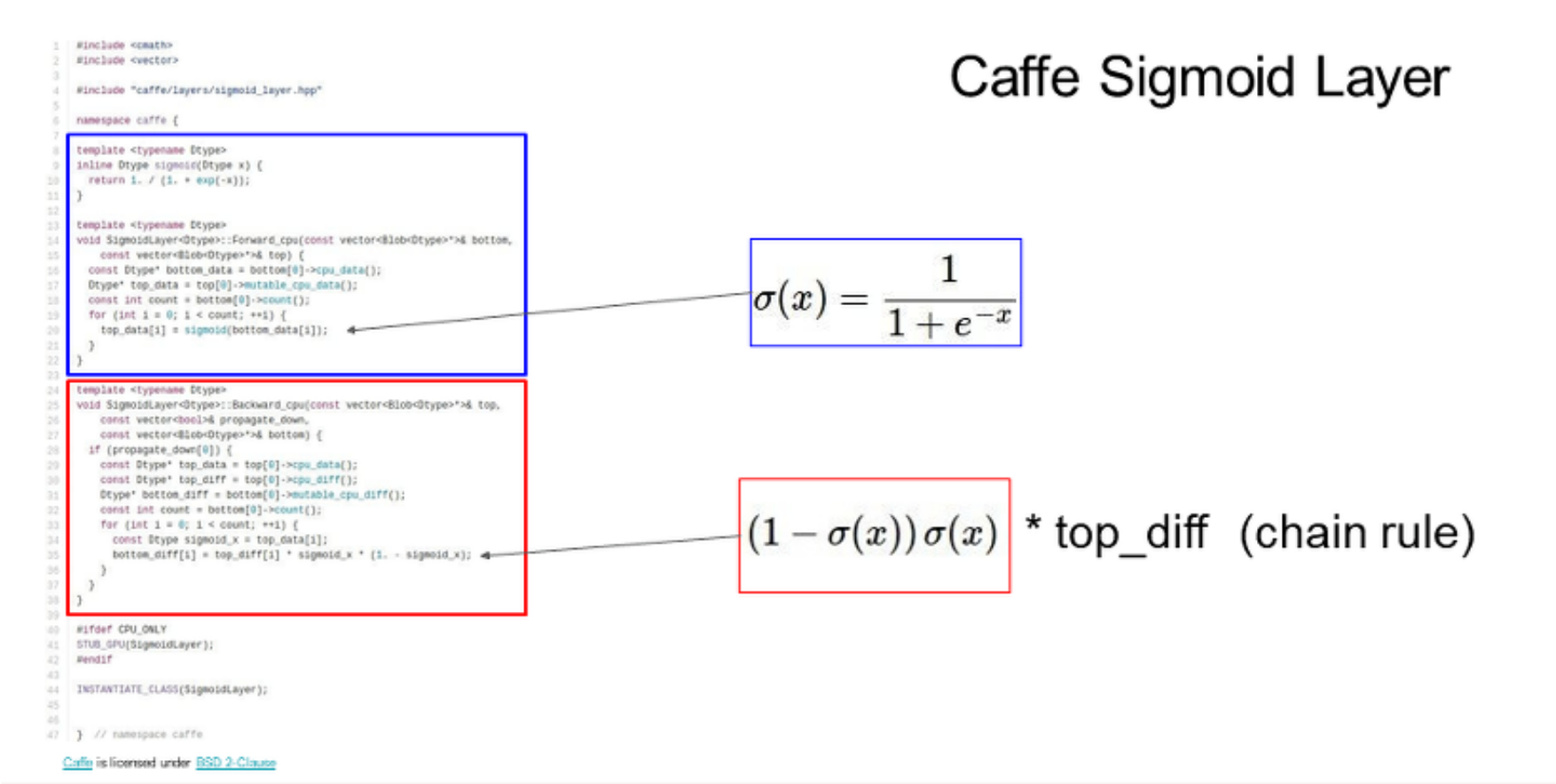

=요약=
- 신경망으로 작업 할 때, 이것들은 매우 복잡해질 것이다. 그래서 모든 파라미터에 대해 gradient를 손으로 써 내려가는 것은 비현실적이다.
- 역전파: 이 것은 신경망의 핵심 기술이고, gradient를 구하기 위해 backpropagation을 쓴다. input/parameters/intermediates의 기울기를 구하는 그래프
- 각각 노드가 구현하는 forward()/backward() API의 그래프 구조를 유지한다.
- forward pass: 작업의 결과를 계산하고 결과를 저장한다. 기울기를 구하기 위해 필요로하는 중간을 저장한다.
- backward: 손실함수의 기울기를 계산하기 위해 chain rule을 적용한다.
신경망
사람은 신경망과 뇌 사이에서 많은 유추와 여러 종류의 생물학적 영감을 이끌어낸다.
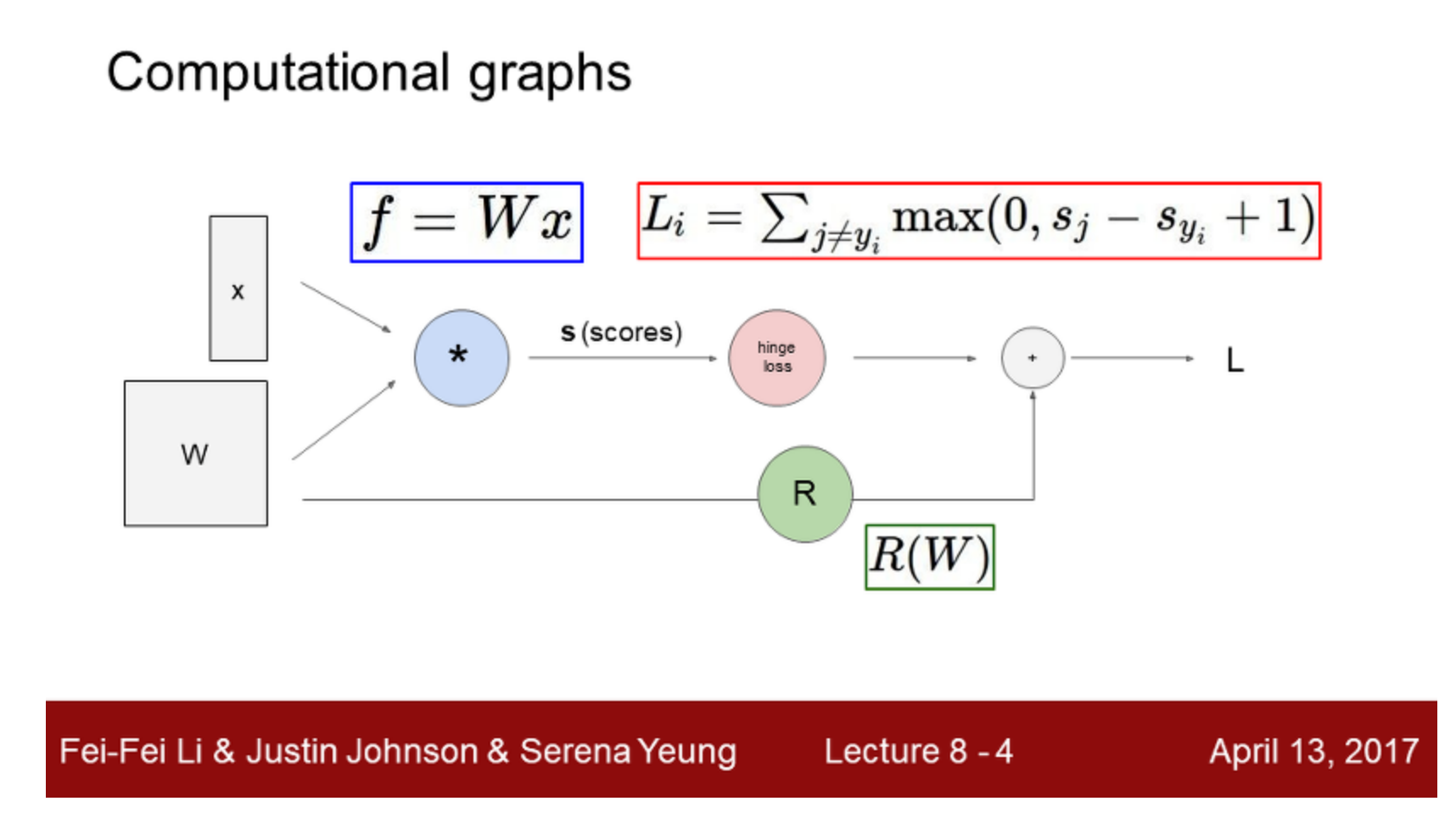
(Before) Linear score function: f=Wx
(Now) 2-layer Neural Network: f=W2max(0,W1x) == Relu

(처음에3072개의 x가 들어오면 w1과 곱해져서 h(hidden)노드에 들어가고 다시 w2를 통해 10개의 출력값이 나오게 된다.)
히든 노드가 100개면 우리는 서로 다른 100개의 분류기를 가지고 있는 것이다.
3-layer는 f = W3max(0, W2max(0,W1x))

input이 있으면 그것에 따른 w를 곱해서 그걸 어떤 활성화 함수를 통해 거쳐서 output으로 나가는..
About Neuron
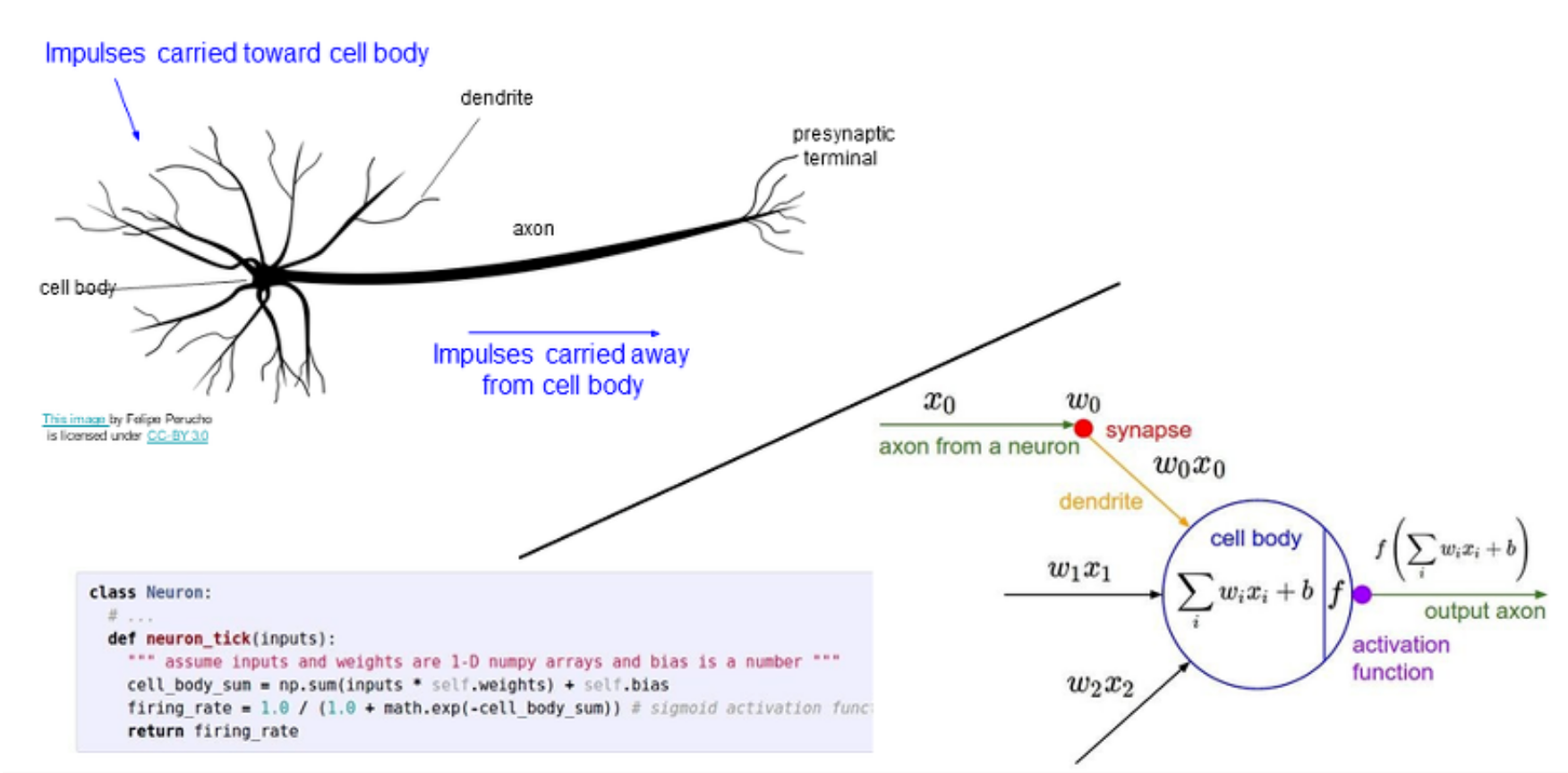
<뉴런의 다이어그램>
서로 연결된 많은 뉴런은 수상돌기를 가지고 있는데, 그것들은 뉴런에 들어온 신호를 받는다.
그리고 세포체와 합친 후의 모든 신호는 'axon'을 통해 다음 뉴런과 다른 세포체로 이동한다.
활성화 함수들
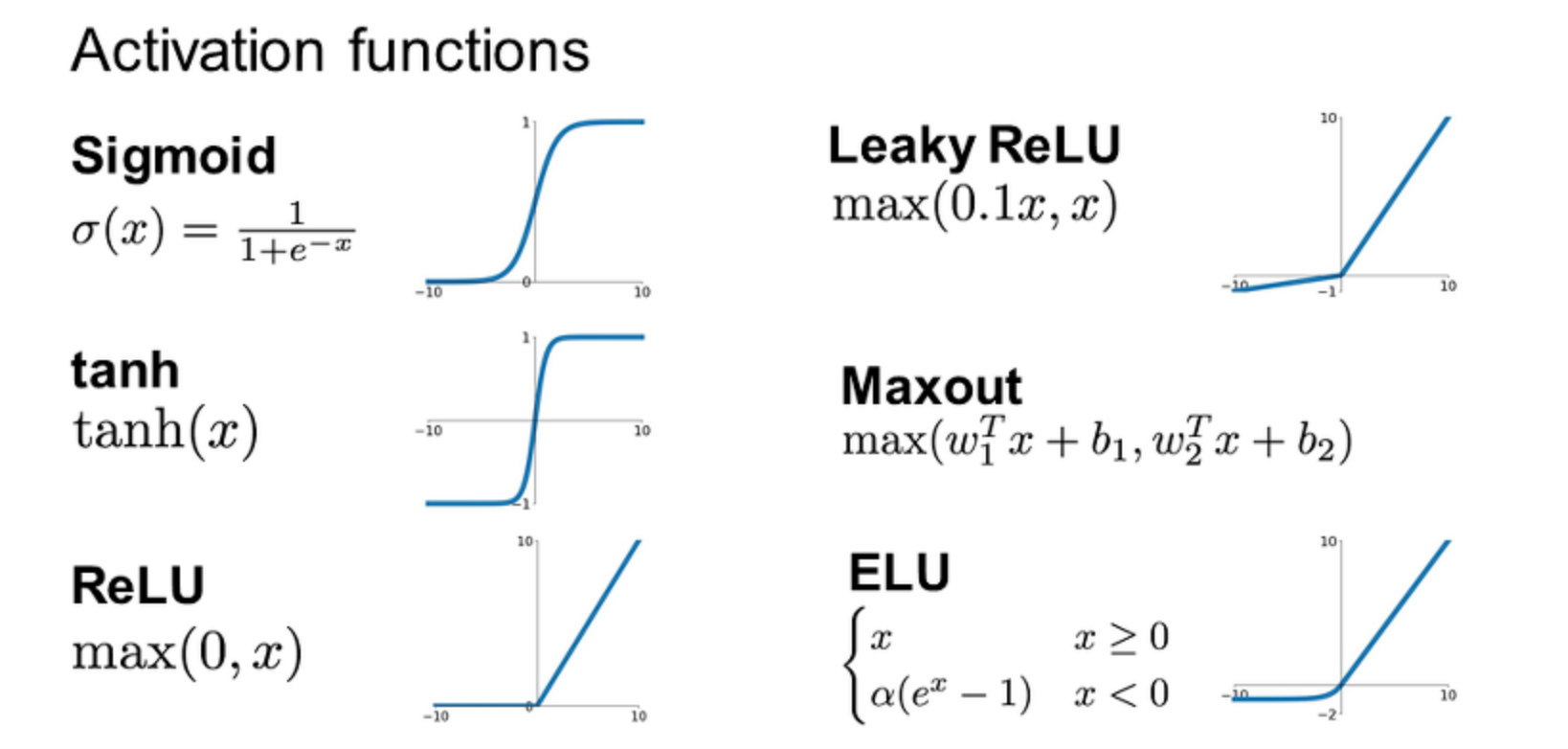
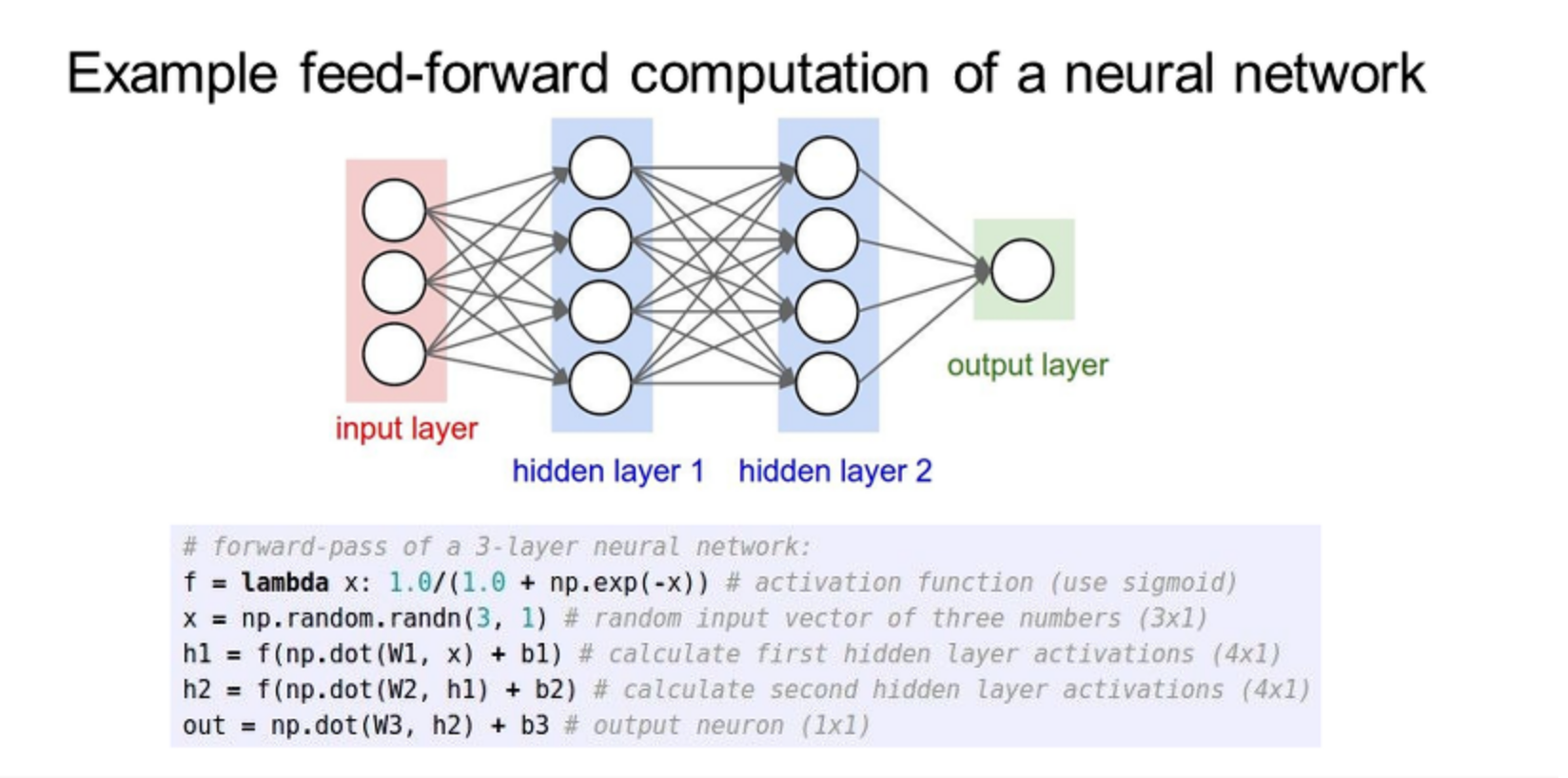
정리
- We arrange neurons into fully-connected layers
- The abstraction of a layer has the nice property that it
allows us to use efficient vectorized code (e.g. matrix
multiplies) - Neural networks are not really neural
추가
어떠한 활성화 함수를 써야할까?
일반적으로 ELU → LeakyReLU → ReLU → tanh → sigmoid 순으로 사용한다고 한다. cs231n 강의에서는 ReLU를 먼저 쓰고 , 그다음으로 LeakyReLU나 ELU 같은 ReLU Family를 쓰며, sigmoid는 사용하지 말라고 하고 있다.
